【BERT】深入理解BERT模型1——模型整体架构介绍
前言
BERT出自论文:《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》 2019年
近年来,在自然语言处理领域,BERT模型受到了极为广泛的关注,很多模型中都用到了BERT-base或者是BERT模型的变体,而且在模型中增加了BERT预训练模型之后,许多NLP任务的模型性能都得到了很大程度的提升,这也说明了BERT模型的有效性。
由于BERT模型内容较多,想要深入理解该模型并不容易,所以我分了大概三篇博客来介绍BERT模型,第一篇(也就是本篇博客)主要介绍BERT模型的整体架构,对模型有一个整体的认识和了解;第二篇详细介绍BERT模型中的重点内容,包括它所提出的两个任务;第三篇从代码的角度来理解BERT模型。
目前我只完成了前两篇论文,地址如下,之后完成第三篇会进行更新。
第一篇:【BERT】深入理解BERT模型1——模型整体架构介绍
第二篇:【BERT】深入BERT模型2——模型中的重点内容,两个任务
第三篇:
BERT整体架构介绍
1、BERT模型基于Transformer架构实现,是一种全新的双向编码器语言模型。与ELMo、GPT等单相语言模型不同,BERT旨在构建一个双向的语言模型来更好地捕获语句间的上下文语义,使其在更多的下游任务上具有更强的泛化能力。因此,预训练完成的BERT模型被迁移到下游任务时,只需要再添加一个额外的输出层便可以进行微调,例如问答和语言推理任务,并不需要针对具体的任务进行模型架构的修改。
2、为了使NLP模型能够充分利用海量廉价的无标注数据信息,预训练语言模型应运而生。
通过模型预训练,我们可以从海量数据集中初步获取潜在的特征规律,再将这些共性特征移植到特定的任务模型中去,将学习到的知识进行迁移。具体来说,我们需要将模型在一个通用任务上进行参数训练,得到一套初始化参数,再将该初始化模型放置到具体任务中,通过进一步的训练来完成更加特殊的任务。
预训练模型的推广,使得许多NLP任务的性能获得了显著提升,它为模型提供了更好的初始化参数,大大提高了其泛化能力。
3、当前的预训练模型主要分为基于特征和微调两大类,但它们大都基于单向的语言模型来进行语言学习表征,这使得许多句子级别的下游任务无法达到最优的训练效果。本文提出的BERT模型(双向预训练表征模型),很大程度上缓解了单向模型带来的约束。同时,引入了“完形填空”和“上下句匹配”分别作为单词级别和句子级别的两大通用任务,对BERT模型进行训练。
基于特征的无监督方法主要是指单词嵌入表征学习。首先将文本级别的输入输出为特征向量的形式,再将预训练好的嵌入向量作为下游任务的输入。
基于微调的无监督方法主要是在,我们在某些通用任务上预训练完成的模型架构,可以被直接复制到下游任务中,下游任务根据自身需求修改目标输出,并利用该模型进行进一步的训练。也就是说,下游任务使用了和预训练相同的模型,但是获得了一个较优的初始化参数,我们需要对这些参数进行微调,从而在特殊任务上获得最优性能。
基于有监督数据的迁移学习,是基于存在大量有监督数据集的任务来获取预训练模型,例如自然语言推理和机器翻译。
4、BERT模型创造性地将Transformer中的Encoder架构引入预训练模型中,成为第一个使用双向表征的预训练语言模型。同时,为了适应该双向架构,BERT引入了两项新的NLP任务——完形填空和上下句匹配,类捕获词语级别和句子级别的表征,并使之具有更强的泛化能力。
5、具体方法:
BERT整体框架包含Pre-training和Fine-tuning两个阶段,Pre-training阶段,模型首先在设定的通用任务上,利用无标签数据进行训练。训练好的模型获得了一套初始化参数之后,再到Fine-tuning阶段,模型被迁移到特定任务中,利用有标签数据继续调整参数,知道在特定任务上重新收敛。
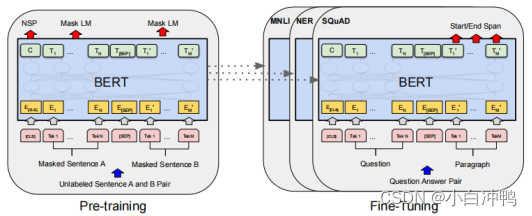
BERT模型采用了Transformer中的Encoder架构,通过引入多头注意力机制,将Encoder块进行堆叠,形成最终的BERT架构。为了适应不同规模的任务,BERT将其结构分为了base和large两类,较小规模的base结构含有12个Encoder单元,每个单元含有12个Attention块,词向量维度为768;较大规模的large结构含有24个Encoder单元,每个单元中含有16个Attention块,词向量维度为1024。通过使用Transformer作为模型的主要框架,BERT能够更彻底地捕获语句中的双向关系,极大地提升了预训练模型在具体任务中的性能。
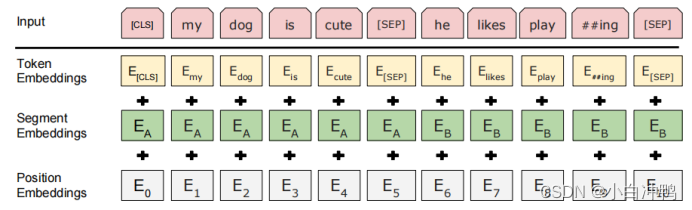
BERT模型的输入由三部分组成。除了传统意义上的token词向量外,BERT还引入了位置词向量和句子词向量。位置词向量的思想与Transformer一致,但BERT并未使用其计算公式,而是随机初始化后放入模型一同训练;句子词向量实质上是一个0-1表征,目的是区分输入段落中的上下句。这三种不同意义的词向量相加,构成了最终输入模型的词向量。
Pre-training:BERT的预训练部分使用了完形填空和上下句匹配两个无监督任务。“完形填空”代表了词语级别的预训练任务,该任务对输入句子中若干随机位置的字符进行遮盖,并利用上下文语境对遮盖字符进行预测。(MLM)“上下句匹配”代表了句子级别的预训练任务,该任务给出两个句子,利用句子之间的语义连贯性判定这两个句子是否存在上下句关系。这两个预训练任务对于大量NLP任务的架构具有更好的代表性,同时也更能匹配模型本身的双向架构,对模型的泛化能力有着巨大的提升帮助。
Fine-tuning:训练具体任务时,我们只需将具体任务中的输入输出传入预训练完成的BERT模型,继续调整参数直至模型再次收敛。该过程成为微调(Fine-tuning)。相比于预训练来说,微调的代价是极小的。在大部分NLP任务中,我们只需要在GPU上对模型进行几个小时的微调,便可使模型在具体任务上收敛,完成训练。
6、实验结果及结论
结果表明,即使是在有标签数据量较小的数据集上,随着模型规模的提高,任务的准确度都获得了显著的提升。进一步可得出结论:如果模型已经经过过滤充分的预训练,那么当将模型缩放到一个极限的规模尺寸时,仍然能够在小规模的微调任务上产生较大的改进。
预训练模型的迁移学习,逐渐成为语言理解系统中不可或缺的一部分,它甚至能够使得一些低资源的任务从深度单向架构中受益。
以上就是对BERT模型理论知识的整体理解,看完之后应该能有个整体的认识吧。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux泡妞大法之Nginx网站服务
- c# 数组删除
- 从零开始了解域名:什么是域名、域名的作用及类别
- 《微信小程序开发从入门到实战》学习六十
- paddlepaddle在执行loss.item()的时候,报错an illegal memory access was encountered.
- vue:状态管理库及其部分原理(Vuex、Pinia)
- 同样是IT行业,测试和开发薪资真就差这么大吗?
- SpringBoot项目使用JWT令牌进行权限校验
- 代理IP在SEO优化、市场调研和数据挖掘中的应用实例
- 项目进度管理:掌握进度管理技巧,保障项目不延期