如何创建/查看/修改/查询/删除数据库表,向表中插入数据,表的本质,修改表的操作(重命名,添加/修改/更改/删除属性)
目录
表的操作
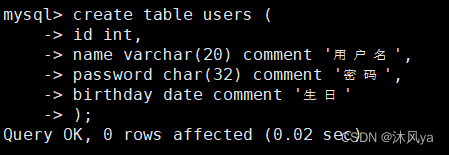
创建数据库表
create table + ( if not exists ) + 表名 + (属性列) ( + 编码格式设置 + 存储引擎设置 )
属性列格式
属性名 + 数据类型(大小) ( + comment '文字说明' )
- 多个属性以,相连
- 大小的设置适用于部分类型
- 文字说明用于补充属性信息
编码格式设置
设置编码集
- charset = 格式名?
- character set 格式名
设置校验集
- collate?格式名
- collate =?格式名
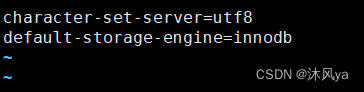
如果不手动设置,会使用数据库的默认编码格式
本质 -- 文件
上面我们使用sql语句创建了users表
那在文件系统上,是如何表现的呢?
- 我们进入d2目录后,会发现,有两个users有关的文件:
所以,创建表的本质,其实就是在当前目录下创建出几个文件

存储引擎设置
engine + 存储引擎名
使用不同的存储引擎
我们在d2中创建出的users表,使用的是默认存储引擎,也就是innodb:
而使用了innodb的表,创建出的是.frm 和 .ibd这两个文件
- .frm -- 代表表结构
- .ibd -- 代表innodb的数据和索引都存放在这个文件中
当我们建立一个使用myisam的表,发现创建出的是?.frm,MYD和.MYI这三个文件
- .frm -- 代表表结构
- MYD和.MYI -- 分别代表myisam的数据文件和索引文件
说明,不同的存储引擎,存储方式都各有不同

查看表信息
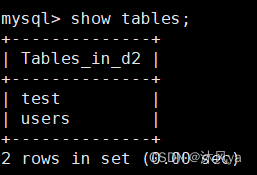
查看当前库拥有的表
show tables
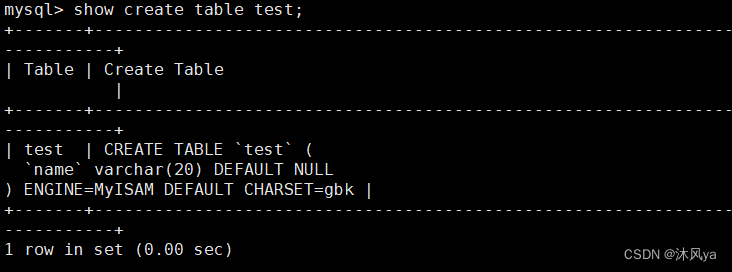
查看创建表时所用语句
show create table + 表名
show create table + 表名 + \G (格式化)
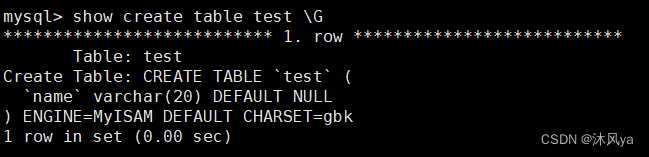
查询指定表的详细信息
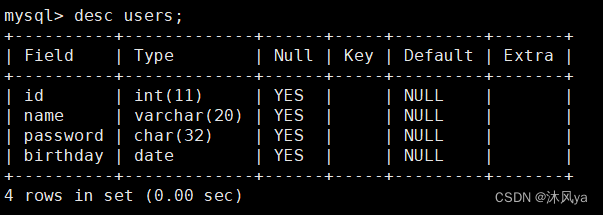
desc + 表名
可以查看该表的各个属性的设置
修改表信息
alter table + 表名 + 操作
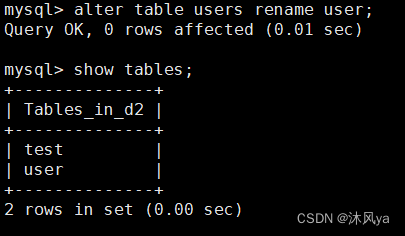
重命名
rename ( to )?+ 新名字
- 结合表的本质是普通文件,这个重命名的操作是不是和mv很像
- 所以它实际上就是使用了mv命令底层的系统调用
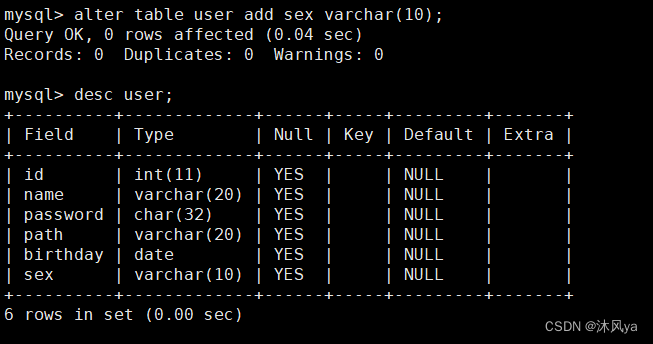
添加属性
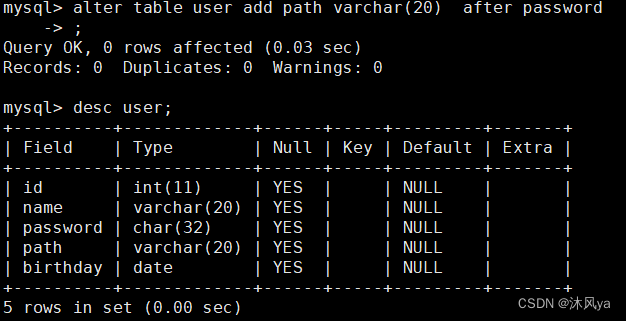
add + 属性列 (+ after 属性列名)
默认添加到属性列末尾
指定添加属性的位置
after + 属性名,可以将新属性添加到指定的属性之后:
修改属性
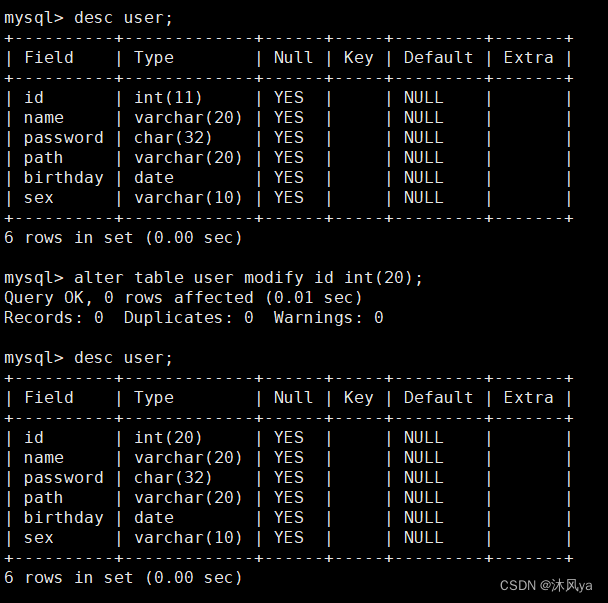
modify + 属性名 + 新属性
- 该属性的其他设置也需要带上,不然就没了,因为是覆盖修改
- 修改后,原先id有的comment就没有了:

更改属性
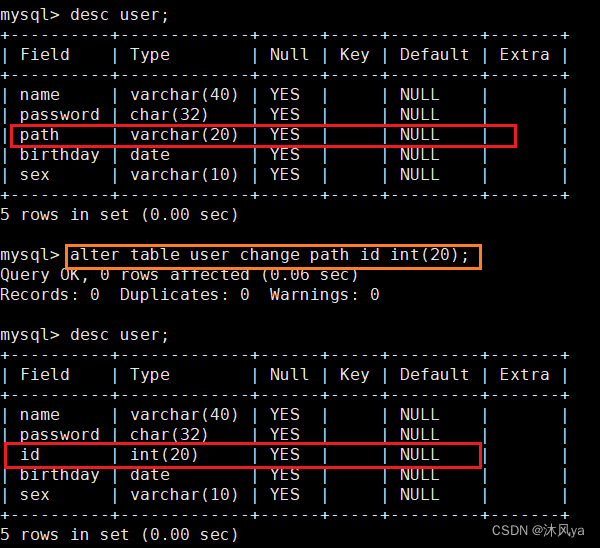
change + 原名称 + 新名称 + 新属性
我们将path这个属性,修改为id
删除属性
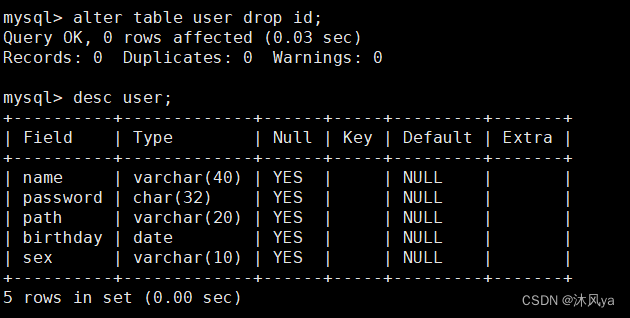
drop + 属性列名
删除表
drop table + 表名?
向表中插入数据
insert into + 表名 ( +(属性列名) ) + values (数据)
指定属性
插入的数据要和手动输入的属性名对应着来

省略属性列
需要将所有属性都插入值,并且要按照原属性列顺序来

查询数据库某个表单内容
select * from + 数据库表名 (where 属性列 = ' xx' )
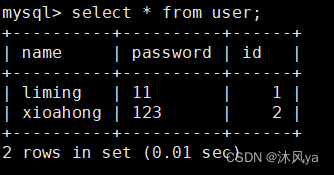
逻辑存储格式
从上面可以看到,我们查询到的表,以表格形式呈现给我们
数据以表格形式存储,每个表代表一种实体或关系
表中的数据按列组织,每列定义了一种数据类型
表中的数据按行存储,每行包含了一条完整的数据记录
where
从拿到的数据中找到匹配某属性=xx的行
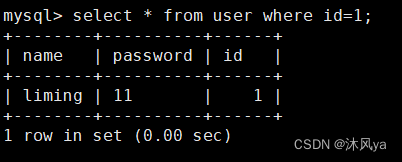
按某列排序
order by + 属性列名

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【面试高频算法解析】算法练习6 广度优先搜索
- 柯南M26黑铁的鱼影——跨龄人脸识别
- 获取JSON里面result的值 将(List数组或对象)转换出来并读取
- Linux分割合并文件
- 清理电脑c盘爆满,不会影响软件功能的方法,这些有效
- [Spark] 将dataframe的数据保存到mysql
- 揭秘家用缝纫机电机霍尔板的多功能特性
- 解决pycharm格式化程序自动删除未使用的import或代码行
- CentOS 防火墙管理及使用的redis基本常用命令
- 阿里云服务器CPU内存配置怎么选择?