ForecastPFN: Synthetically-Trained Zero-Shot Forecasting
ForecastPFN: Synthetically-Trained Zero-Shot Forecasting
2023.11.3 arxiv
论文下载
源码
ForecastPFN(Prior-data Fitted Networks)是zero-shot场景的:经过初始预训练后,它可以对一个全新的数据集进行预测,而没有来自该数据集的训练数据。
这个文章比较偏统计,可能涉及到先验、贝叶斯相关概念
PFN来源:TRANSFORMERS CAN DO BAYESIAN INFERENCE
2021年发表在ICLR上的文章
贝叶斯方法很难获得深度学习的好处,贝叶斯方法允许先验知识的明确规范和准确捕获模型的不确定性。我们提出先验数据拟合网络(PFN)。
摘要
绝大多数时间序列预测方法需要大量的训练数据集。然而,许多现实生活中的预测应用程序只有很少的初始观测值,有时只有40个或更少。因此,在数据稀疏的商业应用中的,大多数时间序列预测方法的适用性受到了限制。
(开篇说明课题背景:观测数据少)
虽然最近有些工作尝试在非常有限的初始数据设置下(“zero-shot"场景)做预测 ,由于预训练的数据不同,其性能也呈现出不一致性。
在我们的工作中,我们采用了一种不同的方法,并设计了ForecastPFN(prior-data fitted network),这是第一个纯粹基于新的合成数据分布训练的零样本预测模型。
ForecastPFN是一个先验数据拟合网络,经过训练以近似贝叶斯推理,可以在一次前向传递中对新的时间序列数据集进行预测。广泛的实验表明,与最先进的预测方法相比,ForecastPFN做出的零样本预测更准确、更快,即使当允许其他方法在数百个额外的分布内数据点上进行训练时也是如此。
处理数据集,合成数据集

贡献
- 引入ForecastPFN
- 实验,结果证明无需预训练,ForecastPFN也能表现得很好
介绍 FPN
巴拉巴拉一堆贝叶斯理论,先验后验,简单问题复杂化,得到第一步,先搞出一个合成的先验分布
,其实就是分解时间序列
Defining a Synthetic Prior for Time Series
时间序列值由三部分组成,trend,sezonal还有噪声zt,这个分解时按照乘法分解的,常见的分解方式还有加法分解
trend由线性成分和指数成分组成,包括四个参数 m l i n 、 m e x p 、 c l i n , c e x p m_{lin}、m_{exp}、c_{lin},c_{exp} mlin?、mexp?、clin?,cexp?四个参数
seasonal成分由周成分、月成分、年成分组成,各自对应参数 p w e e k , p m o n t h , p y e a r p_{week},p_{month},p_{year} pweek?,pmonth?,pyear?
噪声
z
t
z_{t}
zt?服从均值为1的Weibull分布
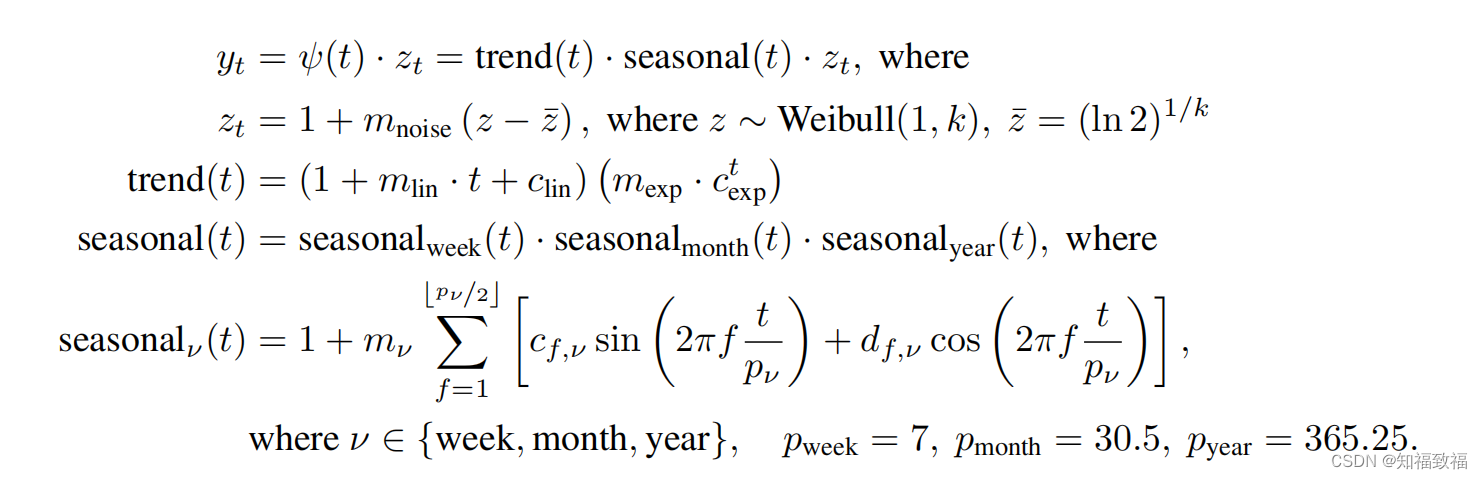
ForecastPFN: a PFN for Zero-Shot Forecasting
-
Architecture Details.
使用transformer做为基础模型,现有的transformer模型通常用于预测next N steps,但本模型与之不同,而是输入一个随机的单一的时间查询,就能预测这个查询的输出。 -
Robust Scaling.
常规的归一化方式像z-score、最大最小归一化等归一化方式不再适用于模型,部分原因是前面的分解操作包括了乘法还有指数操作,这会导致数值变化大
因此文章采用了一些措施来处理离群值:
(1)屏蔽所有缺失值,(2)基于所有非离群值数据点(定义为2-sigma异常值)标准化数据(对落在2σ区间内的数据进行标准化),(3)剪除所有3-sigma离群值。 -
Train Details
一次离线训练,在一块Tesla V100 16GB GPU 上跑了30h
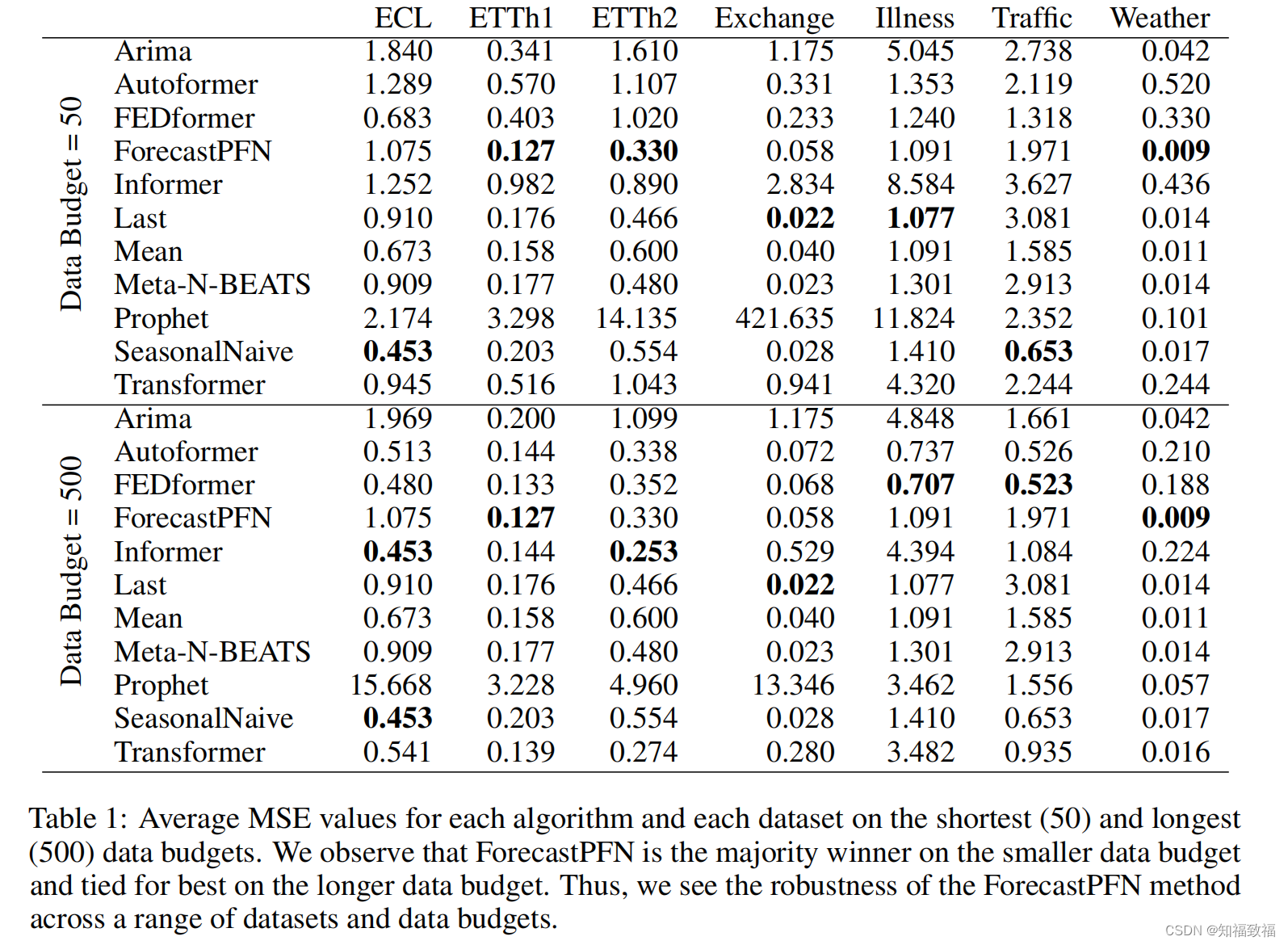
实验结果
只有Meta-N-BEATS和 ForeCastPFN模型是zero-shot,其他基线是非zero-shot的
在Data Budget=50和Data Budget=500情景下,将模型与基于统计学的模型(Arima、Last、Mean…)和基于transformer的模型(Autoformer、FEDFormer、Informer、Transformer)进行了对比,实验结果表示
DB=50,ETTh1、ETTh2、Weather
数据集下模型表现最优
DB=500,ETTh1,Weather数据集下表现最优
代码
tensorflow 不想读了,感觉读这篇文章花了好长时间,结果最后代码还是tensorflow的,有点亏
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringBoot自动装配原理
- pip install默认安装路径
- [go] 桥接模式
- django接收前端vue传输的formData图片数据
- 197.【2023年华为OD机试真题(C卷)】执行时长(模拟题-Java&Python&C++&JS实现)
- IBM vs. 量子噪音,迫在眉睫的技术之争
- AI出题,做不完,根本做不完
- 使用Windows10的OneDrive应用程序,让文件管理上一个台阶
- k8s-Pod
- 跨境必读,IP关联是什么意思?如何防止IP被关联?