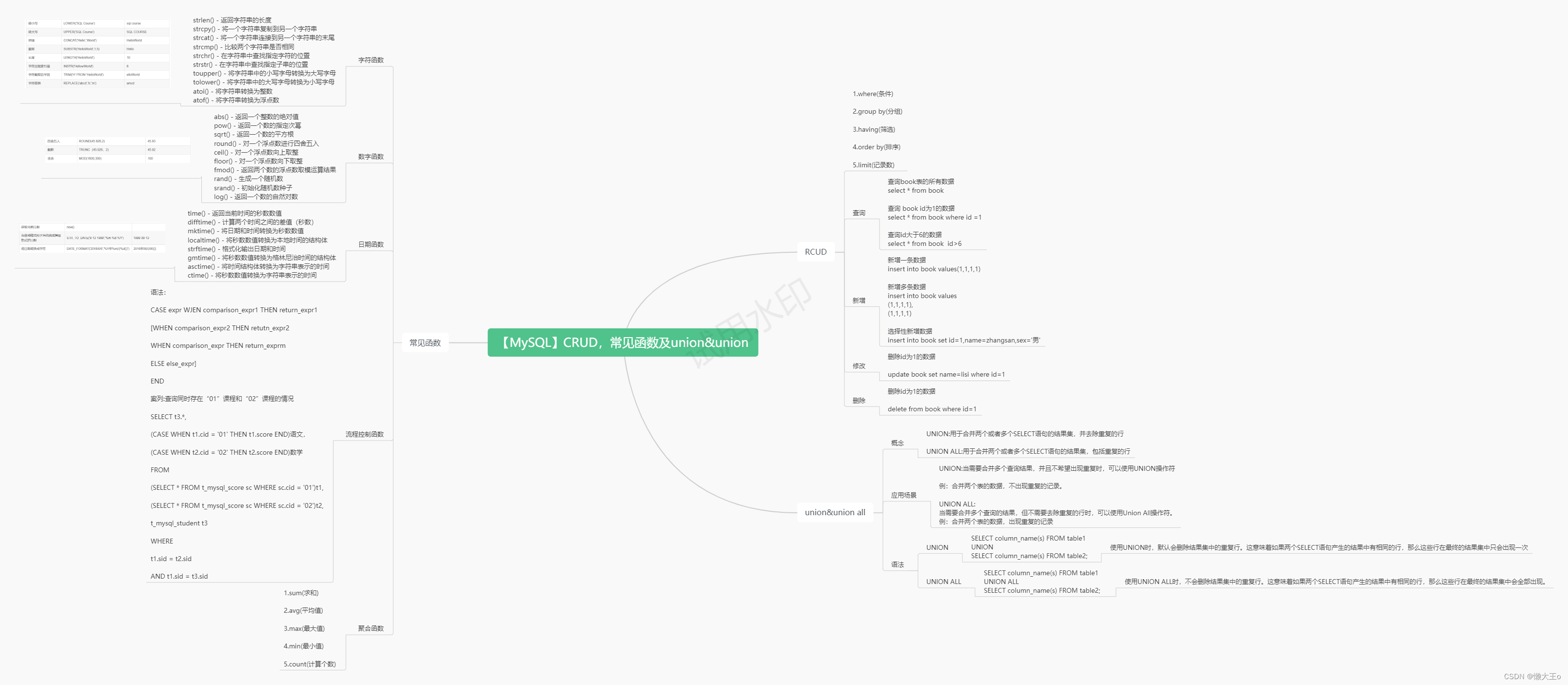
【MySQL】CRUD,常见函数及union&union
目录
CRUD
条件查询执行顺序
1.where(条件)
2.group by(分组)
3.having(筛选)
4.order by(排序)
5.limit(记录数)
?查询
查询book表的所有数据
select * from book?
?
查询 book id为1的数据
select * from book where id =1
?
查询id大于6的数据
select * from book ?id>6?
新增数据
新增一条数据
insert into book values(1,1,1,1)
?
新增多条数据
insert into book values
(1,1,1,1),
(1,1,1,1)
?
选择性新增数据?
insert into book set id=1,name=zhangsan,sex='男'?
修改数据
删除id为1的数据
update book set name=lisi where id=1
删除数据
删除id为1的数据
delete from book where id=1
常见函数
字符函数
- strlen() - 返回字符串的长度
- strcpy() - 将一个字符串复制到另一个字符串
- strcat() - 将一个字符串连接到另一个字符串的末尾
- strcmp() - 比较两个字符串是否相同
- strchr() - 在字符串中查找指定字符的位置
- strstr() - 在字符串中查找指定子串的位置
- toupper() - 将字符串中的小写字母转换为大写字母
- tolower() - 将字符串中的大写字母转换为小写字母
- atoi() - 将字符串转换为整数
- atof() - 将字符串转换为浮点数
| 转小写 | LOWER('SQL Course') | sql course |
| 转大写 | UPPER('SQL Course') | SQL COURSE |
| 拼接 | CONCAT('Hello','World') | HelloWorld |
| 截取 | SUBSTR('HelloWorld',1,5) | Hello |
| 长度 | LENGTH('HelloWorld') | 10 |
| 字符出现索引值 | INSTR('HellowWorld') | 6 |
| 字符截取后半段 | TRIM('H' FROM 'HelloWorld') | elloWorld |
| 字符替换 | REPLACE('abcd','b','m') | amcd |
?数字函数
- abs() - 返回一个整数的绝对值
- pow() - 返回一个数的指定次幂
- sqrt() - 返回一个数的平方根
- round() - 对一个浮点数进行四舍五入
- ceil() - 对一个浮点数向上取整
- floor() - 对一个浮点数向下取整
- fmod() - 返回两个数的浮点数取模运算结果
- rand() - 生成一个随机数
- srand() - 初始化随机数种子
- log() - 返回一个数的自然对数
| 四舍五入 | ROUND(45.926,2) | 45.93 |
| 截断 | TRUNC(45.926,2) | 45.92 |
| 求余 | MOD(1600,300) | 100 |
?日期函数
- time() - 返回当前时间的秒数数值
- difftime() - 计算两个时间之间的差值(秒数)
- mktime() - 将日期和时间转换为秒数数值
- localtime() - 将秒数数值转换为本地时间的结构体
- strftime() - 格式化输出日期和时间
- gmtime() - 将秒数数值转换为格林尼治时间的结构体
- asctime() - 将时间结构体转换为字符串表示的时间
- ctime() - 将秒数数值转换为字符串表示的时间
| 获取当前日期 | now() | |
| 将日期格式的字符转换成指定格式的日期 | STR_TO_DATE('9-13-1999','%m-%d-%Y') | 1999-09-13 |
| 将日期转换成字符 | DATE_FORMAT('2018/6/6','%Y年%m月%d日') | 2018年06月06日 |
流程控制函数
语法:
CASE expr WJEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN retutn_expr2
WHEN comparison_expr THEN return_exprm
ELSE else_expr]
END
案列:查询同时存在“01”课程和“02”课程的情况
SELECT t3.*,
(CASE WHEN t1.cid = '01' THEN t1.score END)语文,
(CASE WHEN t2.cid = '02' THEN t2.score END)数学
FROM
(SELECT * FROM t_mysql_score sc WHERE sc.cid = '01')t1,
(SELECT * FROM t_mysql_score sc WHERE sc.cid = '02')t2,
t_mysql_student t3
WHERE
t1.sid = t2.sid
AND t1.sid = t3.sid
?聚合函数
1.sum(求和)
2.avg(平均值)
3.max(最大值)
4.min(最小值)
5.count(计算个数)
?union&union all
概念
UNION:用于合并两个或者多个SELECT语句的结果集,并去除重复的行
UNION ALL:用于合并两个或者多个SELECT语句的结果集,包括重复的行
?应用场景
UNION:当需要合并多个查询结果,并且不希望出现重复时,可以使用UNION操作符
例:合并两个表的数据,不出现重复的记录。
UNION ALL:
当需要合并多个查询的结果,但不需要去除重复的行时,可以使用Union All操作符。
例:合并两个表的数据,出现重复的记录
?语法
UNION
SELECT column_name(s) FROM table1?
UNION?
SELECT column_name(s) FROM table2;
使用UNION时,默认会删除结果集中的重复行。这意味着如果两个SELECT语句产生的结果中有相同的行,那么这些行在最终的结果集中只会出现一次
UNION ALL
SELECT column_name(s) FROM table1 ?
UNION ALL ?
SELECT column_name(s) FROM table2;
使用UNION ALL时,不会删除结果集中的重复行。这意味着如果两个SELECT语句产生的结果中有相同的行,那么这些行在最终的结果集中会全部出现。?
思维导图
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- mysql数据库清除自增id并从1开始(详细一次成功)
- Linux|centos7操作系统|无线WiFi的命令行配置---wpa_supplicant详解
- Golang 使用 AST 获取方法和参数名以及应用举例
- 043、循环神经网络
- Arrays.asList()方法:陷阱与解决之道
- 企业最新几种好用的数据同步工具对比
- vue前端开发,如何正确安装node.js的开发脚手架,yarn
- 好家长期刊投稿方式
- OpenVINS学习6——VioManagerHelper.cpp,VioManagerOptions.h学习与注释
- Java Math类库 | 算法实用总结 | 蓝桥杯java组备赛