【DDD领域驱动设计】事件风暴
发布时间:2024年01月23日
事件风暴(Event Storming)是一种灵活的研讨会格式,用于协作探索复杂的业务领域 。
核心概念
- 用户(User): 同样的命令也是由对象执行的,这称之为用户。这里的用户一般是指自然人,例如一个电子购物网站的顾客。使用黄色的即时贴表示。
- 命令(Command): 既然有了事件必然有产生事件的对象,这就是命令。命令可以理解为是一个动作,执行了动作之后就会产生相应的事件。典型的动作描述可以是: 「加入购物车」。使用蓝色的即时贴表示。
- 规则(Policy): 当产生事件时,需要进行某些业务相关的规则校验,如:事件「商品已添加至购物车」的策略可以是「若购物车已满则无法添加」,诸如此类的业务规则可以使用粉色的即时贴表示。
- 领域事件(Event): 事件风暴中的核心概念,它代表了某一个「业务行为」,描述的形似为宾语+动词的过去式。如:「商品已添加至购物车」。使用橙色的即时贴表示。
- 读模型(Read Model) 与页面布局(Screen Layout): 事件产生后的另一个结果往往是呈现在用户面前的系统界面,在这里我们使用页面布局进行展示。这部分的工作一般由 UX 与业务人员完成,展现他们所需要的用户界面。同时页面布局上会展现用户所关心的数据,如:近7天加入购物车的商品。
- 外部系统(System): 事件并不一定由命令产生,也可能由一个外部系统产生,例如一个第三方的支付系统会调用由你系统提供的回调接口,确认客户支付成功,由此产生一个「交易已完成」的事件。
- 问题(Question) 与假设(Assumption): 在讨论过程中各个参与人员可能会发生分歧,例如对于事件的定义,或是由哪个用户执行,或者是具体的规则是什么。此时如果无法在规定的 time box 之内达成统一意见(一般为 5 分钟),可以将问题写在红色的即时贴上,作为问题,或是对某种情况的假设记录下来。
- 聚合(Aggregate): 当一个完整的业务流程通过上述方式写完之后,对于每个用户,命令,事件进行组合,我们就能获得聚合了,用事件风暴的描述就是「用户在 XX 聚合对象上执行了 YY 命令,生成了 ZZ 事件」。例如「顾客在购物车对象上执行了结账命令,生成了购物车结算事件」。
- 连线:代表存在连锁反应,一般出现在:事件 -> 事件,事件 -> 读模型实线:强一致的连锁反应(必须同时发生)虚线:弱一致的连锁反应(允许过一段时间再发生)

基于事件风暴的战略设计
基于事件风暴的战略设计,主要的参与人一般有:研发人员、产品人员、业务人员、领域专家
通过这个过程,最终能有以下收获:
- 识别出业务的不变性(抛开系统,业务的本质是什么)。
- 研发、产品、业务对齐对业务的认知,并且识别出核心子域(未来要在哪些方向上重点发力)。
- 产出相对稳定的微服务划分,并与组织架构、产品规划对齐。
整体过程,按顺序会分为以下几个阶段进行:

实践步骤
准备工作
在开始事件风暴之前,需要邀请相关的参与人员,已经准备相关的物料,具体如下:
- 参加人员: 条件许可的情况下应该全员参与,包括系统开发人员,业务分析师,业务人员,测试工程师,UX 设计师,项目管理人员等。
- 场地要求: 场地尽可能的大,关键是要有一面长 4 米左右的墙壁,用来悬挂或是黏贴纸张。
- 其他物料: 在进行事件风暴的过程中还需要准备以下的材料:
数张大型的招贴纸,如果一时找不到很大的可以用几张小型的纸拼凑一下。
各种不同颜色的即时贴,包括蓝色,黄色,红色,橙色,绿色,粉色,紫色,不同颜色的即时贴对于事件风暴有不同的意义,因此请务必准备好这些颜色的即时贴。
马克笔,准备 3 种不同颜色的多只马克笔。
?命令风暴
目的:
- 识别事件的触发原因以及约束(策略、规则)
- 识别事件与事件之间因果的关系强/弱一致性
过程:
- 第一步:参与者在事件周围添加新的卡片:
- 「角色」「命令」:代表某个事件由什么角色通过什么命令触发
- 「外部系统」:某个事件由外部系统触发
- 「定时器」:某个事件因到达某个时刻而触发
- 「策略」:事件的发生依赖哪些规则或者条件,依赖了哪些业务规则(战略设计时不必太细)
- 第二步:添加事件之间的因果关系
- 如果事件和事件之间存在因果关系,使用单向箭头的连线将两个事件连起来
比如:「面试已创建」会导致「面试通知已发送」
- 因果关系存在强/弱一致性,使用实/虚线箭头表示
「实线箭头」:强一致,表示事件会同时发生
「虚线箭头」:弱一致(最终一致),表示允许一段时间后再发生
- 第三步:对所有的事件的触发原因达成一致
- 所有参与的同学按顺序讨论事件触发的原因是否合理
- 讨论的过程中,每个人需要对事件触发的原因都达成共识
关键点:
- 认真识别强/弱一致性:
- 避免不经思考就认为是强一致,会导致在解决方案层面付出更多的技术复杂性
- 从用户的视角出发,判断两件事是否需要严格的同时发生,否则为弱一致
- 弱一致并不代表不一致,而是一段时间后(x秒/x分钟/...)最终会一致
- 发现外部系统对当前业务的影响
- 不应忽略外部系统造成的影响,比如 CoreHR 系统中,「员工已离职」对各种业务都有影响
阶段产物:
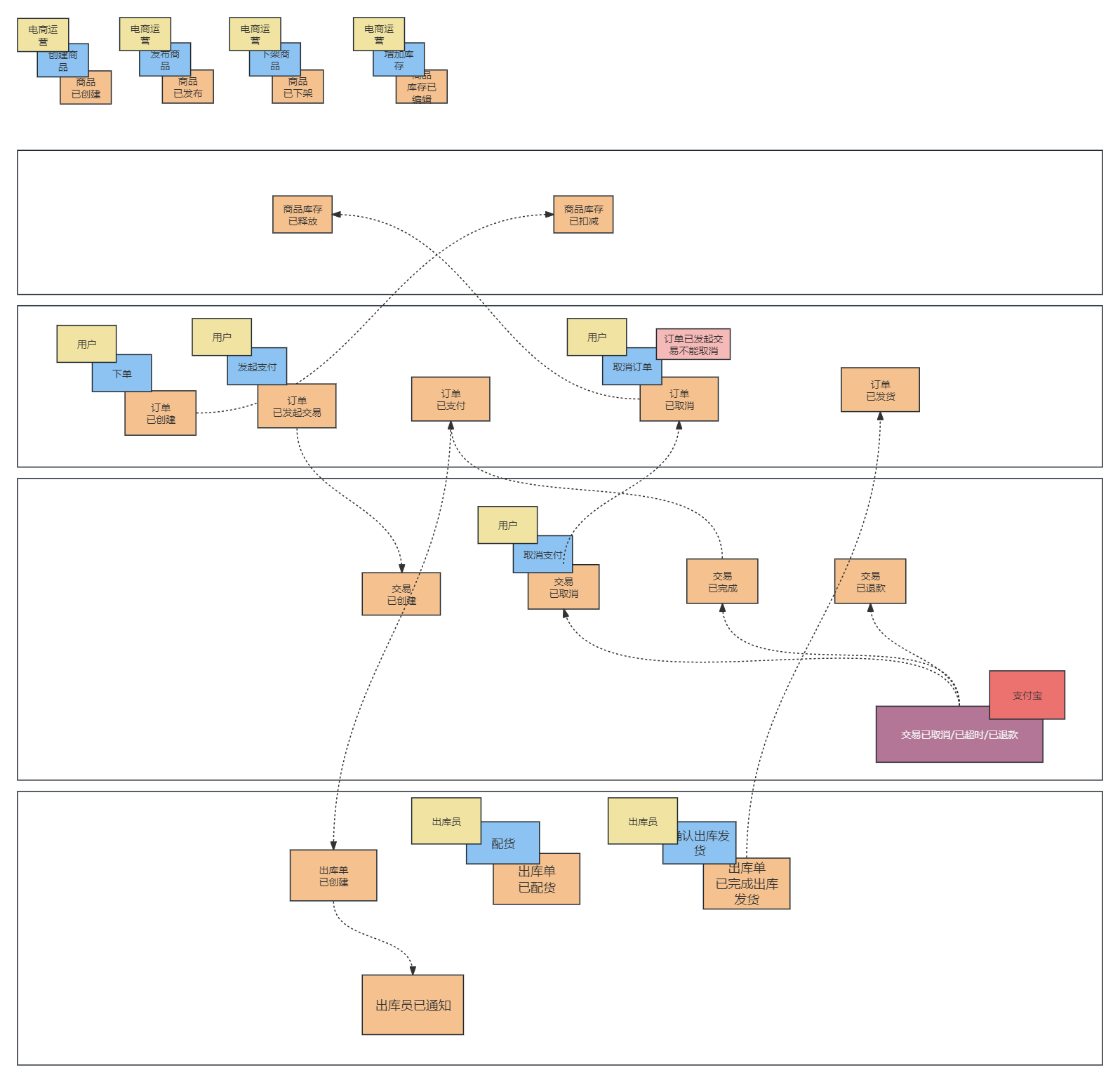
事件风暴
目的:
- 识别业务中会发生的事件
- 通过类似头脑风暴的过程,确保事件不遗漏
过程:
- 第一步:参与者尽可能的罗列业务中可能发生的「事件」
- 「事件」代表业务中会发生的事实,且对业务会产生影响
- 「事件」使用动词的过去式,比如:用户已创建(UserCreated),职位已停用(JobDisabled)
- 尽可能多的罗列,不必担心重复
- 过程中(包括后续阶段)没有定论的部分 / 对别人的贴的不认可,可以贴上菱形卡片,后续讨论
- 第二步:对所有的事件进行一遍整理和排列
- 排列的规则为:同一类事件在一行,时间上后发生的事件在先发生的事件的右边
- 对于重复的事件,或识别为非事件的,可以把卡片挪到一边(不删除,方便找回)
- 整理的过程中,每个人需要对事件存在与否、事件的命名都达成共识
关键点:
- 业务同学的输入很关键
- 业务同学是最了解业务本身的,只有 PM、RD 参与的事件风暴可能会落入解决方案的陷阱
- 有精通行业标准的领域专家最佳
- 「问题」而不是「解决方案」
- 事件应该是对问题的描述,比如:「笔试结果短信已发送」,反复推敲后我们会发现,“笔试结果短信”这件事本身就是个解决方案,背后的问题是:怎样能将笔试的结果送达用户,送达的介质可以是短信、邮件、电话、公告栏中的任何一种,这些都是易变的,但笔试结果要通知用户这件事是不易变的,所以「笔试结果已通知」是更好的表达
- 「业务」而不是「系统」
- 思考业务的本质是什么,比如:「简历去重记录已创建」,这个场景下业务的本质实际上是在说,求职者在某些场景下不能重复进行投递,去重记录只是针对这个规则的一个解决方案,我们也可以使用其他方案来解决这个问题,所以它就不应该是事件
- 业务存在「业务不变性」,借助识别「业务不变性」划分的微服务指责和边界,也会相对稳定
常见 Case:
- 「XX 已查看」
- 查看并不会对业务产生影响,所以并不是事件,类似的还有「XX 已导出」
- 「XX 已修改」
- 需要辨别这个事件是否过于宽泛,不同类型的修改对业务的影响是否一样,比如:「任务名称已修改」和「任务截止时间已修改」这两件事对业务的影响就不一样
- 「XX 状态已变更」
- 状态是很典型的解决方案,是我们根据业务总结出来的,所以应该列出的是导致状态会变化的那个具体事件
阶段产物:

寻找聚合
目的:
- 识别具有固定规则的业务模型
过程:
- 第一步:将事件归纳为聚合
- 将于聚合相关的卡片拖动到聚合周围
- 保留连线不要删除(要作为后续划分限界上下文的依据)
- 第二步:所有人达成一致
- 所有参与的同学讨论每个聚合的合理性,是否存在遗漏
- 最后需要所有人达成共识
关键点:
- 聚合是业务的一致性边界
- 聚合具有业务的一致性边界,在整个生命周期内,任何业务变化都应该遵守定义的全部「业务规则」,比如:「订单」、「订单商品子项」同属于「订单」聚合,当订单商品金额/数量发生变化时,订单的总金额需要一起变化
- 设计小聚合
- 聚合如果过大可能是因为没有准确识别,考虑是否可以拆分
- 从另一个角度讲,大聚合也会限制系统的性能和伸缩性
阶段产物:
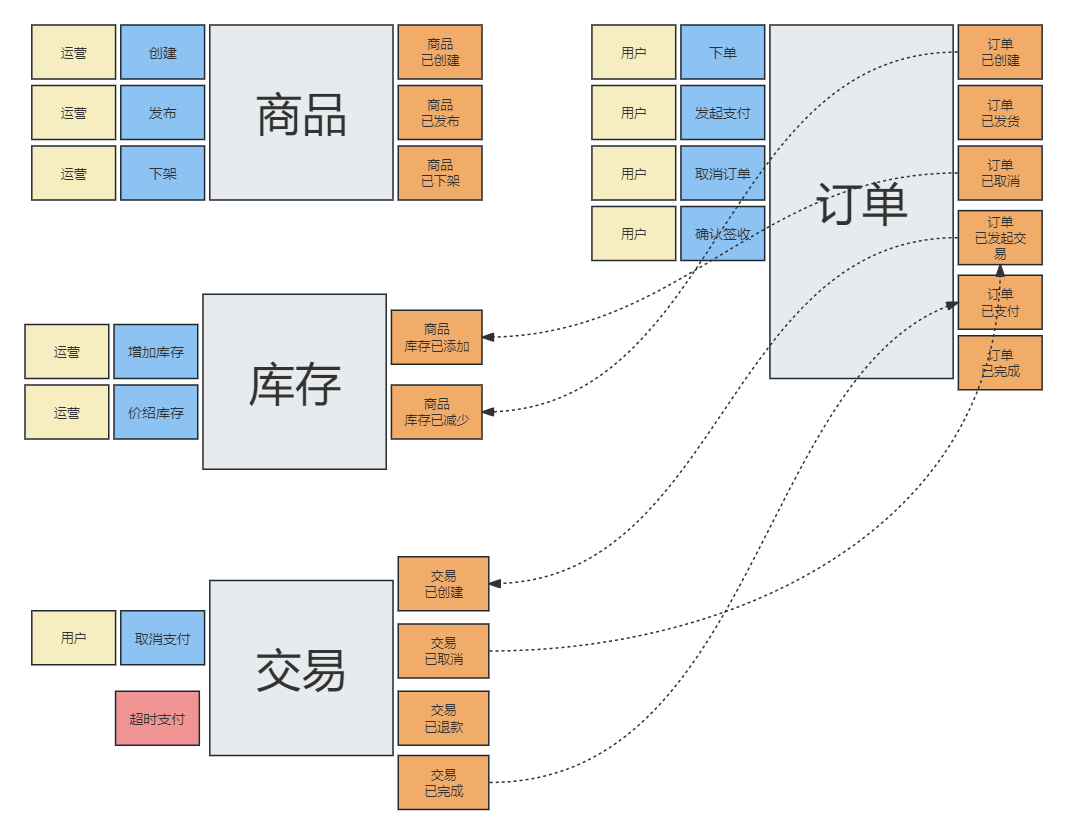
子域划分
目的:
- 将业务划分为多个子业务,并识别出核心业务
过程:
- 第一步:参与者各自将聚合划分为子域
- 「子域」可以理解为具有相关性的一类业务,代表现实世界中特定的业务能力
- 「子域」背后对应的是一类问题,比如:「将商品送达客户」是个需要解决的问题,为了解决这个问题,需要有一个单独的「配送子域」来承载「配送业务」
- 划分时对子域进行命名,如果无法产生合适的命名,可能需要重新审视划分是否正确
- 第二步:识别核心域
- 核心域:核心要解决的问题,决定了我们产品的核心竞争力,需要投入最优质的人才与资源
- 支撑域:对应着业务的某些重要方面,但却不是核心,用以支撑核心域的子域
- 通用域:通常与特定业务不强相关,提供一些通用能力,比如:认证、权限等
- 第三步:所有人达成一致
- 所有参与的同学讨论每个子域划分、命名、分类的合理性
- 最后需要所有人达成共识
关键点:
没有标准答案
子域的划分没有标准答案,每个人都可以有自己的划分思路,但最终需要达成一致
有些不太好划分的聚合,可以通过思考、讨论聚合之间的夹角来辨别,比如在 IT业务中:
「资产负债聚合」是对员工的 IT资产借用待归还的一种描述
「资产子域」对应的业务是企业中 IT资产的生命周期、履历、归属
「信用子域」对应的业务是员工在企业中的信用评价
虽然「资产负债聚合」与两个子域都有关系,但经过讨论后,我们认为其与「资产子域」的夹角要更小,即使没有信用体系,也会存在资产负债,资产负债只是影响信用的其中一个因素,就像负责征信的人民银行并不会实际催你还贷款,所以「资产负债聚合」与「资产子域」的关系会更紧密一些
核心域也会发生变化
核心域、支撑域、通用域并不是一成不变的,会随着时间的推移发生变化
公司战略的变化会导致核心域与支撑域发生互换,有的支撑域也有可能进一步下沉为通用域(比如:中台)
阶段产物:
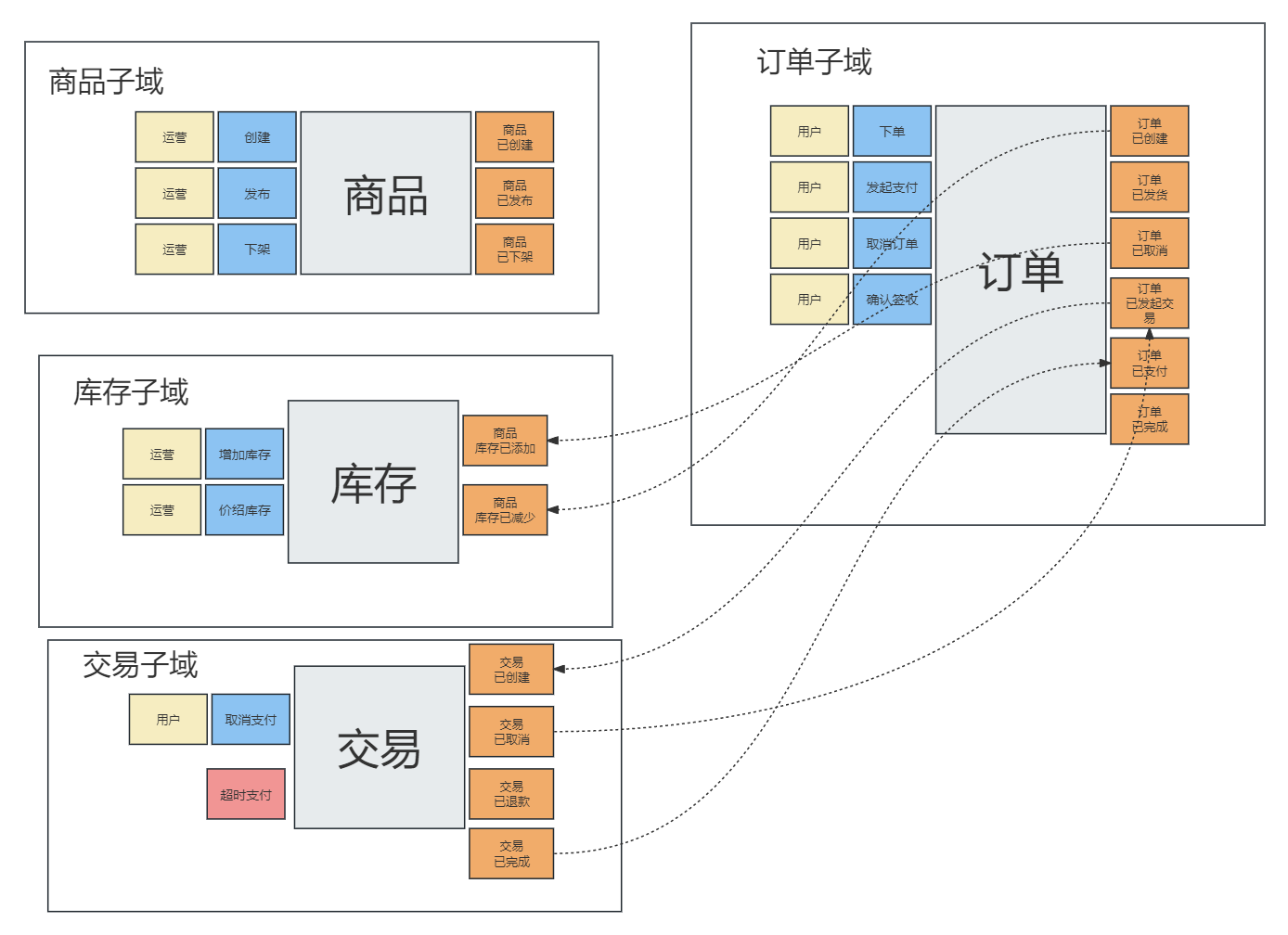
上下文映射
目的:
- 在系统架构、组织架构层面上确定对业务的解决方案
过程:
- 第一步:参与者各自划分限界上下文
- 限界上下文(Bounded Context)是领域模型的显式边界,最终会与团队的组织架构对齐
- 限界上下文决定了使用什么解决方案来解决问题
- 限界上下文的边界内的具有通用语言,对概念的认识是一致的
- 第二步:确定限界上下文之间的关系
- 限界上下文之间存在多种团队协作模式:
-
- 合作关系(Partnership): 两个上下文紧耦合,需要一起协调开发计划与发布计划,会出现糟糕的“双向依赖”,并不是一种好的关系
- 客户方-供应方(Customer-Supplier Development): 一种上游-下游关系,上游团队可以独立于下游团队完成开发,同时上游团队也应顾及下游团队的需求
- 遵奉者(Conformist): 另一种上游-下游关系,上游团队过于强势无法满足下游团队的需求,下游团队只能盲目的使用上游团队的已有能力
- 分离(SeparateWay): 两个上下文完全解耦,是一种比较理想的关系
- 大泥球(Big Ball of Mud): 混杂在一起的上下文关系,边界模糊,常常表现为无法维护的大单体。
- 从保证松耦合的角度来讲,尽量使协作模式是 客户方-供应方、分离 ,当然有时这一点的控制权不在自己手中
- 第三步:所有人达成一致
- 同样, 所有人需要共同对齐,并达成共识
关键点:
- 同样没有标准答案
- 限界上下文的划分同样没有标准答案,每个人都可以有自己的划分思路,但最终需要达成一致
- 划分限界上下文的目的是“分而治之”
- 限界上下文代表的是对工作边界的控制,各上下文之间“各司其职、权责分明”
- 对应于统一语言,限界上下文是语言的边界,对于领域模型,限界上下文是模型的边界
- 限界上下文内部(最终会对应到团队)高效配合,限界上下文之间有明确的指责划分,以提高整体生产效率
- 识别技术复杂度的部分
- 当一个子域中存在技术复杂度高的部分时,需要考虑将分拆为独立的限界上下文,比如:流程引擎、AI、BI、搜索等能力
- 限界上下文与子域没有绝对的对应关系
- 一个限界上下文包含多个子域:有的子域太小不值得用单独的上下文解决,可以由同一个上下文解决多个业务问题,最终会体现在这几个业务都由一个团队来负责
- 一个子域拆分为多个限界上下文:一个子域中存在需要单独解决的,比如商品业务中可能会存在智能推荐的部分,这个子域可以被拆分为商品上下文,商品推荐上下文
- 制定规则的一方为上游
- 这里指的是业务的上下游,业务上谁更强势、谁制定规则,谁即是上游
- 识别上下游决定了在具体实现上,下游可以依赖上游,上游不能依赖下游
- 比如:实现支付功能时,支付平台(支付宝)是上游,因为支付平台并不会为我们单独定制接口,我们只能依照平台预定的规则进行开发
阶段产物:

文章来源:https://blog.csdn.net/sucess_zhang/article/details/135765232
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 02. VBA从入门到精通——基础语法
- 解压命令之一 gzip
- qt+creator快捷键修改成idea的,改完就能像idea那样50%左右丝滑了
- Java人脸识别
- 都2023年了还不了解?使用FileZilla搭建信息文件服务器(Windows7)
- 命令行导出导入数据库
- 找不到api-mswin-crt-runtime-|1-1-0.dll的修复方法解析
- laravel框架的用途有哪些
- 无惧数据泄露风险:迅软科技与电子科技公司共同谱写的安全合奏
- 虚拟机connect: Network is unreachable 无法联网【已解决】