性能篇:LinkedList循环为什么使用Iterator而不是for?
大家好,我是小米,一个热衷于技术分享的程序员。今天我们来聊一个平时开发中可能会遇到的问题——在使用LinkedList时,为什么要避免使用for循环来读取元素,以及如何优化性能。
LinkedList简介
首先,让我们简单回顾一下LinkedList的基本概念。LinkedList是一种链表数据结构,由节点组成,每个节点包含数据元素和指向下一个节点的引用。相比于ArrayList,LinkedList具有动态大小、插入和删除更高效的特点。
for循环在LinkedList中的问题
在使用LinkedList时,我们通常会使用迭代器(Iterator)来遍历元素,而不是采用传统的for循环。为什么呢?原因在于LinkedList的数据存储方式。在ArrayList中,我们可以通过索引直接访问元素,但是在LinkedList中,要通过遍历找到目标元素,这就导致了使用for循环的性能问题。
让我们看一个简单的例子:
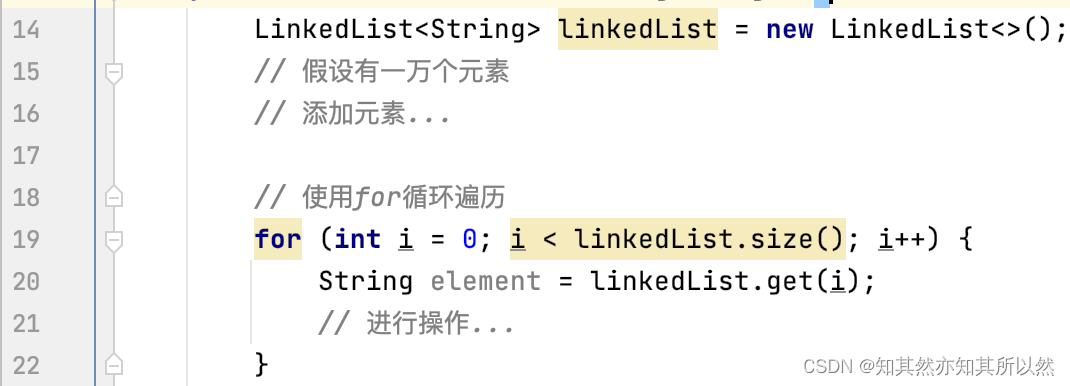
这样的代码在LinkedList上运行会非常慢,因为每次调用get(i)都需要从头开始遍历链表,时间复杂度是O(n),总体性能会大大降低。
使用迭代器优化性能
为了避免这种性能问题,我们应该使用迭代器来遍历LinkedList。迭代器内部维护了一个指针,可以直接访问下一个元素,而无需每次都从头开始查找。修改上述代码:
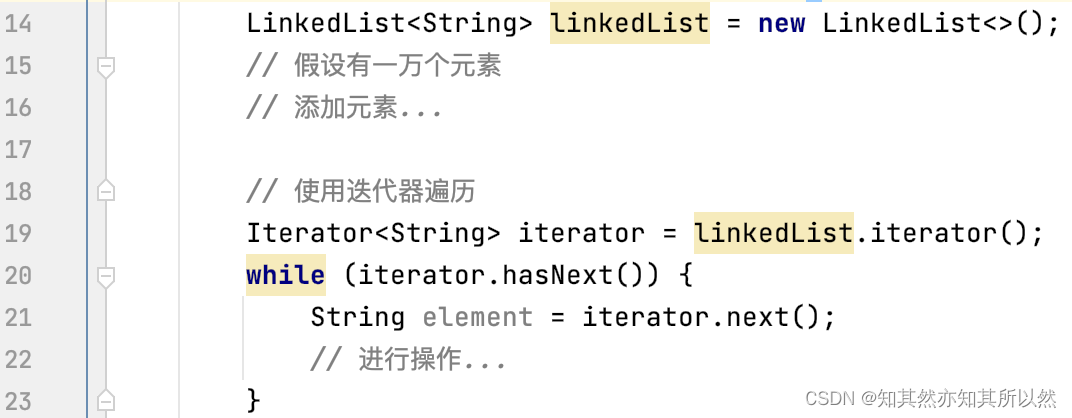
通过使用迭代器,我们避免了每次都从头开始遍历链表的性能问题,使得代码更加高效。
性能对比
为了更直观地感受性能的差异,我们可以通过简单的测试来对比使用for循环和迭代器的性能。这里我用JMH(Java Microbenchmarking Harness)来进行简单的性能测试:
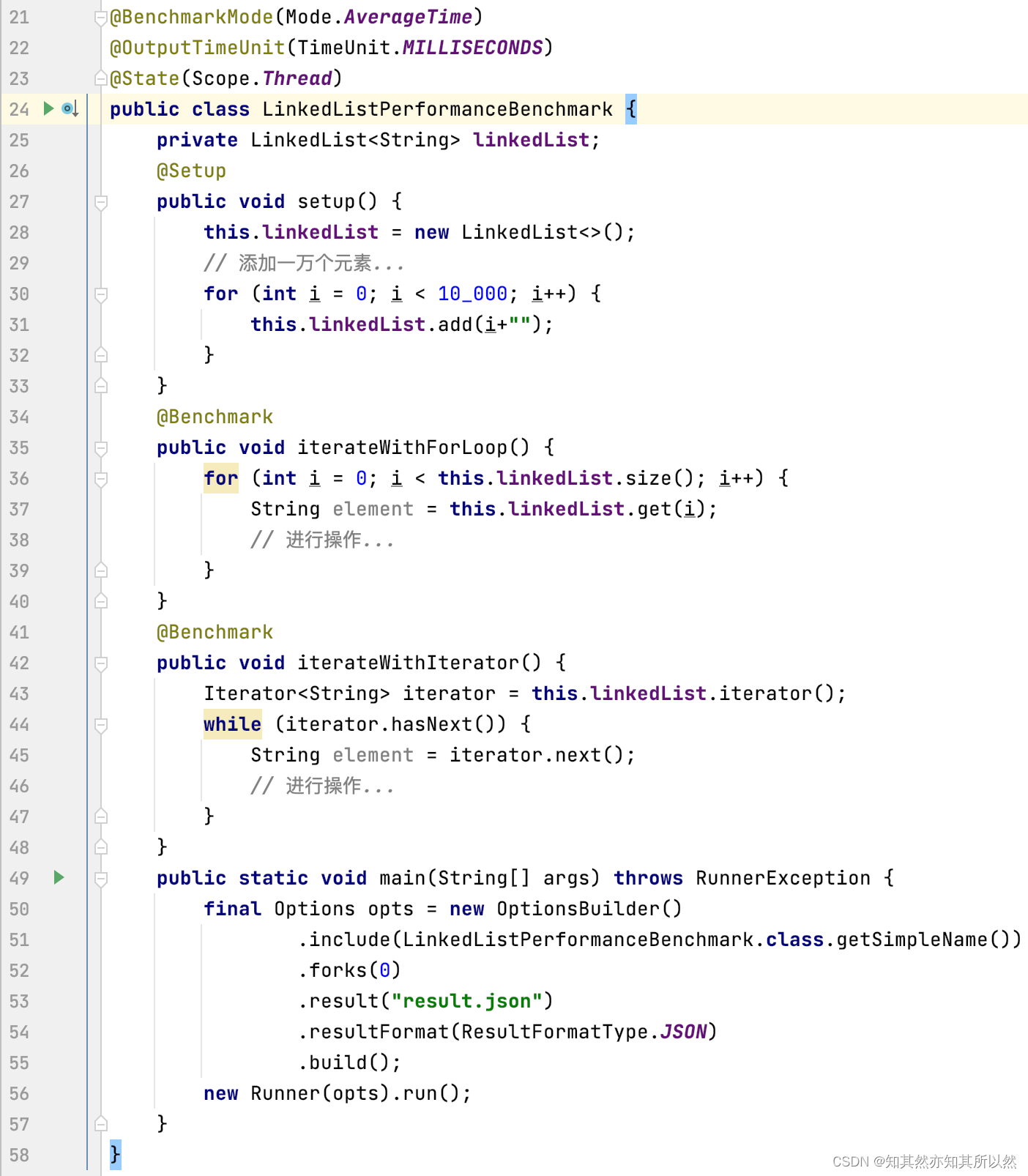
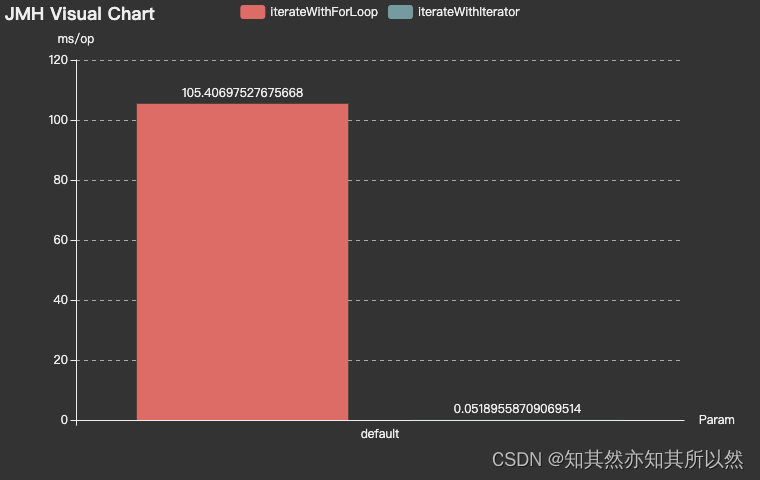
测试结果很明显,使用迭代器的性能要远远优于使用for循环,特别是在数据量较大的情况下。
小结
我们经常使用的 LinkedList 集合,如果使用 for 循环遍历该容器,将大大降低读的效率,但这种效率的降低很难导致系统性能参数异常。
这时有经验的同学,就会改用 Iterator (迭代器)迭代循环该集合,这是因为 LinkedList 是链表实现的,如果使用 for 循环获取元素,在每次循环获取元素时,都会去遍历一次List,这样会降低读的效率。
END
通过这篇文章,我们了解了在使用LinkedList时为什么要避免使用for循环,以及如何通过使用迭代器来优化性能。在实际开发中,优化性能是我们应该时刻关注的问题之一,合理选择数据结构和遍历方式是其中的一个重要方面。
希望大家在今后的开发中能够更加注重代码性能,少走弯路,写出更加高效的代码。如果你有其他关于性能优化或者数据结构方面的问题,也欢迎留言讨论哦!感谢大家的阅读,我们下期再见!
如有疑问或者更多的技术分享,欢迎关注我的微信公众号“知其然亦知其所以然”!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 全链路追踪关键技术-TraceId、SpanId生成规则
- Python 猎户星空Orion-14B,截止到目前为止,各评测指标均名列前茅,综合指标最强;Orion-14B表现强大,LLMs大模型
- C# WPF上位机开发(树形控件在地图软件中的应用)
- Minikube安装
- Tomcat配置教程分享【^_^】
- 《ORANGE’S:一个操作系统的实现》读书笔记(三十)文件系统(五)
- 程序员如何应对裁员-法律知识
- 最新Jasmine博客模板:简洁美观的自适应Typecho主题
- MySQL事务管理
- DC-2靶场