具有运动模糊的大规模场景的混合神经绘制
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
本周的学习内容主要是以阅读文献为基础,在文献中了解前沿知识。这次共阅读具有运动模糊的大规模场景的混合神经绘制,了解移动运动模糊的神经辐射场中的问题,以及了解文中提出的视点依赖归一化方法的工作原理。此外还学习了解了YOLO模型,了解其大致的工作原理,与先前学习的卷积神经网络模型进行对比,并开始学习MMdetection的相关代码知识。
Abstract
This week’s learning content is mainly based on reading literature to understand cutting-edge knowledge. This time, I read a large-scale scene with motion blur for hybrid neural rendering, and I learned about the problems in the neural radiation field of mobile motion blur, as well as the working principle of the viewpoint-dependent normalization method proposed in the article. In addition, I also learned about the YOLO model, understood its general working principle, compared it with the previously learned convolutional neural network model, and began to learn the relevant code knowledge of MMdetection.
文献阅读:具有运动模糊的大规模场景的混合神经绘制
Title: VDN-NeRF_Resolving_Shape-Radiance_Ambiguity_via_View-Dependence_Normalization
Author:Bingfan Zhu , Yanchao Yang , Xulong Wang , Youyi Zheng? , Leonidas Guibas
From:2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
1、研究背景
在三维渲染中,形状-辐射模糊和方向性视图依赖性是一个重要的问题。形状-辐射模糊是指由于光照和物体表面的相互作用,相同的表面点在不同的视角下可能会表现出不同的辐射亮度。方向性视图依赖性则是指物体表面的辐射亮度不仅取决于表面的几何形状,还取决于观察者的视角。为了处理这个问题,我们需要增加方向性颜色函数的容量。但是,我们不能让这个容量超过所需的范围,否则形状-辐射模糊就会开始影响几何形状的估计精度。换句话说,我们需要找到一个平衡点,既能处理方向性视图依赖性,又能保持几何形状的精度。此外,我们还可以通过训练神经网络来解决这个问题。例如,我们可以使用一种名为NeuS的神经网络进行训练,这个神经网络可以为每个对象生成一个可学习的颜色分支,用于处理方向性视图依赖性。通过调整这个颜色分支的容量,我们可以更好地平衡形状-辐射模糊和方向性视图依赖性的问题。
2、方法提出
VDN-NeRF是一种改进神经辐射场(NeRF)的方法,用于在非朗伯表面和动态光照条件下更好地重建三维场景的几何形状。这种方法通过解决形状-辐射模糊性来提高几何精度。在非朗伯表面和动态光照条件下,一个点的辐射度会因观察角度的不同而发生显著变化,这给三维重建带来了挑战。传统的NeRF方法通常会受到形状-辐射模糊性的影响,导致重建的几何形状不够准确。为了解决这个问题,VDN-NeRF提出了一种简单而有效的技术,通过在训练过程中对视图依赖性进行归一化,从已学习的NeRF中提取不变量信息。通过这种方法,NeRF可以更好地捕获形状和光照信息的内在关联,从而提高几何重建的准确性。具体来说,VDN-NeRF首先对NeRF进行训练,以进行视图合成。然后,它采用一种简单的归一化技术,将视图依赖性纳入考虑范围,从而对训练数据进行调整。这样可以在训练过程中优化几何形状的重建结果。通过这种方法,即使在非朗伯表面和动态光照条件下,也可以获得高质量的几何形状重建结果。

3、视点依赖归一化方法
视点依赖归一化方法是一种优化技术,用于解决Volume rendering中的shape-radiance ambiguity和directional view-dependence问题。该方法通过调整神经网络的权重,使其更好地适应方向性变化,从而提高几何形状的准确性。具体来说,视点依赖归一化方法首先对输入数据进行归一化处理,将数据转换到同一尺度下。然后,使用神经网络对归一化后的数据进行学习,得到每个像素点的颜色值。在训练过程中,通过反向传播算法不断调整神经网络的权重,以最小化渲染结果与真实场景之间的差异。
为了更好地适应方向性变化,视点依赖归一化方法引入了方向性函数的概念。方向性函数用于描述在不同观察角度下像素点的颜色值变化规律。通过学习方向性函数,神经网络能够更好地理解不同观察角度下的像素值之间的关系,从而在渲染过程中更准确地预测像素点的颜色值。
4、训练方法
文章提到了一个联合训练的目标函数L,它由三个部分组成:颜色损失λcolor、视图依赖归一化损失Lvdn和正则化损失Lreg。颜色损失用于最小化重建图像与原始图像之间的颜色差异,视图依赖归一化损失用于对不同视图的特征进行归一化处理,正则化损失则用于对网络进行正则化,防止过拟合。具体来说,颜色损失函数和视图依赖归一化损失函数被最小化,其中颜色损失函数用于衡量输入图像和重建图像之间的颜色差异,而视图依赖归一化损失函数则用于对深度神经网络进行正则化,以提高网络的泛化能力。

5、试验细节及对比
中采用了NeuS和WaveletMonodepth两种深度学习网络结构。NeuS是一种基于多层感知器(MLP)的深度神经网络,用于特征提取和深度估计。在NeuS中,特征函数F和辐射函数c具有相似的架构,即4层MLP,隐藏维度为256。同时,文中还采用了分层采样策略,将批量大小设置为512。另外,为了进一步提高网络的泛化能力,文中还引入了WaveletMonodepth作为深度学习网络结构。WaveletMonodepth采用DenseNet161作为其骨干网络,并预训练了几个epoch以加速收敛。在训练过程中,特征提取器从Distillation网络的第一个Conv block中提取深度特征。

文章中提到了对不同的方法进行比较,包括COLMAP、Plenoxels、NeRF、NeRF-W、NeROIC、RefNeRF、VolSDF、NeuS、Geo-A和GeoNeuS等。这些方法涵盖了基于体积的方法和基于表面方向场(SDF)的方法。在比较中,文章提到了使用Intersection-over-Union (IoU)、L1/L2 Chamfer Distance (CD)、Normal Consistency (NC)和f-score等度量标准来评估这些方法的性能。这些度量标准用于衡量多视图重建结果的准确性。此外,文章还提到了使用提出的视图依赖性归一化方法(VolSDF+F、Geo-A+F和Ours)对一些方法进行改进,并观察到这些改进方法的有效性。在这些改进方法中,Ours(即NeuS)在所有度量标准上均取得了最好的性能。文章提出的方法能够保留更准确的几何形状和更多的细节,同时减少伪影。

YOLO模型
1、什么是YOLO
YOLO是一种目标检测模型,全称You Only Look Once,属于目标检测模型的一种。目标检测是计算机视觉中相对简单的任务,旨在在一幅图像中找到特定的物体。YOLO模型将单个神经网络应用于整个图像,将图像划分为若干个网格,每个网格预测一定数量的边界框和其相应的置信概率。这些边界框表示图像中物体的位置,置信概率表示预测边界框的准确性。与以往的带有建议框的神经网络相比,YOLO的速度有显著提升。在YOLO中,每个网格只负责预测一种物体,因此可以一次性输出所有检测到的目标信息,包括类别和位置。这使得YOLO具有较高的处理速度,适用于实时检测等应用场景。
2、YOLO原理
目的是在一张图片中找出物体,并给出它的类别和位置。目标检测是基于监督学习的,每张图片的监督信息是它所包含的N个物体,每个物体的信息有五个,分别是物体的中心位置(x,y)和它的高(h)和宽(w),最后是它的类别。YOLO 的预测是基于整个图片的,并且它会一次性输出所有检测到的目标信息,包括类别和位置。先假设我们处理的图片是一个正方形。YOLO的第一步是分割图片,它将图片分割为 n2
个grid,每个grid的大小都是相等的,像下图这样:

具体方法: n2个框每个都预测出B个bounding box,这个bounding box有5个量,分别是物体的中心位置(x,y)和它的高(h)和宽(w),以及这次预测的置信度。每个框框不仅只预测B个bounding box,它还要负责预测这个框框中的物体是什么类别的,这里的类别用one-hot编码表示。注意,虽然一个框框有多个bounding boxes,但是只能识别出一个物体,因此每个框框需要预测物体的类别,而bounding box不需要。每个框框的bounding boxes个数为B,分类器可以识别出C种不同的物体,那么所有整个ground truth的长度为:n x n x ( B x 5 + C )
3、bounding box
bounding box可以锁定物体的位置,这要求它输出四个关于位置的值,分别是x,y,h和w。我们在处理输入的图片的时候想让图片的大小任意,这一点对于卷积神经网络来说不算太难,但是,如果输出的位置坐标是一个任意的正实数,模型很可能在大小不同的物体上泛化能力有很大的差异。这时候当然有一个常见的套路,就是对数据进行归一化,让连续数据的值位于0和1之间。对于x和y而言,这相对比较容易,毕竟x和y是物体的中心位置,既然物体的中心位置在这个grid之中,那么只要让真实的x除以grid的宽度,让真实的y除以grid的高度就可以了。但是h和w就不能这么做了,因为一个物体很可能远大于grid的大小,预测物体的高和宽很可能大于bounding box的高和宽,这样w除以bounding box的宽度,h除以bounding box的高度依旧不在0和1之间。解决方法是让w除以整张图片的宽度,h除以整张图片的高度。
4、损失函数
YOLO的损失函数由三个部分组成:坐标损失、置信度损失和类别损失。
坐标损失是指预测框与真实框之间的位置差异。对于每个预测框,计算其与真实框的重心坐标和宽高之差的平方和,然后取平方根得到每个预测框的坐标损失。
置信度损失是指预测框与真实框之间的匹配程度。对于每个预测框,计算其与真实框的交并比,并根据交并比的值确定该预测框的置信度损失。如果预测框与真实框不匹配,则置信度损失较大;如果预测框与真实框匹配,则置信度损失较小。
类别损失是指预测框中是否包含目标物体的类别信息。对于每个预测框,计算其与真实框的交并比,并根据交并比的值确定该预测框的类别损失。如果预测框中包含目标物体,则类别损失较小;如果预测框中不包含目标物体,则类别损失较大。
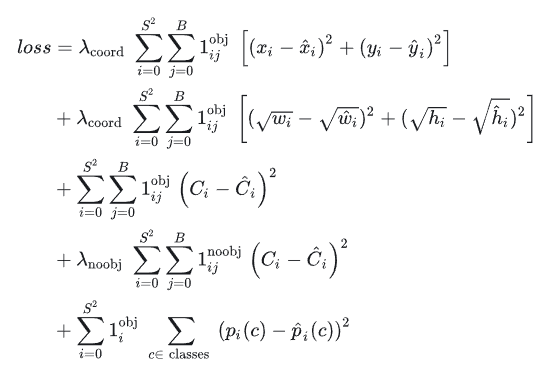
总结
本周的文献阅读,具有运动模糊的大规模场景的混合神经绘制,了解移动运动模糊的神经辐射场中的问题,以及了解文中提出的视点依赖归一化方法的工作原理。在这阅读的过程中充满着许多的疑惑,也多次翻阅其他文献及网页解读才大概了解,希望未来以此打下基础对相关知识能学习地更好。此外还学习了解了YOLO模型,了解其大致的工作原理,开始学习MMdetection的相关代码知识,从整个BackBone、Neck、Head框架开始学习。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Mybatis-Executor执行器介绍
- 全国(山东、安徽)职业技能大赛--信息安全管理与评估大赛题目+答案讲解——操作系统取证
- word写标书的疑难杂症总结
- Linux内嵌汇编
- 数据可视化能为我们带来哪些好处?
- 【数据库】第三章 MySQL库表操作
- AI元素深化人类发展之路:挑战与趋势
- Python高级用法:描述符(descriptor)
- JAVA中的BigInteger和BigDecimal
- 梯度提升机(Gradient Boosting Machines,GBM)