神经网络入门
一、非线性假设
????????我们之前学的无论是线性回归还是逻辑回归都有这样一个缺点,即:当特征太多时,计算的负荷会非常大。下面是一个例子:
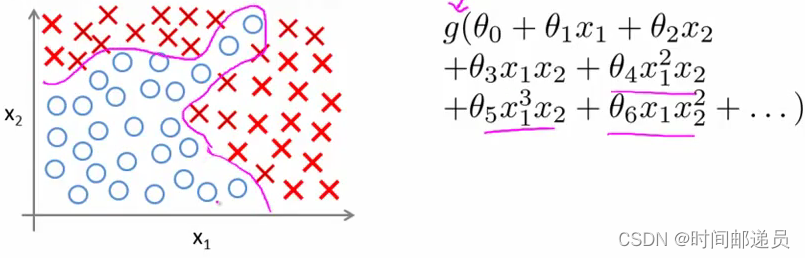
????????当我们使用x_1,x_2 的多项式进行预测时,我们可以应用的很好。 之前我们已经看到过,使用非线性的多项式,能够帮助我们建立更好的分类模型。假设我们有100个特征,我们希望用这100个特征来构建一个非线性的多项式模型,结果将是数量非常惊人的特征组合,即便我们只采用两两特征的组合(x_1x_2+x_1x_3+x_1x_4+...+x_2x_3+x_2x_4+...+x_99x_100),我们也会有接近5000个组合而成的特征,这对于一般的逻辑回归来说需要计算的特征太多了。
????????假设我们希望训练一个模型来识别视觉对象(例如识别一张图片上是否是一辆汽车),一种方法是我们利用很多汽车的图片和很多非汽车的图片,然后利用这些图片上一个个像素的值(饱和度或亮度)来作为特征。假如我们只选用灰度图片,每个像素则只有一个值(非 RGB值),我们可以选取图片上的两个不同位置上的两个像素,然后训练一个逻辑回归算法利用这两个像素的值来判断图片上是否是汽车:
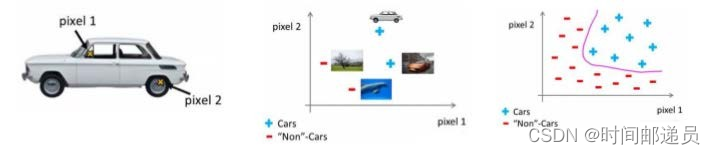 ????????假使我们采用的都是50x50像素的小图片,并且我们将所有的像素视为特征,则会有 2500个特征,如果我们要进一步将两两特征组合构成一个多项式模型,则会有约接近三百万个特征。普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们就需要另一件武器---神经网络。
????????假使我们采用的都是50x50像素的小图片,并且我们将所有的像素视为特征,则会有 2500个特征,如果我们要进一步将两两特征组合构成一个多项式模型,则会有约接近三百万个特征。普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们就需要另一件武器---神经网络。
二、模型表示Ⅰ
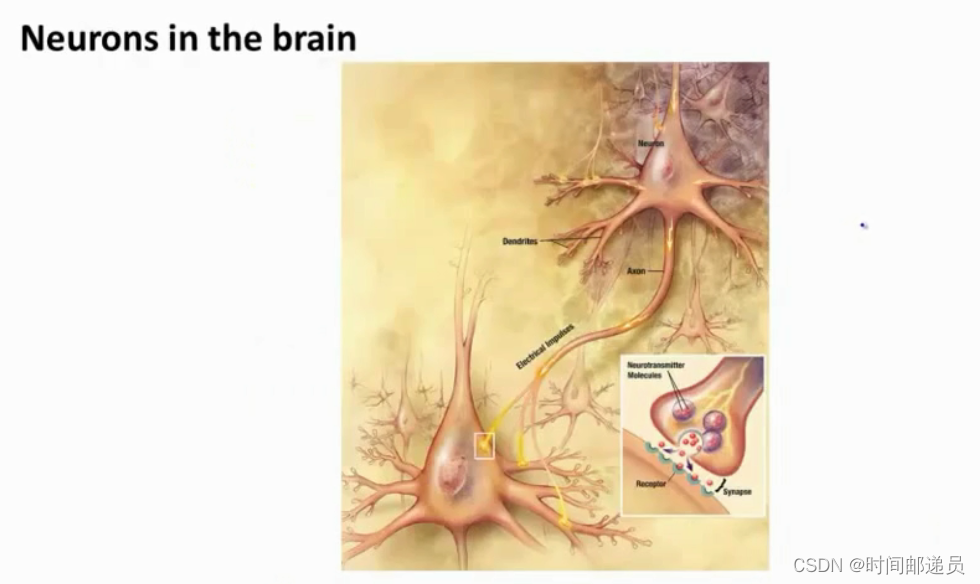
????????为了构建神经网络模型,我们需要首先思考大脑中的神经网络是怎样的,每一个神经元都可以被认为是一个处理单元/神经核,它含有许多输入/树突(input/Dendrite),并且有一个输出/轴突(output/Axon),神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。

????????下面是一组神经元的示意图,神经元利用微弱的电流进行沟通,这些弱电流也称作动作电位,所以如果神经元想要传递一个消息,它就会就通过它的轴突,发送一段微弱电流给其他神经元
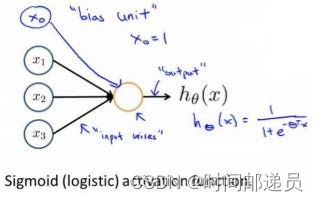
????????神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型,这些神经元(也叫激活单元,activation unit)采纳一些特征作为输入并且根据自身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中参数又可被成为权重(weight)
我们设计出了类似于神经元的神经网络,效果如下:
其中是输入单元(input units),我们将原始数据输入给它们。
是中间单元,它们负责将数据进行处理,然后传递到下一层,最后是输出单元,它负责计算
。
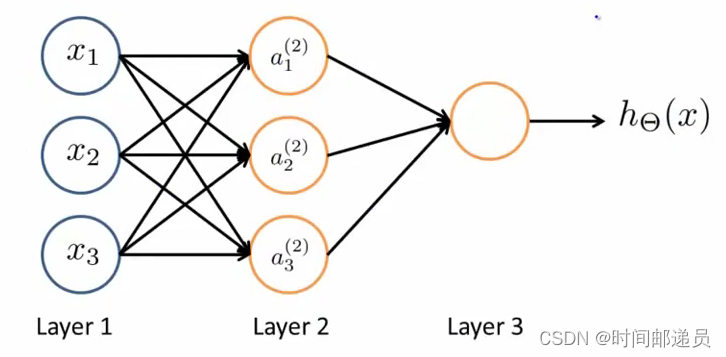
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。下图为一个3层的神经网络,第一层成为输入层(Input Layer),最后一层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers),我们为每一层都增加一个偏差单位(bias unit):

下面引入一些标记法来帮助描述模型:
代表第 j 层的第 i 个激活单元
代表从第 j 层映射到第 j+1 层时的权重的矩阵,例如
代表从第一层映射到第二层的权重的矩阵。其尺寸为:以第 j+1层的激活单元数量为行数,以第 j 层的激活单元数加一为列数的矩阵。例如:上图所示的神经网络中
的尺寸为 3*4。
对于上图所示的模型,激活单元和输出分别表达为:
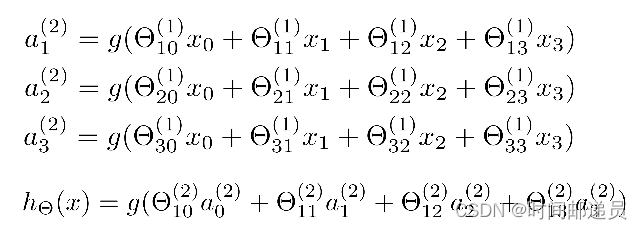
上面进行的讨论中只是将特征矩阵中的一行(一个训练实例)喂给了神经网络,我们可以知道:每一个a都是由上一层所有的x和每一个x所对应的θ决定的。我们把这样从左到右的算法称为前向传播算法( FORWARD PROPAGATION )
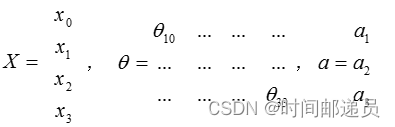
把分别用矩阵表示,我们可以得到
三、模型表示Ⅱ
????????利用向量化的方法会使得计算更为简便,以上面的神经网络为例,试着计算第二层的值:

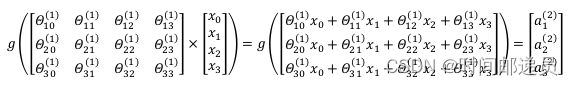
我们令,则
,计算后添加
,?计算输出的值为:
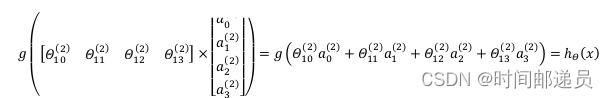
我们令 ,则
,为了更好了了解神经网络的工作原理,我们先把左半部分遮住
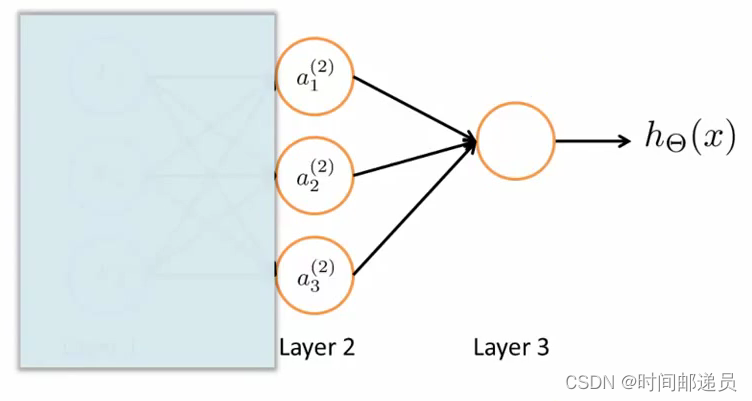
右半部分其实就是以,按照Logistic Regression的方式输出
:

其实神经网络就像是logistic regression,只不过我们把logistic regression中的输入向量变成了中间层的
,即:
?,我们可以把
看成更为高级的特征值,也就是
的进化体,并且它们是由 x与θ决定的,因为是梯度下降的,所以a是变化的,并且变得越来越厉害,所以这些更高级的特征值远比x次方厉害,也能更好的预测新数据。,这就是神经网络相比于逻辑回归和线性回归的优势。
四、特征和直观理解Ⅰ
????????从本质上讲,神经网络能够通过学习得出其自身的一系列特征。在普通的逻辑回归中,我们被限制为使用数据中的原始特征,我们虽然可以使用一些二项式项来组合这些特征,但是我们仍然受到这些原始特征的限制。在神经网络中,原始特征只是输入层,在我们上面三层的神经网络例子中,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层中的原始特征,我们可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。神经网络中,单层神经元(无中间层)的计算可用来表示逻辑运算,比如逻辑AND、逻辑或OR。
逻辑与AND
????????下图中左半部分是神经网络的设计与output层表达式,我们可以用这样的一个神经网络表示AND 函数:
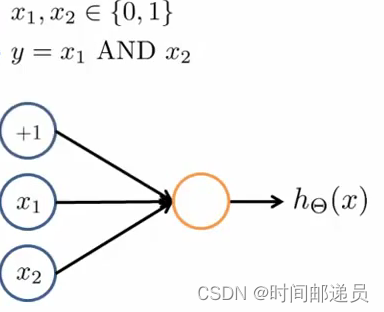
其中?
我们的输出函数为:
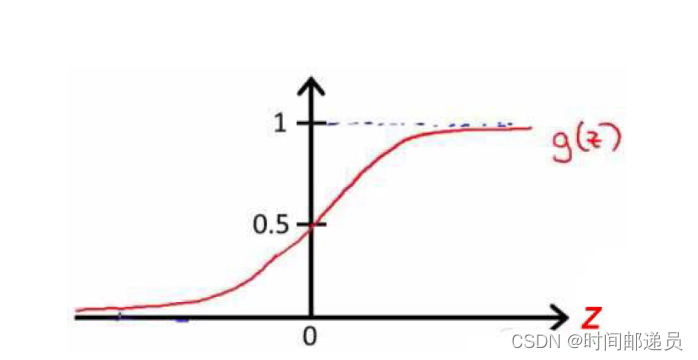
我们知道g(x)的图像是:
真值表为:

所以我们有:,这就是AND函数
逻辑或OR
OR与AND整体一样,区别只在于θ的取值不同
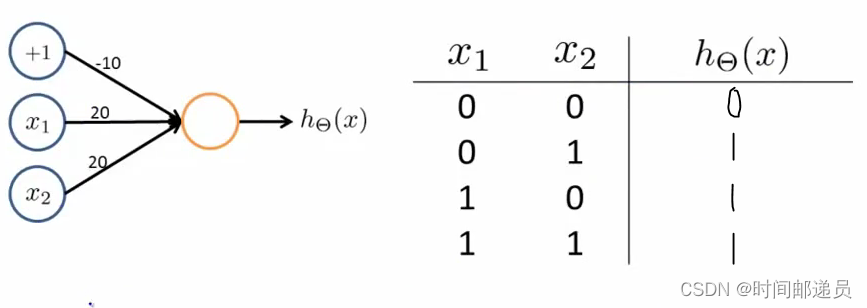
五、样本和直观理解Ⅱ
????????为了表示不同的运算符,我们选择不同的权重即可
下图的神经元(三个权重分别为-30,20,20)可以被视为作用同于逻辑与(AND):
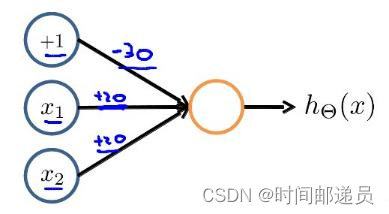
下图的神经元(三个权重分别为-10,20,20)可以被视为作用等同于逻辑或(OR):
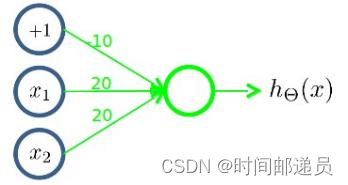
下图的神经元(两个权重分别为 10,-20)可以被视为作用等同于逻辑非(NOT):
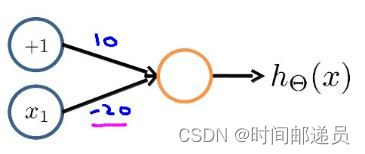
我们可以利用神经元来组合成更为复杂的神经网络以实现更复杂的运算。例如我们要实现XNOR 功能(输入的两个值必须一样,均为1或均为0)才输出1
即
首先构造一个能表达部分的神经元:

然后将表示 AND 的神经元和表示的神经元以及表示 OR 的神经元进行组合:
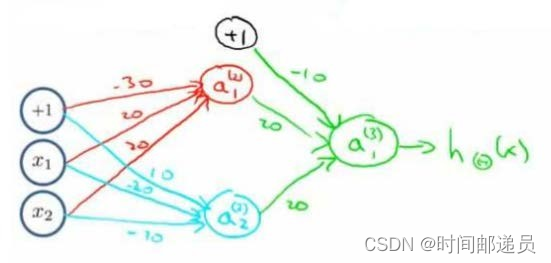
我们就得到了一个能实现 运算符功能的神经网络。按这种方法我们可以逐渐构造出越来越复杂的函数,也能得到更加厉害的特征值,这就是神经网络的厉害之处。
六、多类分类
????????如果我们要训练一个神经网络算法来识别路人、汽车、摩托车和卡车,在输出层我们应该有4个值。例如,第一个值为1或0用于预测是否是行人,第二个值为1或0用于判断是否为汽车。输入层x有三个维度,两个中间层,输出层4个神经元分别用来表示4类,也就是每一个数据在输出层都会出现,且a,b,c,d中仅有一个为1,表示当前类。下面是该神经网络的可能结构示例:
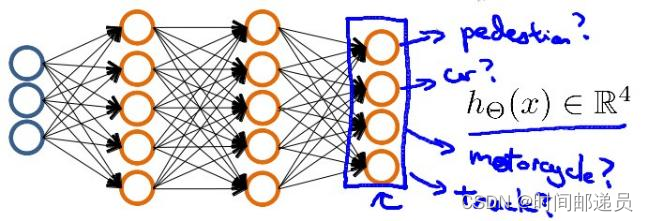

神经网络算法的输出结果为四种可能情形之一:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于SSM的在线电影票购买系统(有报告)。Javaee项目。ssm项目。
- AV1编码器的优化策略和实践技巧
- linux服务器硬盘挂载教程
- stm32cubemx下载以及安装【最新版本傻瓜式教程】
- mysql释放表空间
- Logstash输入Kafka输出Es配置
- Geotrust中的dv ssl证书
- 信息安全概论
- cubmx基础操作,hal库基本配置流程之使用 stm32cubmx生成HAL库进行gpio点亮led(stm32h7xx)(超详细,小白教程)
- 梯度提升机(Gradient Boosting Machines,GBM)