数据类型与运算符
关键字
关键字
所谓关键字,就是被Java赋予了特殊含义,用作专门用途的字符串(例如在第一个Java程序中涉及到的public、class、static等都是Java的关键字)。
特点
所有的关键字全部都是小写字母。
注意
- 所有关键字并不用特别去记忆,后续学习中慢慢接触即可。
- const、goto虽然没有被使用,但是预留为关键字防止后续版本使用。
标识符
标识符
Java中变量、方法以及类等要素命名的时候使用的字符序列;即自己命名的名字都叫标识符,有包名、类名、方法名、变量名以及常量名。
命名规则
以数字、字母、下划线和$组成;其中数字不能开头。
命名规范
包名:全部小写拼接
类名:采用大驼峰
方法名、变量名:采用小驼峰
常量名:全部大写并且单词之间使用下划线拼接。
变量
变量
内存中的一个存储区域,该区域的数据可以在同一类型范围内不断变化。
变量构成的三个要素
数据类型? ?变量名? ?存储的值
Java中声明变量的方式
数据类型 变量名 = 变量值
强类型语言:在定义变量时必须指定其类型(根据Java中声明变量的格式可知,Java属于强类型语言)。
弱类型语言:在定义变量时无需指定其类型(例如JavaScript就是弱类型语言,其在定义任何变量时都是let或者var<一个新版本一个旧版本的区别>)。
// 定义变量的方式
// 方式一
int a; // 先声明
a = 10; // 变量的赋值(第一次赋值时被称为初始化)
// 方式二
int a = 10; // 声明和初始化合并变量的作用?
用于在内存中保存数据。
Java中变量按数据类型分类
基本数据类型
整数型:byte、short、int、long
浮点型:float、double
字符型:char
布尔型:boolean
在每个基本数据类型的背后,也各自对应着一个引用数据类型,例如int对应着Integer,boolean对应着Boolean;在此作一个了解,后续就会慢慢引入。
引用数据类型
类(class)
数组(array)
接口(interface)
枚举(enum)
注解(annotation)
记录(record)
数据类型
基本数据类型
基本数据类型
一共有八种基本数据类型。
整数型:byte、short、int、long
浮点型:float、double
字符型:char
布尔型:boolean
整数类型
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| byte | 1字节 = 8bit | -128 ~ 127 |
| short | 2字节 | -2^15 ~ 2^15-1 |
| int | 4字节 | -2^31 ~ 2^31-1? ?21亿 |
| long | 8字节 | -2^63 ~ 2^63-1? ?9.22*10^1 8 |
定义long类型的变量时,赋值时需要以“L”或“l” 作为后缀。
long a = 123L;补充·:计算机存储单位
字节(byte):是计算机用于计量存储容量的基本单位,一个字节等于八个bit。
位(bit):是数据存储的最小单位。在二进制系统中,每个0或者1就是一个位,叫作bit(比特),其中八个比特就是一个字节。
转换关系:
- 8 bit = 1 Byte
- 1024 Byte = 1 KB
- 1024 KB = 1 MB
- 1024 MB = 1 GB
- 1024 GB = 1 TB
?浮点类型
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| 单精度 float | 4字节 | -3.403E38 ~ 3.403E38 |
| 双精度 double | 8字节 | -1.798E308 ~ 1.798E308 |
- float:单精度,位数可以精确到7位有效数字。
- double:双精度,精度是float的两倍。
- 在使用float时,赋值时需要以“F”或“f“为后缀。
float a = 12.3f;?补充:关于浮点数的说明
- 并不是所有的小数都可以精确的用二进制浮点数表示,例如0.1、0.01、0.001这样的10的负次幂就不能使用浮点数精确表示。
- 浮点数float、double的数据不适合在不容许舍入误差的金融计算领域使用,如果需要精确数字计算或保留指定位数的精度,需要用到BigDecimal类。??
System.out.println(0.1 + 0.2);
// 输出结果本来应该是0.3,但是最终输出结果为0.30000000000000004
float f1 = 123123123f;
float f2 = 123123124f;
System.out.println(f1);
System.out.println(f2);
System.out.println(f1 == f2);
// 输出结果本来应该为flase,但是最终输出结果为true
// 在上述测试中可以发现,浮点数是非常不牢靠的数?字符类型
- char类型的数据用来表示通常意义上的”字符“,占用两个字节。
- Java中所有字符的编码都使用Unicode编码,故一个字符可以存储一个字母,一个汉字,或者是其他书面语的一个字符。
- 四种表现形式
// 表示形式一
//使用一对单引号''表示,单引号内部有且只有一个字符
char a = '1';
// 表示形式二
//直接使用Unicode编码,形式为'\uXXXX',XXXX为16进制
char b = '\u0012';
// 表示形式三
// 使用转义字符
char c = '\n';
// 表示形式四
// 直接使用数字来表示
char d = 97;布尔类型?
- 布尔类型只有两个取值,true和flase。
- 扩展:JVM中并没有任何供boolean值专用的字节码指令,那boolean到底是如何存储的呢?实际上,Java语言中的boolean值,在编译之后都使用int类型对应的字节码指令来替代true和flase,1表示true、0表示flase;因此,对于boolean类型 所占用的空间,一般是不过多探讨的,但是非要说他多少那么他就是四个字节。
基本数据类型间的运算规则
自动类型提升
- 常规情况:当容量小的变量和容量大的变量做运算时,结果自动转化为容量大的数据类型;所谓容量大小,按下述规则 由小到大排列:byte、short、char → int → long → float → double
- 特殊情况:byte、short和char三者之间的运算结果是int类型的,因此涉及到下述的强制类型转换。
- 注意
// 注意一
// 对于整型常量来说,规定其为int类型
// 对于浮点型常量来说,规定其为double类型
// 注意二
long a = 123;
long b = 123L;
// 变量a来说,由于123是常量,因为把他赋值给a之后实际上进行了自动类型提示
// 变量b来说,由于在123之后加了后缀L,因此就是long类型
// 因此,如果给long类型赋值123123123123123而不加L,那就会报错,因为他超过了int类型
// 注意三
float a = 1.2f;
// 对于float来说,必须加上后缀f
// 由于int到long是自动类型提示,但是double到float确是大容量到小容量,不符合规矩
// 注意四
int a = 12;
float b = a;
// 将整型赋值给浮点型之后,本来结果还是12
// 但是输出b时是12.0,也就是说,变为浮点型之后自动补一个'.0'强制类型转换
- 将容量大的类型转换为容量小的类型,需要使用到强制类型转换。
- 在强制类型转化中,需要使用到强制类型转换符(XX),XX表示需要转换的类型;例如:
// 将long类型强制转换为int类型
long a = 123L;
int b = (int) a;
- 精度虽然问题举例
// 例一 // 将double转化为int double a = 12.8; int b = (int) a; // 输出结果为12,直接截断,没有四舍五入一说 // 例二 // 将int转化为byte int a = 128; byte b = (byte) a; // 输出结果为-128,具体原因和数据底层存储有关,在进制模块中会提到
引用数据类型
引用数据类型
一共有六种引用数据类型,和基本数据类型不同的是,每种引用数据类型只是一个统称,一种引用数据类型又有许多种不同的内容(例如未来要学习到的类,程序员本身就可以创造无数的类)。
类(class)
数组(array)
接口(interface)
枚举(enum)
注解(annotation)
记录(record)
String
- String是一个类,属于引用数据类型,俗称”字符串“。
- String类型的变量,可以使用双引号”“来进行赋值
String a = "hello"; - String与基本数据类型变量间只能做连接运算,即”+“运算。?
特别注意的是:
1. 在八种基本数据类型中,只有布尔类型不能和其它数据类型做运算,其他其中数据类型相互之间都可以运算。
2. 对于String,可以和八种基本数据类型之间任意进行运算。
进制
背景介绍:为什么要介绍进制?
在计算机的世界中,只有二进制,也可以这样说,计算机是最深情的一种没有感情的机器,毕竟他的眼里只有二进制;所有计算机存储和运算的数据都要转化为二进制,包括但不限于数字、字符、图片、声音、视频等。
世界上只有10种人,认识二进制的和不认识二进制的。
常见进制
// 二进制
// 满二进一,以0b或者0B开头
int a = 0b1010;
// 八进制
// 满八进一,以0开头
int b = 01234567;
// 十进制
// 满十进一,是最常见的一种进制
int c = 123456789;
// 十六进制
// 满十六进一,以0x或者0X开头
int d = 0x123456789abcdef;原反补?
计算机数据的存储采用二进制补码的形式存储,并且最高位是符号位:
- 正数的最高位是0
- 负数的最高位是1
规定:
1. 正数的原反补都一样,即三码合一。
2. 负数的原反补不相同。
- 原码:将十进制转换为二进制,然后最高位设置为1
- 反码:把除最高位以外的原码其余位都取反(0变1,1变0)
- 补码:反码加1
补充:
将int的128转化为byte变为-128的原因:
 ?最后虽然得到了转化之后的补码,其值确实为-128,但是如何转化为原码,说实话不太清楚。
?最后虽然得到了转化之后的补码,其值确实为-128,但是如何转化为原码,说实话不太清楚。
运算符
运算符
运算符是一种特殊的符号,用以表示数据的运算、赋值以及比较等。
分类
按功能分类

按操作数个数分类

算数运算符?
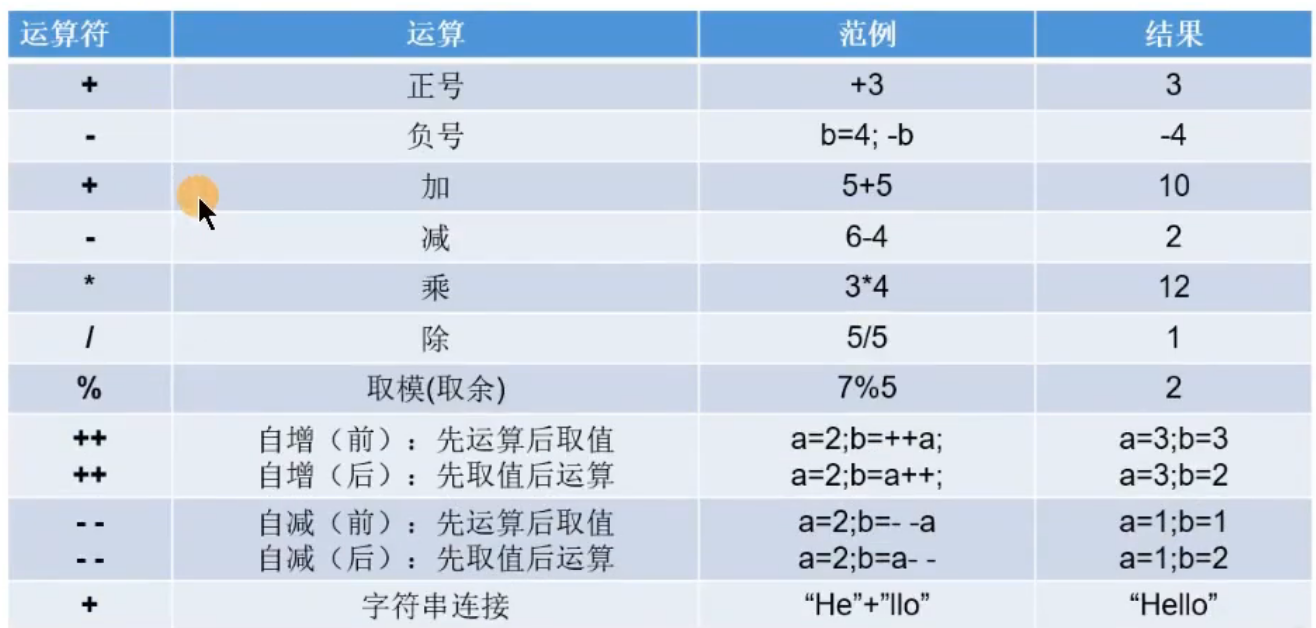
?注意
- 除(/):整型相除时结果还是整型。
int a = 12;
int b = 5;
int c = a / b;
// c的输出结果应该是2- 取模、取余(%):通常用来判断一个数是否能整除另一个数
int a = 12;
int b = 5;
int c = a % b;
// c输出的如果是0,那就表明a可以被b整除
// 反之不是0,就表明a不可以被b整除 int a = 12;
int b = -5;
// 输出结果为:2
int a = -12;
int b = 5;
// 输出结果为:-2
int a = -12;
int b = -5;
// 输出结果为:-2
// 综上可知:余数的正负与被余数的正负相同
- ++和++
int a = 3;
int b = a++;
// 输出的结果为:a = 4,b = 3
int a = 3;
int b = ++a;
// 输出的结果为:a = 4,b = 4
// 上述结果表明,a++整体表示的是a原来的值
// ++a表示的a+1之后的值
// 即a++是先运算,再自增
// ++a是先自增,再运算注意:
short a = 3;
a++;
a = (short) (a + 1);
// 在使用a++自增时,并不会报错
// 在使用a+1时,如果不强制类型转换,那么就会报错
// 表明使用自增符时并不会影响数据的数据类型- --和--,与++和++类似,只不过前者是减1,后者是加1,不作过多描述。
上述注意证明了使用++和--符号并不会影响数据的数据类型,因此在使用时可以用自增符时尽量去使用;这样即方便,又减少不必要的麻烦。
- ?字符串连接符(+)
赋值运算符
- =,当”=“两侧数据类型不一致时,自动类型提升或者使用强制类型转换进行处理即可;并且? ”=“支持连续赋值(例如a = b = 10)。
- +=,a+=2和a=a+2输出结果相同,但是过程不太相同;类似于a++与a=a+1的区别。
- 还有其他许多的赋值运算符,不过多介绍,和上述原理都是类似的。
比较运算符

在比较运算中,结果不是true就是flase。
对于instanceof的介绍,会在面向对象的讲解中进行专门介绍。
注意=和==的区别。
逻辑运算符

1.? 在逻辑运算符中,操作的都是boolean类型的常量或者变量,而且运算结果也都是boolean类型值。
2. 对于!来说,表示与原来值相反的值。
3. ^表示异或,符号左右两边的值相同时为flase,不同时为true。
&和&&的异同点:
相同点:两者表达的都是且的关系,只有符号两边的结果都为true,那么最终结果才为true。
不同点:对于&&来说,当符号左边的结果为flase时,就不会再去执行符号右边的操作;但是对于&来说,无论左边操作的结果是啥,都会执行右边的操作。
|与||的异同点:
相同点:两者表达的都是或的关系,只有符号两边的结果都为flase时,那么最终的结果才为flase。?不同点:对于||来说,当符号左边的结果为true时,就不会再去执行符号右边的操作;但是对于|来说,无论左边操作的结果是啥,都会执行右边的操作。?
位运算符

1. 位运算符,针对的都是数值类型的变量或者常量进行运算,运算的结果也都是数值。
2. <<,左移运算符;在一定范围内,数据向左移一位,相当于原数据*2;对于左移运算符,在底层相当于是把该数反码高位第一位去掉,然后在低位第一位补0;因此无论是正数还是负数,左移几位就是乘2的几次方。
3. >>,右移运算符;在一定范围内,数据向右移一位,就相当于原数据除以2;对于右移运算符,在底层相当于是把该数反码低位的第一位去掉,然后在高位第一位补,如果是正数就补0,如果是负数就补1。
4. >>>,无符号右移运算符;表示的意思是无论正数还是负数,补的都是0。
5. ~和!的运算法则相同。
6. &、|和^的运算法则还和逻辑运算符中相同,只不过布尔类型的变成了数值。
条件运算符

反是可以使用条件运算符的位置,都可以使用if else语句;但是在可以使用if else的地方,却不一定可以使用条件运算符;在两者都可以使用的情况下,建议使用条件运算符,他的效率相对较高。
运算符优先级
- 不要过多的依赖运算的优先级来控制表达式的执行顺序,尽量使用()来控制表达式的执行顺序。
- 如果一个表达式过于复杂,建议拆分成几步来完成。
总结
在本篇文章中,是对数据类型和运算符的简单介绍;在下篇文章中,是对流程控制的简单介绍,也就是对顺序结构、分支结构以及循环结构等的感悟与理解;本篇文章到这里就结束了,感谢各位同学的观看。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux系统安装MySQL
- NGINX加载多个COF文件配置
- 行为型设计模式—策略模式
- 代码随想录算法训练营第五十八天|739.每日温度、496.下一个更大元素 I
- linux docker 怎么更换镜像源
- 【C语言】Windows上用GTK写GUI程序
- 外汇天眼:仿冒OANDA安达──诓称分析师带领稳赚不赔,恶意爆仓再三骗入金
- 【2024系统架构设计】 系统架构设计师第二版-嵌入式系统架构设计理论与实践
- SpringBoot教程(十五) | SpringBoot集成RabbitMq
- Atlassian Confluence RCE漏洞复现(CVE-2023-22527)