Java泛型图文详解
一:泛型本质
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,即给类型指定一个参数,然后在使用时再指定此参数具体的值,那样这个类型就可以在使用时决定了。这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
二:为什么使用泛型
泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
(1)保证了类型的安全性。
在没有泛型之前,从集合中读取到的每一个对象都必须进行类型转换,如果不小心插入了错误的类型对象,在运行时的转换处理就会出错。
比如:没有泛型的情况下使用集合:
public static void noGeneric() {
ArrayList names = new ArrayList();
names.add("mikechen的互联网架构");
names.add(123); //编译正常
}
有泛型的情况下使用集合:
public static void useGeneric() {
ArrayList<String> names = new ArrayList<>();
names.add("mikechen的互联网架构");
names.add(123); //编译不通过
}
有了泛型后,定义好的集合names在编译的时候add(123)就会编译不通过。
相当于告诉编译器每个集合接收的对象类型是什么,编译器在编译期就会做类型检查,告知是否插入了错误类型的对象,使得程序更加安全,增强了程序的健壮性。
(2) 消除强制转换
泛型的一个附带好处是,消除源代码中的许多强制类型转换,这使得代码更加可读,并且减少了出错机会。
还是举例说明,以下没有泛型的代码段需要强制转换:
List list = new ArrayList();
list.add("hello");
String s = (String) list.get(0);
当重写为使用泛型时,代码不需要强制转换:
List<String> list = new ArrayList<String>();
list.add("hello");
String s = list.get(0); // no cast
(3)避免了不必要的装箱、拆箱操作,提高程序的性能
在非泛型编程中,将筒单类型作为Object传递时会引起Boxing(装箱)和Unboxing(拆箱)操作,这两个过程都是具有很大开销的。引入泛型后,就不必进行Boxing和Unboxing操作了,所以运行效率相对较高,特别在对集合操作非常频繁的系统中,这个特点带来的性能提升更加明显。
泛型变量固定了类型,使用的时候就已经知道是值类型还是引用类型,避免了不必要的装箱、拆箱操作。
object a=1;//由于是object类型,会自动进行装箱操作。
?
int b=(int)a;//强制转换,拆箱操作。这样一去一来,当次数多了以后会影响程序的运行效率。
使用泛型之后
public static T GetValue<T>(T a)
?
{
return a;
}
?
public static void Main()
?
{
int b=GetValue<int>(1);//使用这个方法的时候已经指定了类型是int,所以不会有装箱和拆箱的操作。
}
(4)提高了代码的重用性。
三:如何使用泛型
泛型有三种使用方式,分别为:泛型类、泛型接口和泛型方法。
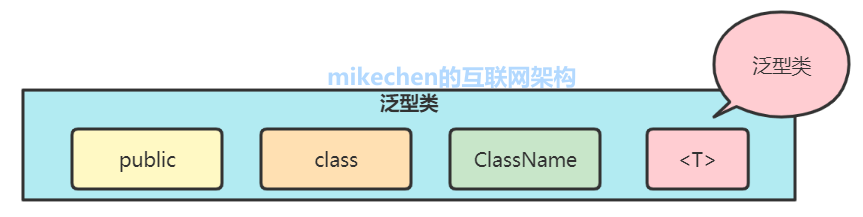
1、泛型类
泛型类:把泛型定义在类上
定义格式:
public class 类名 <泛型类型1,...> {
????
}
注意事项:泛型类型必须是引用类型(非基本数据类型)
定义泛型类,在类名后添加一对尖括号,并在尖括号中填写类型参数,参数可以有多个,多个参数使用逗号分隔:
public class GenericClass<ab,a,c> {}
当然,这个后面的参数类型也是有规范的,不能像上面一样随意,通常类型参数我们都使用大写的单个字母表示:
T:任意类型 type
E:集合中元素的类型 element
K:key-value形式 key
V: key-value形式 value
示例代码:
泛型类:
public class GenericClass<T> {
????private T value;
?
?
????public GenericClass(T value) {
????????this.value = value;
????}
????public T getValue() {
????????return value;
????}
????public void setValue(T value) {
????????this.value = value;
????}
}
测试类:
//TODO 1:泛型类
GenericClass<String> name = new GenericClass<>("mikechen的互联网架构");
System.out.println(name.getValue());
?
?
GenericClass<Integer> number = new GenericClass<>(123);
System.out.println(number.getValue());
运行结果:

2、泛型接口
泛型方法概述:把泛型定义在方法上
?
定义格式:
public <泛型类型> 返回类型 方法名(泛型类型 变量名) {
????
}
注意要点:
-
- 方法声明中定义的形参只能在该方法里使用,而接口、类声明中定义的类型形参则可以在整个接口、类中使用。当调用fun()方法时,根据传入的实际对象,编译器就会判断出类型形参T所代表的实际类型。
public interface GenericInterface<T> {
void show(T value);}
}
public class StringShowImpl implements GenericInterface<String> {
@Override
public void show(String value) {
System.out.println(value);
}}
?
public class NumberShowImpl implements GenericInterface<Integer> {
@Override
public void show(Integer value) {
System.out.println(value);
}}
注意:使用泛型的时候,前后定义的泛型类型必须保持一致,否则会出现编译异常:
GenericInterface<String> genericInterface = new NumberShowImpl();//编译异常
或者干脆不指定类型,那么 new 什么类型都是可以的:
GenericInterface g1 = new NumberShowImpl();
GenericInterface g2 = new StringShowImpl();
3、泛型方法
泛型方法,是在调用方法的时候指明泛型的具体类型 。
- 定义格式:
修饰符?<代表泛型的变量>?返回值类型 方法名(参数)
例如:
/**
?????*
?????* @param t 传入泛型的参数
?????* @param <T> 泛型的类型
?????* @return T 返回值为T类型
?????* 说明:
?????*???1)public 与 返回值中间<T>非常重要,可以理解为声明此方法为泛型方法。
?????*???2)只有声明了<T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
?????*???3)<T>表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。
?????*???4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E等形式的参数常用于表示泛型。
?????*/
????public <T> T genercMethod(T t){
????????System.out.println(t.getClass());
????????System.out.println(t);
????????return t;
????}
?
?
public static void main(String[] args) {
????GenericsClassDemo<String> genericString??= new GenericsClassDemo("helloGeneric"); //这里的泛型跟下面调用的泛型方法可以不一样。
????String str = genericString.genercMethod("hello");//传入的是String类型,返回的也是String类型
????Integer i = genericString.genercMethod(123);//传入的是Integer类型,返回的也是Integer类型
}
?
?
class java.lang.String
hello
?
?
class java.lang.Integer
123
这里可以看出,泛型方法随着我们的传入参数类型不同,他得到的类型也不同。泛型方法能使方法独立于类而产生变化。
四:泛型通配符
Java泛型的通配符是用于解决泛型之间引用传递问题的特殊语法, 主要有以下三类:
//表示类型参数可以是任何类型
public class Apple<?>{}
?
//表示类型参数必须是A或者是A的子类
public class Apple<T extends A>{}
?
//表示类型参数必须是A或者是A的超类型
public class Apple<T supers A>{}
1. 无边界的通配符(Unbounded Wildcards), 就是, 比如List
无边界的通配符的主要作用就是让泛型能够接受未知类型的数据.
2. 固定上边界的通配符(Upper Bounded Wildcards),采用<? extends E>的形式
使用固定上边界的通配符的泛型, 就能够接受指定类及其子类类型的数据。
要声明使用该类通配符, 采用<? extends E>的形式, 这里的E就是该泛型的上边界。
注意: 这里虽然用的是extends关键字, 却不仅限于继承了父类E的子类, 也可以代指显现了接口E的类
3. 固定下边界的通配符(Lower Bounded Wildcards),采用<? super E>的形式
使用固定下边界的通配符的泛型, 就能够接受指定类及其父类类型的数据.。
要声明使用该类通配符, 采用<? super E>的形式, 这里的E就是该泛型的下边界.。
注意: 你可以为一个泛型指定上边界或下边界, 但是不能同时指定上下边界。
五:泛型中KTVE的含义
果点开JDK中一些泛型类的源码,我们会看到下面这些代码:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
...
}
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
...
}
上面这些泛型类定义中的泛型参数E、K和V都是什么意思呢?其实这些参数名称是可以任意指定,就想方法的参数名一样可以任意指定,但是我们通常会起一个有意义的名称,让别人一看就知道是什么意思。泛型参数也一样,E一般是指元素,用来集合类中。
常见泛型参数名称有如下:
E: Element (在集合中使用,因为集合中存放的是元素)
T:Type(Java 类)
K: Key(键)
V: Value(值)
N: Number(数值类型)
?: 表示不确定的java类型
六:泛型的实现原理
泛型本质是将数据类型参数化,它通过擦除的方式来实现,即编译器会在编译期间「擦除」泛型语法并相应的做出一些类型转换动作。
看一个例子就应该清楚了,例如:
public class Caculate<T> {
private T num;
}
我们定义了一个泛型类,定义了一个属性成员,该成员的类型是一个泛型类型,这个 T 具体是什么类型,我们也不知道,它只是用于限定类型的。
反编译一下这个 Caculate 类:
public class Caculate{
public Caculate(){}
private Object num;
}
发现编译器擦除 Caculate 类后面的两个尖括号,并且将 num 的类型定义为 Object 类型。
那么是不是所有的泛型类型都以 Object 进行擦除呢?大部分情况下,泛型类型都会以 Object 进行替换,而有一种情况则不是。那就是使用到了extends和super语法的有界类型,如:
public class Caculate<T extends String> {
private T num;
}
这种情况的泛型类型,num 会被替换为 String 而不再是 Object。
这是一个类型限定的语法,它限定 T 是 String 或者 String 的子类,也就是你构建 Caculate 实例的时候只能限定 T 为 String 或者 String 的子类,所以无论你限定 T 为什么类型,String 都是父类,不会出现类型不匹配的问题,于是可以使用 String 进行类型擦除。
实际上编译器会正常的将使用泛型的地方编译并进行类型擦除,然后返回实例。但是除此之外的是,如果构建泛型实例时使用了泛型语法,那么编译器将标记该实例并关注该实例后续所有方法的调用,每次调用前都进行安全检查,非指定类型的方法都不能调用成功。
实际上编译器不仅关注一个泛型方法的调用,它还会为某些返回值为限定的泛型类型的方法进行强制类型转换,由于类型擦除,返回值为泛型类型的方法都会擦除成 Object 类型,当这些方法被调用后,编译器会额外插入一行 checkcast 指令用于强制类型转换,这一个过程就叫做『泛型翻译』。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PID横向控制和仿真实现
- MetaGPT( The Multi-Agent Framework):颠覆AI开发的革命性多智能体元编程框架
- Docker Harbor私有镜像image仓库安装
- 秋招复习之树
- Python生成器(Generator)(继续更新...)
- 如何使用xlwings库为Excel表格的单元格创建超链接----关于Python里xlwings库对Excel表格的操作(三十九)
- JetBrains Rider使用总结
- linux RCU机制介绍
- zookeeper【封神录】下篇
- java/php/node.js/python基于的考研信息共享平台【2024年毕设】