mysql高级使用教程
mysql体系结构
1.连接层:主要就是做客户端的连接。
2.服务层:主要就是 缓存,分析器,优化器,执行器。
3.引擎层:就是一些存储引擎,包括索引的存储结构。
4.存储层:数据存储的磁盘。
存储引擎
Innodb
1.特点:支持事务,支持行级锁,支持外键。
2.存储结构:xxx.ibd(存储:数据,表结构,索引)
Myisam
1.特点:速度快,支持表级锁。
2.存储结构:xxx.sdi(存储:表结构),xxx.myd(存储:数据),xxx.myi(存储:索引)
Memory
1.特点:内存存储,读取速度快。
2.存储结构:xxx.sdi(存储:表结构)
三者区别?
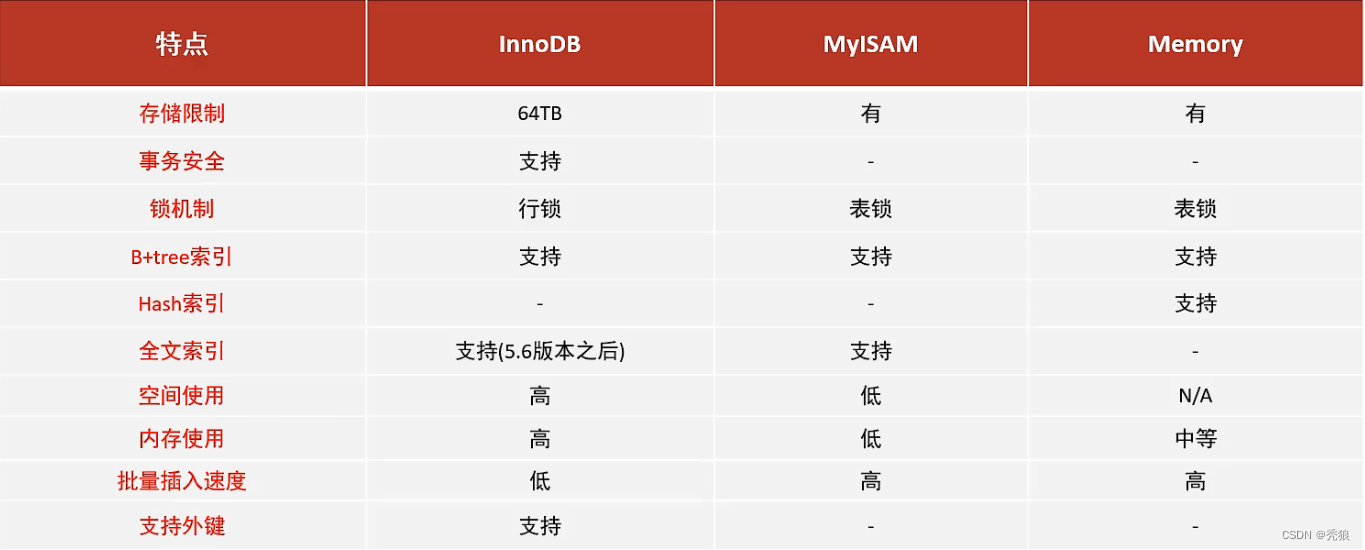
面试题
1.问:Innodb和Myisam的区别?
- Innodb支持事务,而Myisam不支持事务。
- Innodb支持行级锁和表级锁,而Myisam只支持表级锁。
- Innodb支持外键,而Myisam不支持。
2.问:存储引擎的选择上该怎么做?
- 当要求数据完整性高且并发下需要保证数据的一致性时,我们考虑选择Innodb。
- 当数据完整性要求不高,只有数据的查询和插入操作时且追求速度,此时我们考虑选择Myisam。
索引
性能分析
1.查询数据库增删改查的次数。?
show global status like '对应数据库的名字';2.慢查询(在配置文件 /mysql/etc/my.cnf中进行修改)
#开启慢查询
slow_query_log = 1
#设置最长的查询时间
long_query_time = 23.explain性能查询工具?

使用规则(索引失效情况)
1.未符合最左前缀原则(在查询条件中混合索引的最左字段必须存在)就会导致索引全部失效,如果在查询条件中跳过顺序使用查询字段会导致部分索引失效。
2.使用范围查询会导致部分索引失效,会导致范围符右侧的索引失效。解决方案:尽可能使用 >=,<=。
3.使用聚合函数会导致索引失效。
4.当查询条件发生自动类型转换(123 -> '123'),会导致索引失效。
5.使用前缀模糊查询('%abc',后缀模糊则不会失效),会导致索引失效。
6.使用or关键字可能会导致索引失效,如果有一边查询字段没有索引就会导致全部索引失效。
7.数据分布影响可能会导致索引失效。mysql会对语句进行评估,如果查询的数据基本上大于50~60%就会直接不使用索引进行查询。
索引提示
可能存在某个字段既有单独索引又被包含在复合索引中。
1.建议使用某索引
#建议mysql使用某个索引
select * from database use (column)2.忽略某个索引
#忽略某个索引
select * from database ignore (column)3.强制使用某个索引
#强制mysql使用某个索引
select * from database force (column)前缀索引
# n前缀长度
create index index_name on database(column(n))面试题
1.问:在Inonodb的索引结构选型上为什么使用B+树?
- 相比于二叉树,B+树的层数耕更低,减少io操作速度更快。
- 相比于B树,在非叶子节点上是不存储数据的,因此在非叶子节点上的页就可以存储更多的指针数据,对应的层数就会更低,速度就更快。
- 相比于hash表,hash只支持等值查询,而B+树支持范围查询,且支持排序,速度更快。
2.问:select id, username, password from database where username='123',在数据量很大的时候怎么做优化呢?
?对 username和password做联合索引。虽然它是个二级索引,但是在这个二级索引中包含了id的数正好有查询的所有字段,就不会做回表操作。
SQL优化
插入数据
当我们需要插入多条数据的时候,如果一条条插入的话就会出现事务的频繁开启和关闭,效率十分的低下。因此我们可以使用load指令(从本地加载数据),速度上会快很多。因为是顺序插入的原因所以速度上会比乱序插入快很多。
#在客户端连接的时候开启本地环境
mysql --local-infile -u root -p
#全局设置
set global local_infile = 1
#执行对应的本地文件
local data local infile '对应的文件名' into table `tableName` fields terminated by ',' lines terminated by '\n';主键
页分裂:主键底层是存到数据页上,一遍主键是自增的,所以会进行顺序存储。但是当数据不按顺序的时候会,数据在找到对应的位置会会将后百分之五十的数据存储到新的页上,如何将新的看数据存储到对应的位置上,最终在调整页的位置。(图中是插入50后的页分裂)

?页合并:但主键进行删除的时候,会先将要删除的数据进行标记,当达到阈值(MERGE_THRESHOLD)时就会进行删除,并判断前后侧的页是否能合并,能就进行合并,最终出现页合并。
主键设置的原则
1.在满足业务要求的情况下,尽量保证主键的长度较短。因为二级索引中的数据就会主键,当二级索引多的情况就会占用大量的空间,并在数据的读取的时候需要大量的io操作。
2.插入的主键尽量保证有序也就是自增,减少页分裂发生的概率。
3.尽量不要使用uuid作为主键。这会导致页分裂的概率大大增加。
4.在编写业务时,尽量不要修改主键,避免页分裂的发生。
Order By?
在使用Order By的时候如果没有使用索引的话就会在缓冲区中按照对应的字段进行排序,效率上比较低,因此我们可以创建对应的索引结构来减少此排序操作。
Order By 优化
1. 在使用排序语句的时候要创建索引,当存在多个字段的时候我们可以使用混合索引,达到覆盖索引的效果,并且在这个过程中符合最左前缀原则。
2.当排序字段存在已升序一降序的时候,我们在创建对应的混合索引的时候也要设置对应的排序方式。(默认是升序)
3.如果无法避免缓冲区排序的操作,那么我们可以设置更大的缓存区。
limit
使用覆盖索引 + 子查询来优化sql,先通过条件查询出符合条件的主键信息,已改主键最为一张表查询对应的所有字段信息。
count
count(主键):直接遍历整张表,把每行的id取出来,因为主键不可为null。
count(字段):遍历整张表,把每行的字段值取出来,但值不为null直接总个数 + 1.
count(*):遍历整张表,但不会取值,速度较快。
count(num):遍历整张表并且不会取值,对不为null的行放个num进去,并进行累加。
update
要确保操作的字段存在索引,这样就可以保证在每次进行事务操作的时候只会使用行级锁,如果操作的字段不是索引就会导致行级锁升级为表级锁。但是事务并发场景效率低下。
锁
表级锁
锁的类型
1.表级锁。
2.元数据锁。

3.意向锁:为了解决加锁冲突,在innodb中行锁和表锁加锁的冲突问题。(意向锁之间是相互兼容的)
意向共享锁(IS):在执行select...lock in share mode语句的时候就会添加该锁。(其与表锁中的读锁是兼容的,和写锁是互斥的)
意向排他锁(IX):在执行 insert,update,select...for update时添加。(其与表锁中的读写锁都互斥)
行级锁
锁的类型
1.行级锁:锁住对应行的数据,防止其他事务修改,在读已提交,可重复读级别下都是支持的。分为共享锁和排他锁。

2.间隙锁:锁住索引之间的间隙。防止其他事务做insert操作导致幻读的情况,可重复读级别下是支持的。
3.临键锁:可以理解成行级锁 + 间隙锁,其会锁住行数据和数据前后的间隙。可重复读级别下是支持的。
如果在做insert操作的时候,对应的条件字段没有建立索引的话就会导致锁升级:行级锁->表级锁。
行锁的使用
1.如果条件字段是唯一索引,并且给不存在的数据加锁的时候(就比如需要某个不存在的数据时),就会添加间隙锁,锁住该数据应该存储的位置的间隙。
2.如果条件字段不是唯一索引,相同的数据会相邻存储,会使用临键锁,锁住当前数据和数据前后的间隙。(如果条件时 >=这种区间的话,就会锁住当前行和后续的间隙吗,对应的无穷大)
3.间隙锁是可以共存的,一个事务使用的间隙锁不会影响其他事务使用间隙锁。
InnoDB引擎
内存结构
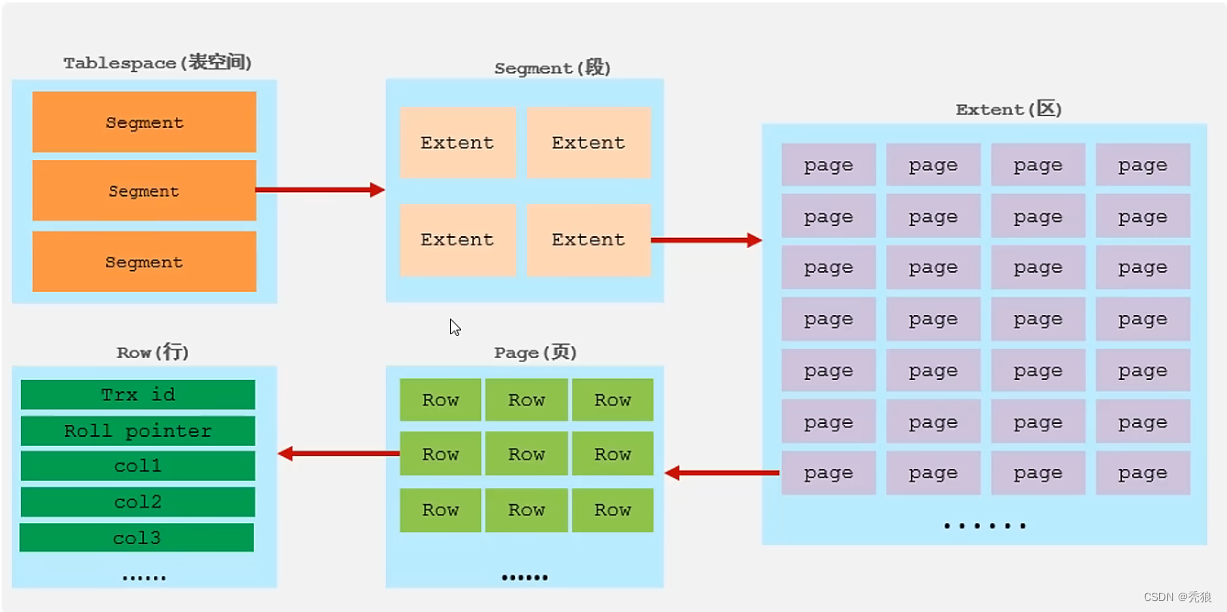
框架结构

?内存区
1.Buffer Pool:缓存区,减少io操作,加快速度。
2.Change Buffer(针对非唯一非一二级索引):更改缓冲区,在执行DML(增删改查),如果缓冲区中没有该数据的话就会像存储到Change Buffer中,最终做同步操作。
3.Log Buffer:用于存储日志的缓冲区。
4.在缓冲区中分为三种page:
- free page:未被使用的page。
- clean page:被使用但数据没有被修改。
- dirty page:脏页,数据被修改但是数据未同步。
磁盘区:主要就是存储change page,rado log, undolog等一些表的信息。
后台线程:用于做缓冲区和磁盘的同步。
1.Mater Thread:核心后台线程,负责调度其他线程。
2.IO Thread:主要就是负责做IO的操作。

3.Purge Thread:主要就是负责回收事务已提交的undo log,在事务提交后undo log就需要被回收。
4.Page Cleaner Thread
协助Master Thread 刷新脏数据到磁盘中,减少堵塞。
MVCC
当前读:读取的就是最新的版本的数据
快照读:读取的数据可能是历史版本。
MVCC的三大部分
1.隐藏字段:
DB_TRX_ID(事务id):当前修改的事务。
DB_ROLL_ID(指向上一版本的地址):回滚指针,通过undo和回滚指针构成版本链。
DB_ROW_ID(主键id):当不存在主键或唯一索引的时候机会自动生成隐藏的主键id。
2.undo:用于表示不同的版本。
3.readview:用于选择版本,按照规则选择版本。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于xgboost-LGBM-SVM的病人哮喘病识别检测 数据+代码
- Spark八:Spark性能优化
- LabVIEW开发滚筒洗衣机动态监测系统
- 【深入浅出Java性能调优】「底层技术原理体系」深入探索Java服务器性能监控Metrics框架的实现原理分析(Gauge和Histogram篇)
- 【科研】[3.番外篇] 常见基础科研词汇的介绍!非常基础的一期,大家选择观看哟~
- Kafka 原理及使用
- 【Antlr】Antlr 使用语法分析树监听器编写程序、Antlr 解析 Properties 格式、监听器模式
- 赛氪公开课|AI发展的影响与对策
- dll不能运行是什么意思,分享5种有效的修复方法
- 半自动和全自动打包机的差别有多大