数仓日常维护:剖析每日增量同步的内部机制
数仓日常维护:剖析每日增量同步的内部机制
一、前言
在现代企业中,离线仓库扮演着不可或缺的角色。它充当着一个数据的中心枢纽,存储和管理着海量的信息。作为企业数据分析、业务决策和预测的基石,离线仓库的重要性不言而喻。
而数据的实时性和准确性对于确保数据仓库的有效性至关重要。而离线数仓中常见的数据同步方式是T+1,其中同步方式主要分为两种:全量同步和增量同步。
本文聚焦于探讨增量同步的原理,解析其工作机制和实现方法。
二、场景
在大数据平台中,业务部门常常需要查看历史某一天的表数据。为了记录历史数据的变化,常见的解决方案包括拉链表和快照表。然而,由于拉链表的实现方式和查询方式较为复杂不便直观的展现问题,因此在这里我选择使用快照表作为示例,以便更清晰地阐述离线数仓的数据一致性问题。
快照表是用来存储某个时间点的所有数据-通常粒度是天,相当于是对每天的业务数据做了一次快照,存储当天的全量数据;例如:快照表12号分区中的数据是从历史到11号的所有数据,13号分区中的数据是从历史到12号的所有数据,其他的以此类推,示例如下:
- [Mysql] 业务数据 - 用户表全量数据:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
- [数仓]由于离线数仓是T+1处理,故2023-06-02时数仓快照表数据如下:
| id | name | phone | gender | create_time | update_time | dt[分区字段] |
|---|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | 2023-06-01 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | 2023-06-01 |
| 3 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | 2023-06-01 |
加粗为分区字段
- [Mysql] 2023-06-02 业务数据新增了一名用户,且更改了tom的手机号,此时表数据如下:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 444 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 |
| 4 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 |
加粗为更新/新增数据
- [数仓]由于离线数仓是T+1处理,故2023-06-03时数仓快照表数据如下:
| id | name | phone | gender | create_time | update_time | dt[分区字段] |
|---|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | 2023-06-01 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | 2023-06-01 |
| 3 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | 2023-06-01 |
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | 2023-06-02 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | 2023-06-02 |
| 3 | tom | 444 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 | 2023-06-02 |
| 4 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 | 2023-06-02 |
加粗为更新/新增数据
以上是快照表的表现形式,具体实现方式如下
三、实现
3.1、全量同步
全量同步顾名思义是将业务数据用户表全量同步一份到数仓快照表中的指定分区内,该方式简单粗暴,这里以:2.1、示例中的 2023-06-02业务数据新增了一名用户,且更改了tom的手机号为例;过程如下:
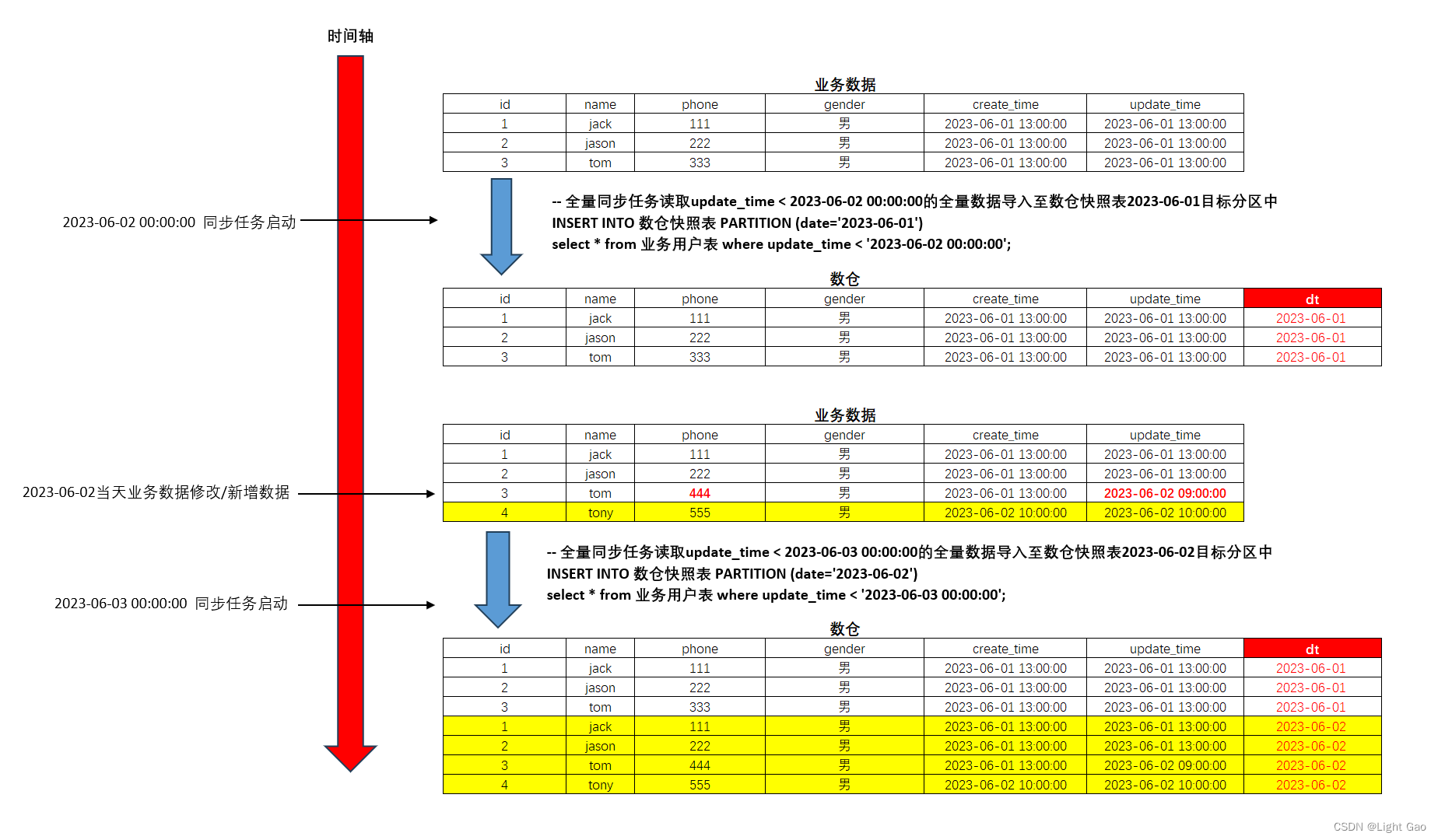
- sql语句:
# 2023-06-03凌晨执行的全量同步sql语句
INSERT INTO 数仓快照表 PARTITION (date='2023-06-02')
select * from 业务用户表 where update_time < '2023-06-03 00:00:00';
3.2、增量同步
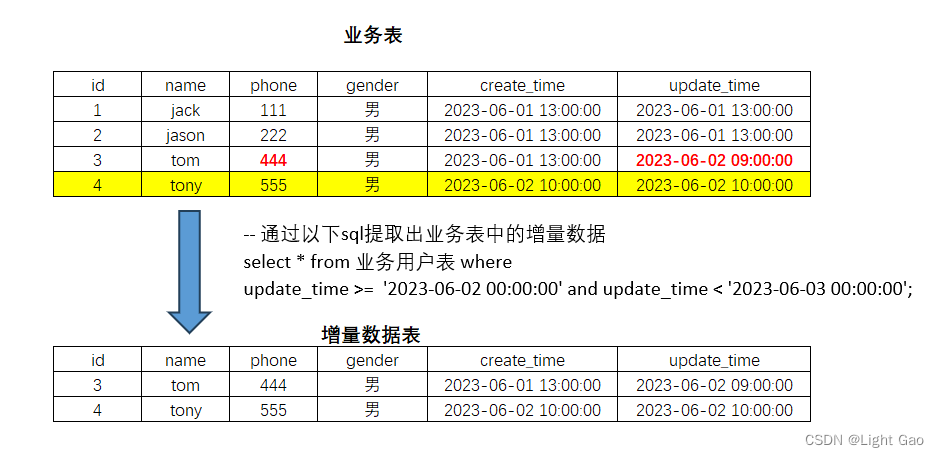
增量同步顾名思义是将业务数据用户表按天为粒度将增量数据与数仓快照表中的前一天数据进行join对比后放入到指定分区内,该方式需要业务数据有唯一字段(常用ID) 和 update_time时间戳,否则无法使用增量同步,这里以:2.1、中示例,实现原理如下:
- 提取业务表中的2023-06-02日的增量数据
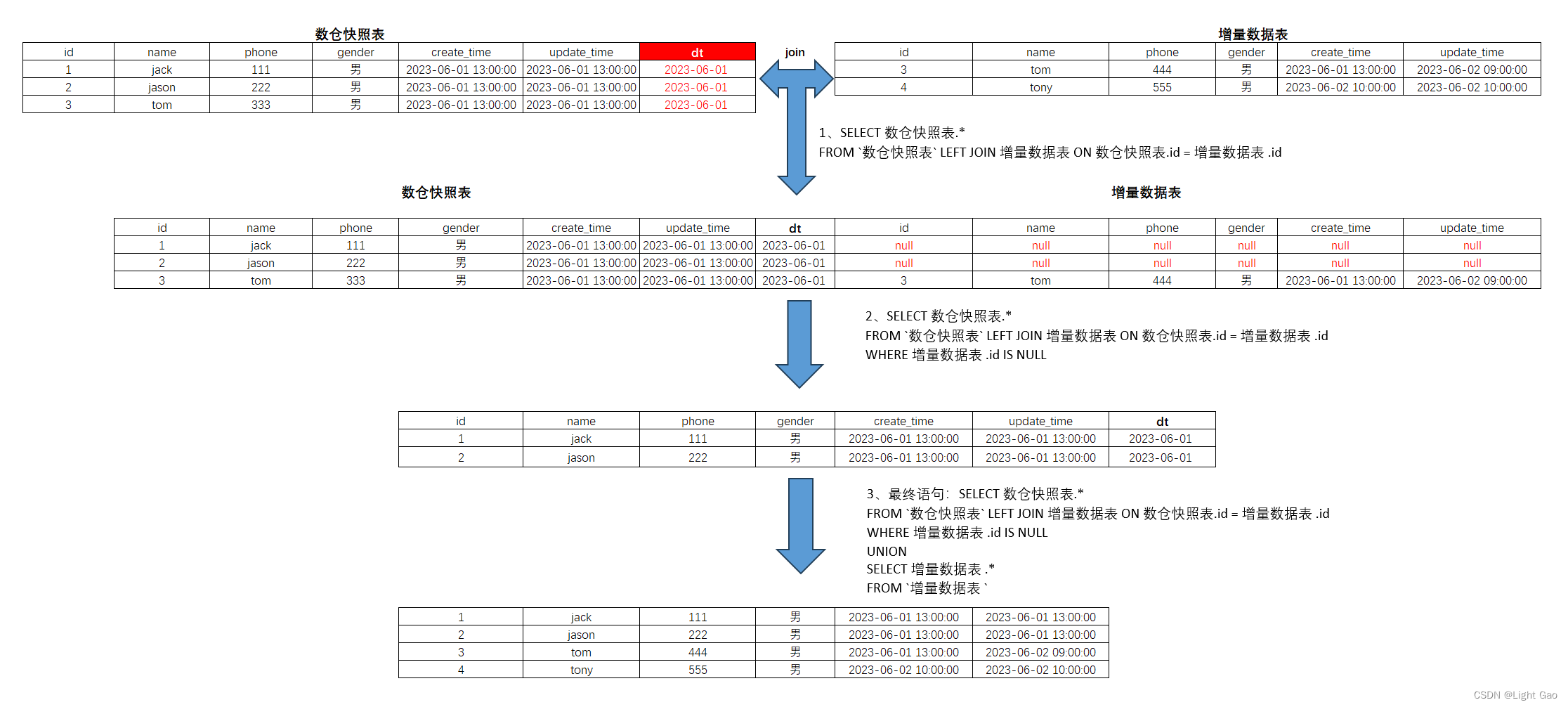
- 通过上一步获得到的增量数据与数仓2023-06-01分区数据进行 left join 及判空提取出未更改的数据后再与增量数据union结合得到最新数据
- 将上一步获取到的最新数据插入至数仓快照表中的2023-06-02分区,全流程如下:
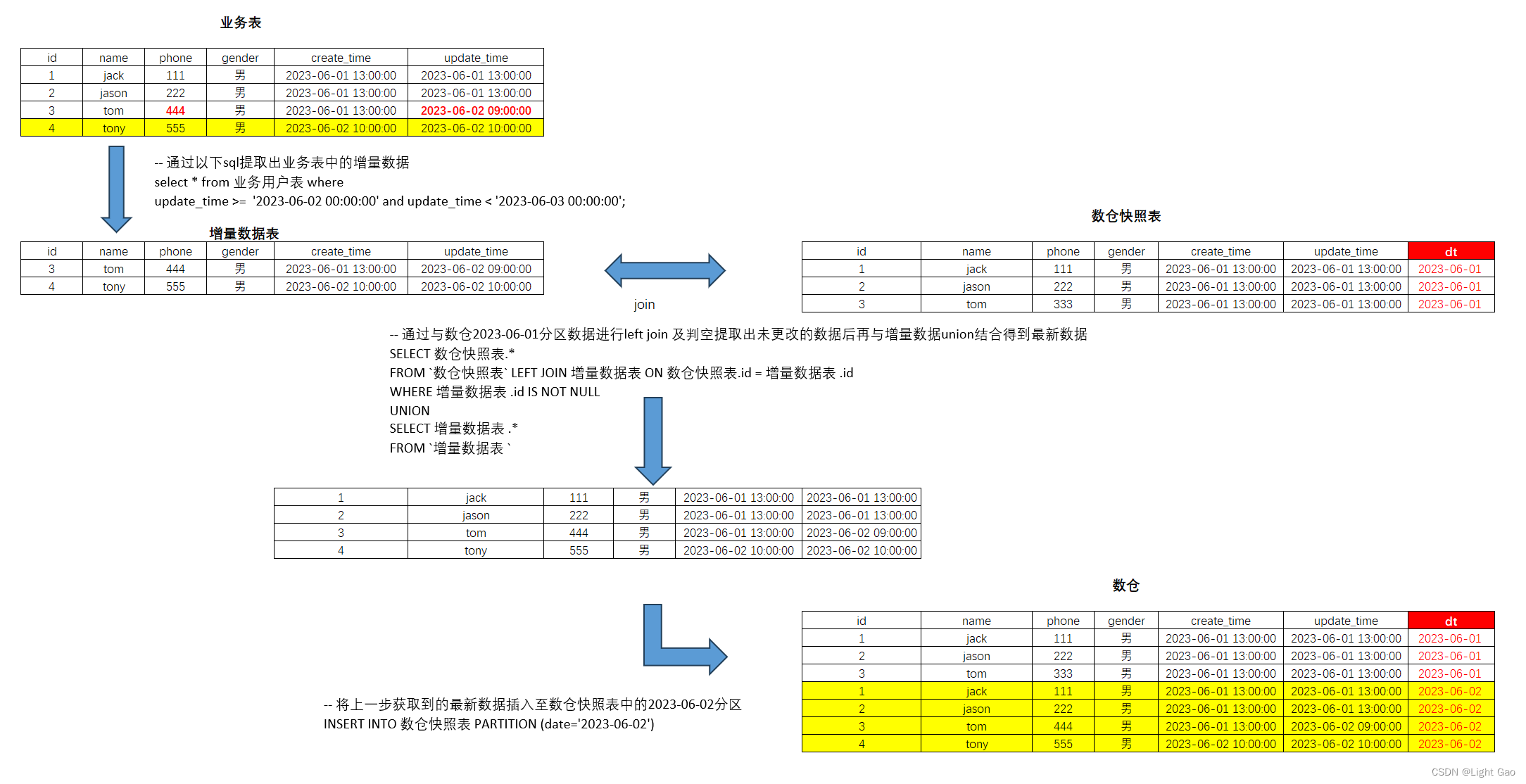
- 所有sql操作如下:
-- 通过以下sql提取出业务表中的增量数据
select * from 业务用户表 where
update_time >= '2023-06-02 00:00:00' and update_time < '2023-06-03 00:00:00';
-- 通过与数仓2023-06-01分区数据进行left join 及判空提取出未更改的数据后再与增量数据union结合得到最新数据
SELECT 数仓快照表.*
FROM `数仓快照表` LEFT JOIN 增量数据表 ON 数仓快照表.id = 增量数据表 .id
WHERE 增量数据表 .id IS NOT NULL
UNION
SELECT 增量数据表 .*
FROM `增量数据表 `
-- 将业务数据导入 至 数仓快照表2023-06-02目标分区中
INSERT INTO 数仓快照表 PARTITION (date='2023-06-02')
SELECT 数仓快照表.*
FROM `数仓快照表` LEFT JOIN 增量数据表 ON 数仓快照表.id = 增量数据表 .id
WHERE 增量数据表 .id IS NOT NULL
UNION
SELECT 增量数据表 .*
FROM `增量数据表 `
四、总结
增量同步方式是一种数据同步的方式,其优势在于只提取业务数据中发生变化的部分,即增量数据集。相对于全量同步,这种方式能够带来诸多优势,其中包括以下几点:
- 降低对业务数据库的压力:
- 增量同步只传输发生变化的数据部分,避免了每次同步都需要传输整个数据集的情况,从而减轻了业务数据库的负担和网络带宽的压力。
- 节省时间和资源:
- 由于只处理数据的增量变化,相比全量同步,增量同步可以更快速地完成同步过程,节省了处理时间和资源。
- 减少同步错误和数据冲突:
- 在增量同步中,仅处理发生变化的数据,减少了数据同步过程中可能出现的错误和冲突,提高了数据同步的准确性和可靠性。
- 提高同步效率和性能:
- 由于只关注变化的数据,增量同步能够更精准地捕获变更,从而提高了同步效率和性能,减少了不必要的重复同步和数据传输。
综上所述,增量同步方式通过只同步业务数据中的变化部分,相比全量同步,能够有效降低对业务数据库的负荷,节省时间和资源,减少同步错误和冲突,以及提高同步效率和性能。这种方式是数据同步过程中常用的有效策略之一,有助于提升数据同步的效率和可靠性。
五、相关文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Keepalived 高可用详解
- VCG 获取网格边界面片
- 【MySQL】基础(一)
- C //练习 5-9 用指针方式代替数组下标方式改写函数day_of_year和month_day。
- 继续理解Nacos的CP和AP架构模型!
- 重学JavaScript高级(十四): 手写工具函数(防抖-节流-深浅拷贝-时间总线)
- gin框架使用系列之五——表单校验
- 腾讯云服务器的介绍_云主机概览——腾讯云
- bagging:随机森林
- mcgs批量自动生成西门子plc IO监视界面方法实现5