【数据库系统概论】数据库恢复机制
系统文章目录
数据库的四个基本概念:数据、数据库、数据库管理系统和数据库系统
数据库系统的三级模式和二级映射
数据库系统外部的体系结构
数据模型
关系数据库中的关系操作
SQL是什么?它有什么特点?
数据定义之基本表的定义/创建、修改和删除
数据定义之索引的创建、修改与删除
数据查询之单表查询。详细解释WHERE、OEDER BY、GROUP BY 和 HAVING
关系的完整性(实体完整性、参照完整性、用户定义的完整性)
事务(包括事务的基本概念和特性解释)
为什么要有数据库恢复机制
当出现故障,造成事务在运行过程中被强行停止从而影响数据库中数据的正确性,使得数据库的状态不是正确的。这时就需要数据库恢复机制将数据库的状态恢复到某一已知的正确状态。
遇到故障后,数据库要么被破坏,要么数据不正确。
数据库恢复技术能够保证事务的一致性。
恢复的实现技术
恢复的基本原理是:冗余。利用存储在系统别处的冗余数据来重建数据库中已被破坏或不正确的那部分数据。虽然恢复技术的基本原理很简单,但实现技术的细节确相当复杂。
恢复机制涉及的关键问题有两点:
- 如何建立冗余数据
- 如何利用这些冗余数据实施数据库恢复
建立冗余数据最常用的技术是数据转储和登录日志文件。通常这两个方法是一起用的。
数据转储
转储的含义:转储是指数据库管理员定期地将整个数据库复制到磁带、磁盘或其他存储介质上保存起来的过程。这些备用的数据文本称为后备副本(backup)。
恢复过程:数据库遭到破坏后可以将后备副本重新装入,重装后备副本只能将数据库恢复到转储时的状态,要想恢复到故障发生时的状态,必须重新运行自转储以后的所有更新事务。
转储过程:转储可以分为静态转储和动态转储。
- 静态转储就是在转储的过程中系统不允许进行任何存取活动。优点是能得到数据一致性的副本,缺点在于会降低数据库的可用性,毕竟如果数据库很大,转储时间就很长,那么这段时间都不能对数据库进行操作的话,对于有些业务场景来说肯定是不能接受的。
- 动态转储就是在储的过程中允许对数据库进行存取和修改。也就是说转储和用户事务可以并发执行。优点是不会影响新事务的运行,缺点是不能保证副本中的数据正确有效,比如在转储期间的某时刻Tc,系统把数据A=100转储到磁盘上,而在下一时刻Td,某一事务将A改为200,那么后备副本上的A就是过时的。解决方案是把动态转储期间各事务对数据库的修改活动登记下来,建立日志文件,这样后备副本加上日志文件就能把数据库恢复到某一时刻的正确状态。
登录日志文件
什么是日志文件:日志文件(log file)记录了事务对数据库的更新操作。
不同的数据库系统采用的日志文件格式并不完全一样。概括起来主要有两种格式:以记录为单位的日志文件和以数据块为单位的日志文件。
以记录为单位的日志文件的内容:
- 各个事务的开始标记(BEGIN TRANSACTION)
- 各个事务的结束标记(COMMIT或ROLLBACK)
- 各个事务的所有更新操作
以上共同构成日志文件中的一条记录。具体来说,每个日志记录的内容主要包括:
- 事务标识(标明是哪个事务)
- 操作类型(插入、删除或修改)
- 操作对象(记录ID、Block NO.)
- 更新前数据的旧值(对插入操作而言,此项为空值)
- 更新后数据的新值(对删除操作而言, 此项为空值)
必须先写日志文件,后写数据库。
REDO(重做)和UNDO(撤销)
恢复操作就是要撤销故障发生时未完成的事务,重做已完成的事务。
具有检查点的恢复技术
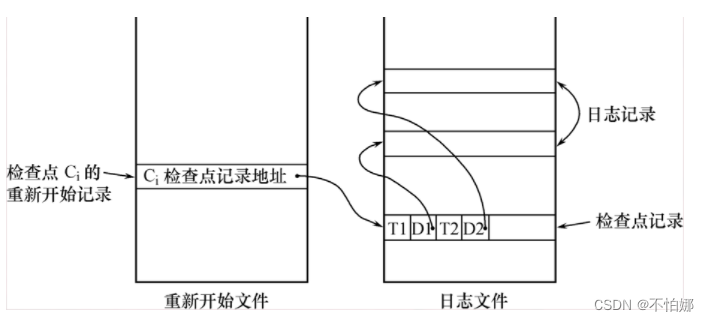
为什么:利用日志技术进行数据库恢复时,恢复子系统必须搜索日志,确定哪些事务需要重做,哪些事务需要撤销。一般来说会检查所有的日志记录,但是搜索整个日志将耗费大量的时间。其次有很多需要重做处理的事务实际上已经在数据库中执行了,然而恢复子系统又重新执行了这些操作,浪费了大量时间。为了解决这些问题,又发展了具有检查点(checkpoint)的恢复技术。这种技术在日志文件中增加检查点记录(checkpoint),增加一个重新开始文件,并让恢复子系统在登录日志文件期间动态地维护日志。
检查点记录的内容包括:建立检查点时刻所有正在执行的事务清单和这些事务最近一个日志记录的地址。
重新开始文件的内容:记录各个检查点记录在日志文件中的地址。
系统出现故障时,恢复子系统将根据事务的不同状态采取不同的恢复策略。
例如:
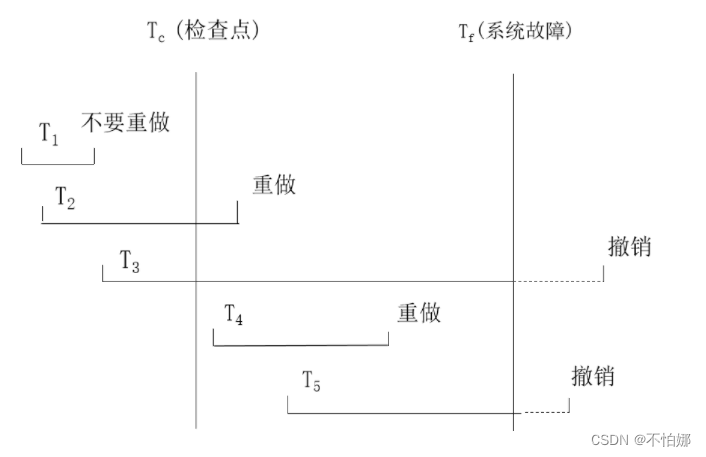
- T1:在检查点之前提交
- T2:在检查点之前开始执行,在检查点之后故障点之前提交
- T3:在检查点之前开始执行,在故障点时还未完成
- T4:在检查点之后开始执行,在故障点之前提交
- T5:在检查点之后开始执行,在故障点时还未完成
恢复策略:
- T3和T5在故障发生时还未完成,所以需要撤销(UNDO)
- T2和T4在检查点之后才提交,它们对数据库所做的修改在故障发生时可能还在缓冲区中,尚未写入数据库,所以要重做(REDO)
- T1在检查点之前已提交,所以不必执行重做操作
从上面这个例子中就能充分体会到什么叫恢复操作就是要撤销故障发生时未完成的事务,重做已完成的事务。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【蓝桥杯选拔赛真题52】python空调模式 第十四届青少年组蓝桥杯python 选拔赛比赛真题解析
- 论文阅读<MULTISCALE DOMAIN ADAPTIVE YOLO FOR CROSS-DOMAIN OBJECT DETECTION>
- Python 面向对象之绑定和非绑定方法
- 第十三章 Squid代理服务器 传统代理服务器
- 装修公司网站
- 【WinForm.NET开发】在后台运行操作
- 教你一招,测试人员如何通过AI提高工作效率!
- docker间通讯
- 第14课 SQL入门之组合查询
- vivado 预设文件、IP设置(_P)、用户参数、以太网时钟处理、GT位置限制、当前可识别板的IP列表