Bert详解
Bert框架
基本架构
由Transformer的Encoder层堆叠而来

每个部分组成如下:

Embedding
Embedding由三种Embedding求和而成
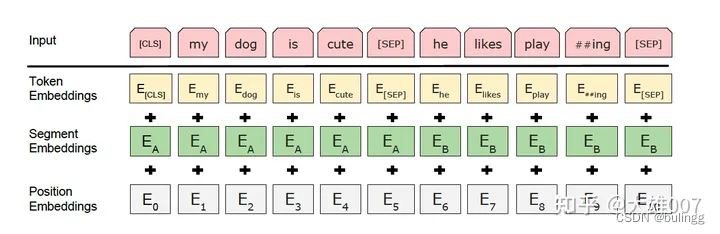
- Token Embeddings:词向量,第一个单词是CLS标志,可以用于之后的分类任务
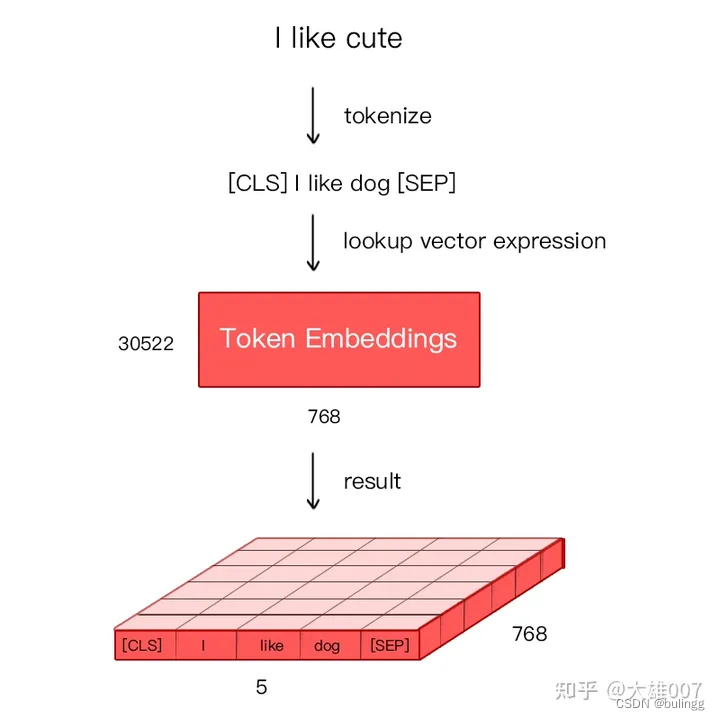
(通过建立词向量表)将每个词转化成一个一维向量,作为模型的输入。首先对文本进行tokenization处理,且在文本开头([CLS])和结尾([SEP])分别插入两个特殊的Token,[CLS]表示该特征用于分类模型,对非分类模型,该符号可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。
Bert处理英文文本需要含有30522个词,Token Embeddings将每个词转化成768维向量
- Segment Embeddings:区别两种句子,因为预训练不光做LM(语言模型,从左往右生成),还要做以两个句子为输入的分类任务。
Segment Embeddings有两种向量表示(0,1),用于表示两个句子,前一个句子全部赋值为0,后一个句子全部赋值为1,然后拼接起来。
如问答系统任务要预测下一句,输入是有关联的句子;文本分类只有一个句子,则全部为0

- Position Embeddings:与Transformer中不一样,不是三角函数的固定位置编码而是学习出来的
由于出现在文本不同位置的字/词所携带的语义信息存在差异(如 ”你爱我“ 和 ”我爱你“),你和我虽然都和爱字很接近,但是位置不同,表示的含义不同。
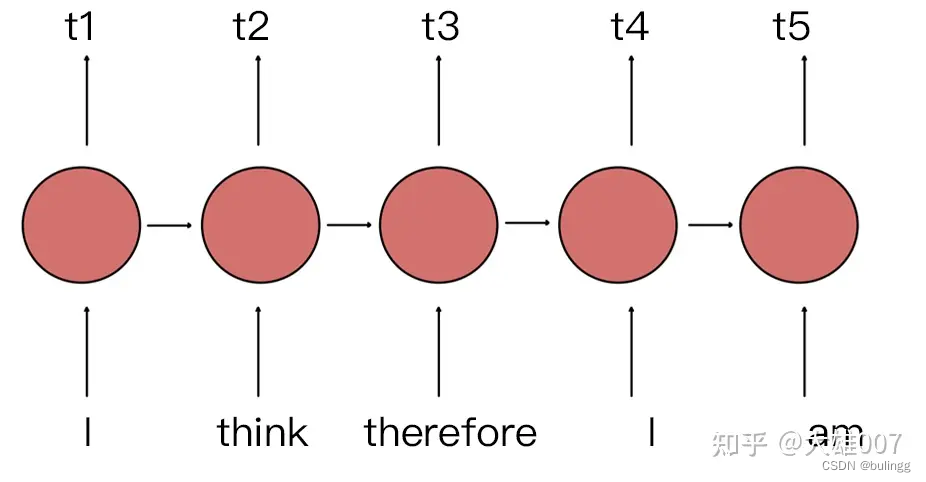
在 RNN 中,第二个 ”I“ 和 第一个 ”I“ 表达的意义不一样,因为它们的隐状态不一样。对第二个 ”I“ 来说,隐状态经过 ”I think therefore“ 三个词,包含了前面三个词的信息,而第一个 ”I“ 只是一个初始值。因此,RNN 的隐状态保证在不同位置上相同的词有不同的输出向量表示。
BERT 中处理的最长序列是 512 个 Token,长度超过 512 会被截取,BERT 在各个位置上学习一个向量来表示序列顺序的信息编码进来,意味着 Position Embeddings 实际上是一个 (512, 768) 的 lookup 表,表第一行是代表第一个序列的每个位置,第二行代表序列第二个位置。
最后,BERT 模型将 Token Embeddings (1, n, 768) + Segment Embeddings(1, n, 768) + Position Embeddings(1, n, 768) 求和的方式得到一个 Embedding(1, n, 768) 作为模型的输入。
[CLS]的作用:
Bert在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。
原因:self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。

pre-training
bert是一个多任务模型,由两个自监督任务组成,即MLM和NSP
MLM(Mask Language Model)
在训练的时候随机从输入语料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。
在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。
- 80%的时候会直接替换为[Mask],将句子 “my dog is cute” 转换为句子 “my dog is [Mask]”。
- 10%的时候将其替换其它任意单词,将单词 “cute” 替换成另一个随机词,例如 “apple”。将句子 “my dog is cute” 转换为句子 “my dog is apple”。
- 10%的时候会保留原始Token,例如保持句子为 “my dog is cute” 不变。
优点
1)被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力;
2)被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。
缺点:针对有两个及两个以上连续字组成的词,随机mask字割裂了连续字之间的相关性,使模型不太容易学习到词的语义信息
NSP(Next Sentence Prediction)
判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘
训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的
fine-tuning
微调(Fine-Tuning)的任务包括:
- 基于句子对的分类任务
- 基于单个句子的分类任务
- 问答任务
- 命名实体识别

优缺点
- 优点:
- BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。
- 相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现
- 缺点:
- 模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
- BERT的NSP任务效果不明显,MLM存在和下游任务mismathch的情况。
- BERT对生成式任务和长序列建模支持不好。
内容参考:读懂BERT,看这一篇就够了
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据在AI任务中的决定性作用:以图像分类为例
- “你基础不太行啊”
- Mysql面试
- java中锁有哪几种?
- 010文章解读与程序——科学技术与工 程北大核心《基于多目标算法的冷热电联供型综合能源系统运行优化》已提供下载资源
- 算法实战(四)
- 中国数据库市场的领军黑马——亚信安慧AntDB数据库
- ChatGPT诞生对全球高等教育所产生的巨大影响
- CPU 飙高系统反应慢怎么排查
- Hydro OJ功能介绍用户使用手册常见问题解决方法