预训练、微调和上下文学习(备忘)
最近语言模型在自然语言理解和生成方面取得了显著进展。这些模型通过预训练、微调和上下文学习的组合来学习。在本文中将深入研究这三种主要方法,了解它们之间的差异,并探讨它们如何有助于语言模型的学习过程。

预训练
预训练(Pre-training)是语言模型学习的初始阶段。 在预训练期间,模型会接触到大量未标记的文本数据,例如书籍、文章和网站。 在大量未标记文本数据上训练语言模型。 比如说在包含数百万本书、文章和网站的数据集上预训练像 GPT-3 这样的语言模型。 预训练目标是捕获文本语料库中存在的底层模式、结构和语义知识。

主要特点:
-
无监督学习:预训练通常是一个无监督学习过程,模型在没有明确指导或标签的情况下从未标记的文本数据中学习。
-
Masked Language Modeling:模型经过训练以预测句子中缺失或屏蔽的单词,学习上下文关系并捕获语言模式。
-
Transformer 架构:预训练通常采用基于 Transformer 的架构,因为这种架构擅长捕获远程依赖关系和上下文信息。
预训练模型作为广泛的自然语言处理任务的基础,例如文本分类、命名实体识别和情感分析。因为它们提供了对语言的一般理解,并且可以针对特定的下游任务进行微调。
预训练的主要下游任务如下:
-
文本生成:预训练模型可以生成连贯且上下文相关的文本,使它们对聊天机器人、虚拟助手和内容生成等应用程序有价值。
-
语言翻译:预训练模型可以针对机器翻译任务进行微调,使它们能够准确地将文本从一种语言翻译成另一种语言。
-
情感分析:通过对带有情感标签的数据集的预训练模型进行微调,它们可用于对文本输入的情感进行分类,协助完成客户反馈分析和社交媒体监控等任务。
-
命名实体识别:可以对预训练模型进行微调,以从文本中识别和提取命名实体,从而促进新闻文章或法律文件中的实体识别等任务。
微调
微调(Fine-Tuning)是在特定任务或领域上进一步训练大型语言模型(LLM)的过程。这可以通过使用预训练的LLM作为起点,然后在特定任务或领域的标记数据集上训练它来完成。微调可以通过调整模型的权重来更好地拟合数据,从而提高LLM在特定任务或领域上的性能。

监督微调(Supervised Fine-Tuning)
SFT使用标记数据来训练LLM。标记的数据由输入和输出数据对组成。输入数据是LLM将得到的数据,输出数据是LLM期望生成的数据。SFT是一种相对简单和有效的方法来微调LLM。
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback)
RLHF使用人类反馈来训练LLM。反馈可以通过多种方式收集,例如调查、访谈或用户研究。RLHF是一种更复杂、更耗时的方法来微调LLM,但它比SFT更有效。
应该使用哪种方法?
微调 LLM 的最佳方法取决于许多因素,例如标记数据的可用性、可用时间和资源以及所需的性能。 如果有很多可用的标记数据,SFT 是一个不错的选择。但是如果没有可用的标记数据,或者如果需要将 LLM 的性能提高到 SFT 无法达到的水平,RLHF 是一个不错的选择,但是RLHF 需要更多的事件和后期的人工参与。
微调的好处
微调可以提高 LLM 在特定任务或领域上的性能,可以为自然语言生成、问答和翻译等任务带来更好的结果。 微调还可以使 LLM 更具可解释性,这有助于调试和理解模型的行为。
所以Fine-tuning 是语言模型学习过程中的后续步骤。 在经过预训练后,模型根据特定于任务的标记数据进行微调,以使其知识适应特定的下游任务。
-
迁移学习:微调利用迁移学习,其中模型将学习到的表示从预训练转移到目标任务。
-
特定于任务的数据:模型在特定于目标任务的标记数据上进行训练,例如带有情感标记的句子或问答对。
-
基于梯度的优化:微调通常涉及基于梯度的优化技术,以根据特定于任务的数据更新模型的参数。
微调使模型能够在各种特定的自然语言处理任务中表现出色,包括情感分析、问题回答、机器翻译和文本生成。像BERT这样的预训练语言模型可以在标有积极或消极情绪的客户评论数据集上进行微调。一般的微调任务如下:
-
情感分析:微调模型可以用于情感分析任务,例如分析客户评论、社交媒体情感监控和市场研究。
-
文本分类:微调允许模型将文本分类到预定义的类别中,从而支持主题分类、垃圾邮件检测和文档分类等应用程序。
-
问答:通过对问答对进行微调,可以使用模型根据给定的上下文回答特定的问题,帮助完成客户支持和信息检索等任务。
上下文学习
上下文学习(In-Context Learning)也可以翻译成情境学习:是一种新兴的方法,它结合了预训练和微调,同时在训练过程中结合特定任务的指令或提示。模型学会根据给定的指令生成与上下文相关的响应或输出,从而提高它们在特定任务中的表现。
随着大模型(GPT3,Instruction GPT,ChatGPT)的横空出世,如何更高效地提示大模型也成了学术界与工业界的关注,因此 In-context learning 的方法在 NLP 领域十分火热。
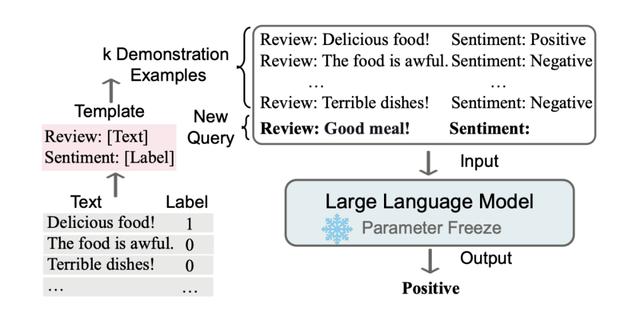
ICL的关键思想是从类比中学习。上图给出了一个描述语言模型如何使用 ICL 进行决策的例子。首先,ICL 需要一些示例来形成一个演示上下文。这些示例通常是用自然语言模板编写的。然后 ICL 将查询的问题(即你需要预测标签的 input)和一个上下文提示(一些相关的 cases)连接在一起,形成带有提示的输入,并将其输入到语言模型中进行预测。
上下文提示:上下文学习包括提供明确的指令或提示,以指导模型在生成响应或输出时的行为。
强化学习或结构化反馈:上下文学习可以结合强化学习技术或结构化反馈来指导模型的响应。
迭代训练:模型经历多次迭代训练,接收反馈并根据提供的提示改进它们的响应。
上下文学习在各种任务中显示出有希望的结果,包括问题回答,对话系统,文本完成和文本摘要。它允许模型生成上下文一致的和特定于任务的输出。
上下文学习与预训练和微调的关系
预训练侧重于从大规模未标记数据中进行无监督学习,获取一般语言理解。微调建立在预训练的基础上,并使用特定于任务的标记数据使模型适应特定的任务,从而实现专门的性能。上下文学习在训练过程中包含特定于任务的指令或提示,指导模型的行为并提高任务性能。
上下文学习包括训练语言模型,以根据特定的指令或提示生成与上下文相关的响应。主要训练语言模型以礼貌和有用的方式生成对客户查询的响应
-
聊天机器人和虚拟助手:上下文学习允许聊天机器人和虚拟助手为用户查询提供更适合上下文和有用的响应,增强用户体验。
-
对话系统:通过结合上下文学习,模型可以产生连贯和引人入胜的对话,改善对话系统中的人机交互。
-
个性化推荐:可以使用上下文学习来训练模型,根据用户偏好和历史数据提供个性化推荐,提高推荐的准确性和相关性。
总结
语言模型通过预训练、微调和上下文学习的结合来学习。预训练捕获一般的语言理解,微调专门针对特定任务的模型,而上下文学习包含特定任务的指令以提高性能。理解这些方法可以深入了解语言模型学习过程中涉及的不同阶段和技术,从而使它们能够有效地应用于各种自然语言处理任务。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux每日智囊
- 【pwn】hitcontraining_uaf --堆利用之uaf
- 万万没想到之抓捕孔连顺
- 函数装饰器基础
- 应急响应排查Linux中的secure和message日志如何排查
- LeetCode 2610. 转换二维数组【数组,哈希表】1373
- Java的内部类主要分为哪几种?分别简单的举例实现
- 训练好的YOLO模型的预测过程是什么样的。
- Day67内网安全-域横向smb&wmi明文|哈希
- 深入剖析:Kafka流数据处理引擎的核心面试问题解析75问(5.7万字参考答案)