Selenium自动化测试+OCR-获取图片页面小说
发布时间:2024年01月09日
随着爬虫技术的发展,反爬虫技术也越来越高。
目前有些网站通过自定义字体库的方式实现反爬,主要表现在页面数据显示正常,但是页面获取到的实际数据是别的字符或者是一个编码。
这种反爬需要解析网站自己的字体库,对加密字符使用字体库对应字符替换。需要制作字体和基本字体间映射关系。
还有些网站通过图片加载内容的方式实现反爬,想要获取网页内容,可以结合使用OCR技术获取图片文字内容。【文末有配套视频教程】
第一步:先获取网页内容截图
结合之前《文章代码,改造下,封装成一个新方法,只获取小说网页内容截图,按章节ID分目录保存每页截图文件。
依旧采用拆分步骤细化功能模块封装方法编写代码,便于后续扩展功能模块。
def spider_novel_content_save_image(req_dict):
'''
@方法名称: 爬取小说章节明细内容,保存内容截图文件
@中文注释: 爬取小说章节明细内容,保存内容截图文件
@入参:
@param req_dict dict 请求容器
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param rsp_dict dict 响应容器
@作 者: PandaCode辉
@weixin公众号: PandaCode辉
@创建时间: 2023-09-26
@使用范例: spider_novel_content_save_image(req_dict)
'''
try:
if (not type(req_dict) is dict):
return [0, "111111", "请求容器参数类型错误,不为字典", [None]]
# 章节目录文件名
json_name = req_dict['novel_name'] + '.json'
# 检查文件是否存在
if os.path.isfile(json_name):
print('json文件存在,不用重新爬取小说目录.')
else:
print('json文件不存在')
# 爬取小说目录
spider_novel_mulu(req_dict)
# 读取json文件
with open(json_name, 'r') as f:
data_str = f.read()
# 转换为字典容器
mulu_dict = json.loads(data_str)
# 在列表中查找指定元素的下标,未完成标志下标
flag_index = mulu_dict['flag'].index('0')
print(flag_index)
# 章节总数
chap_len = len(mulu_dict['chap_url'])
# 在列表中查找指定元素的下标
print('章节总数:', chap_len)
# 截图目录
screenshot_dir = os.path.join(os.path.dirname(__file__), 'screenshot')
if not os.path.exists(screenshot_dir):
os.makedirs(screenshot_dir)
print('打开浏览器驱动')
open_driver()
# 循环读取章节
for chap_id in range(flag_index, chap_len):
print('chap_id : ', chap_id)
# 章节url
chap_url = mulu_dict['chap_url'][chap_id]
# 截图目录,根据章节ID分类保存
chap_id_dir = os.path.join(screenshot_dir, str(chap_id))
if not os.path.exists(chap_id_dir):
os.makedirs(chap_id_dir)
# 打开网址网页
print('打开网址网页')
driver.get(chap_url)
# 等待6秒启动完成
driver.implicitly_wait(6)
print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2))
# 章节分页url列表初始化
page_href_list = []
# 根据url地址获取网页信息
chap_rst = get_html_by_webdriver(chap_url)
time.sleep(3)
if chap_rst[0] != 1:
# 跳出循环爬取
break
chap_html_str = chap_rst[3][0]
# 使用BeautifulSoup解析网页数据
chap_soup = BeautifulSoup(chap_html_str, "html.parser")
# 章节内容分页数和分页url
# 获取分页页码标签下的href元素取出
page_href_list_tmp = chap_soup.select("div#PageSet > a")
all_page_cnt = len(page_href_list_tmp)
print("分页页码链接数量:" + str(all_page_cnt))
# 去除最后/后面数字+.html
tmp_chap_url = re.sub(r'(\d+\.html)', '', chap_url)
for each in page_href_list_tmp:
if len(each) > 0:
chap_url = tmp_chap_url + str(each.get('href'))
print("拼接小说章节分页url链接:" + chap_url)
# 判断是否已经存在列表中
if not chap_url in page_href_list:
page_href_list.append(chap_url)
print("分页url链接列表:" + str(page_href_list))
# 网页长宽最大化,保证截图是完整的,不会出现滚动条
S = lambda X: driver.execute_script('return document.body.parentNode.scroll' + X)
driver.set_window_size(S('Width'), S('Height'))
# 章节页码,首页
page_num = 1
# 章节内容截图
image_file = os.path.join(chap_id_dir, str(page_num) + '.png')
# 元素定位
chap_content_element = driver.find_element(By.ID, 'content')
print(chap_content_element)
# 元素截图
chap_content_element.screenshot(image_file)
# 分页列表大于0
if len(page_href_list) > 0:
for chap_url_page in page_href_list:
print("chap_url_page:" + chap_url_page)
time.sleep(3)
# 打开网址网页
print('打开网址网页')
driver.get(chap_url_page)
# 等待6秒启动完成
driver.implicitly_wait(6)
print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2))
# 章节页码
page_num += 1
# 章节内容截图
image_file = os.path.join(chap_id_dir, str(page_num) + '.png')
# 元素定位
chap_content_element = driver.find_element(By.ID, 'content')
print(chap_content_element)
# 元素截图
chap_content_element.screenshot(image_file)
# 爬取明细章节内容截图成功后,更新对应标志为-2-截图已完成
mulu_dict['flag'][chap_id] = '2'
print('关闭浏览器驱动')
close_driver()
# 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
# 返回容器
return [1, '000000', '爬取小说内容截图成功', [None]]
except Exception as e:
print('关闭浏览器驱动')
close_driver()
# 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
print("爬取小说内容异常," + str(e))
return [0, '999999', "爬取小说内容截图异常," + str(e), [None]]第二步:通过OCR接口识别截图
结合之前的文章代码,改造下,封装成一个新方法,通过OCR接口识别小说网页内容截图,然后写入文件保存。
依旧采用拆分步骤细化功能模块封装方法编写代码,便于后续扩展功能模块。
# 模拟http请求
def requests_http(file_path, file_name, url):
full_file_path = os.path.join(file_path, file_name)
# 请求参数,文件名
req_data = {'upload_file': open(full_file_path, 'rb')}
# 模拟http请求
rsp_data = requests.post(url, files=req_data)
# print(rsp_data.text)
result_dict = json.loads(rsp_data.text)
# print(result_dict)
return result_dict
def spider_novel_content_by_ocr(req_dict):
'''
@方法名称: 通过OCR接口获取小说章节明细内容文字
@中文注释: 读取章节列表json文件,通过OCR接口获取小说章节明细内容文字,保存到文本文件
@入参:
@param req_dict dict 请求容器
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param rsp_dict dict 响应容器
@作 者: PandaCode辉
@weixin公众号: PandaCode辉
@创建时间: 2023-09-26
@使用范例: spider_novel_content_by_ocr(req_dict)
'''
try:
if (not type(req_dict) is dict):
return [0, "111111", "请求容器参数类型错误,不为字典", [None]]
# 章节目录文件名
json_name = req_dict['novel_name'] + '.json'
# 检查文件是否存在
if os.path.isfile(json_name):
print('json文件存在,不用重新爬取小说目录.')
else:
print('json文件不存在')
# 爬取小说目录
spider_novel_mulu(req_dict)
# 读取json文件
with open(json_name, 'r') as f:
data_str = f.read()
# 转换为字典容器
mulu_dict = json.loads(data_str)
"""
关于open()的mode参数:
'r':读
'w':写
'a':追加
'r+' == r+w(可读可写,文件若不存在就报错(IOError))
'w+' == w+r(可读可写,文件若不存在就创建)
'a+' ==a+r(可追加可写,文件若不存在就创建)
对应的,如果是二进制文件,就都加一个b就好啦:
'rb' 'wb' 'ab' 'rb+' 'wb+' 'ab+'
"""
file_name = req_dict['novel_name'] + '.txt'
# 在列表中查找指定元素的下标,2-截图完成,标志下标
flag_index = mulu_dict['flag'].index('2')
print(flag_index)
# 2-截图完成,标志下标为0,则为第一次爬取章节内容,否则已经写入部分,只能追加内容写入文件
# 因为章节明细内容很多,防止爬取过程中间中断,重新爬取,不用重复再爬取之前成功写入的数据
if flag_index == 0:
# 打开文件,首次创建写入
fo = open(file_name, "w+", encoding="utf-8")
else:
# 打开文件,再次追加写入
fo = open(file_name, "a+", encoding="utf-8")
# 章节总数
chap_len = len(mulu_dict['chap_url'])
# 在列表中查找指定元素的下标
print('章节总数:', chap_len)
# 截图目录
screenshot_dir = os.path.join(os.path.dirname(__file__), 'screenshot')
# 循环读取章节
for chap_id in range(flag_index, chap_len):
# 识别成功标志
succ_flag = False
# 章节标题
chap_title = mulu_dict['chap_title'][chap_id]
print('chap_id : ', chap_id)
# # 写入文件,章节标题
fo.write("\n" + chap_title + "\r\n")
# 截图目录,根据章节ID分类保存
chap_id_dir = os.path.join(screenshot_dir, str(chap_id))
# 列出目录下的所有文件和文件夹
file_list = os.listdir(chap_id_dir)
# 章节目录下文件列表大于0
if len(file_list) > 0:
for file_name in file_list:
print("file_name:" + file_name)
time.sleep(3)
url = "http://127.0.0.1:5000/upload/"
# 模拟http请求
result_dict = requests_http(chap_id_dir, file_name, url)
print(result_dict)
# 识别成功
if result_dict['error_code'] == '000000':
succ_flag = True
result_list = result_dict['result']
for data in result_list:
print(data['text'])
# 将识别结果,逐行写入文件,章节内容
fo.write(data['text'] + "\n")
else:
succ_flag = False
print('识别失败异常.')
# 识别成功则更新
if succ_flag:
# 爬取明细章节内容成功后,更新对应标志为-1-已完成
mulu_dict['flag'][chap_id] = '1'
print('关闭浏览器驱动')
close_driver()
# 关闭文件
fo.close()
print("循环爬取明细章节内容,写入文件完成")
# 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
# 返回容器
return [1, '000000', '爬取小说内容成功', [None]]
except Exception as e:
print('关闭浏览器驱动')
close_driver()
# 关闭文件
fo.close()
# 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
print("爬取小说内容异常," + str(e))
return [0, '999999', "爬取小说内容异常," + str(e), [None]]第三步:运行效果
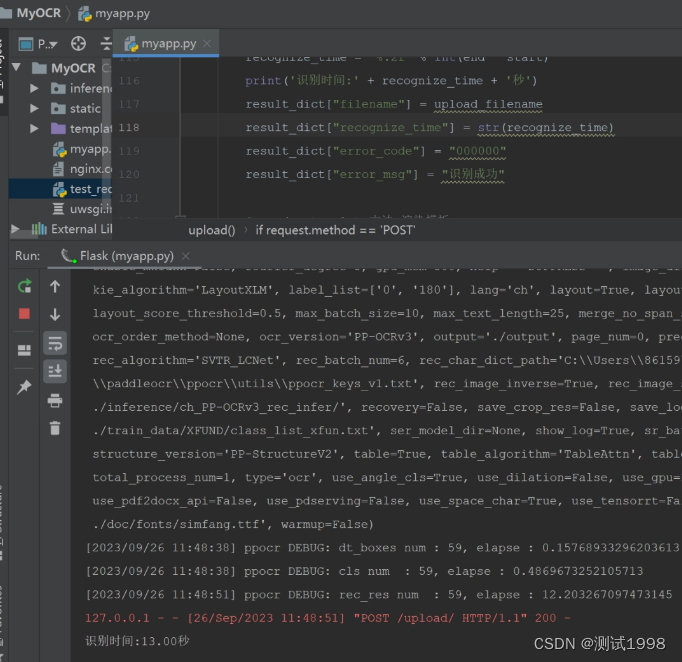
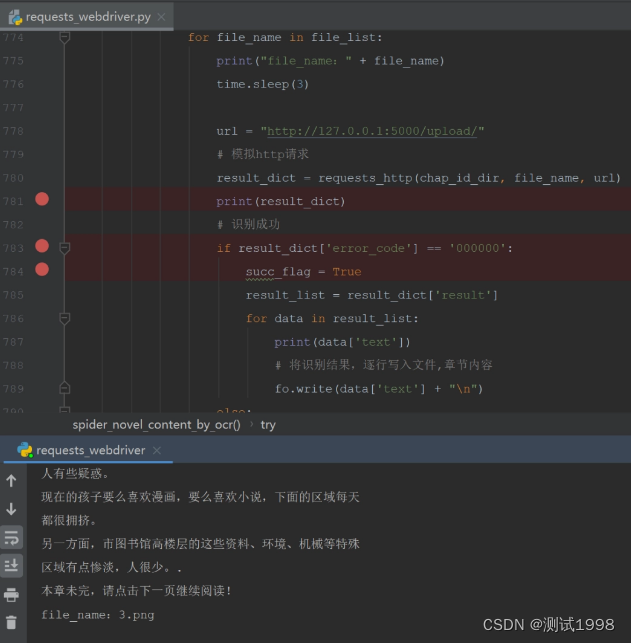

第四步:总结
目前很多网站都有基本的反爬策略,常见就是验证码、JS参数加密这两种。
爬虫本身会对网站增加一定的压力,所以也应该合理设定爬取速率,尽量避免对目标网站造成麻烦,影响网站正常使用,一定注意自己爬虫的姿势。
同时,在这我也准备了一份软件测试视频教程(含接口、自动化、性能等),需要的可以直接在下方观看就行,希望对你有所帮助!【公众号:互联网杂货铺】免费领取软件测试资
【2024最新版】Python自动化测试15天从入门到精通,10个项目实战,允许白嫖。。。
文章来源:https://blog.csdn.net/zhangsiyuan1998/article/details/135480405
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 线性代数:逆、转置、分块、多项式 矩阵公式总结
- 学习记录685@获取第三方文件后转存入自己服务器
- 批量缩放图片尺寸,让每一张图片都恰到好处
- 模拟退火算法(SA)解决旅行商(TSP)问题的python实现
- IaC基础设施即代码:Terraform 进行 lifecycle 生命周期管理
- 详解FreeRTOS:FreeRTOS的系统时钟节拍(拓展篇—2)
- 鸿蒙OpenHarmony NAPI技术-基础学习
- 九州金榜|家庭教育学会给高三孩子减压,助力孩子考上好大学!
- 算法练习Day27 (Leetcode/Python-贪心算法)
- vue vue-quill-editor 富文本编辑器 (图片问题)