深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第三节 栈与堆,值类型与引用类型
深入浅出图解C#堆与栈 C# Heaping VS Stacking 第三节 栈与堆,值类型与引用类型
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第一节 理解堆与栈](https://mp.csdn.net/mdeditor/101021023)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第二节 栈基本工作原理](https://mp.csdn.net/mdeditor/101022949#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第三节 栈与堆,值类型与引用类型](https://mp.csdn.net/mdeditor/101023885#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第四节 参数传递对堆栈的影响 1](https://mp.csdn.net/mdeditor/101026168#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第四节 参数传递对堆栈的影响 2](https://mp.csdn.net/mdeditor/101027584#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第五节 引用类型复制问题及用克隆接口ICloneable修复](https://mp.csdn.net/mdeditor/101028008#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第六节 理解垃圾回收GC,提搞程序性能](https://mp.csdn.net/mdeditor/101029557#)
- 栈与堆,值类型与引用类型
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第一节 理解堆与栈
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第二节 栈基本工作原理
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第三节 栈与堆,值类型与引用类型
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第四节 参数传递对堆栈的影响 1
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第四节 参数传递对堆栈的影响 2
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第五节 引用类型复制问题及用克隆接口ICloneable修复
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第六节 理解垃圾回收GC,提搞程序性能
栈与堆,值类型与引用类型
前言
虽然在.Net Framework 中我们不必考虑内在管理和垃圾回收(GC),但是为了优化应用程序性能我们始终需要了解内存管理和垃圾回收(GC)。另外,了解内存管理可以帮助我们理解在每一个程序中定义的每一个变量是怎样工作的。
简介
本文将介绍值类型与引用类型在堆栈里的基本存储原理。
值类型会存储在堆里?
是的,值类型有时候就是会存储在堆里。上一节中介绍的黄金规则2:值类型和指针永远存储在它们声明时所在的堆或栈里。如果一个值类型不是在方法中定义的,而是在一个引用类型里,那么此值类型将会被放在这个引用类型里并存储在堆上。
代码图例
我们定义一个引用类型:
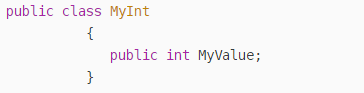
里面包含一个值类型MyValue。
执行下面的方法:

就像上一节介绍的一样,线程开始执行此方法,参数pValue将会被放到当前线程栈上。

接下来不同于上一节所介绍的是MyInt是一个引用类型,它将被放到堆上并在栈上放一个指针指向它在堆里的存储。
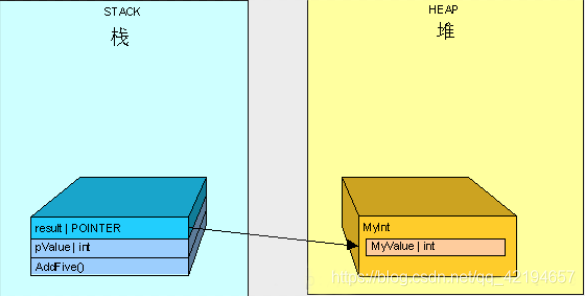
当AddFive()执行完成后,如上一节所讲栈开始清理。
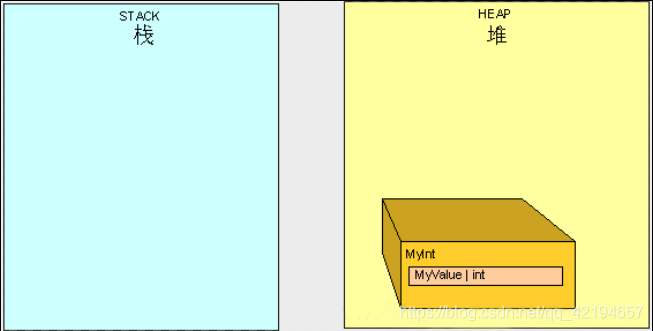
现在是需要C#垃圾回收GC的时候了。当我们的程序所占内存到达临界值时(即将溢出),我们会需要更多的堆空间,GC就会开始运行。GC停止所有当前运行线程(整体停止),找到堆里所有主程序不会访问到的对象并删除它们。然后,GC会识别所有堆里剩下的对象并分配内存空间给它们,同时调整堆和栈里指向它们的指针。你可以想像这是非常耗资源的,这会影响到程序的性能。这就是为什么我们需要理解和注意堆栈的使用,进而写出高性能代码。
堆栈原理对代码的影响
当我们使用引用类型时,我们在和指向引用类型的指针打交道,而不是引用类型本身。
当我们使用值类型时,我们就是在和值类型本身打交道。
代码图例
使用值类型
假设执行方法:

我们会得到值 3。
使用引用类型

如果执行方法:

我们得到的值是4而不是3!(译外话:这是很简单,但相信还是有很多人不知道原理的)
第一个示例中

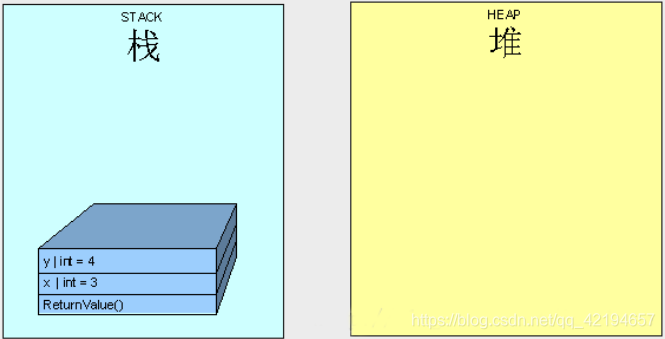
x就是3,y就是4。操作两个不同对象。
第二个示例

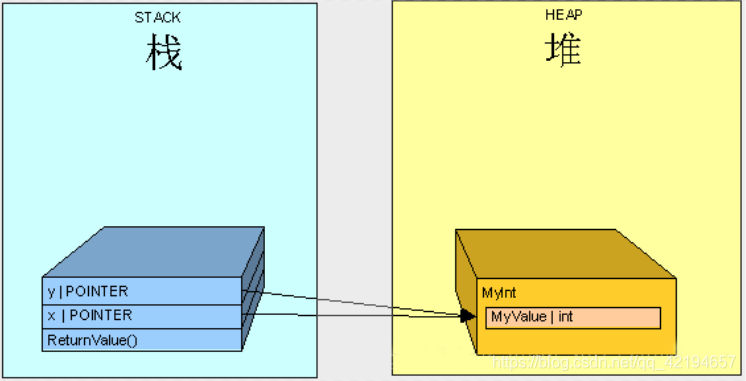
得到的值是4不是3是因为我们操作栈里两个指针并且它们指向堆里同一个对象。
总结
希望这篇文章能帮助你更好的理解值类型变量与引用类型变量的不同,同时理解什么是指针,什么时候用到指针。以后的文章里会更深入的介绍C#内存管理并详细阐述方法参数。
译文连接:https://blog.csdn.net/leewhoee/article/details/16957545
原文链接:https://www.c-sharpcorner.com/article/C-Sharp-heaping-vs-stacking-in-net-part-i/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python项目-基于Python的考研调配系统-爬虫
- mac绘画软件有哪些?Mac绘画软件大揭秘
- ACL16_S 系列 低成本物联网安全芯片,可应用物联网认证、 SIM、防抄板和设备认证等产品上
- Angular: FormArray 数组表单控件,允许用户手动修改页面表格的数据
- [Vue warn]: injection “Symbol(router)“ not found.
- 详解—C++ [异常]
- android 分享文件
- Docker五部曲之二:Docker引擎
- 浅谈 Java 数组链表
- 数据库学习日常案例20231221-SUN OS swap使用严重 IPCS -MA 共享内存未释放导致