AWS 专题学习 P5 (Classic SA、S3)
发布时间:2024年01月19日
文章目录
- Classic Solutions Architecture
- Amazon S3 Section
- Advanced S3
- Amazon S3 安全
- 什么是 CORS?
Classic Solutions Architecture
- 让我们了解我们所见过的所有技术如何协同工作
- 这是一个你需要百分百熟悉的部分
- 我们将通过许多示例案例研究看到解决方案架构师思维的进展:
- WhatIsTheTime.com
- MyClothes.com
- NyWordPress.com
- 快速实例化应用程序
- Beanstalk
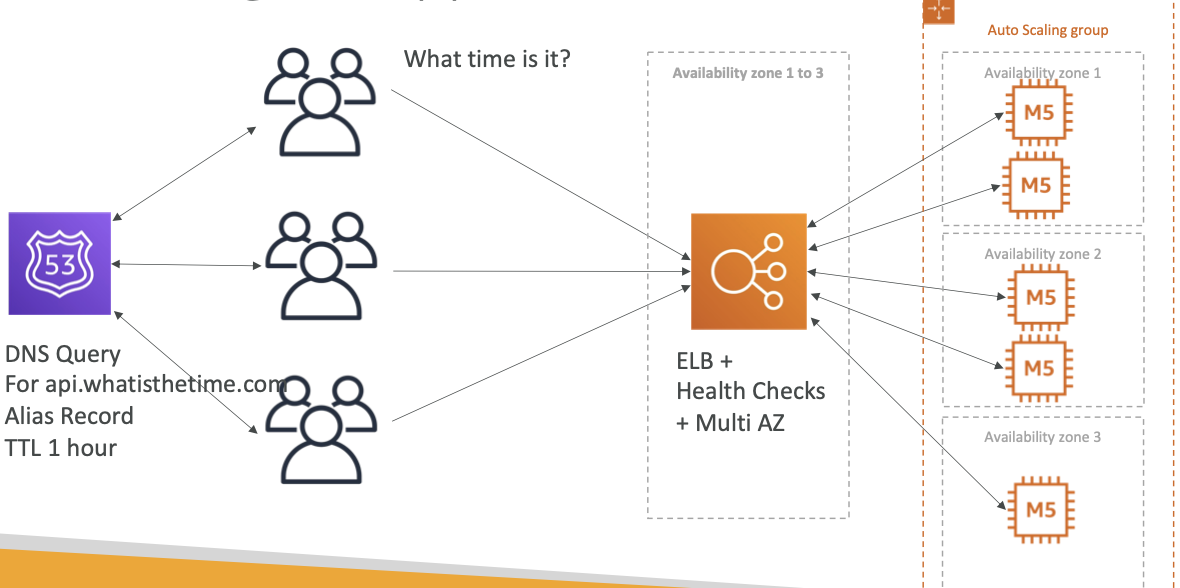
无状态 Web 应用程序:WhatIsTheTime.com
背景 & 目标
- 不需要数据库
- 初始阶段可以接受停机时间,最佳实践下完全垂直和水平扩展,无需停机
架构演进
- 从简单开始(一个 t2 Instance + 一个 EIP)
- 垂直扩展(单 Instance的容量从 t2 到 m5)
- 水平扩展(instance 和 EIP 均扩展为 3 个 => 引入 DNS,去除 EIP,解决需要记住多个 IP 的问题)
- 水平扩展、添加和删除实例(需要添加和删除实例时部分用户会感知到停机)
- 使用负载均衡器水平扩展(引入 ELB + Health Check,使 instance 扩展无感知)
- 使用自动缩放组进行水平缩放(引入 ASG,使扩展自动化)
- 使我们的应用程序多可用(灾备能力,可以最小化配置为 2 AZ => 预留更多容量,节约成本)
Well-Architected 5 pillars
成本、性能、可靠性、安全性、卓越运营
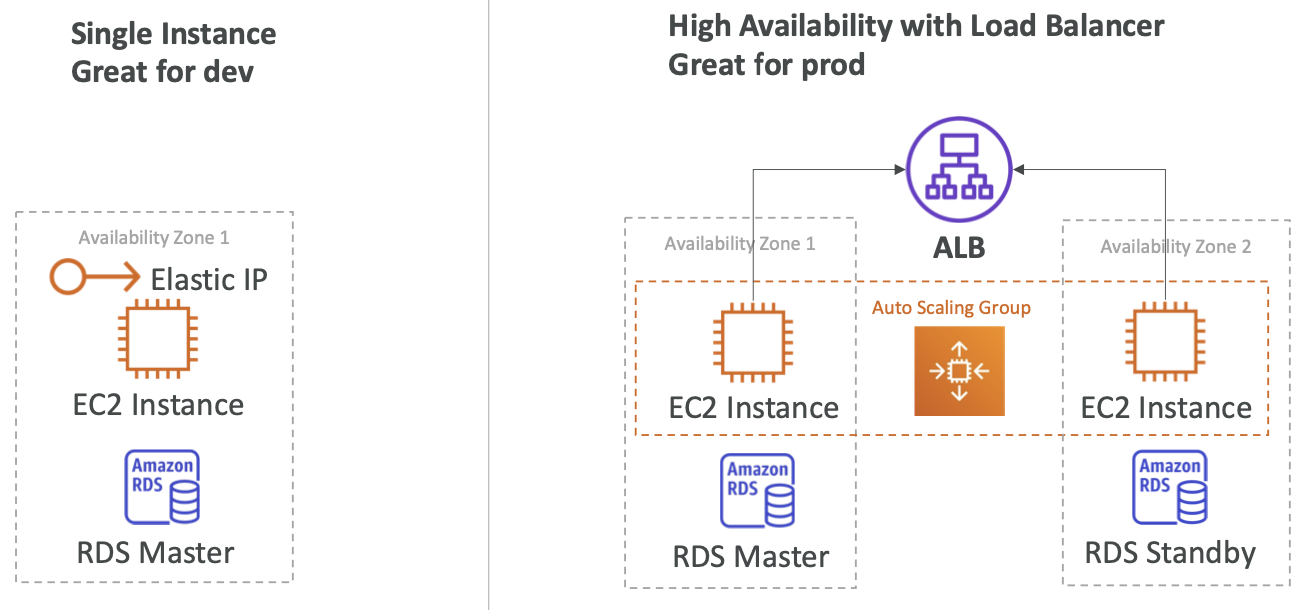
有状态的 Web 应用程序:MyClothes.com
背景 & 目标
- 此应用有一个购物车,允许用户选购商品,在线购买衣服
- 网站同时拥有数百个用户
- 我们需要扩展、保持水平可扩展性并尽可能保持我们的 Web 应用端 无状态
- 购物车的数据、用户的详细信息等都应该存储在数据库中
架构演进
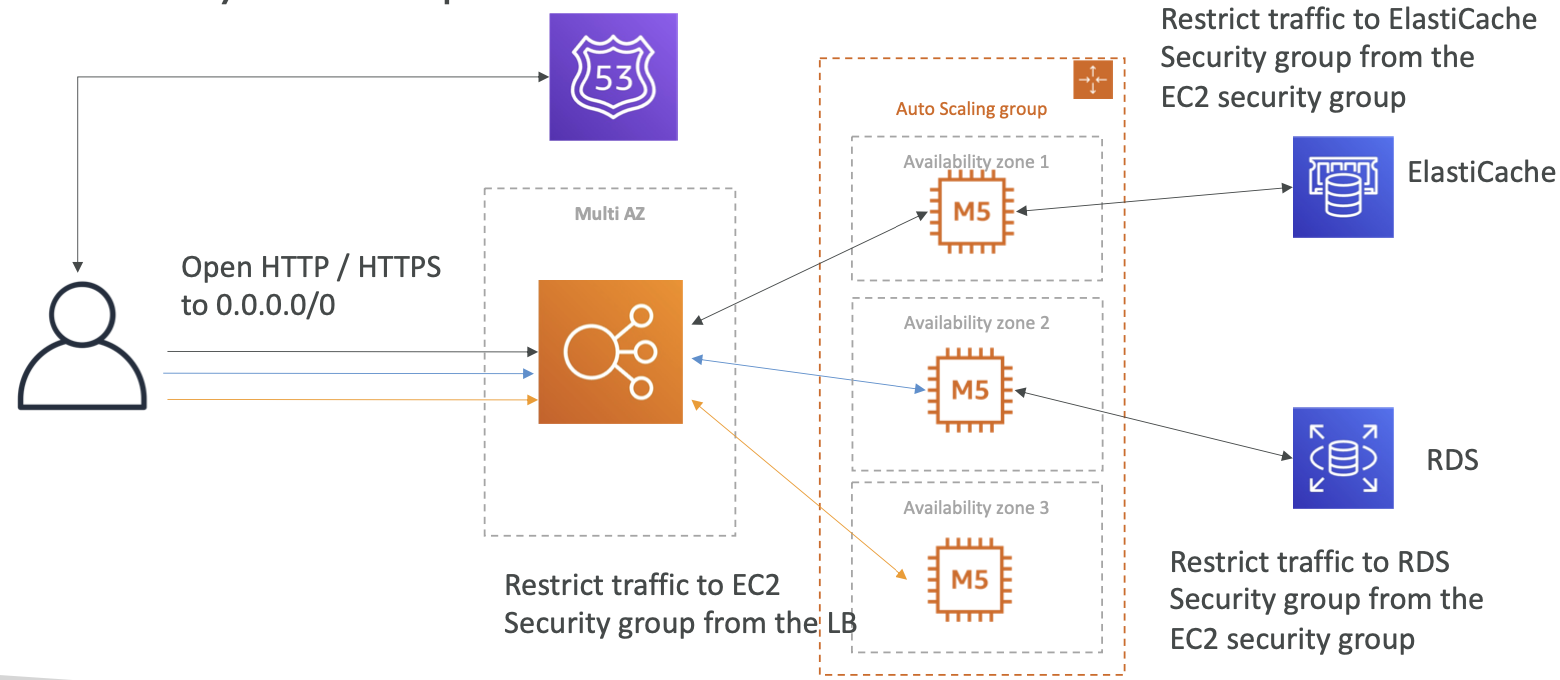
- 引入 ELB Stickiness (Session Affinity) — 使请求能根据cookie或者IP地址路由到同一服务器
- 引入 User Cookie — 实现客户端无状态
- 引入 Server Session — 引入 ElasticCache 实现 Session 存储,同时可以缓存 RDS 数据
- 将 User Data 存储到数据库 — 引入 RDS
- Scaling Reads — 通过只读副本将读取操作分散到多个数据库实例提高读取性能
- Scaling Reads(可选)— 延迟加载,当客户端请求数据时只将需要的数据加载到只读副本中,减少数据传输和加载的时间,提高读取性能
- 多可用区— 灾备
- 安全组 — 相互引用,确保严格的安全性
总结
- Web 应用程序的 3 层架构
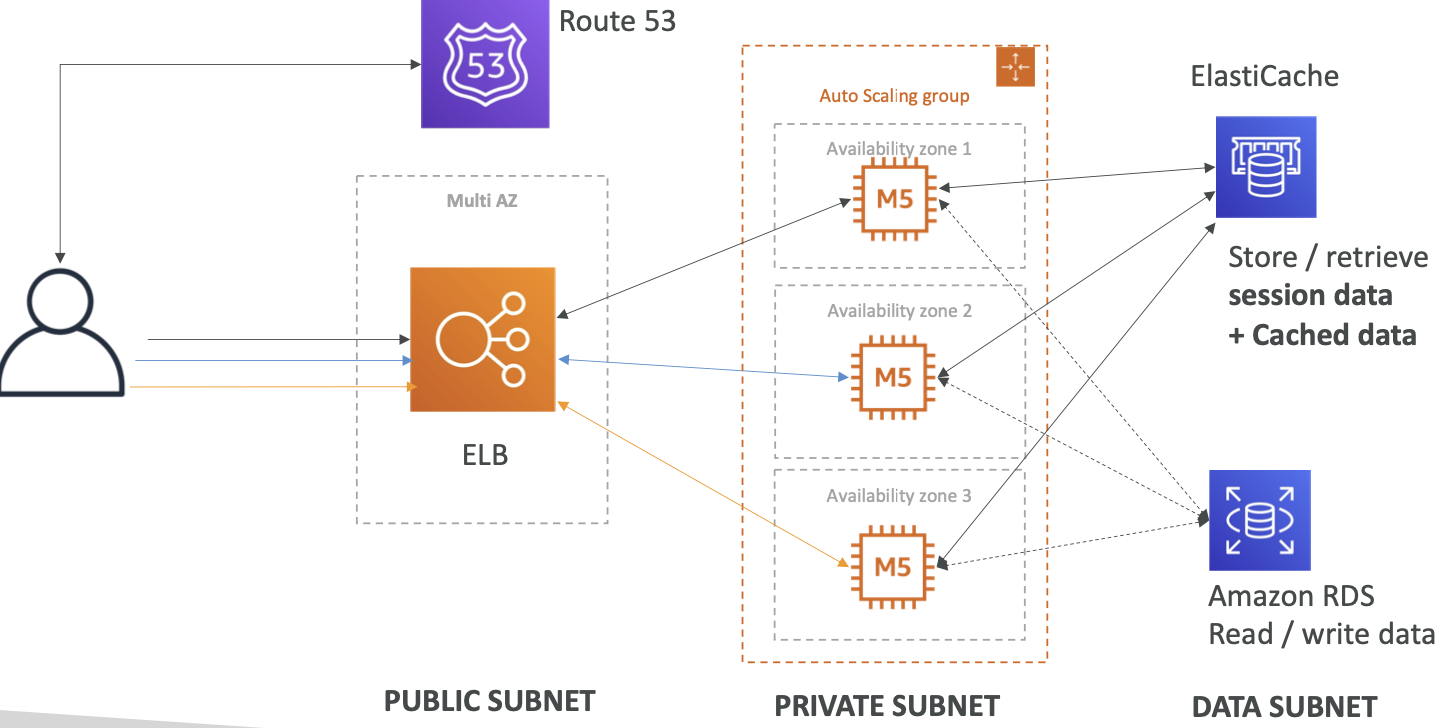
- 公有子网层
- 私有子网层
- 数据子网层
- ElasticCache
- 用于存储 Session(替代方案:DynamoDB)
- 用于缓存来自 RDS 的数据
- 多可用区
- RDS
- 用于存储用户数据
- 用于扩展读取的读取副本
- 用于灾难恢复的多可用区
- ElasticCache
有状态的 Web 应用程序:MyWordPress.com
背景 & 目标
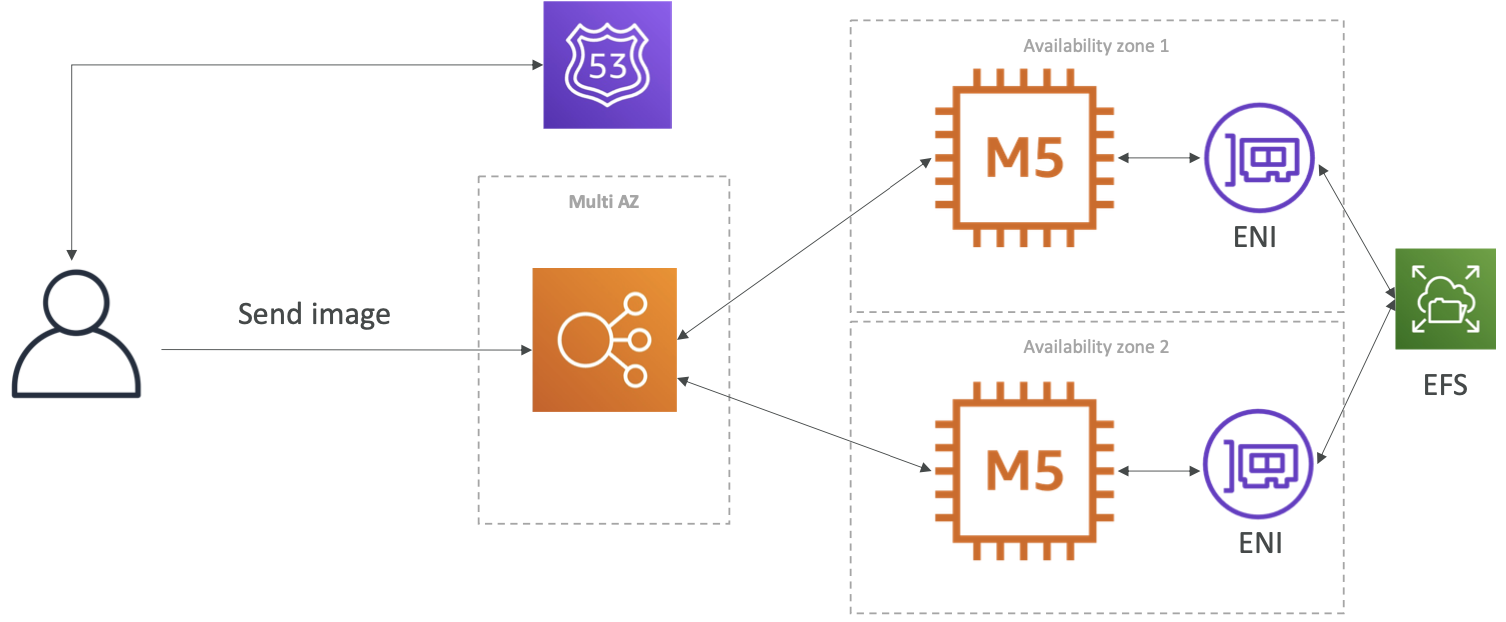
- 一个能够访问并正确显示上传的图片的 WordPress 网站
- 该网站完全可扩展
- 用户数据和博客内容应该存储在 MySQL 数据库中
架构演进
- RDS 层
- 使用 Aurora 进行扩展:多可用区和只读副本
- 使用 EBS 存储 Image(单例应用程序)
- 使用 EFS 存储 Image(分布式应用程序)
快速实例化应用程序
- 启动一个完整的堆栈(e.s. EC2、EBS、RDS)可能需要较长时间: 安装应用程序、插入初始(或恢复)数据、初始化配置、启动应用程序
- 利用云特性来加速启动
- EC2 实例:
- 使用 Golden AMI:预先安装应用程序、操作系统依赖项等,并从 Golden AMI 启动 EC2 实例
- Bootstrap using User Data:对于动态配置,请使用用户数据脚本
- Hybrid:混合 Golden AMI 和用户数据 (e.s. Elastic Beanstalk)
- RDS 数据库
- 从快照恢复:数据库将准备好架构和数据!
- EBS 卷
- 从快照恢复:磁盘已经格式化并且有数据!
AWS 上的开发人员的问题
- 管理基础设施
- 部署代码
- 配置所有数据库、负载均衡器等
- 扩展问题
- 大多数网络应用程序具有相同的架构(ALB + ASG)
- 开发人员想要的只是他们的代码能够运行!
- 可以在不同的应用程序和环境中保持一致
Elastic Beanstalk
概述
- Elastic Beanstalk 是在 AWS 上部署应用程序的以开发人员为中心的视图
- 它使用了我们之前见过的所有组件:EC2、ASG、ELB、RDS……
- 托管服务
- 自动处理容量配置、负载平衡、扩展、应用程序运行状况监控、实例配置……
- 仅应用程序代码是开发人员的责任
- 我们仍然可以完全控制配置
- Beanstalk 是免费的,但您需要为底层实例付费
组成
- 应用程序:Elastic Beanstalk 组件的集合(环境、版本、配置等)
- 应用程序版本:应用程序代码的迭代
- 环境
- 运行应用程序版本的AWS 资源集合(一次仅一个应用程序版本)
- Tiers:WebServerEnvironmentTier&WorkerEnvironmentTier
- 您可以创建多个环境(dev、test、prod…)
支持的平台
- Go
- Java SE
- Java & Tomcat
- .NET Core on Linux
- .NET on Windows Server
- Node.js
- PHP
- Python
- Ruby
- Packer Builder
- Single container Docker
- Multi-container Docker
- Preconfigured Docker
- 如果不支持,可以编写自定义平台(高级)
Web ServerTier vs. WorkerTier
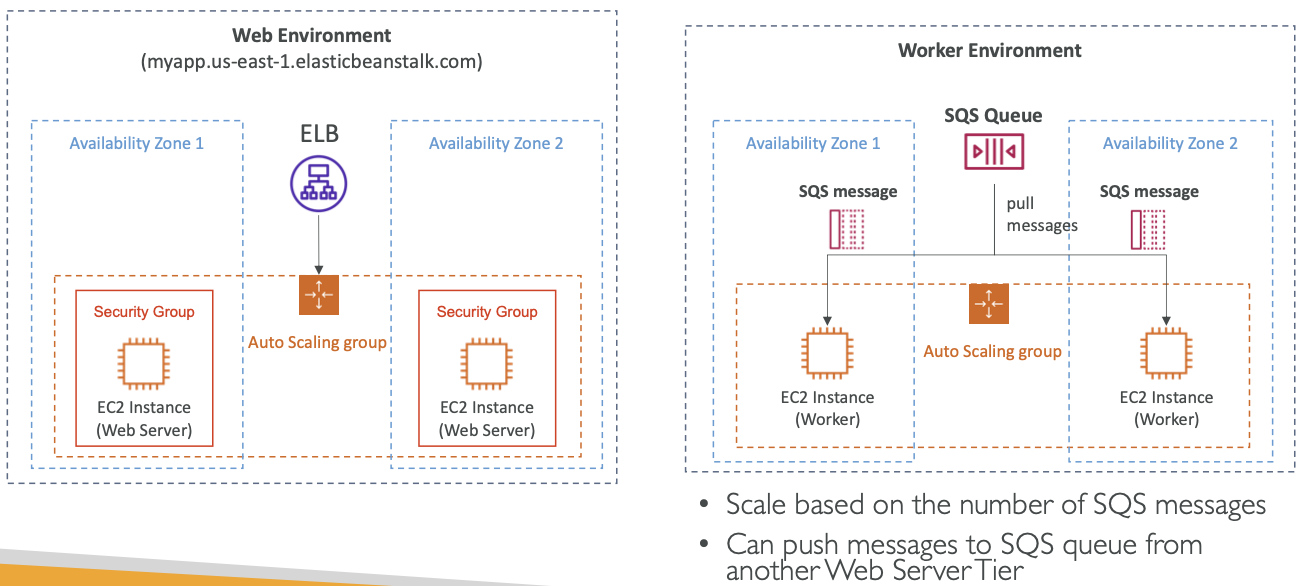
- Web ServerTier 旨在处理传入的 HTTP 请求,负责提供 Web 页面、运行 Web 应用程序和管理用户会话。
它通常包括一个 ELB,将传入的流量分配到多个应用程序实例中,提高性能和可用性。 - WorkerTier 则旨在处理后台任务或长时间运行的进程,与提供 Web 请求的任务无直接关系。
它通常用于诸如 数据处理、图像或视频编码、消息队列处理和其他类型的批处理作业等任务。 - WorkerTier 可用于从 Web ServerTier 中卸载资源密集型任务。
- WorkerTier 可以根据 SQS 消息数量进行扩展(独立于 Web ServerTier 服务器)
- Web ServerTier 可以将消息推送到 WorkerTier 的 SQS 队列
Elastic Beanstalk 部署模式

Amazon S3 Section
Amazon S3 是 AWS 的主要组成部分之一,许多网站使用 Amazon S3 作为核心部分,许多 AWS 服务也使用 Amazon S3 进行集成
Amazon S3 Use cases
- 备份和存储
- 灾难恢复
- 归档
- 混合云存储
- 应用程序托管
- 媒体托管
- 数据湖和大数据分析
- 软件交付
- 静态网站
Amazon S3 — Buckets
- Amazon S3 允许人们将对象(文件)存储在“存储桶”(目录)中
- 存储桶必须具有全球唯一的名称(跨所有区域的所有账户)
- 虽然 S3 是 Global 服务,但存储桶是在特定 Regions 中创建的
- 命名约定
- 没有大写字母,没有下划线
- 3-63 个字符长
- 不是 IP
- 必须以小写字母或数字开头
- 不得以前缀 xn-- 开头
- 不得以后缀 -s3alias 结尾
Amazon S3 — Objects
- 每个 Objects(files)对应一个键(key)
- 关键是完整路径:
- s3://my-bucket/my_file.txt
- s3://my-bucket/my_folder1/another_folder/my_file.txt
- 键由前缀+对象名组成
- s3://my-bucket/my_folder1/another_folder/my_file.txt
- S3 存储桶中没有“目录”的概念,键通常是一个很长的名称,可以包含斜杠(“/”)字符,这些“/”被用来模拟目录结构。
- 对象值是内容主体:
- 单个对象的最大存储空间为 5TB (5000GB)
- 如果上传超过5GB,必须使用“multi-part upload”
- MetaData(文本键/值对列表 — 系统或用户元数据)
- Tags (Unicode 键/值对 — 最多 10 个) — 对于安全/生命周期有用
- Version ID(如果启用版本控制)
Amazon S3 — Security
- User-Based
- IAM 策略 — 应允许特定用户从 IAM 调用哪些 API
- Resource-Based
- 存储桶策略 — 来自 S3 控制台的存储桶范围规则 — 允许跨账户
- 对象访问控制列表 (ACL) — 更细粒度(可以禁用)
- 存储桶访问控制列表 (ACL) — 不太常见(可以禁用)
- 注意:满足以下条件时 IAM principal 可以访问 S3 对象:
- 用户 IAM权限 允许或 资源策略 允许
- 并且没有明确的拒绝
- Encryption:使用加密密钥加密 Amazon S3 中的对象
S3 Bucket Policies
- 基于 JSON 的策略
- Resources:存储桶和对象
- Effect:允许/拒绝
- Actions:API 集
- Principal:应用策略的帐户或用户
- 使用 S3 Bucket Policies 可以实现:
- 授予公共访问存储桶的权限
- 强制对象在上传时加密
- 授予对另一个帐户的访问权限(跨帐户)

示例:公共访问 — 使用存储桶策略

示例:用户访问 S3 — IAM 权限

示例:EC2 实例访问 — 使用 IAM 角色

进阶:跨账户访问 — 使用存储桶策略

阻止公共访问的存储桶设置

- 创建这些设置是为了防止公司数据泄露
- 如果您知道您的存储桶永远不应该公开,请将它们保留在
- 可以在帐户级别设置
Amazon S3 — Static Website Hosting(静态网站托管)
- S3 可以托管静态网站并让互联网用户可以访问它们
- 网站 URL 为(取决于地区)
- 如果您收到 403 Forbidden 错误,请确保存储桶策略允许 public reads!
Amazon S3 — Versioning
- 可以在 Amazon S3 中对文件进行版本控制
- 它在存储桶级别启用
- 相同密钥的覆盖将更改“版本”:1、2、3…
- 最佳实践是对存储桶进行版本控制
- 防止意外删除(恢复版本的能力)
- 轻松回滚到以前的版本
- 注意:
- 在启用版本控制之前未进行版本控制的任何文件的版本将为“null”
- 暂停版本控制不会删除以前的版本
Amazon S3 — Replication(CRR & SRR)
- 必须在源存储桶和目标存储桶中启用版本控制
- Cross-Region 复制 (CRR)
- Same-Region 复制 (SRR)
- 存储桶可以位于不同的 AWS 账户中
- 复制是异步的
- 必须向 S3 授予适当的 IAM 权限
- 用例:
- CRR:合规性、低延迟访问、跨账户复制
- SRR:日志聚合、生产和测试帐户之间的实时复制
Notes
- 启用复制后,仅复制新对象
- 也可以选择使用 S3 批量复制来复制现有对象
- 复制现有对象和复制失败的对象
- 对于删除操作
- 可以将删除标记从源复制到目标(可选设置)
- 不会复制带有版本 ID 的删除(以避免恶意删除)
- 不存在复制 “chaining” 链式反应
- 如果 存储桶1 已复制到 存储桶2,而 存储桶2 已复制到 存储桶3
- 那么在 存储桶1 中创建的对象不会复制到 存储桶3
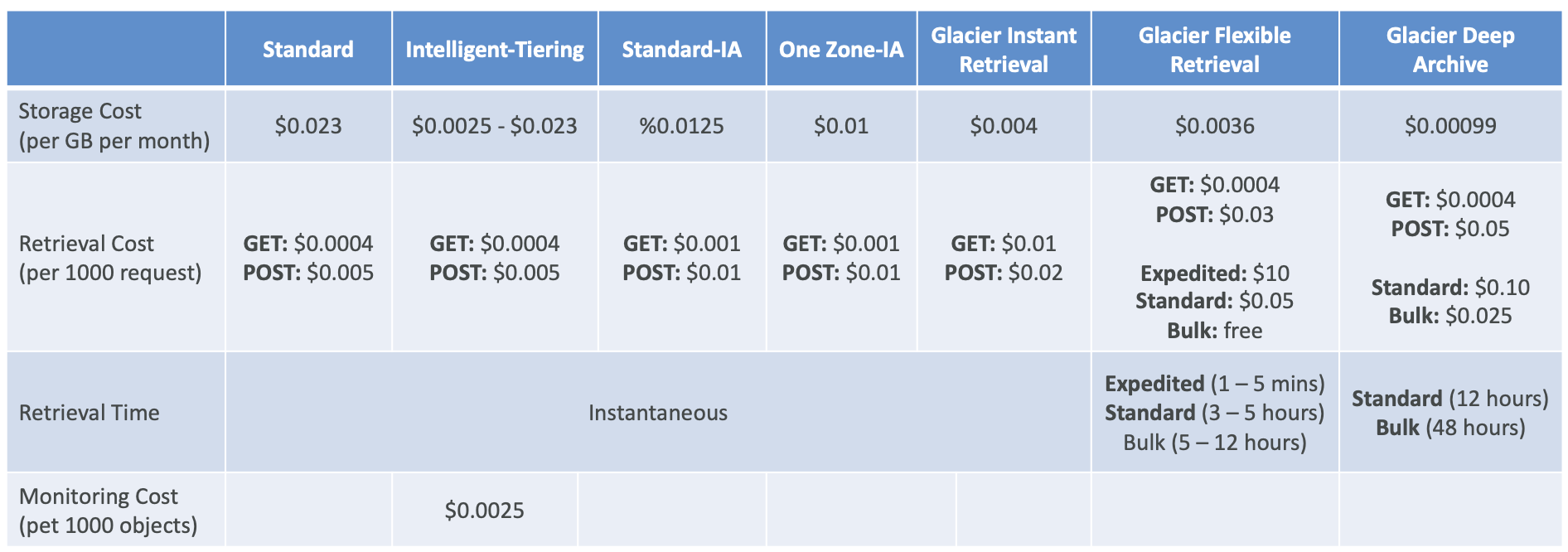
Amazon S3 Storage Classes
- Amazon S3 Standard — General Purpose(通用)
- Amazon S3 Standard — Infrequent Access (IA)
- Amazon S3 One Zone — 不频繁访问
- Amazon S3 Glacier Instant Retrieval
- Amazon S3 Glacier Flexible Retrieval
- Amazon S3 Glacier Deep Archive
- Amazon S3 Intelligent Tiering
- 用户可以手动配置转移对象的存储类别,也可以使用 S3 生命周期 自动转移或删除对象
S3 Durability and Availability
- 耐用性:
- 跨多个可用区的对象的高持久性(99.999999999%,11 个 9)
- 如果您使用 Amazon S3 存储 10,000,000 个对象,则平均每 10,000 年就会丢失一个对象
- 所有存储类别均相同
- 可用性:
- 衡量服务的可用性
- 因存储类别而异
- 示例:S3 标准的可用性为 99.99% = 每年有 53 分钟不可用
S3 Standard — 通用
- 99.99% 的可用性
- 用于经常访问的数据
- 低延迟和高吞吐量
- 维持 2 个并发设施故障
- 用例:大数据分析、移动和游戏应用程序、内容分发…
S3 Storage Classes — Infrequent Access
- 适用于访问频率较低但需要在需要时快速访问的数据
- 成本低于 S3 标准
- Amazon S3 标准 - 不频繁访问(S3 标准 - IA)
- 99.9% 的可用性
- 使用案例:灾难恢复、备份
- Amazon S3 单时区 - 不频繁访问(S3 One Zone - IA)
- 单个 AZ 内的高耐用性(99.999999999%),但 AZ 被破坏时数据会丢失
- 99.5% 的可用性
- 用例:存储本地数据的辅助备份副本或可以重新创建的数据
S3 Glacier Storage Classes
- 用于归档/备份的低成本对象存储
- 定价:存储价格 + 对象检索成本
- Amazon S3 Glacier 即时检索
- 毫秒检索,非常适合每季度访问一次的数据
- 最短储存期限为 90 天
- Amazon S3 Glacier 灵活检索(以前称为 Amazon S3 Glacier):
- 加急(1 至 5 分钟)、标准(3 至 5 小时)、批量(5 至 12 小时)- 免费
- 最短储存期限为 90 天
- Amazon S3 Glacier Deep Archive — 用于长期存储:
- 标准(12 小时)、批量(48 小时)
- 最短存储期限为 180 天
S3 Intelligent Tiering
- 每月少量的监控和自动分层费用
- 根据使用情况在访问层之间自动移动对象
- S3 智能分层中没有检索费用
- 频繁访问层(自动):默认层
- 不频繁访问层(自动):30 天未访问的对象
- 存档即时访问层(自动):90 天内未访问的对象
- 存档访问层(可选):可配置为 90 天至 700 天以上
- 深度存档访问层(可选):配置。 从 180 天到 700+ 天
S3 Storage Classes 比较
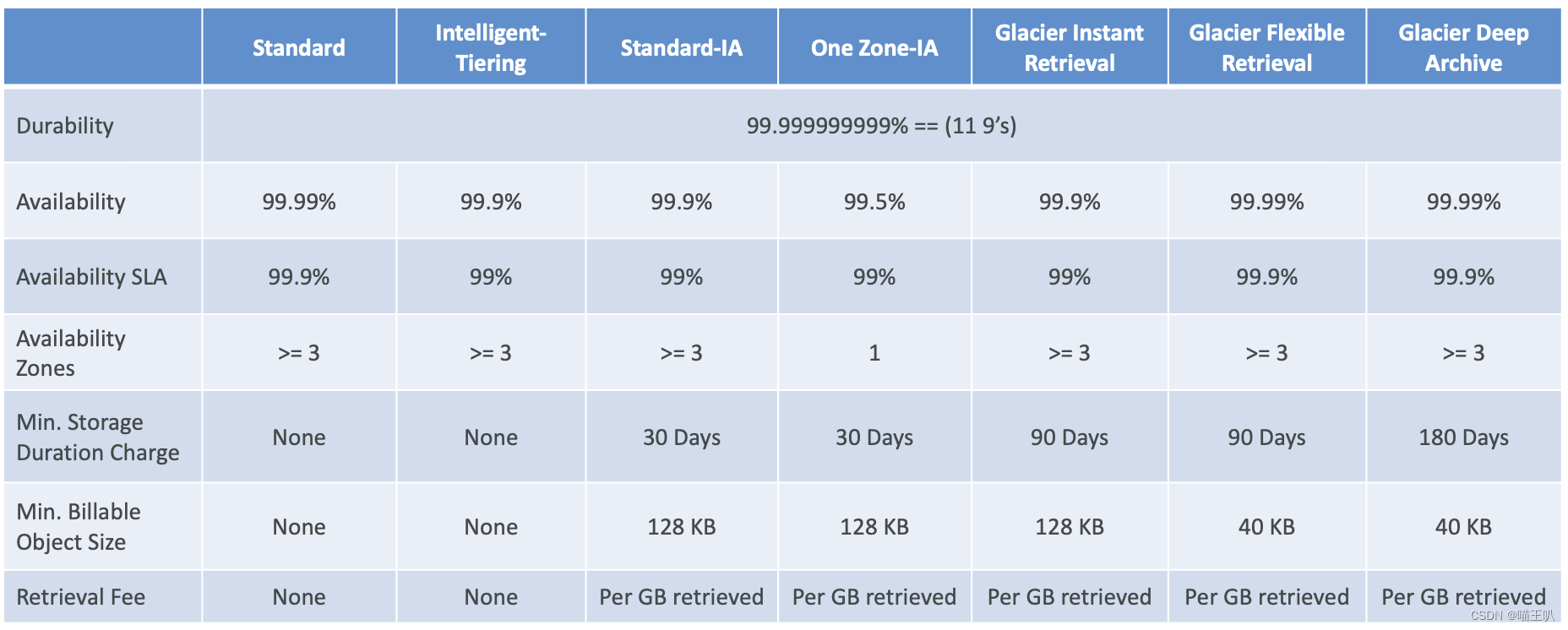
S3 存储类别 — 价格比较示例:us-east-1
Advanced S3
Amazon S3 — Storage Classes 间的转换
- 用户可以在存储类别之间转换对象
- 对于不经常访问的对象,将其移至标准 IA
- 对于不需要快速访问的存档对象,将其移至 Glacier 或 Glacier Deep Archive
- 可以使用生命周期规则自动转移对象
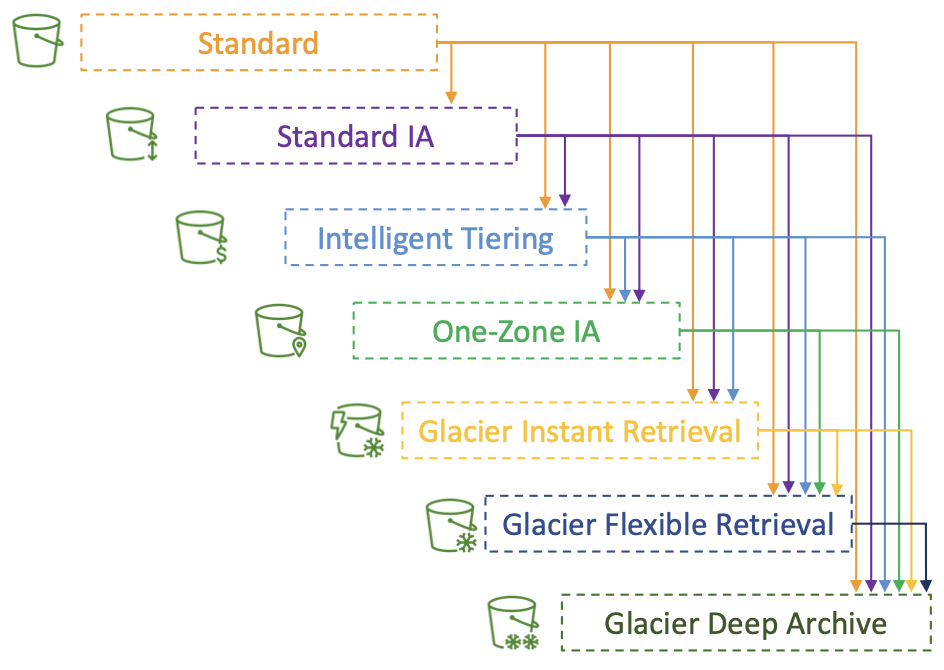
Amazon S3 — Lifecycle Rules
- 转换操作 — 配置对象以转换到另一个存储类别
- 创建后 60 天将对象移至标准 IA 类
- 6 个月后移至 Glacier 进行存档
- 过期操作 — 配置对象在一段时间后过期(删除)
- 访问日志文件可以设置为在 365 天后删除
- 可用于删除旧版本的文件(如果启用了版本控制)
- 可用于删除不完整的分段上传
- 可以为特定前缀创建规则(例如:s3://mybucket/mp3/*)
- 可以为某些对象标签创建规则(例如:部门:财务)
Amazon S3 — 生命周期规则(场景 1)
- 您在 EC2 上的应用程序会在将个人资料照片上传到 Amazon S3 后创建图像缩略图。这些缩略图可以轻松重新创建,并且只需要保留 60 天。源图像应该能够在这 60 天内立即检索,并且 此后,用户最多可以等待 6 小时。 你会如何设计这个?
- S3 源映像可以采用标准,并通过生命周期配置在 60 天后将其转换到 Glacier
- S3 缩略图可以位于 One-Zone IA 上,生命周期配置可使其在 60 天后过期(删除)
Amazon S3 — 生命周期规则(场景 2)
- 您公司的一条规则规定,您应该能够在 30 天内立即恢复已删除的 S3 对象,尽管这种情况很少发生。 在此时间之后,最多 365 天内,已删除的对象应该可以在 48 小时内恢复。
- 启用 S3 版本控制以获得对象版本,以便“已删除的对象”实际上被“删除标记”隐藏并可以恢复
- 将对象的“非当前版本”转换为标准 IA
- 随后将“非当前版本”转换为 Glacier Deep Archive
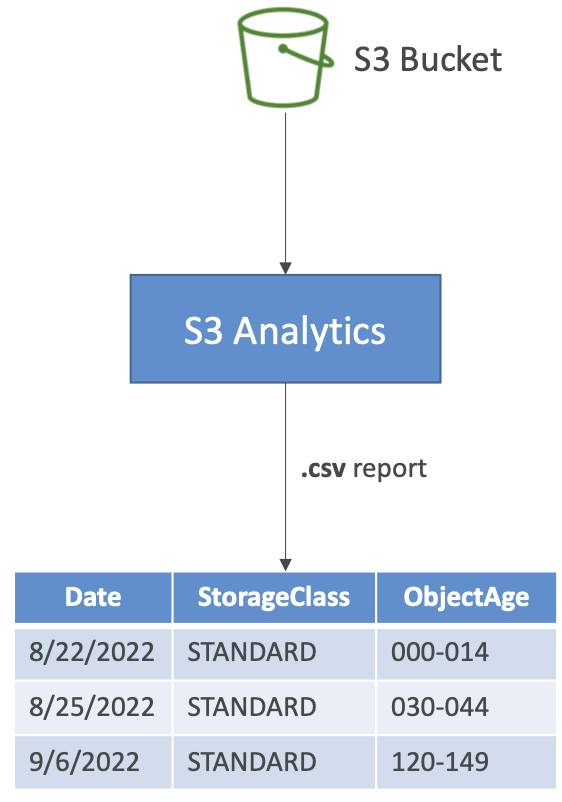
Amazon S3 Analytics — Storage Class Analysis
- 帮助用户决定何时将对象转换到正确的存储类别
- 对标准和标准 IA 的建议
- 不适用于单区 IA 或 Glacier
- 报告 每日更新
- 24 至 48 小时即可开始查看数据分析
- 整合生命周期规则(或改进它们)的良好第一步!
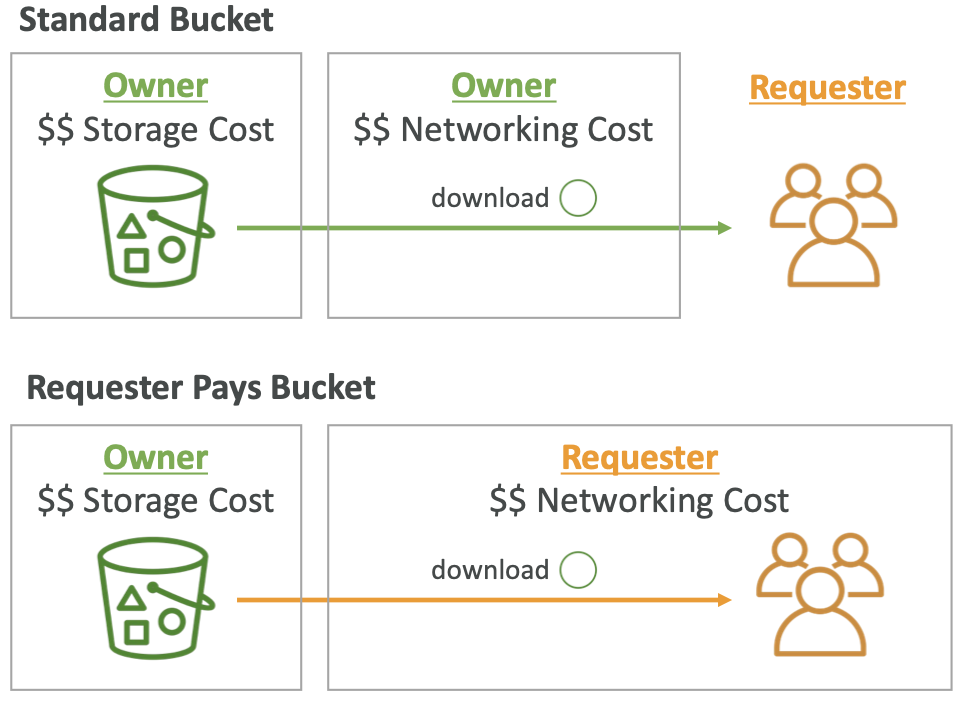
S3 — Requester Pays
- 一般来说,存储桶所有者支付与其存储桶相关的所有 Amazon S3 存储和数据传输成本
- 通过请求者支付存储桶,请求者(而不是存储桶所有者)支付请求费用以及从存储桶下载数据的费用
- 当用户想要与其他帐户共享大型数据集时很有帮助
- 请求者必须在 AWS 中经过身份验证(不能匿名)
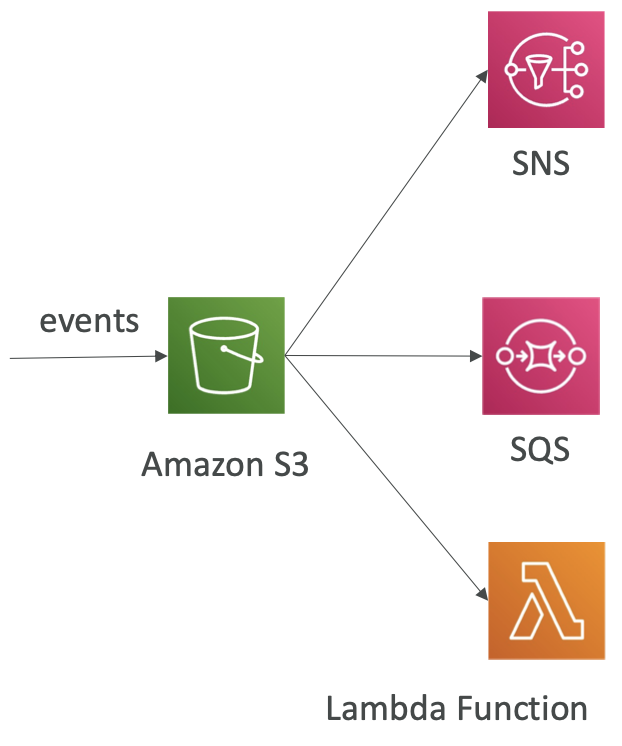
S3 Event Notifications
- S3:对象创建、S3:对象删除、S3:对象恢复、S3:复制…
- 可进行对象名称过滤 (*.jpg)
- 使用案例:生成上传到 S3 的图像的缩略图
- 可以根据需要创建任意数量的“S3 事件”
- S3 事件通知通常会在几秒钟内传送事件,但有时可能需要一分钟或更长时间
使用 Amazon EventBridge 的 S3 事件通知
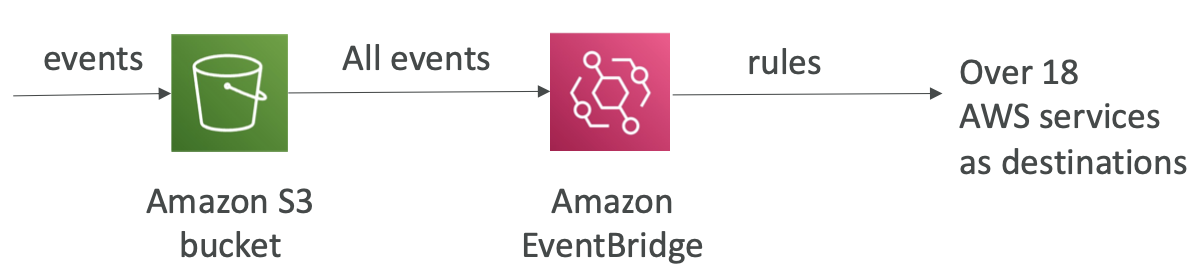
- 具有 JSON 规则的高级过滤选项(元数据、对象大小、名称…)
- 多个目标 — 例如 Step Functions、Kinesis Streams/Firehose…
- EventBridge 功能 — 存档、重播事件、可靠交付
S3 — Baseline Performance 基准性能
- Amazon S3 自动扩展到高请求率,延迟为 100-200 毫秒
- 用户应用程序可以实现存储桶中每个前缀每秒至少 3,500 个 PUT/COPY/POST/DELETE 或 5,500 个 GET/HEAD 请求。
- 存储桶中的前缀数量没有限制。
- 示例(对象路径 => 前缀):
- bucket/folder1/sub1/file => /folder1/sub1/
- bucket/folder1/sub2/file => /folder1/sub2/
- bucket/1/file => /1/
- bucket/2/file => /2/
- 如果将读取均匀分布在所有四个前缀上,则每秒可以实现 22,000 个 GET 和 HEAD 请求
S3 Performance
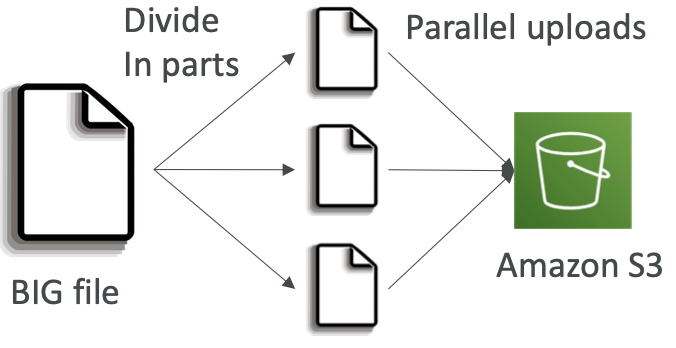
- Multi-Part upload:
- 建议用于 > 100MB 的文件,必须用于 > 5GB 的文件
- 可以帮助并行上传(加快传输速度)
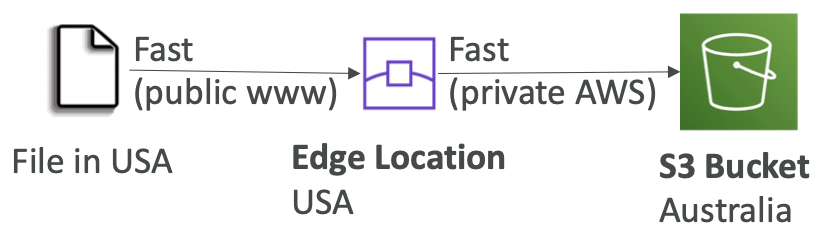
- S3 Transfer Acceleration
- 通过将文件传输到 AWS 边缘站点来提高传输速度,该站点会将数据转发到目标区域中的 S3 存储桶
- 兼容分段上传
S3 Performance — S3 Byte-Range Fetches
- 通过请求特定字节范围来并行化 GET
- 发生故障时具有更好的恢复能力
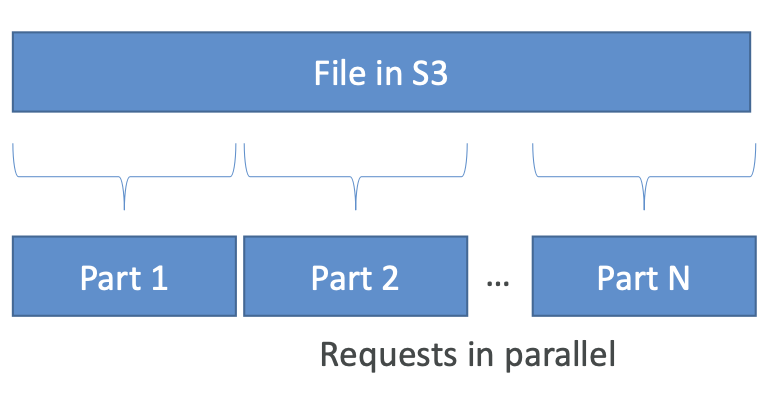
可用于加快下载速度

可用于仅检索部分数据(例如文件头)
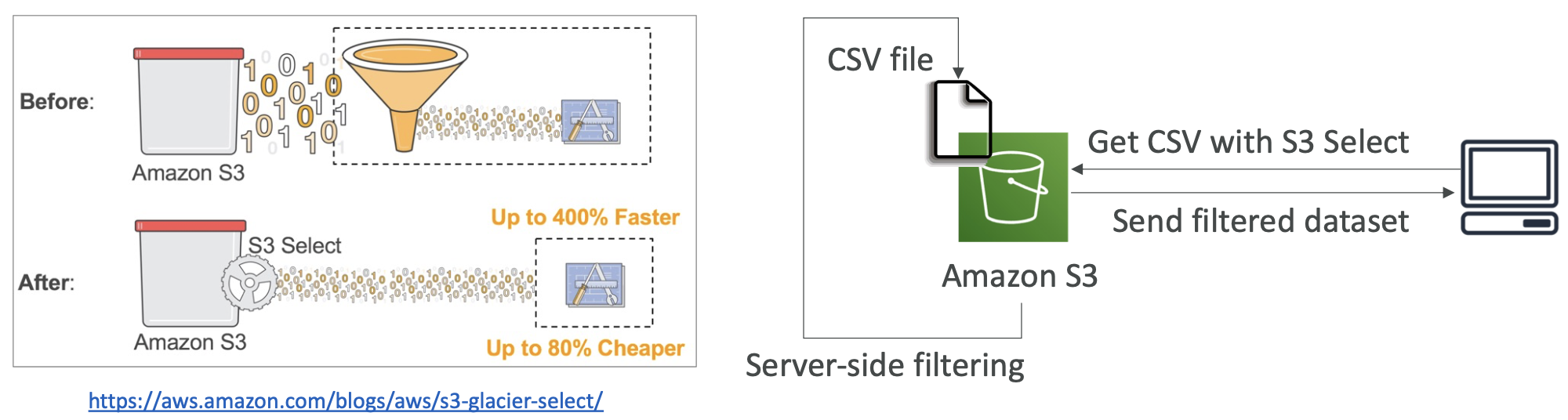
S3 Select 和 Glacier Select
- 通过执行服务器端过滤,使用 SQL 检索更少的数据
- 可以按行和列进行过滤(简单的 SQL 语句)
- 网络传输更少,客户端 CPU 成本更低
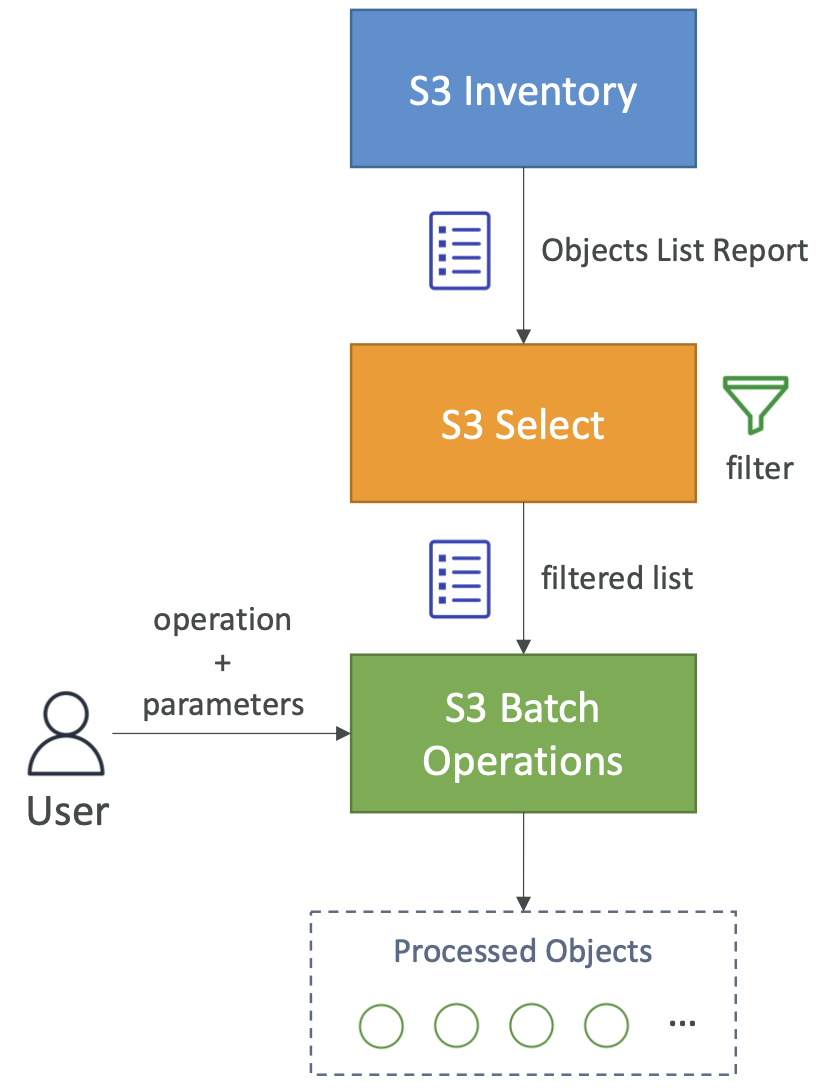
S3 批量操作
- 通过单个请求对现有 S3 对象执行批量操作,例如:
- 修改对象元数据和属性
- 在 S3 存储桶之间复制对象
- 加密未加密的对象
- 修改 ACL、标签
- 从 S3 Glacier 恢复对象
- 调用 Lambda 函数以执行自定义操作
- 作业由对象列表、要执行的操作和可选参数组成
- S3 批量操作管理重试、跟踪进度、发送完成通知、生成报告…
- 您可以使用 S3 Inventory 获取对象列表并使用 S3 Select 过滤对象
Amazon S3 安全
Amazon S3 — 对象加密
- 您可以使用 4 种方法之一加密 S3 存储桶中的对象
- 服务器端加密 (SSE)
- 使用 Amazon S3 托管密钥的服务器端加密 (SSE-S3) — 默认启用
- 使用 AWS 处理、管理和拥有的密钥加密 S3 对象
- 使用存储在 AWS KMS 中的 KMS 密钥进行服务器端加密 (SSE-KMS)
- 利用AWSKey Management Service (AWSKMS) 管理加密密钥
- 使用客户提供的密钥进行服务器端加密 (SSE-C)
- 当您想要管理自己的加密密钥时
- 使用 Amazon S3 托管密钥的服务器端加密 (SSE-S3) — 默认启用
- 客户端加密
- 重要的是要了解哪些内容适用于哪种考试情况
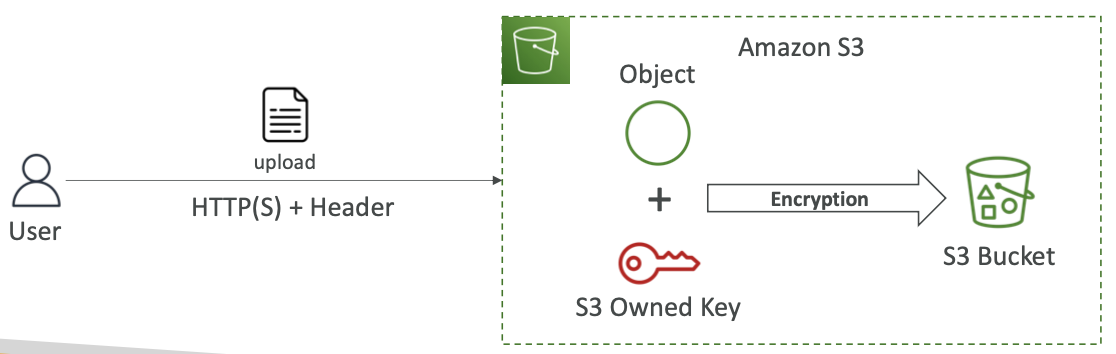
Amazon S3 加密 — SSE-S3
- 使用由 AWS 处理、管理和拥有的密钥进行加密
- 对象在服务器端加密
- 加密类型为 AES-256
- 必须设置标头“x-amz-server-side-encryption”:“AES256”
- 默认情况下为新存储桶和新对象启用
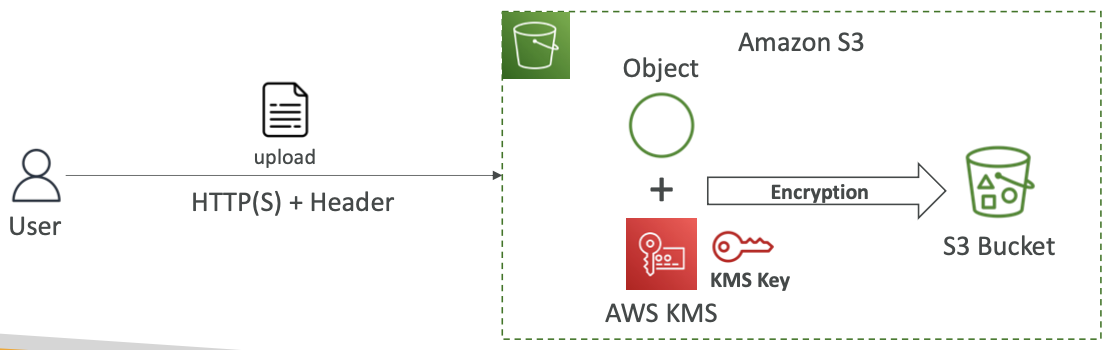
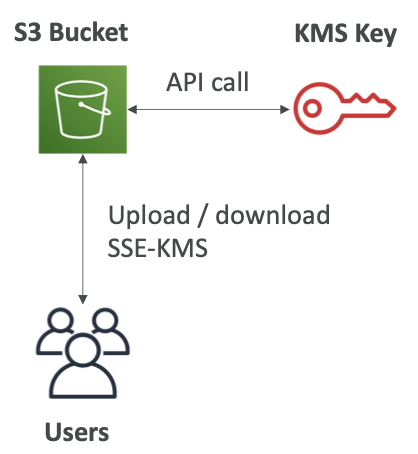
Amazon S3 加密 — SSE-KMS
- 使用由 AWS KMS(密钥管理服务)处理和管理的密钥进行加密
- KMS 优势:用户控制 + 使用 CloudTrail 审核密钥使用情况
- 对象在服务器端加密
- 必须设置标头“x-amz-server-side-encryption”:“aws:kms”
SSE-KMS Limitation
- 如果使用 SSE-KMS,用户可能会受到 KMS 限制的影响
- 当上传时,它会调用 GenerateDataKey KMS API
- 当您下载时,它会调用解密 KMS API
- 计入每秒 KMS 配额(根据区域为 5500、10000、30000 请求/秒)
- 可以使用服务配额控制台请求增加配额
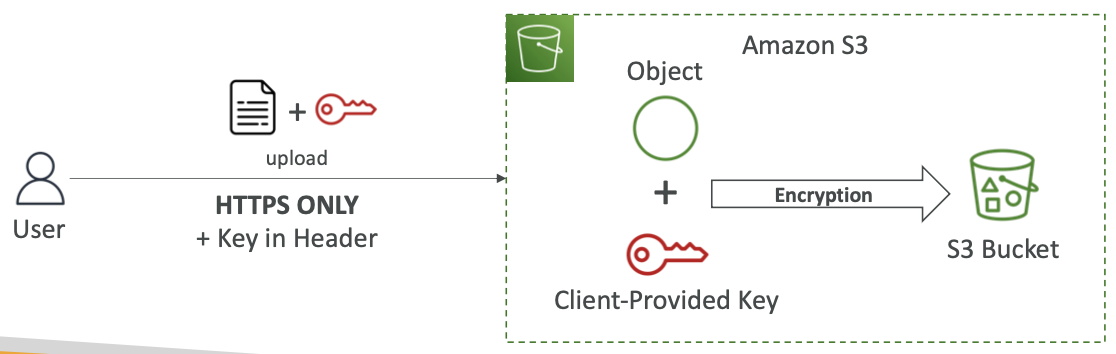
Amazon S3 加密 — SSE-C
- 使用完全由客户在 AWS 外部管理的密钥进行服务器端加密
- Amazon S3 不存储您提供的加密密钥
- 必须使用 HTTPS
- 对于发出的每个 HTTP 请求,必须在 HTTP 标头中提供加密密钥
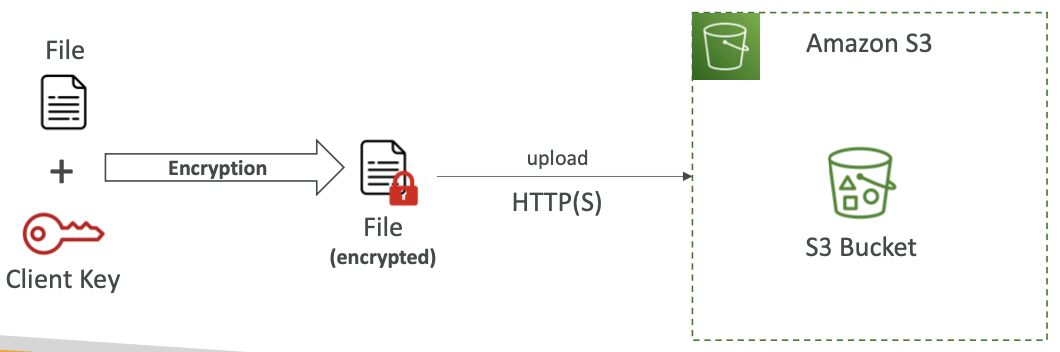
Amazon S3 加密 — Client-Side Encryption
- 使用客户端库,例如 Amazon S3 客户端加密库
- 客户端在发送到 Amazon S3 之前必须自行加密数据
- 从 Amazon S3 检索数据时,客户端必须自行解密数据
- 客户完全管理密钥和加密周期
Amazon S3 — Encryption in transit (SSL/TLS)
- 传输中加密也称为 SSL/TLS
- Amazon S3 公开两个终端节点:
- HTTP 端点 — 未加密
- HTTPS 端点 — 动态加密
- 建议使用HTTPS
- HTTPS 对于SSE-C 是强制的
- 大多数客户端默认使用 HTTPS 端点
Amazon S3 — Default Encryption vs. Bucket Policies
- SSE-S3 加密自动应用于 S3 存储桶中存储的新对象
- 您可以选择使用存储桶策略“强制加密”,并拒绝任何 API 调用来 PUT 没有加密标头的 S3 对象(SSE-KMS 或 SSE-C)
- 注意:存储桶策略在“默认加密”之前评估

什么是 CORS?
- 跨源资源共享 (CORS)
- 来源 = 方案(协议)+ 主机(域)+ 端口
- 示例:https://www.example.com(HTTPS 的隐含端口为 443,HTTP 的隐含端口为 80)
- 基于 Web 浏览器的机制,允许在访问主源时向其他源发出请求
- 同源:http://example.com/app1 和 http://example.com/app2
- 不同来源:http://www.example.com & http://other.example.com
- 除非其他源使用 CORS 标头允许请求(例如:Access-Control-Allow-Origin),否则请求不会得到满足

Amazon S3 — CORS
- 如果客户端对我们的 S3 存储桶发出跨域请求,我们需要启用正确的 CORS 标头
- 这是一个热门考试题
- 您可以允许特定来源或*(所有来源)

Amazon S3 — MFA Delete
- MFA(多重身份验证)– 强制用户在 S3 上执行重要操作之前在设备(通常是移动电话或硬件)上生成代码
- MFA 将被要求:
- 永久删除对象版本
- 暂停存储桶上的版本控制
- MFA 不需要:
- 启用版本控制
- 列出已删除的版本
- 要使用 MFA 删除,必须在存储桶上启用版本控制
- 只有存储桶所有者(根账户)才能启用/禁用 MFA 删除
S3 访问日志
- 出于审计目的,您可能希望记录对 S3 存储桶的所有访问
- 从任何帐户向 S3 发出的任何请求(无论授权还是拒绝)都将记录到另一个 S3 存储桶中
- 可以使用数据分析工具来分析该数据…
- 目标日志记录存储桶必须位于同一AWS 区域
- 日志格式位于:https://docs.aws.amazon.com/AmazonS3/latest/dev/LogFormat.html

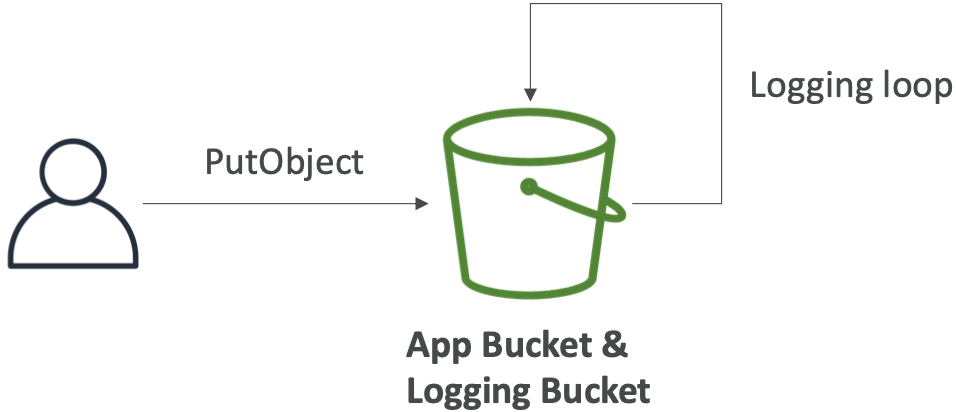
S3 访问日志:警告
- 不要将您的日志存储桶设置为受监控存储桶
- 它将创建一个日志循环,您的存储桶将呈指数级增长
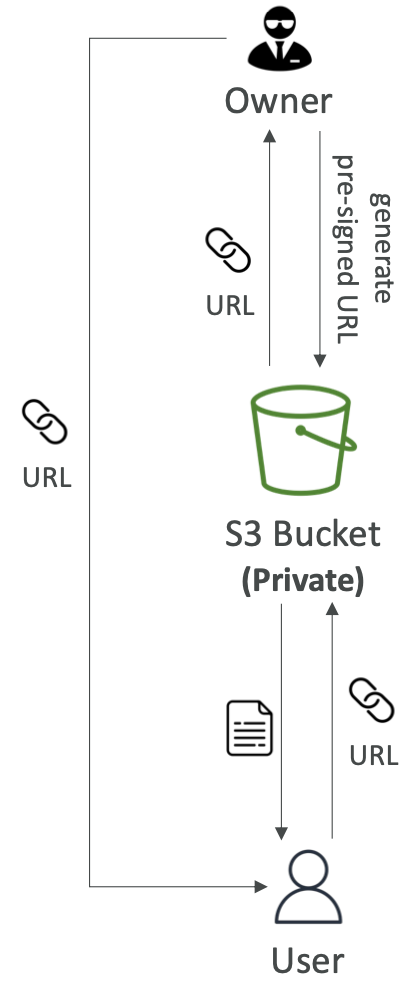
Amazon S3 — 预签名 URL
- 使用S3 控制台、AWS CLI 或开发工具包生成预签名URL
- URL 过期
- S3 控制台 — 1 分钟至 720 分钟(12 小时)
- AWS CLI — 使用–expires-in 参数配置过期时间(以秒为单位)(默认 3600 秒,最长 604800 秒 ~ 168 小时)
- 获得预签名 URL 的用户将继承生成 GET/PUT URL 的用户的权限
- 例子:
- 仅允许登录用户从您的 S3 存储桶下载优质视频
- 通过动态生成 URL,允许不断变化的用户列表下载文件
- 暂时允许用户将文件上传到 S3 存储桶中的精确位置
 |
|
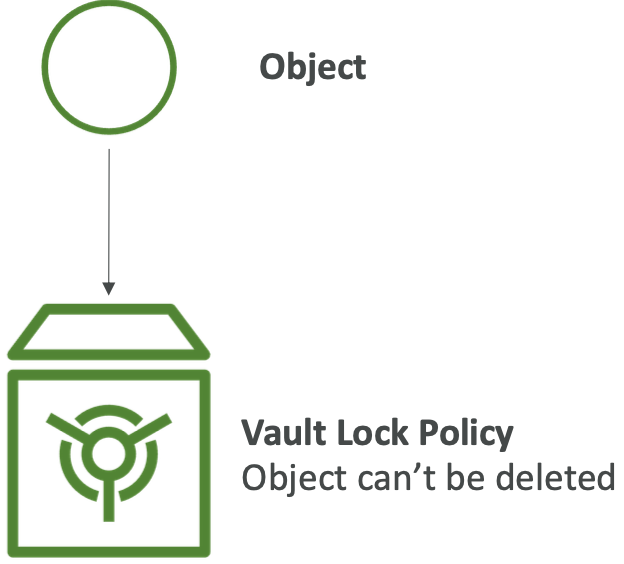
S3 Glacier Vault Lock
- 采用WORM(一次写入多次读取)模型
- 创建保管库锁定策略
- 锁定策略以供将来编辑(无法再更改或删除)
- 有助于合规性和数据保留
 |
|
S3 Object Lock(必须启用版本控制)
- 采用WORM(一次写入多次读取)模型
- 在指定的时间内阻止对象版本删除
- 保留模式 - 合规性:
- 任何用户(包括 root 用户)都无法覆盖或删除对象版本
- 对象保留模式无法更改,保留期限无法缩短
- 保留模式 - 治理:
- 大多数用户无法覆盖或删除对象版本或更改其锁定设置
- 某些用户具有更改保留或删除对象的特殊权限
- 保留期限:在固定期限内保护对象,可以延长
- 合法保留:
- 无限期地保护对象,不受保留期限的影响
- 可以使用 s3:PutObjectLegalHold IAM 权限自由放置和删除
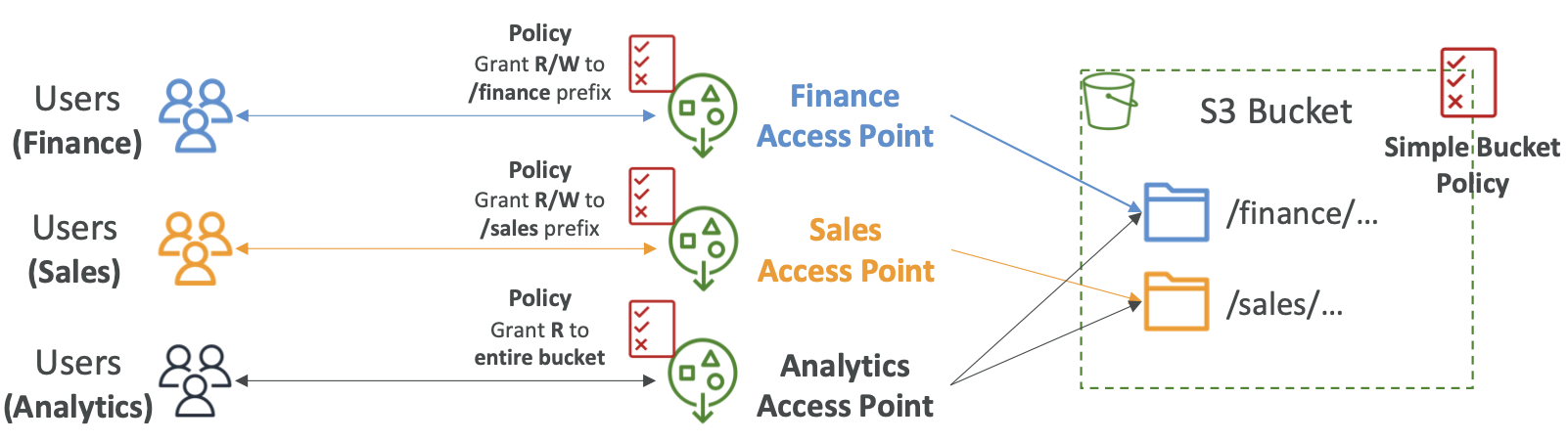
S3 – Access Points(接入点)
- 接入点简化了 S3 存储桶的安全管理
- 每个接入点都有:
- 自己的 DNS 名称(Internet Origin 或 VPC Origin)
- 接入点策略(类似于存储桶策略)——大规模管理安全性
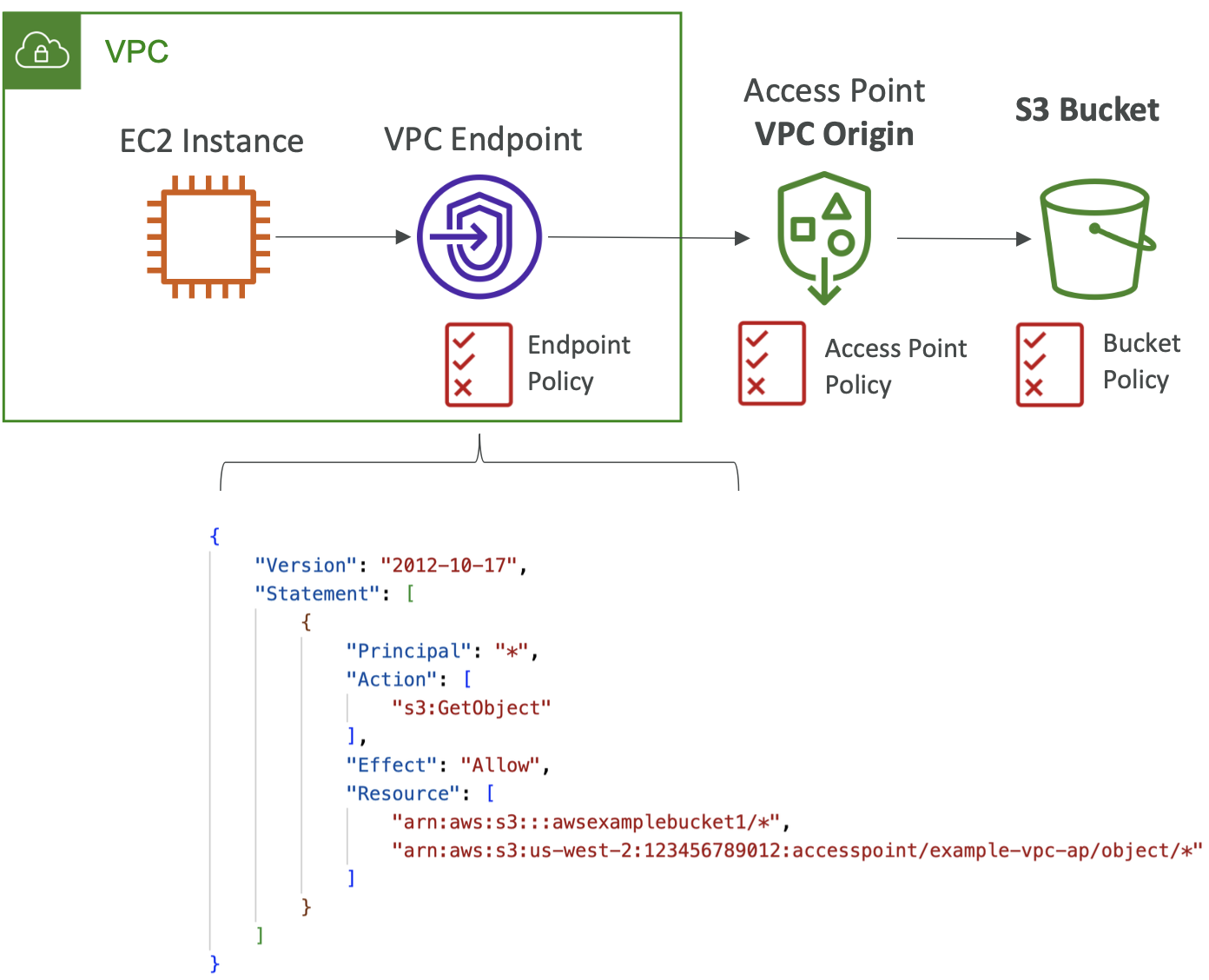
S3 – 接入点 – VPC Origin
- 我们可以定义只能从 VPC 内部访问的访问点
- 您必须创建 VPC 端点才能访问接入点(网关或接口端点)
- VPC 端点策略必须允许访问目标存储桶和接入点
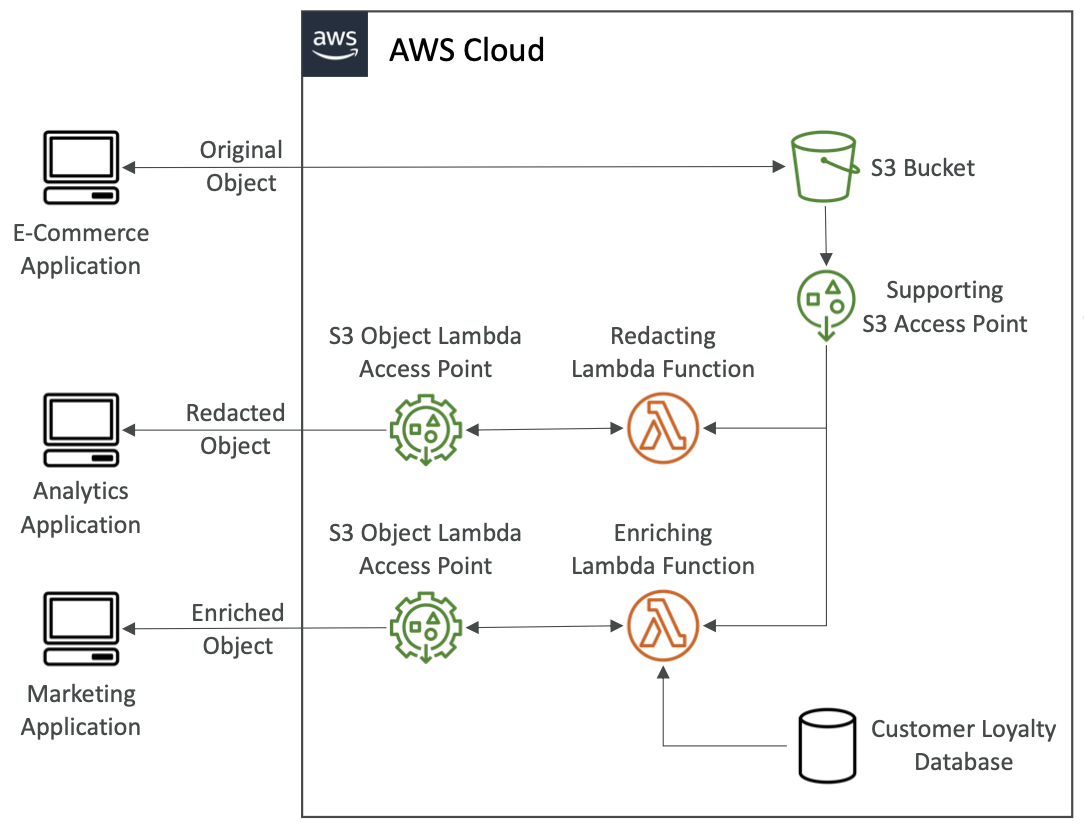
S3 Object Lambda
- 在调用者应用程序检索对象之前,使用 AWS Lambda 函数更改对象
- 仅需要一个 S3 存储桶,我们在其上创建 S3 访问点和 S3 对象 Lambda 访问点。
- 用例:
- 编辑个人身份信息以用于分析或非生产环境。
- 跨数据格式转换,例如将 XML 转换为 JSON。
- 使用特定于调用者的详细信息(例如请求该对象的用户)动态调整图像大小并为其添加水印。
文章来源:https://blog.csdn.net/weixin_40815218/article/details/135591326
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 精进单元测试技能——Pytest断言的艺术
- FPGA中为什么不能双时钟触发
- 前端-如何用echarts绘制含有多个分层的波形图
- 谷歌Gemini造假始末
- 【Python面试场】:行情太差,我被裁了
- Js进阶31-DOM 操作专题
- 数据集介绍【01】-MNIST
- 图数据库NebulaGraph学习
- 【Latex错误:】Package fontspec: The font “SIMLI“ cannot be found. LaTex [行 37,列1]
- 代码随想录算法训练营第二十五天 | 回溯算法part2