神经网络:表述(Neural Networks: Representation)
1.非线性假设
无论是线性回归还是逻辑回归,当特征太多时,计算的负荷会非常大。
案例:
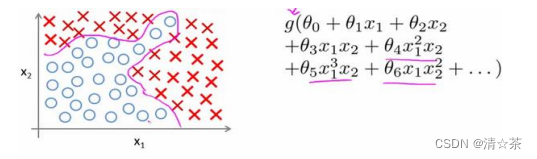
假设我们有非常多的特征,例如大于 100 个变量,我们希望用这 100 个特征来构建一个非线性的多项式模型,结果将是数量非常惊人的特征组合,即便我们只采用两两特征的组合(𝑥1𝑥2 +𝑥1𝑥3 + 𝑥1𝑥4+. . . +𝑥2𝑥3 + 𝑥2𝑥4+. . . +𝑥99𝑥100),我们也会有接近 5000 个组合而成的特征。这对于一般的逻辑回归来说需要计算的特征太多了。
假使我们采用的都是 50x50 像素的小图片,并且我们将所有的像素视为特征,则会有
2500 个特征,如果我们要进一步将两两特征组合构成一个多项式模型,则会有约2500的平方/2个(接近 3 百万个)特征。普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们需要神经网络。
非线性假设是指在模型中存在非线性关系的假设。在机器学习中,许多算法都是基于线性关系的假设,即输入特征和输出目标之间存在线性关系。然而,在实际问题中,这种线性关系可能并不存在,或者非线性关系可能更为复杂和重要。
非线性假设的引入是为了解决线性模型无法很好地拟合非线性数据的问题。非线性模型能够更好地拟合数据,提高模型的预测精度和稳定性。
在机器学习中,有许多非线性模型可供选择,例如决策树、支持向量机、神经网络等。这些模型能够处理各种复杂的非线性关系,并且具有不同的优缺点和适用场景。
在实际应用中,需要根据具体问题和数据特征选择合适的非线性模型。在选择模型时,需要考虑模型的复杂度、可解释性、泛化能力等因素。同时,也需要对数据进行适当的预处理和特征选择,以提高模型的训练效果和预测精度。
2.神经元和大脑
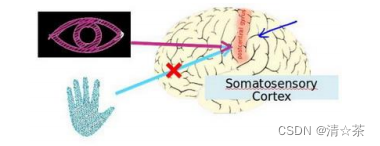
大脑的这一部分这一小片红色区域是你的听觉皮层,你现在正在理解我的话,这靠的是耳朵。耳朵接收到声音信号,并把声音信号传递给你的听觉皮层,正因如此,你才能明白我的话。
在吴恩达的课程中,机器学习中的神经网络可以被认为是受到人类大脑神经元网络的启发而设计的一种模型。神经网络是一种用于处理和学习数据的算法,其结构由多个人工神经元组成,这些神经元通过连接进行信息传递。
在机器学习中,神经网络的目标是通过学习输入数据和相应的输出之间的关系,来构建一个模型,从而能够进行预测和分类任务。神经网络通过多个层次的神经元组成,包括输入层、隐藏层和输出层。每个神经元接收来自上一层神经元的输入,并通过激活函数对输入进行处理,然后将结果传递给下一层神经元。通过调整神经元之间的连接权重,神经网络可以学习数据中的模式和特征。
与大脑相比,机器学习中的神经网络只是对大脑神经元网络的简化模型。尽管神经网络的设计灵感来自于大脑,但它并不完全模拟和复制大脑的功能和结构。然而,神经网络的训练和学习过程可以提供一种近似大脑学习的方式,因为它们可以通过调整连接权重来适应输入数据的模式和特征。
总的来说,神经网络是机器学习中一种常用且强大的模型,它使用多层次的人工神经元来学习数据的模式和特征。尽管受到大脑的启发,但神经网络只是对大脑的简化模型,并不能完全模拟和复制大脑的功能。
机器学习中的神经元和大脑与生物学中的神经元和大脑相似,但存在一些重要的区别。
在机器学习中,神经元通常被称为神经网络中的节点或单元,它们通过加权连接相互连接。每个神经元接收来自其他神经元的输入,并根据这些输入和相应的权重进行计算,产生输出信号。这个过程模拟了生物学中神经元的电化学信号传递过程。
与生物学中的大脑类似,机器学习中的神经网络也通过大量神经元的相互作用实现复杂的认知功能。然而,与实际的大脑不同,机器学习中的神经网络是静态的,即它们的结构和连接不会随时间改变。此外,机器学习中的神经网络通常比实际的大脑更简单,并且缺乏大脑的许多复杂结构和功能。
尽管存在这些差异,机器学习中的神经网络和生物学中的大脑在处理信息方面有许多相似之处。例如,两者都使用并行处理和分布式存储,通过学习不断优化其结构和功能。此外,两者都具有一定的容错性和自适应性,能够处理不完全或错误的信息,并从中学习和适应。
总之,机器学习中的神经元和大脑是模拟生物学中神经元和大脑的概念,它们在处理信息方面有许多相似之处。然而,由于机器学习和生物学的本质差异,两者在实现这些功能时的机制和结构存在显著差异。
3.模型表示1
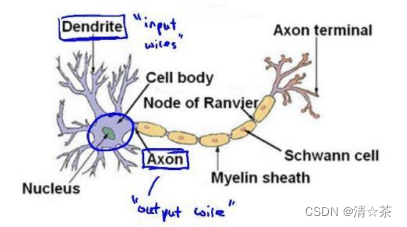
每一个神经元都可以被认为是一个处理单元/神经核(processing unit/Nucleus),它含有许多输入/树突(input/Dendrite),并且有一个输出/轴突(output/Axon)。神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。
神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输出,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被成为权重(weight)。
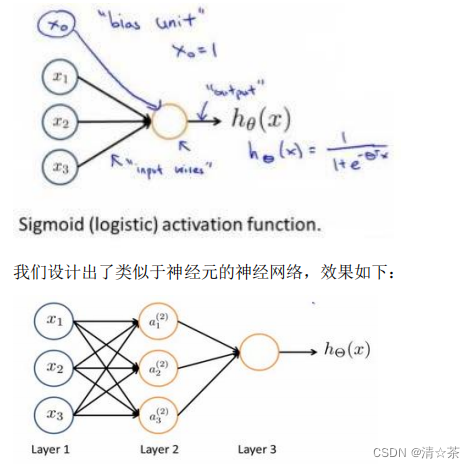
其中𝑥1, 𝑥2, 𝑥3是输入单元(input units),我们将原始数据输入给它们。
𝑎1, 𝑎2, 𝑎3是中间单元,它们负责将数据进行处理,然后呈递到下一层。
最后是输出单元,它负责计算?𝜃(𝑥)。
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。下图为一个 3 层的神经网络,第一层成为输入层(Input Layer),最后一层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers)。我们为每一层都增加一个偏差单位(bias unit):
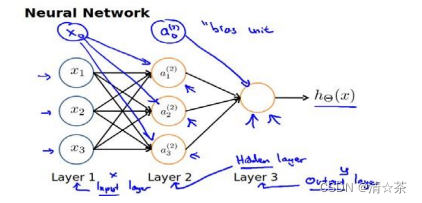

上面进行的讨论中只是将特征矩阵中的一行(一个训练实例)喂给了神经网络,我们需要将整个训练集都喂给我们的神经网络算法来学习模型。
我们可以知道:每一个𝑎都是由上一层所有的𝑥和每一个𝑥所对应的决定的。
(我们把这样从左到右的算法称为前向传播算法( FORWARD PROPAGATION ))
把𝑥, 𝜃, 𝑎 分别用矩阵表示,我们可以得到𝜃 ? 𝑋 = 𝑎 :
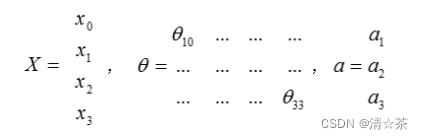
4.模型表示2
前向传播算法相对于使用循环来编码,利用向量化的方法会使得计算更
为简便。以上面的神经网络为例,试着计算第二层的值:

神经网络的工作原理,把左半部分先遮住:
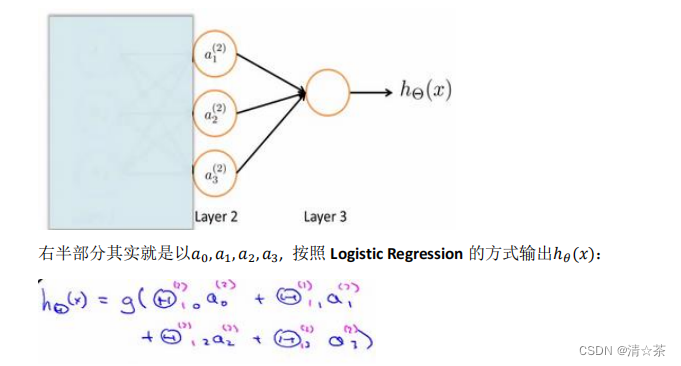
其实神经网络就像是逻辑回归(将结果限制在0到1之间,从而表示为概率),只不过我们把 逻辑回归(logistic regression) 中的输入向量
![[𝑥1 ~ 𝑥3
] 变成了中间层的[𝑎1
(2)
~ 𝑎3
(2)
], 即:](https://img-blog.csdnimg.cn/direct/8c6b36305d06418aac3af643cefa311b.png)
把𝑎0, 𝑎1, 𝑎2, 𝑎3看成更为高级的特征值,也就是𝑥0, 𝑥1, 𝑥2, 𝑥3的进化体,并且它们是由 𝑥与决定的,因为是梯度下降的,所以𝑎是变化的,并且变得越来越厉害,所以这些更高级的特征值远比仅仅将 𝑥次方厉害,也能更好的预测新数据。这就是神经网络相比于逻辑回归和线性回归的优势。
5.特征和直观理解1
在神经网络中,原始特征只是输入层,
在我们上面三层的神经网络例子中,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层中的原始特征,我们可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。
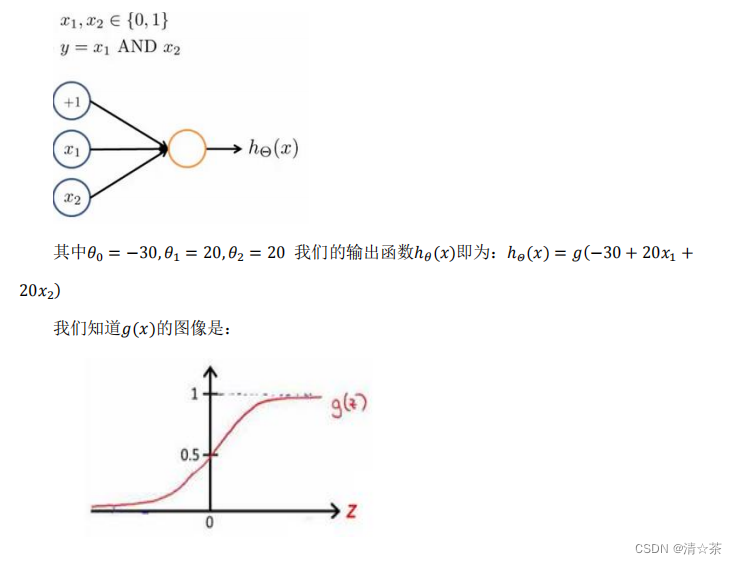
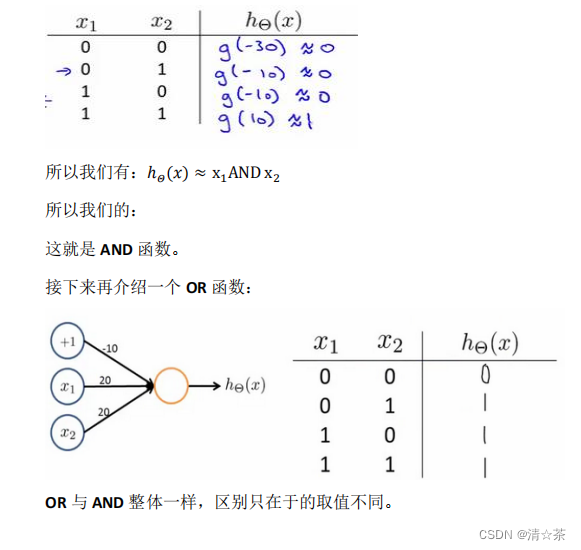
神经网络中,单层神经元(无中间层)的计算可用来表示逻辑运算,比如逻辑与(AND)、逻辑或(OR)。
举例说明:逻辑与(AND);下图中左半部分是神经网络的设计与 output 层表达式,右边上部分是 sigmod 函数,下半部分是真值表。
我们可以用这样的一个神经网络表示 AND 函数:
6.样本和直观理解 II
二元逻辑运算符(BINARY LOGICAL OPERATORS)当输入特征为布尔值(0 或 1)时,我们可以用一个单一的激活层可以作为二元逻辑运算符,为了表示不同的运算符,我们只需要选择不同的权重即可。

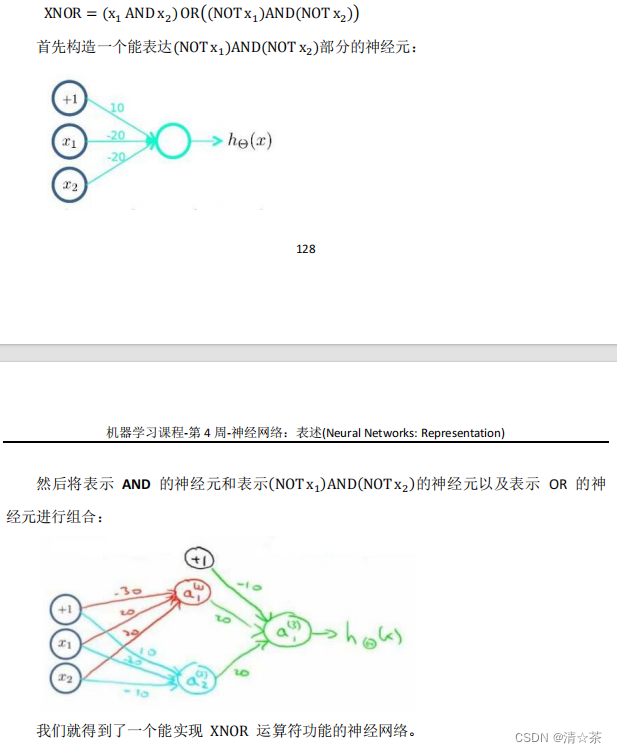
我们可以利用神经元来组合成更为复杂的神经网络以实现更复杂的运算。例如我们要实现 XNOR 功能(输入的两个值必须一样,均为 1 或均为 0),即:
7.多类分类
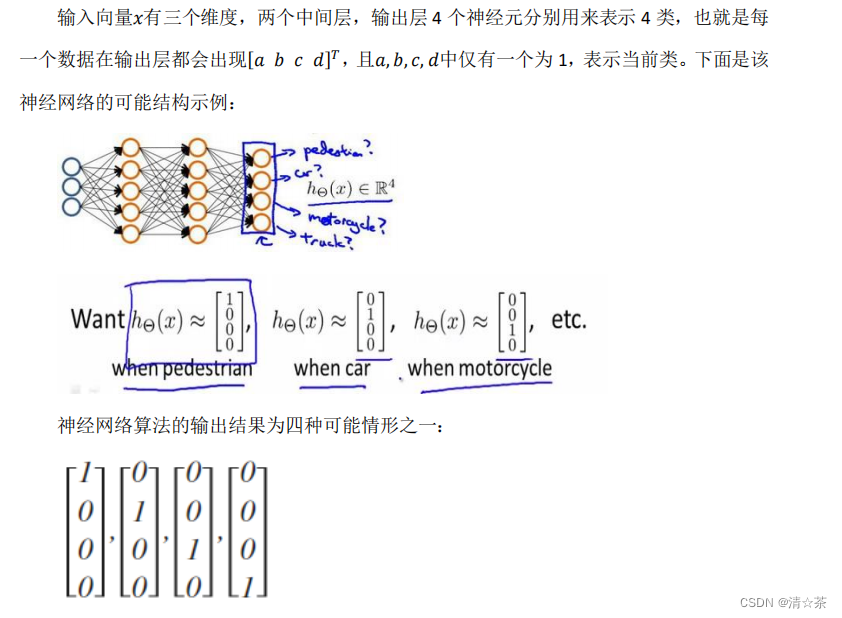
案例:
当有不止两种分类时(也就是𝑦 = 1,2,3 ….),比如以下这种情况,该怎么办?如果我们要训练一个神经网络算法来识别路人、汽车、摩托车和卡车,在输出层我们应该有 4 个值。例如,第一个值为 1 或 0 用于预测是否是行人,第二个值用于判断是否为汽车。
解决思路:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 美国防部网络发布的安全成熟度模型认证 (CMMC) 计划拟议规则的要点整合
- Rockchip平台Android应用预安装功能(基于Android13)
- 读论文1:Towards Unsupervised Domain Generalization
- Go 中 for循环内使用协程的变量值脏读问题
- java中的流
- Android ZXing二维码包含中文时乱码解决
- 【问题记录】AttributeError: module ‘numpy‘ has no attribute ‘bool‘
- 【八】【C语言\动态规划】1567. 乘积为正数的最长子数组长度、413. 等差数列划分、978. 最长湍流子数组,三道题目深度解析
- HTML+CSS基础——CSS控制器(布局)
- jupyter获取token