MySQL日志管理,备份与恢复
备份的主要目的是灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。 而备份、恢复中,日志起到了很重要的作用
MySQL日志管理是数据库管理中的一个重要方面,它可以用于诊断问题、监控性能、进行故障恢复等。MySQL主要有几种类型的日志,包括错误日志、查询日志、二进制日志、慢查询日志等。下面详细解析每种类型的日志以及其管理。
配置文件
vim /etc/my.cnf
错误日志(Error Log):
错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启
查看错误日志:
log-error=/usr/local/mysql/data/mysql_error.log #指定日志的保存位置和文件名
配置错误日志路径:
在MySQL配置文件(通常是my.cnf或my.ini)中添加或修改如下配置:
[mysqld]
log_error=/path/to/error.log
查询日志(General Query Log):
查询日志记录了所有客户端的连接和执行的SQL语句。启用查询日志会对性能产生一定影响,默认是关闭的,因此在生产环境中通常不建议一直启用。
查看查询日志状态:
SHOW VARIABLES LIKE 'general_log%';
启用查询日志:
SET GLOBAL general_log = 'ON';
配置查询日志路径:
在MySQL配置文件中添加或修改如下配置:
[mysqld]
general_log = ON
general_log_file = /path/to/query.log
二进制日志(Binary Log):
二进制日志包含了对数据库的修改操作,用于数据恢复、主从复制等。启用二进制日志会对性能有一定影响。默认已开启
查看二进制日志状态:
SHOW VARIABLES LIKE 'log_bin%';
启用二进制日志:
SET GLOBAL log_bin = 'ON';
配置二进制日志路径和命名:
在MySQL配置文件中添加或修改如下配置:
[mysqld]
log_bin = ON
log_bin_basename = /path/to/binlog
慢查询日志(Slow Query Log):
慢查询日志记录执行时间超过阈值的查询,用于识别性能问题。
查看慢查询日志状态:
SHOW VARIABLES LIKE 'slow_query_log%';
启用慢查询日志:
SET GLOBAL slow_query_log = 'ON';
配置慢查询日志路径和阈值:
在MySQL配置文件中添加或修改如下配置:
[mysqld]
slow_query_log = ON
slow_query_log_file = /path/to/slow-query.log
long_query_time = 1 # 指定执行时间的阈值,单位是秒
中继日志
一般情况下它在Mysql主从同步(复制)、读写分离集群的从节点开启。主节点一般不需要这个日志
刷新日志设置:
无需重启MySQL,可以通过以下命令刷新日志设置:
FLUSH LOGS;
systemctl restart mysqld
mysql -u root -P
show variables like 'general%'; #查看通用查询日志是否开启
show variables like 'log_bin%'; #查看二进制日志是否开启
show variables like '%slow%'; #查看慢查询日功能是否开启
show variables like 'long_query_time'; #查看慢查询时间设置
set global slow_query_log=ON; #在数据库中设置开启慢查询的方法
二进制日志开启后,重启mysql 会在目录中查看到二进制日志
cd /usr/local/mysql/data
ls
mysql-bin.000001 #开启二进制日志时会产生一个索引文件及一个索引列表
索引文件:记录更新语句 索引文件刷新方式: 1、重启mysql的时候会更新索引文件,用于记录新的更新语句 2、刷新二进制日志
mysql-bin.index: 二进制日志文件的索引
数据备份
数据备份的重要性
1、备份的主要目的是灾难恢复 2、在生产环境中,数据的安全性至关重要 3、任何数据的丢失都可能产生严重的后果 4、造成数据丢失的原因
备份类型
1. 逻辑备份(Logical Backups):
-
SQL导出: 使用
mysqldump命令将数据库导出为SQL格式的文件,可以包含数据库结构和数据。这种备份方式可读性强,易于理解和修改,但在恢复大型数据库时速度较慢。 -
SELECT INTO OUTFILE: 使用SQL语句将查询结果导出到文件,可以备份表中的数据。
2. 物理备份(Physical Backups):
-
全量备份: 备份整个MySQL数据库系统,包括数据文件、索引等。这种备份方式恢复速度快,但文件较大,占用存储空间多。
-
增量备份: 只备份自上次全量备份或增量备份以来发生更改的数据。通常使用MySQL的二进制日志(binary log)来实现。
3. 冷备份与热备份:
-
冷备份: 在数据库关闭状态下进行备份,这种方式可能导致数据库暂时不可用,适用于小型数据库或可以承受停机时间的环境。
-
热备份: 在数据库运行时进行备份,数据库可以继续提供服务。热备份的方法包括使用复制、文件系统快照、MySQL Enterprise Backup 等。
4. 远程备份与本地备份:
-
远程备份: 将备份数据存储在远程位置,可以提高数据安全性,防止因本地故障而导致备份数据丢失。
-
本地备份: 将备份数据存储在本地设备或服务器上,便于访问和恢复,但可能存在风险,如硬件故障或自然灾害导致数据丢失。
5. 定时备份策略:
-
完整备份和增量备份结合: 定期进行完整备份,然后以较短的时间间隔进行增量备份,确保备份数据的完整性和实时性。
-
定期验证备份: 不仅要进行备份,还应定期验证备份文件的完整性和可恢复性,以确保在需要时可以顺利进行恢复。
备份方式比较
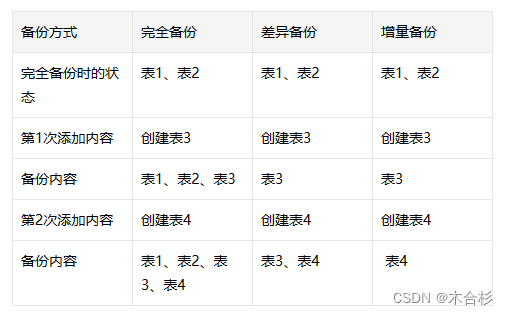
?
逻辑备份的策略(增、全、差异)
合理值区间??? 一周一次的全备,全备的时间需要在不提供业务的时间区间进行 PM 10点 AM 5:00之间进行全备 增量:3天/2天/1天一次增量备份 差异:选择特定的场景进行备份 一个处理(NFS)提供额外空间给与mysql 服务器用
常见的备份方法
1、物理冷备 备份时数据库处于关闭状态,直接打包数据库文件(tar) 备份速度快,恢复时也是最简单的
2、专用备份工具 mysqldump 或 mysqlhotcopy mysqldump 常用的逻辑备份工具 mysqlhotcopy 仅拥有备份 MyISAM 和 ARCHIVE 表
3、启用二进制日志进行增量备份 进行增量备份,需要刷新二进制日志
MySQL支持增量备份,进行增量备份时必须启用二进制日志。二进制日志文件为用户提供复制,对执行备份点后进行的数据库更改所需的信息进行恢复。如果进行增量备份(包含自上次完全备份或增量备份以来发生的数据修改),需要刷新二进制日志。
4、第三方工具备份 免费的MySQL 热备份软件 Percona XtraBackup mysqlbackup
MySQL完全备份
MySQL完全备份一般是指备份整个数据库系统,包括数据库结构(表结构、存储过程、触发器等)和数据。这种备份方式确保在灾难发生或数据丢失时能够进行全面的恢复。
是差异备份和增量备份的基础
优缺点
优点:
备份与恢复操作简单方便
缺点:
数据存在大量的重复 占用大量的备份空间 备份与恢复时间长
数据库完全备份分类
物理冷备份与恢复
关闭MySQL数据库 使用tar命令直接打包数据库文件夹 直接替换现有MySQL目录即可
mysqldump备份与恢复
MySQL自带的备份工具,可方便实现对MySQL的备份 可以将指定的库、表导出为SQL 脚本 使用命令mysq|导入备份的数据
实验
环境准备
use 库名;
create table if not exists info (
id int(4) not null auto_increment,
name varchar(10) not null,
age char(10) not null,
hobby varchar(50),
primary key (id)
);
insert into info values(1,'user1',20,'running');
insert into info values(2,'user2',30,'singing');
MySQL完全备份与恢复
InnoDB 存储引擎的数据库在磁盘上存储成三个文件: db.opt(表属性文件)、表名.frm(表结构文件)、表名.ibd(表数据文件)。
物理冷备份与恢复
systemctl stop mysqld
yum -y install xz
#压缩备份
tar Jcvf /opt/mysql_all_$(date +%F).tar.xz /usr/local/mysql/data/
mv /usr/local/mysql/data/ /opt/
#解压恢复
tar Jxvf /opt/mysql_all_2020-11-22.tar.xz -C /usr/local/mysql/data/
cd /usr/local/mysql/data
mv /usr/local/mysql/data/* ./
mysqldump 备份与恢复(温备份)
reate table info2 (id int,name char(10),age int,sex char(4));
insert into info2 values(1,'user',11,'性别');
insert into info2 values(2,'user',11,'性别');
完全备份一个或多个完整的库 (包括其中所有的表)
mysqldump -u root -p[密码] --databases 库名1 [库名2] ... > /备份路径/备份文件名.sql #导出的就是数据库脚本文件
例:
mysqldump -u root -p --databases kgc > /opt/kgc.sql #备份一个kgc库
mysqldump -u root -p --databases mysql kgc > /opt/mysql-kgc.sql #备份mysql与 kgc两个库
完全备份 MySQL 服务器中所有的库
mysqldump -u root -p[密码] --all-databases > /备份路径/备份文件名.sql
例:
mysqldump -u root -p --all-databases > /opt/all.sql
完全备份指定库中的部分表
mysqldump -u root -p[密码] 库名 [表名1] [表名2] ... > /备份路径/备份文件名.sql
例:
mysqldump -u root -p [-d] kgc info1 info2 > /opt/kgc_info1.sql
#使用“-d”选项,说明只保存数据库的表结构
#不使用“-d"选项,说明表数据也进行备份
#做为一个表结构模板
查看备份文件
grep -v "^--" /opt/库名_info1.sql | grep -v "^/" | grep -v "^$"
MySQL完全恢复
恢复数据库
1.使用mysqldump导出的文件,可使用导入的方法
source命令
mysql命令
2.使用source恢复数据库的步骤
登录到MySQL数据库
执行source备份sql脚本的路径
3.source恢复的示例
MySQL [(none)]> source /backup/all-data.sql
示例方法一
创建备份
mysqldump -uroot -p123456 school info > /opt/info.sql
mysql -uroot -p123123 -e 'drop table school.info;' #删除数据库的表
这是一个使用mysqldump命令进行MySQL数据库备份的示例,具体含义如下:
-
mysqldump: 是MySQL提供的用于导出数据库的命令行工具。 -
-uroot: 指定MySQL连接的用户名,这里是"root"。 -
-p123456: 指定MySQL连接的密码,这里是"123456"。请注意,密码没有空格,直接接在-p后面。 -
school: 是要备份的数据库名称,这里是"school"。 -
info: 是数据库中的表名称,这里是"info"表。如果没有指定表名,那么默认备份整个数据库。 -
> /opt/info.sql: 将备份的内容输出到一个SQL文件,这里是"/opt/info.sql"。>操作符用于将命令输出写入到指定的文件中。
所以,这个命令的含义是从MySQL数据库中的"school"数据库的"info"表中导出数据,并将导出的SQL语句保存到"/opt/info.sql"文件中。如果数据库连接成功并且有足够的权限,系统将要求输入密码。
示例方法二
恢复数据表
mysql -uroot -p123456 school < /abc/school.info.sql
这是一个使用mysql命令进行MySQL数据库导入的示例,具体含义如下:
-
mysql: 是MySQL提供的用于执行SQL语句的命令行工具。 -
-uroot: 指定MySQL连接的用户名,这里是"root"。 -
-p123456: 指定MySQL连接的密码,这里是"123123"。请注意,密码没有空格,直接接在-p后面。 -
school: 是要导入数据的数据库名称,这里是"school"。 -
< /abc/school.info.sql: 从指定文件 ("/abc/school.info.sql") 中读取SQL语句,并将其导入到MySQL数据库中。
所以,这个命令的含义是将包含在"/abc/school.info.sql"文件中的SQL语句导入到MySQL数据库中的"school"数据库。如果数据库连接成功并且有足够的权限,系统将要求输入密码。
select * from info; 查询所有字段
show tables; 查看表信息
免交互方式:source /opt/info.sql
mysql -uroot -p123123 -e 'show tables from school;'
mysqldump 严格来说属于温备份,会需要对表进行写入的锁定
在全量备份与恢复实验中,假设现有test01库,test01库中有一个test表,需要注意的一点为:
当备份时加 --databases ,表示针对于test01库
#备份命令
mysqldump -uroot -p123123 --databases school > /opt/school_01.sql 备份库后
#恢复命令过程为:
mysql -uroot -p123123
drop database ky13;
exit
mysql -uroot -p123123 < /opt/ky13_01.sql
② 当备份时不加 --databases,表示针对ky11库下的所有表
#备份命令
mysqldump -uroot -p123123 ky13 > /opt/ky11_all.sql
#恢复过程:
mysql -uroot -p123123
drop database ky13;
create database ky13;
exit
mysql -uroot -p123123 ky13 < /opt/ky11_02.sql
#查看ky11_01.sql 和ky11_02.sql
主要原因在于两种方式的备份(前者会从"create databases"开始,而后者则全是针对表格进行操作)
4.在生产环境中,可以使用Shell脚本自动实现定时备份(时间频率需要确认)
0 1 * * 6 /usr/local/mysql/bin/mysqldump -uroot -pabc123 kgc info1 > ./kgc_infol_$(date +%Y%m%d).sql ;/usr/local/mysql/bin/mysqladmin -u root -p flush-logs
MySQL增量备份与恢复
MySQL数据库增量恢复
-
一般恢复
将所有备份的二进制日志内容全部恢复
-
基于位置恢复
数据库在某一时间点可能既有错误的操作也有正确的操作 可以基于精准的位置跳过错误的操作 发生错误节点之前的一个节点,上一次正确操作的位置点停止
-
基于时间点恢复
跳过某个发生错误的时间点实现数据恢复 在错误时间点停止,在下一个正确时间点开始
增量备份示例
1.开启二进制日志功能
vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
binlog_format = MIXED #可选,指定二进制日志(binlog)的记录格式为MIXED(混合输入)
server-id = 1 #可加可不加该命令
#二进制日志(binlog)有3种不同的记录格式: STATEMENT (基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT
① STATEMENT(基于SQL语句):
每一条涉及到被修改的sql 都会记录在binlog中
缺点:日志量过大,如sleep()函数,last_insert_id()>,以及user-defined fuctions(udf)、主从复制等架构记录日志时会出现问题
总结:增删改查通过sql语句来实现记录,如果用高并发可能会出错,可能时间差异或者延迟,可能不是我们想想的恢复可能你先删除或者在修改,可能会倒过来。准确率底
② ROW(基于行)
只记录变动的记录,不记录sql的上下文环境
缺点:如果遇到update......set....where true 那么binlog的数据量会越来越大
总结:update、delete以多行数据起作用,来用行记录下来,
只记录变动的记录,不记录sql的上下文环境,
比如sql语句记录一行,但是ROW就可能记录10行,但是准确性高,高并发的时候由于操作量,性能变低 比较大所以记录都记下来,
③ MIXED 推荐使用
一般的语句使用statement,函数使用ROW方式存储。
systemctl restart mysqld
查看二进制日志文件的内容
cp /usr/local/mysql/data/mysql-bin.000002 /opt/
① mysqlbinlog --no-defaults /opt/mysql-bin.000002
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002
#--base64-output=decode-rows:使用64位编码机制去解码(decode)并按行读取(rows)
#-v: 显示详细内容
#--no-defaults : 默认字符集(不加会报UTF-8的错误)
PS: 可以将解码后的文件导出为txt格式,方便查阅
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002 > /opt/mysql-bin.000002
二进制日志中需要关注的部分
1、at :开始的位置点
2、end_log_pos:结束的位置
3、时间戳: 210712 11:50:30
4、SQL语句
2.进行完全备份(增量备份时基于完全备份的,所以我们直接完全备份数据库)
[root@mysql data]# mysqldump -uroot -p school info > /opt/kgc_info1_$(date +%F).sql
[root@mysql data]# mysqldump -uroot -p123123 school > /opt/school_all_$(date +%F).sql
3.可每天进行增量备份操作,生成新的二进制日志文件(例如:mysql-bin.000002)
mysqladmin -u root -p flush-logs
4.插入新数据,以模拟数据的增加或变更
PS:在第一次完全备份之后刷新二进制文件,在第二个二进制文件中记载着"增量备份的数据"
mysql> create database ky13;
Query OK, 1 row affected (0.00 sec)
mysql> use ky13;
Database changed
mysql> create table test1 (id int(4),name varchar(4));
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test1 values(1,'one');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test1 values(2,'two');
Query OK, 1 row affected (0.00 sec)
mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
+------+------+
2 rows in set (0.00 sec)
5.再次生成新的二进制日志文件(例如:mysql-bin.000003)
mysqladmin -u root -p flush-logs
#之前的步骤4的数据库操作会保存到mysql-bin.000002文件中,之后我们测试删除ky13库的操作会保存在mysql-bin.000003文件中 (以免当我们基于mysql-bin.000002日志进行恢复时,依然会删除库)
增量恢复实例
1.一般恢复
(1)、模拟丢失更改的数据的恢复步骤(直接使用恢复即可)
① 备份ky11库中test1表
mysqldump -uroot -p123123 ky13 test1 > /opt/ky13_test13.sql
② 删除ky13库中test1表
drop table ky13.test1;
③ 恢复test1表
mysql -uroot -p ky13 < info-2020-08-31.sql
#查看日志文件
[root@mysql data]# mysqlbinlog --no-defaults --base64-output=decode-rows -v mysql-bin.000002
(2)、模拟丢失所有数据的恢复步骤
① 模拟丢失所有数据
[root@mysql data]# mysql -uroot -p123123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| ky13 |
| mysql |
| performance_schema |
| school |
| sys |
| test |
+--------------------+
7 rows in set (0.00 sec)
mysql> drop database ky13;
Query OK, 1 row affected (0.00 sec)
mysql> exit
② 基于mysql-bin.000002恢复
mysqlbinlog --no-defaults /opt/mysql-bin.000002 | mysql -u root -p
2.断点恢复
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002
例:
# at 302
#201122 16:41:16
插入了"user3"的用户数据
# at 623
#201122 16:41:24
插入了"user4"的用户数据
(1)、基于位置恢复
① 插入三条数据
mysql> use ky13;
mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
+------+------+
2 rows in set (0.00 sec)
mysql> insert into test1 values(3,'true');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test1 values(4,'f');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test1 values(5,'t');
Query OK, 1 row affected (0.00 sec)
mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
| 3 | true |
| 4 | f |
| 5 | t |
+------+------+
5 rows in set (0.00 sec)
#需求:以上id =4的数据操作失误,需要跳过
② 确认位置点,刷新二进制日志并删除test1表
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000003
960 停止
1066 开始
#刷新日志
mysqladmin -uroot -p123123 flush-logs
mysql> use ky13;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------+
| Tables_in_ky13 |
+----------------+
| test1 |
+----------------+
1 row in set (0.00 sec)
mysql> drop table ky13.test1;
Query OK, 0 rows affected (0.00 sec)
③ 基于位置点恢复
#仅恢复到操作 ID 为“623"之前的数据,即不恢复"user4"的数据
mysqlbinlog --no-defaults --stop-position='623' /opt/mysql-bin.000002 | mysql -uroot -p
#仅恢复"user4"的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-position='623' /opt/mysql-bin.000002 | mysql -uroot -p
mysqlbinlog --no-defaults --start-position='400' --stop-position='623' /opt/mysql-bin.000002 | mysql -uroot -p #恢复从位置为400开始到位置为623为止
(2)、基于时间点恢复
mysqlbinlog [--no-defaults] --start-datetime='年-月-日 小时:分钟:秒' --stop-datetime='年-月-日小时:分钟:秒' 二进制日志 | mysql -u 用户名 -p 密码
#仅恢复到16:41:24 之前的数据,即不恢复"user4"的数据
mysqlbinlog --no-defaults --stop-datetime='2020-11-22 16:41:24' /opt/mysql-bin.000002 | mysql -uroot -p
#仅恢复"user4"的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-datetime='2020-11-22 16:41:24' /opt/mysql-bin.000002 | mysql -uroot -p
如果恢复某条SQL语之前的所有数据,就stop在这个语句的位置节点或者时间点
如果恢复某条SQL语句以及之后的所有数据,就从这个语句的位置节点或者时间点start
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据库-期末考前复习-第5章-数据库完整性
- 用springboot mybatis写一个增删改查
- 亚马逊鲲鹏系统:打造个性化QA,助力产品留言增长!
- 智能物联网汽车3d虚拟漫游展示增强消费者对品牌的认同感和归属感
- 虚拟机域环境的搭建
- JAVA基于遗传算法的中药药对挖掘系统的设计与实现(源代码+论文)
- 打开任务管理器的13种方法,总有一款适合你
- Oracle递归查询
- PHP特性知识点扫盲 - 上篇
- 拼图软件哪个好?拼图模板多吗