d2l动手学深度学习】 Lesson 13 Dropout层 老板随机丢掉一些做项目的程序员?,项目的效果会更好!(bushi)
1. 什么是Dropout
老板随机丢掉一些做项目的程序员🧑?💻,项目的效果会更好!
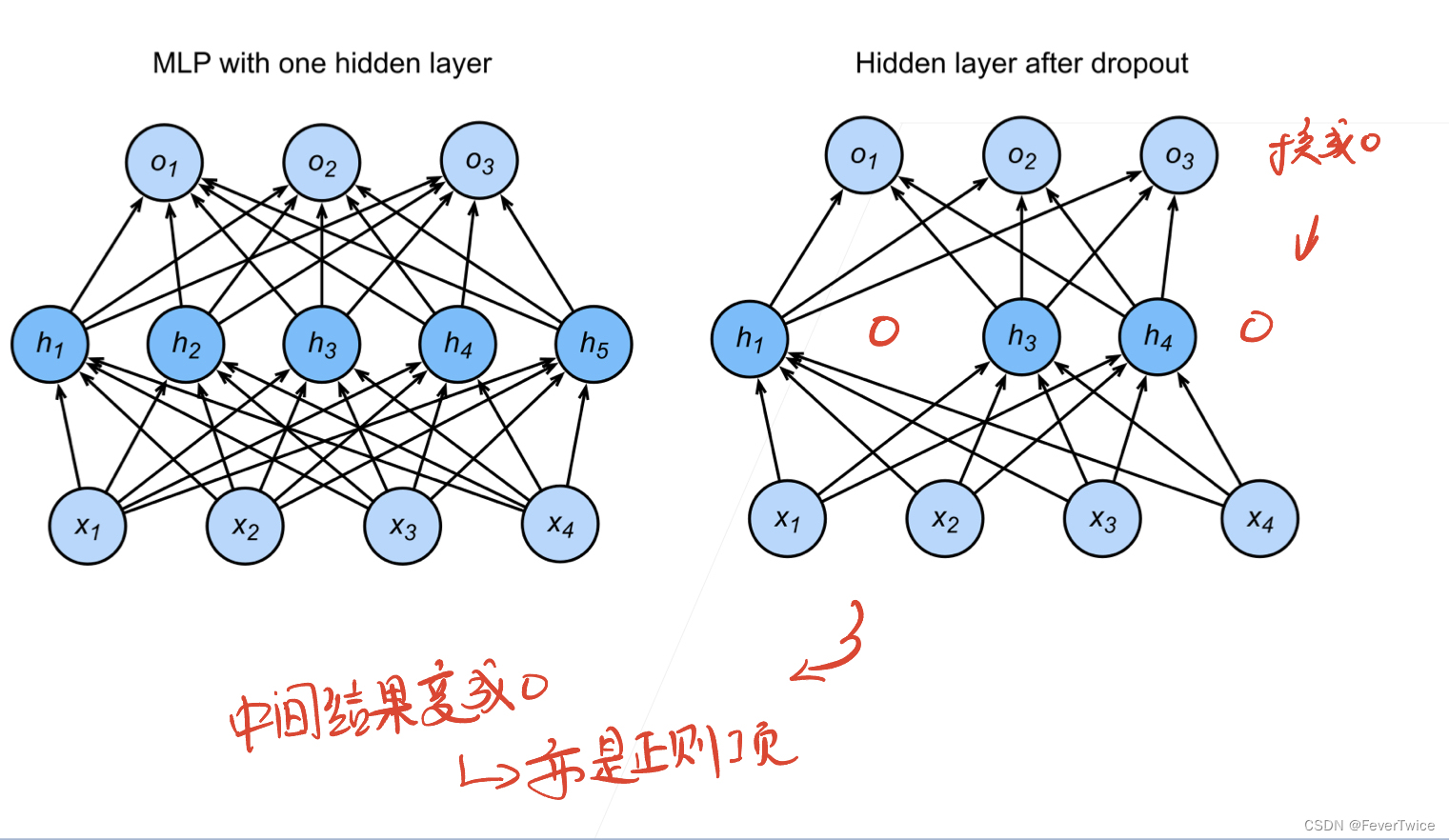
Dropout,顾名思义,就是丢弃,是在多层感知机(MLP)中经常用到的一种用于防止过拟合的一种训练技巧,如上图所示,就是在中间层将一些神经元变为0,然后输出
需要注意的是:在实作中并不会像上面这张图片这样直接删除神经元,而是通过生成一个含有0的Mask去和原来输入的结果作点积(维持输入形状不改变,被去掉的神经元对应的位置乘以0)
李沐老师还提到,Dropout也可以看成是另一种形式的正则化方法(Regulation),也可以用来防止模型过拟合
2. 代码实现(不用torch)
def dropout_layer(X, dropout):
# input, dropout rate
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(X) # 等于1变全0了 全丢了
if dropout == 0:
return X
# 比较得到布尔矩阵
mask = (torch.randn(X.shape) > dropout).float()
# 做矩阵乘法比使用数组索引index的运算速度快 X[mask] = 0
return mask * X /(1.0 - dropout)
3. 代码实现(使用torch)
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
模型结构
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=256, bias=True)
(2): ReLU()
(3): Dropout(p=0.0, inplace=False)
(4): Linear(in_features=256, out_features=256, bias=True)
(5): ReLU()
(6): Dropout(p=0.0, inplace=False)
(7): Linear(in_features=256, out_features=10, bias=True)
)
3. 调节实验
老师的代码主要用到了两个Dropout层,因此在模型中对应两个dropout rate,👇下面我们主要对者两个参数进行调节并观察对应的实验结果。dropout rate 后面将简写为(DR)
??注意!!:在运行代码时候,记得修改loss = nn.CrossEntropyLoss(reduction='none'),里面reduction,不然显示不出来loss!
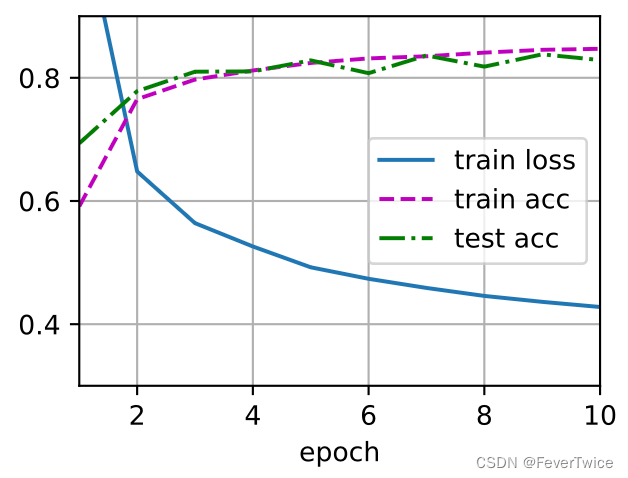
3.1 老师上课所设置的dropout1, dropout2 = 0.2, 0.5
动手实现版
简介torch版
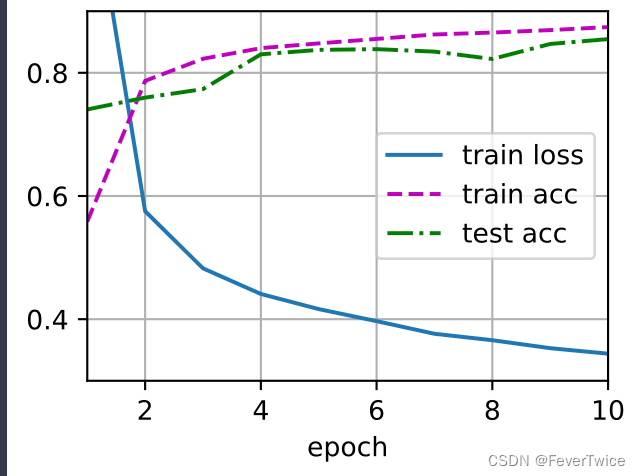
两种版本的实现的训练效果都差不多(这里假设没有其他优化计算的因素影响模型最后的训练效果),接下来我们就用简洁Torch版本来讨论。
3.2 dropout1, dropout2 = 0, 0
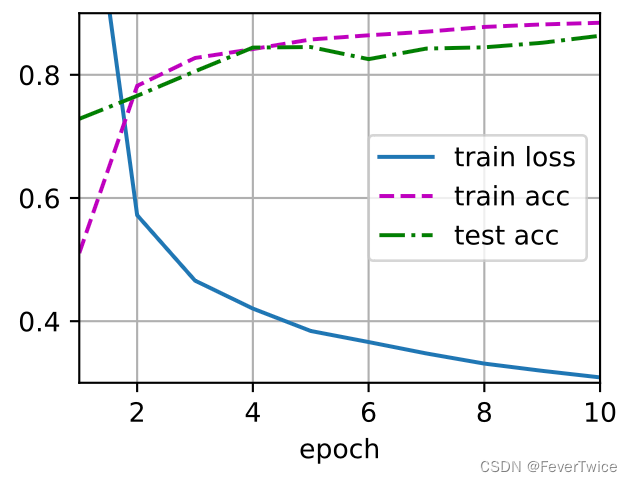
不用dropout的模型准确率反而上升了?
弹幕里面说是因为有可能模型是过拟合的,因为这里的Loss变的非常小
李沐老师说,现在256是一个很大的模型(对于我们这个小的MNIST数据集来说
3.3 dropout1, dropout2 = 1, 1(全部扔掉?🤔)
报错🙅,这个是运行不了的
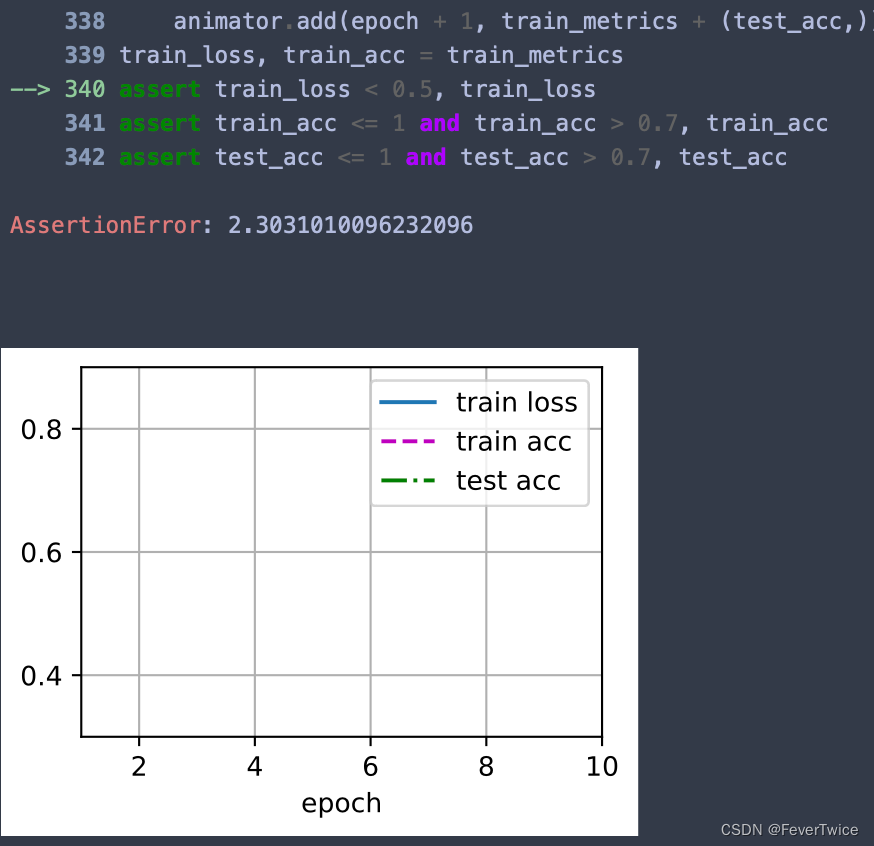
3.4 dropout1, dropout2 = 0.9, 0.9(几乎全部扔掉?)
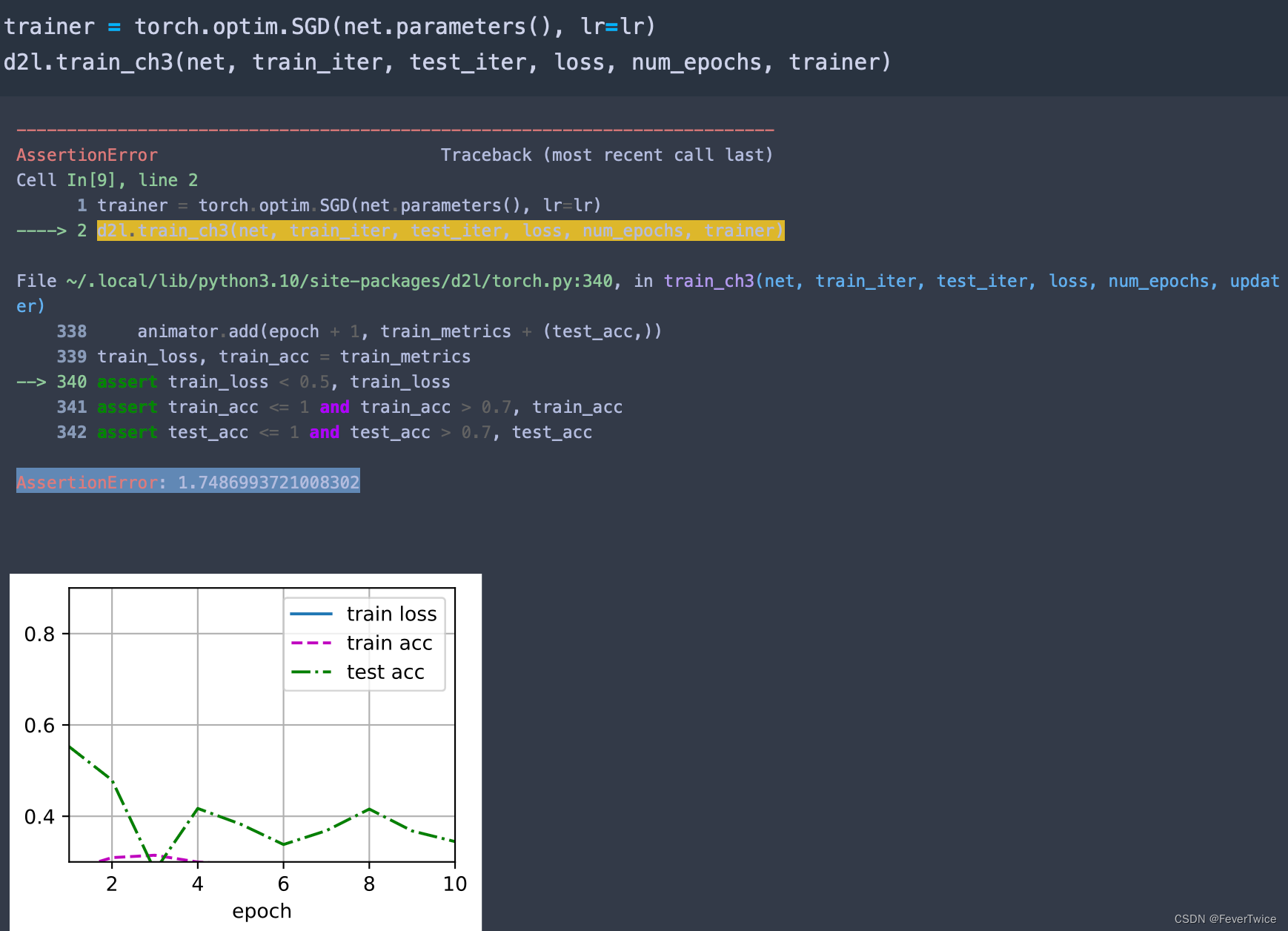
这个也会出现很问题
3.5 dropout1, dropout2 = 0.6, 0.8

3.5 dropout1, dropout2 = 0.8, 0.6
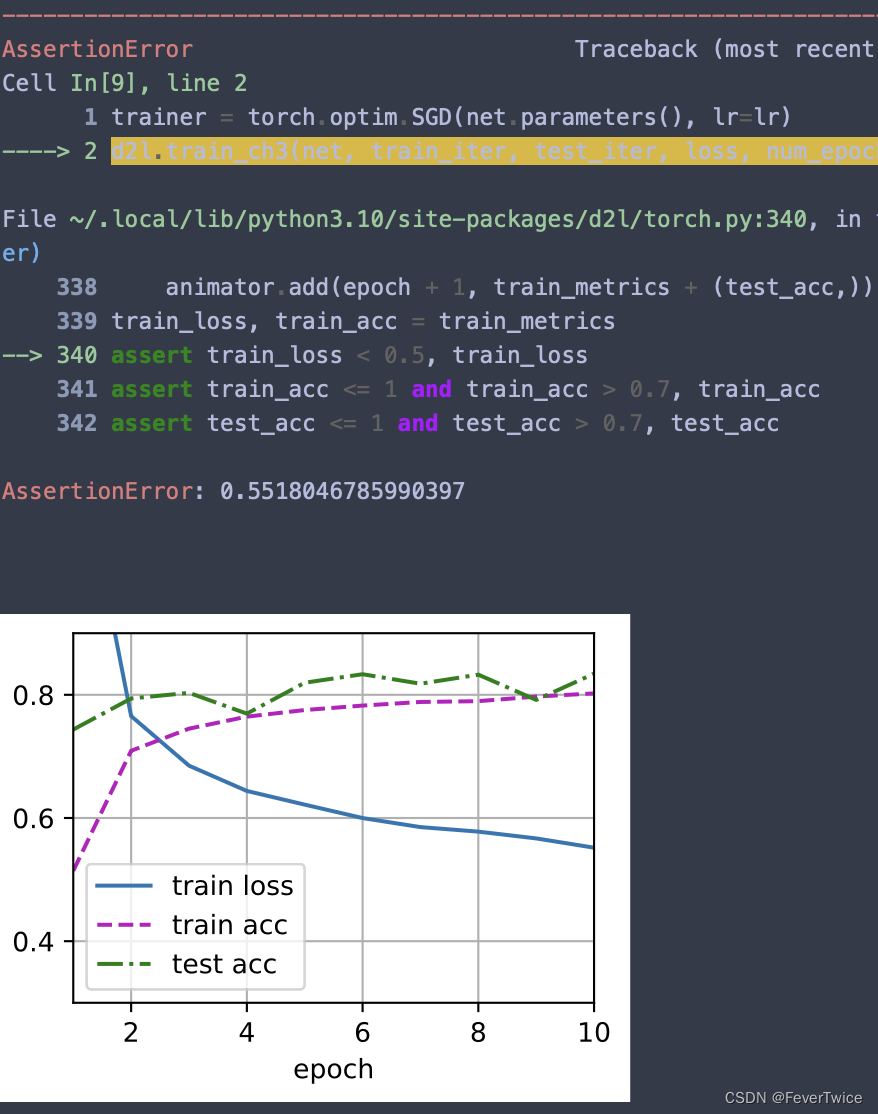
这里推测之前运行不了的原因也有可能是第一层的神经网络扔得太多了
综上所述,不管怎么调节dropout rate,还是比不过不用drop的策略,有可能模型还是不够大,应该出现overfitting的情况再使用dropout策略会好一点?
4. 整理一些有趣的Q&A 🤔
dropout 随机为0?
- 在求梯度时,设置随机为0,在BackProp的时候对应的梯度也是0,所以为啥Hinton说Dropout更像是在训练的过程中,将一些小网络逐一拿出来(不同的子网络),将各个子网络完成训练以后再融和在一起
理解dropout
- DR太小了,和太大了都不合适,太小没有作用,相反,太大就变成限制模型参数拟合的性能发挥 没有正确性🙆可言,一般就只有正确率
- 在作模型推理的时候,不需要使用Drop,因为不会再改变模型参数,如果用也可以,就会引入一些随机性,需要多算几遍,预测会丢掉东西,第一次是猫🐱,第二次可能就是狗🐶
- Drop在MLP全连接层用的比较多,但是weight decay则全部都在用,包括CNN,RNN这些
可重复性问题
- 神经网络训练的可重复性确实是一个问题,不过可以通过把random seed设定
- 但是李沐老师提到一个问题🙋,就是使用加速?CUDA中的Cudnn的话可能会导致计算结果不能🔁重复,这是因为并行计算的加法问题,100个数相加的先后顺序不同的话,得到的结果也会不同(精度不够),想重复的话需要固定住CuDNN
- 随机性会使得整个神经网络的收敛域变的平滑
- 每个batch丢进去之后,都要丢弃一次
- 老师,dropout每次随机选几个子网络,最后做平均的做法是不是类似于随机森林多决策树做投票的这种思想?(是的)
- 深度学习:我需要模型够强,但是我需要通过正则化来保证不要学偏
写在最后
各位看官,都看到这里了,麻烦动动手指头给博主来个点赞8,您的支持作者最大的创作动力哟!
才疏学浅,若有纰漏,恳请斧正
本文章仅用于各位作为学习交流之用,不作任何商业用途,若涉及版权问题请速与作者联系,望悉知
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【论文阅读】基于纤维束成像的新型微结构信息引导的监督对比学习,自动识别视网膜丘视觉通路
- ?枚举类型在技术派中的应用示例
- LabVIEW在燃气轮机发电机组励磁控制系统测试中的应用
- FPGA-Xilinx ZYNQ PS端实现SD卡文件数据读取-完整代码
- 帆软报表11.0.19增加postgres数据源方案
- 【JVM】一、认识JVM
- 【C语言】数据结构——带头双链表实例探究
- 【数据库设计和SQL基础语法】--用户权限管理--用户权限管理
- 十、Java中的main方法
- 双指针——复写零