StreamPark + PiflowX 打造新一代大数据计算处理平台
🚀 什么是PiflowX
PiFlow 是一个基于分布式计算框架 Spark 开发的大数据流水线系统。该系统将数据的采集、清洗、计算、存储等各个环节封装成组件,以所见即所得方式进行流水线配置。简单易用,功能强大。它具有如下特性:
-
简单易用:可视化配置流水线,实时监控流水线运行状态,查看日志;
-
功能强大:提供 100 + 的数据处理组件, 包括 Hadoop 、Spark、MLlib、Hive、Solr、Redis、MemCache、ElasticSearch、JDBC、MongoDB、HTTP、FTP、XML、CSV、JSON 等,同时集成了微生物领域的相关算法;
-
扩展性强:支持自定义开发数据处理组件;
-
性能优越:基于分布式计算引擎 Spark 开发。
Piflow架构图:
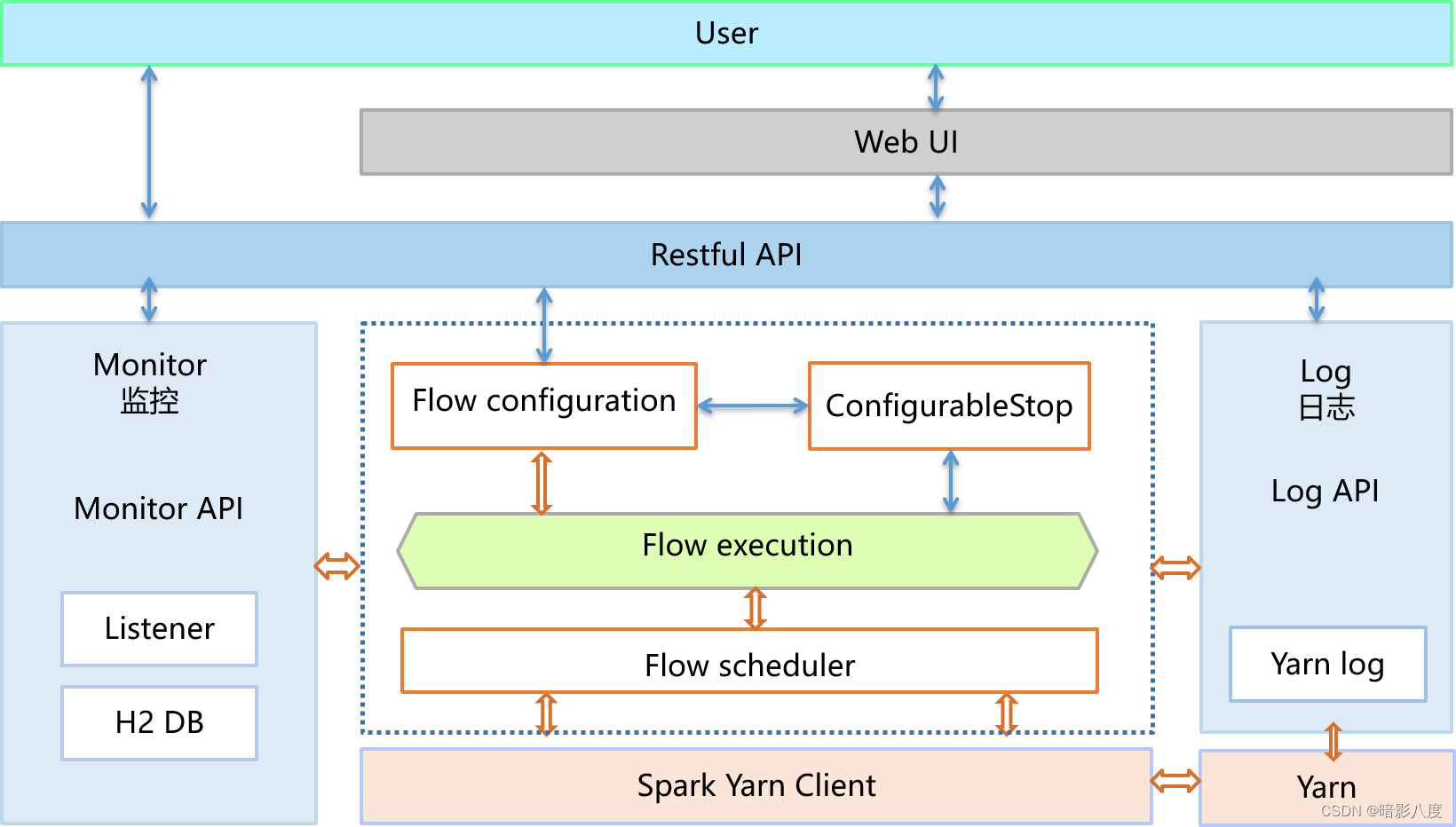
在实时化的大趋势下,Flink 已经成为实时计算行业的事实标准。我们看到,不光是阿里巴巴,国内外各个领域的头部厂商,都把 Flink 做为实时计算的技术底座,国内有字节跳动、腾讯、华为,国外有 Netflix、Uber 等等。

为了流水线处理系统支持flink引擎,PiflowX应运而生,PiflowX基于Piflow二次开发(在此,向piflow作者和全体开发人员致敬!!!),对核心框架进行了重构,使算子组件接口抽象与计算引擎完全解耦,组件实现侧则完全由spark或flink API实现。采用这种架构虽然实现代价高,后期维护困难,但好处也是显而易见的,首先,组件完全由引擎自身API构成,天然可插拔,天然支持多版本。其次,可最大化和自由的使用引擎各自的特性,不会因为为了统一实现而不得不舍弃某些高级特性或功能。最后不会因为数据抽象和转换而造成性能损失,毕竟PilfowX是一款大数据处理系统!
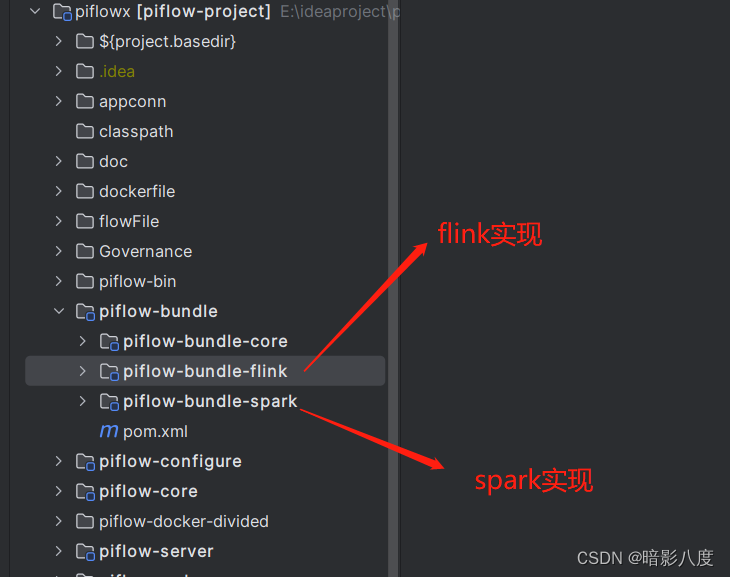
下图是改造后spark和flink分别实现的组件算子模块。
PiflowX架构图:
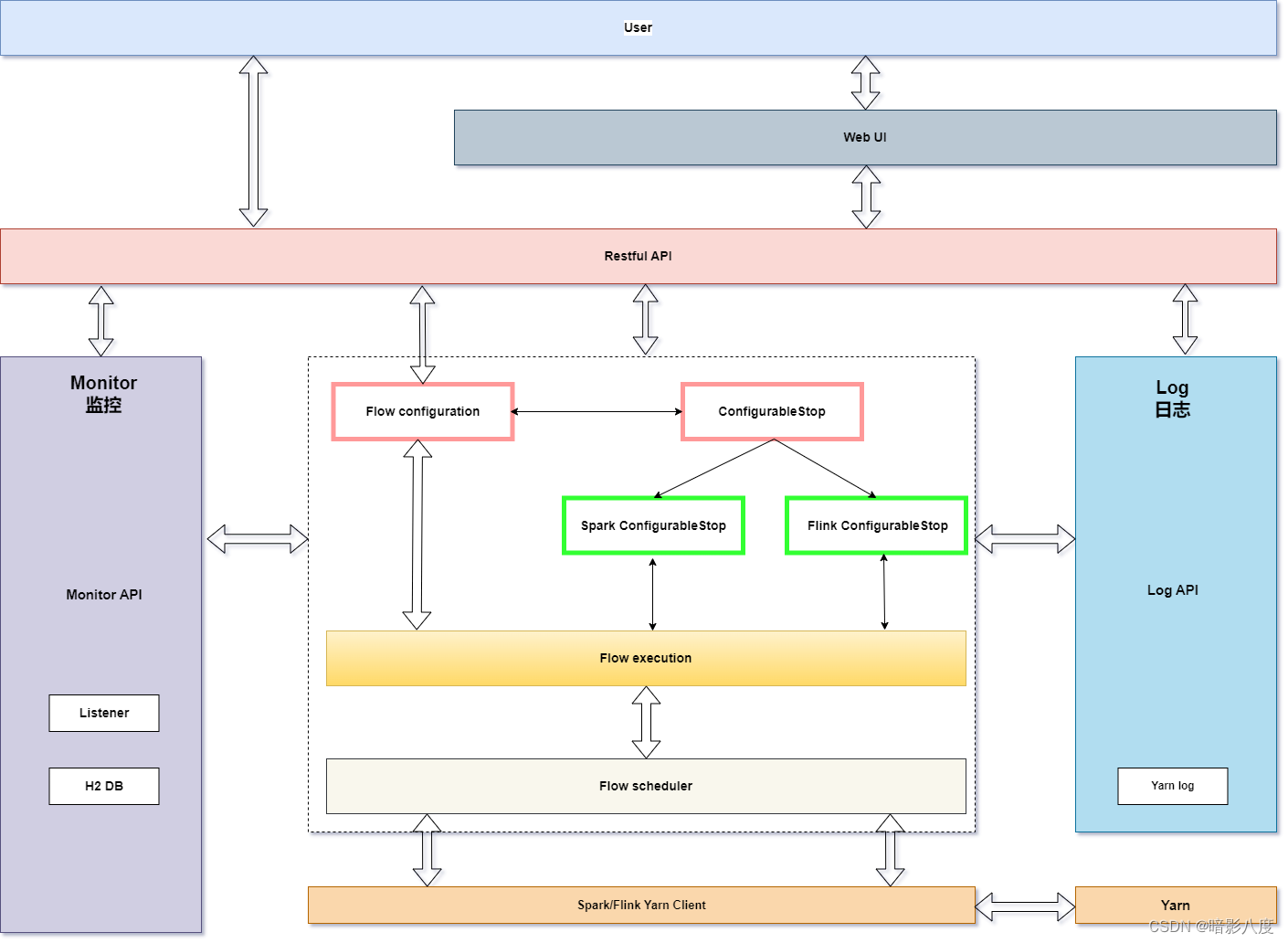
任务侧添加了引擎类型(engineType)字段,这样便可识别底层实现组件。目前flink实现了大约40种组件,spark则是piflow原生实现的100+种组件。
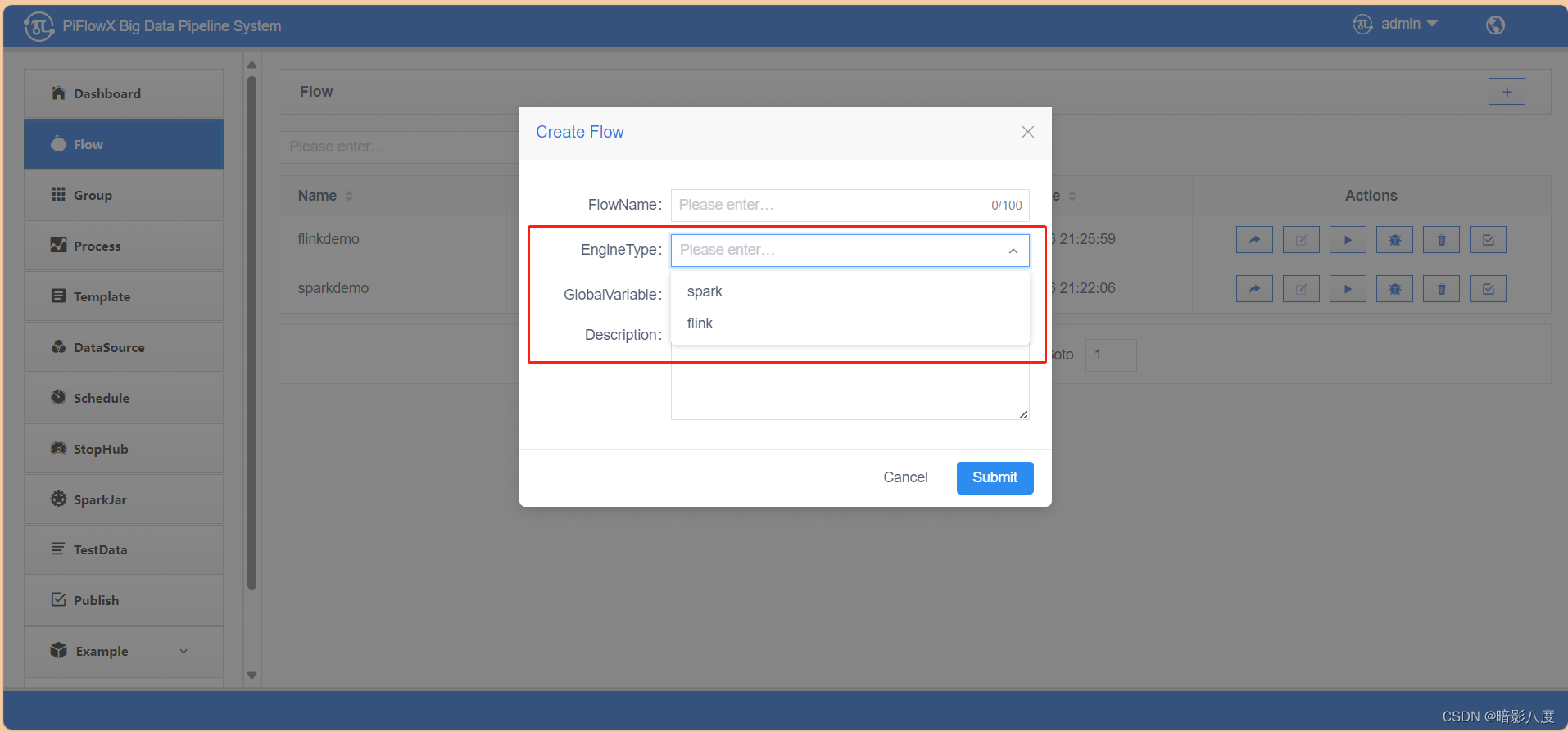
flink类型任务:
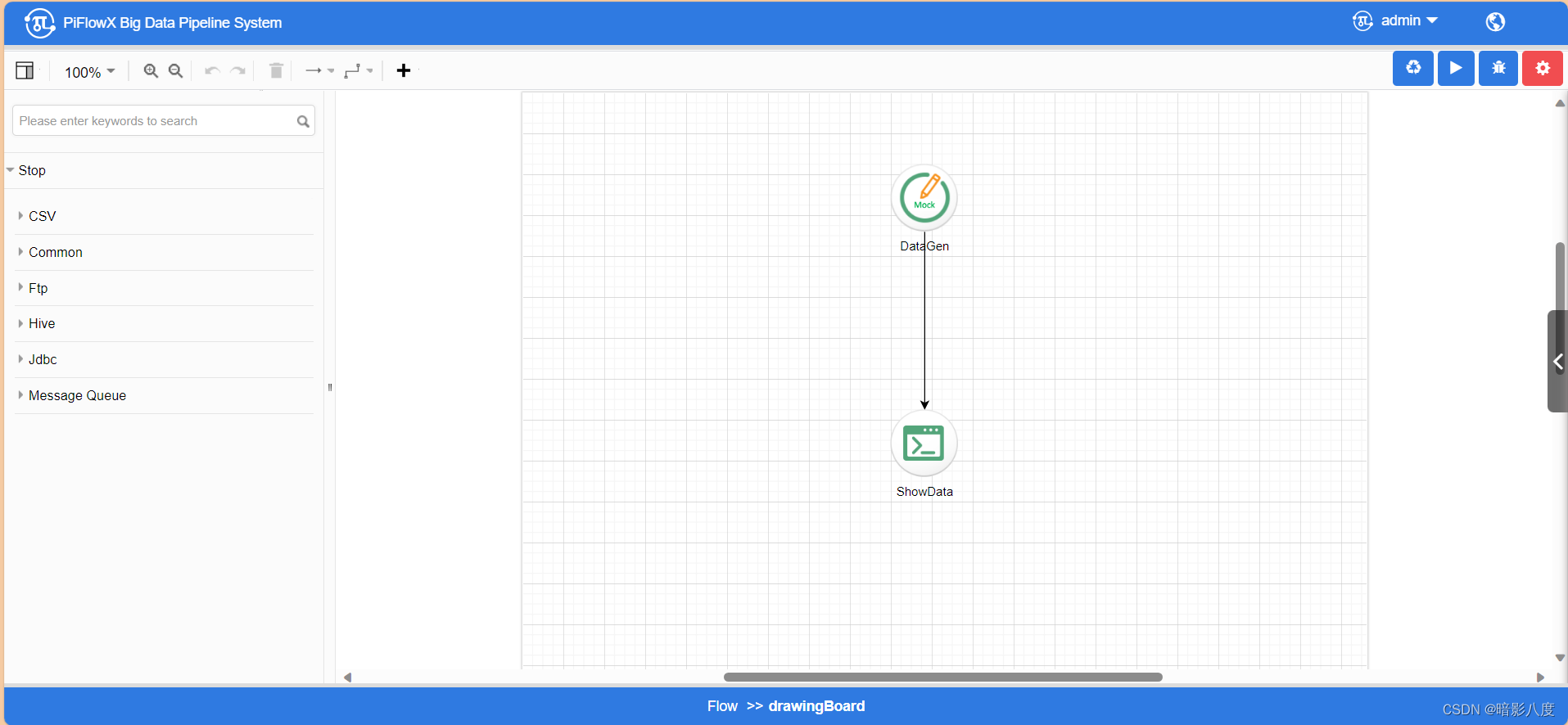
spark类型任务:
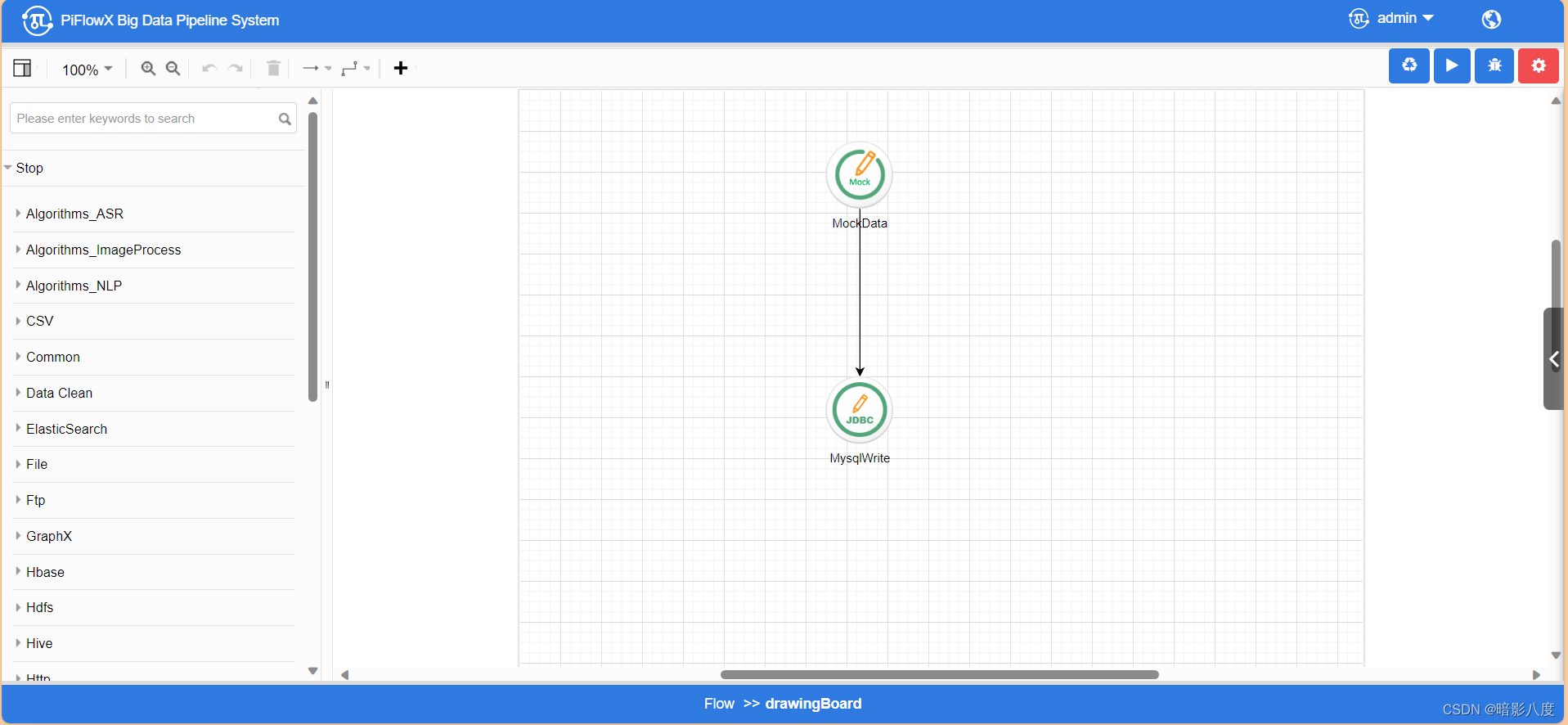
PiflowX任务运行DEMO:
67bf2a930f51a536212ba5c442271bfb
在二开的过程中,也发现了piflow存在的一些问题:
-
由于piflow原生是基于spark的,现在增加了flink的实现,flink工作模式众多,因此任务运维这块工作量和难度都比较大!!!
-
piflow webui美观度上还是欠缺一点(纯属个人意见,没有别的意思,望piflow各位开发者见谅),技术栈基于vue2,组件实现上代码量偏大。如果在原有基础上迁移到vue3和其他ui框架上,工作量无疑是个天文数字!!!
基于以上两点,便考虑在开源产品中寻找一款基于flink开发的产品,UI美观又大气的产品进行整合。不出意外的很轻松的找到了StreamPark。
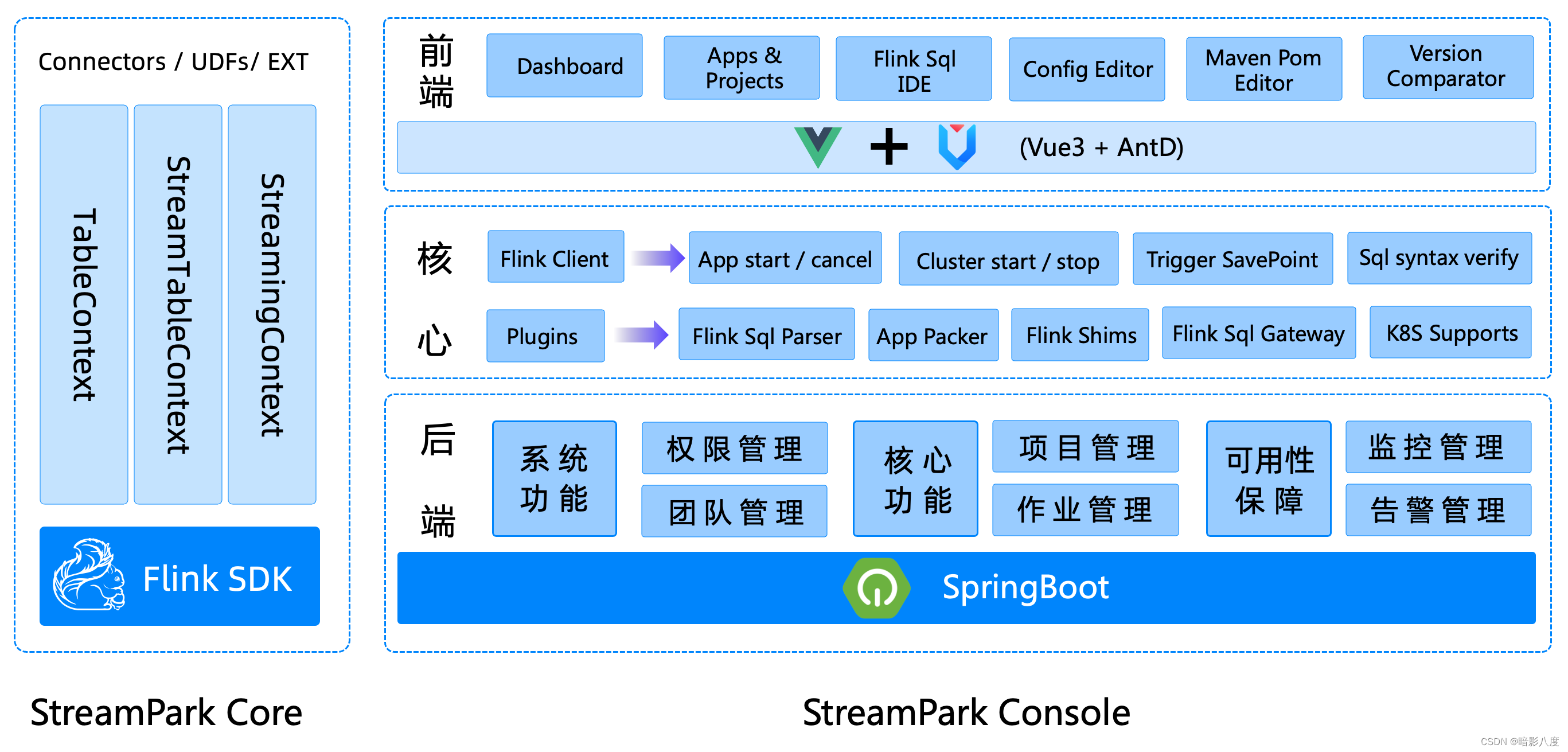
🚀 什么是StreamPark?
实时即未来,在实时处理流域 Apache Spark 和 Apache Flink 是一个伟大的进步,尤其是 Apache Flink 被普遍认为是下一代大数据流计算引擎, 我们在使用 Flink & Spark 时发现从编程模型, 启动配置到运维管理都有很多可以抽象共用的地方, 我们将一些好的经验固化下来并结合业内的最佳实践, 通过不断努力诞生了今天的框架 —— StreamPark, 项目的初衷是 —— 让流处理更简单, 使用 StreamPark 开发流处理作业, 可以极大降低学习成本和开发门槛, 让开发者只用关心最核心的业务,StreamPark 规范了项目的配置,鼓励函数式编程,定义了最佳的编程方式,提供了一系列开箱即用的Connectors,标准化了配置、开发、测试、部署、监控、运维的整个过程, 提供了scala和java两套 Api, 并且提供了一个一站式的流处理作业开发管理平台, 从流处理作业开发到上线全生命周期都 做了支持, 是一个一站式的流处理计算平台.
简言之,Streampark是流处理极速开发框架,支持流批一体 & 湖仓一体的云原生平台,一站式流处理计算平台。
目前,PiflowX后端已全部整合到streampark-console-service模块,前端流水线相关功能也基本迁移。
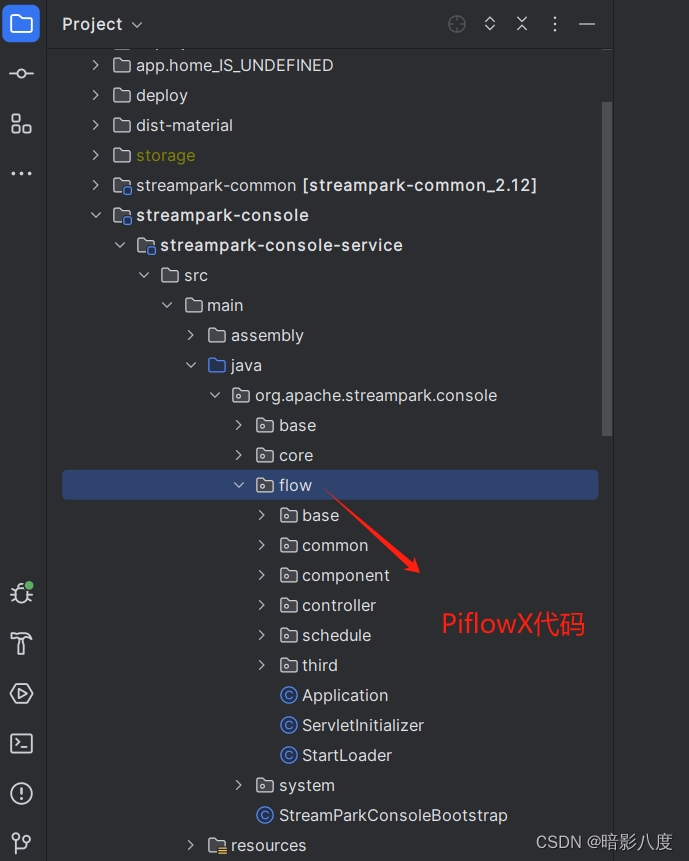
以下是整合后的相关图片:
登录页
首页
流水线首页
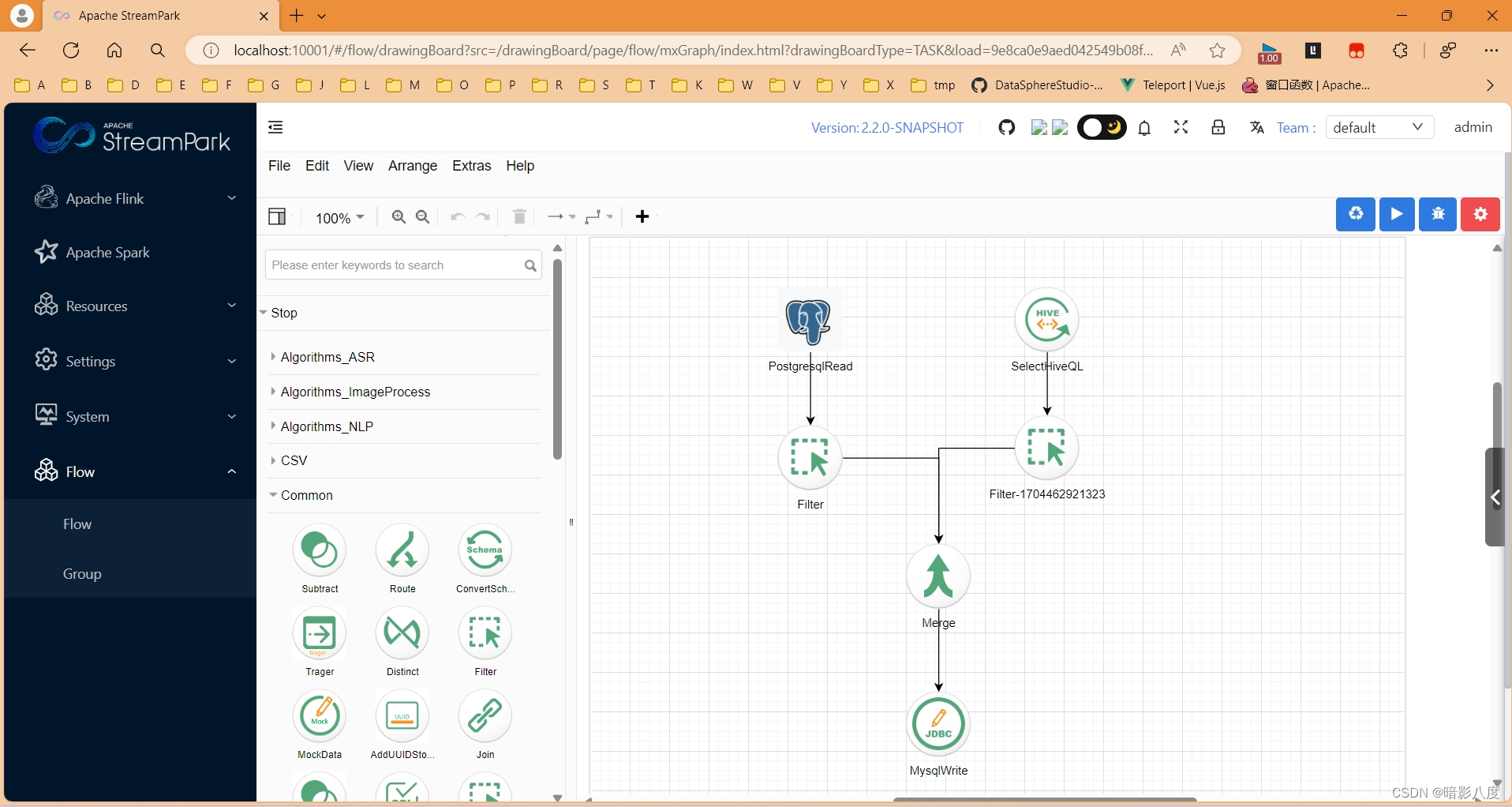
创建flink类型任务
设计flink类型流水线
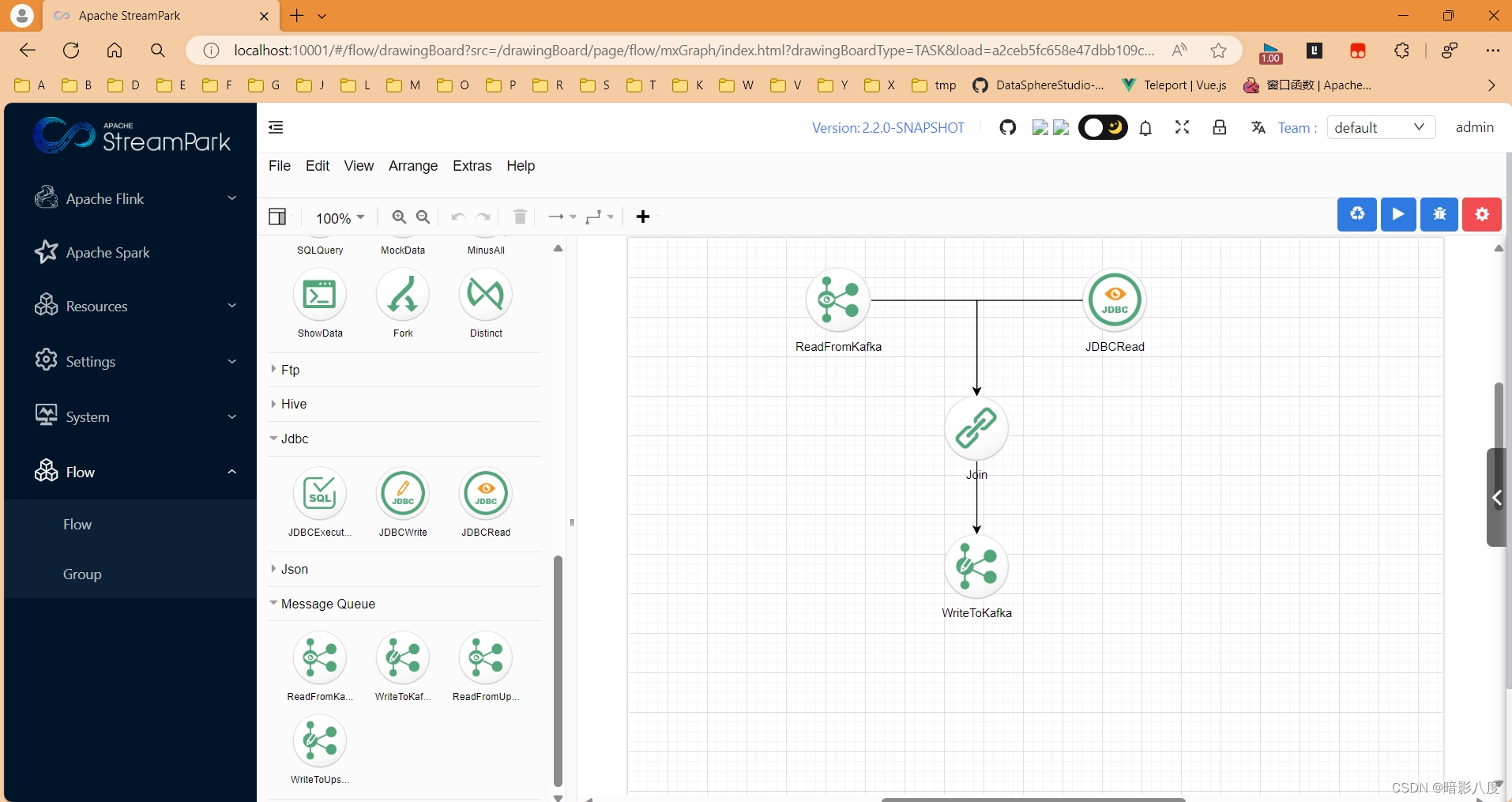
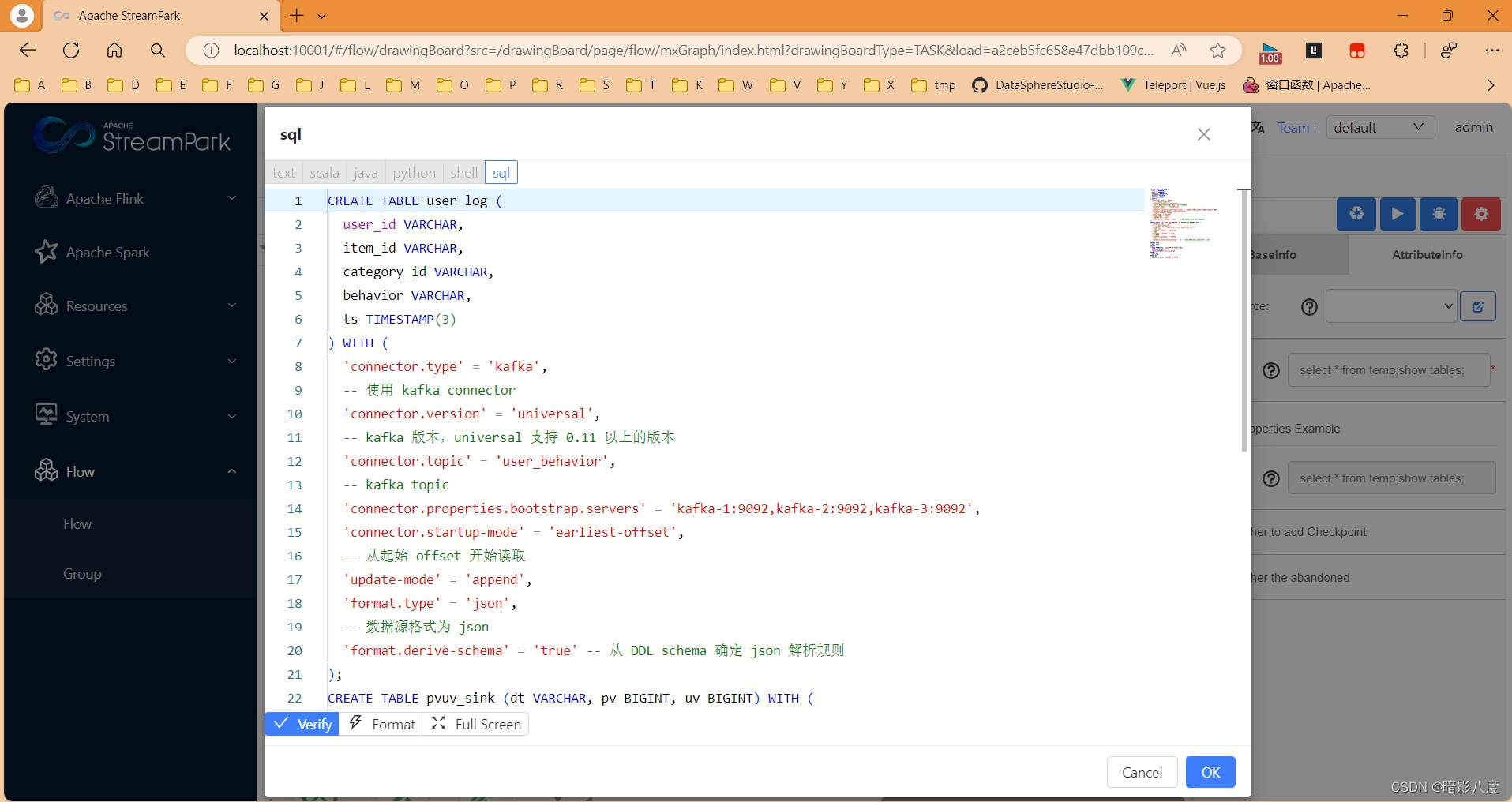
当然,纯flinksql组件算子已经实现,可以直接在节点上编写flinksql脚本
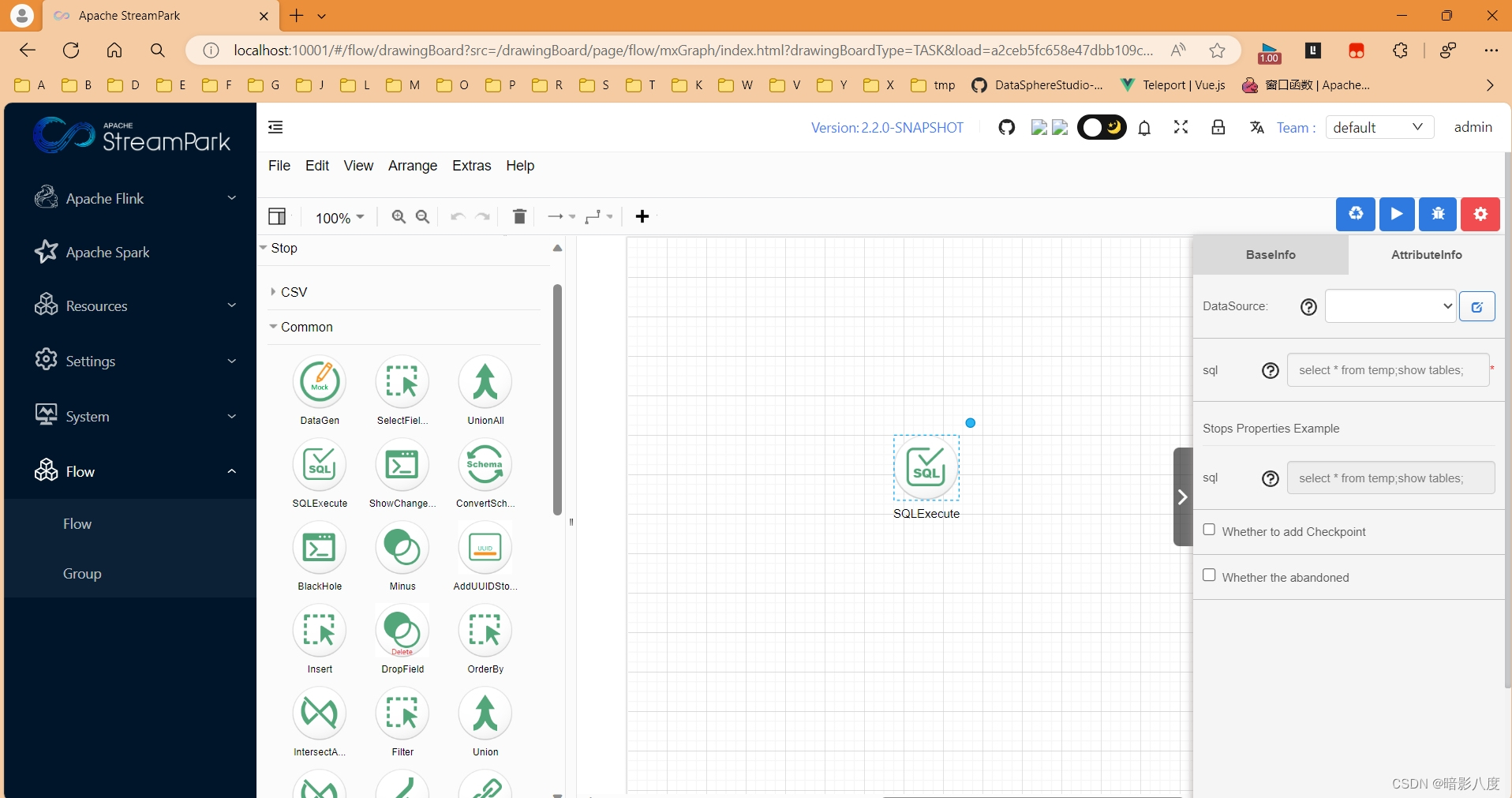
创建spark类型任务
设计spark类型流水线
目前整合进度刚刚开始,二者功能完全割裂,接下来,还需继续努力,争取早日实现无缝连接,完美糅合,打造新一代大数据计算处理平台!!!
参考资料:
cas-bigdatalab/piflow: πflow is a big data flow engine with spark support (github.com)
框架介绍 | Apache StreamPark (incubating)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 调用微信扫一扫功能
- 巴菲特又有新动作,投资版图再更新
- 小程序中实现多个页面中顶部固定高为50px,底部固定高为50px,中间列表为所在页面剩余高度,且列表内容超出高度时可以滑动。
- golang实现rpc方法一:使用net/rpc库【不能跨平台】
- VMware虚拟机安装小tips
- Ubuntu系统如何安装和卸载CUDA和CUDNN
- docker 安装可视化工具 Protainer 以及 汉化
- 安装Paddlehub报错
- maven依赖无法传递问题排查
- 最新ChatGPT网站源码,支持Midjourney绘画,GPT语音对话+GPT-4识图理解能力+ChatFile文档对话总结+DALL-E3文生图