基于CLIP4Clip的DRL的WTI模块实现
关于DRL的WTI模块:
- Weighted Token-wise Interaction:
直觉上,并非所有的单词和视频帧都同等重要。我们提供一种自适应方法,来调整每个标记的权重大小:
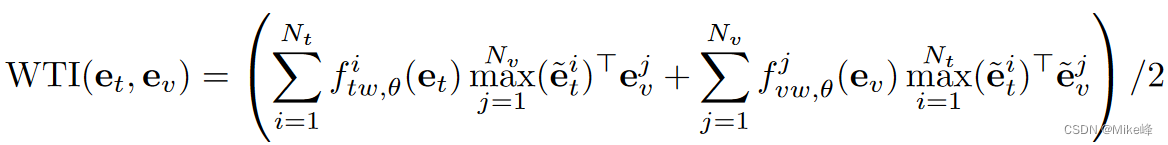
注:其中两个f函数都是MLP和softmax构成。
WTI的算法流程图:

- 输入video和text之后分别通过encoder,得到representation
- 之后使用fusion weights网络计算权重(在这个算法中,文本和视频的嵌入经过文本权重网络和视频权重网络,分别进行 Softmax 操作得到权重向量),
- 之后将representation进行归一化,
- 之后计算t2v和v2t的相关度
DRL中的WTI源代码:
def wti_interaction(self, text_feat, video_feat, text_mask, video_mask):
if self.training and torch.cuda.is_available(): # 在训练时,且有 GPU 可用时进行批处理合并
text_feat = allgather(text_feat, self.config) # 合并文本特征
video_feat = allgather(video_feat, self.config) # 合并视频特征
text_mask = allgather(text_mask, self.config) # 合并文本掩码
video_mask = allgather(video_mask, self.config) # 合并视频掩码
torch.distributed.barrier() # 强制同步
if self.config.interaction == 'wti': # 如果交互方式为加权令牌级交互
# 计算文本权重
text_weight = self.text_weight_fc(text_feat).squeeze(2) # B x N_t x D -> B x N_t
text_weight.masked_fill_(torch.tensor((1 - text_mask), dtype=torch.bool), float("-inf")) # 将未激活的令牌(padding)设置为负无穷
text_weight = torch.softmax(text_weight, dim=-1) # 对文本权重进行 softmax 操作,以获取归一化的权重值
# 计算视频权重
video_weight = self.video_weight_fc(video_feat).squeeze(2) # B x N_v x D -> B x N_v
video_weight.masked_fill_(torch.tensor((1 - video_mask), dtype=torch.bool), float("-inf")) # 将未激活的令牌(padding)设置为负无穷
video_weight = torch.softmax(video_weight, dim=-1) # 对视频权重进行 softmax 操作,以获取归一化的权重值
text_feat = text_feat / text_feat.norm(dim=-1, keepdim=True) # 对文本特征进行 L2 归一化
video_feat = video_feat / video_feat.norm(dim=-1, keepdim=True) # 对视频特征进行 L2 归一化
# 计算令牌间的交互得分
retrieve_logits = torch.einsum('atd,bvd->abtv', [text_feat, video_feat]) # 通过张量乘积计算交互得分
retrieve_logits = torch.einsum('abtv,at->abtv', [retrieve_logits, text_mask]) # 融合文本掩码到交互得分
retrieve_logits = torch.einsum('abtv,bv->abtv', [retrieve_logits, video_mask]) # 融合视频掩码到交互得分
text_sum = text_mask.sum(-1) # 文本掩码的求和结果
video_sum = video_mask.sum(-1) # 视频掩码的求和结果
if self.config.interaction == 'ti': # 如果交互方式为令牌级交互
# 令牌间的交互方式是逐令牌进行
t2v_logits, max_idx1 = retrieve_logits.max(dim=-1) # 最大化视频令牌得分,获得文本到视频的交互得分
v2t_logits, max_idx2 = retrieve_logits.max(dim=-2) # 最大化文本令牌得分,获得视频到文本的交互得分
t2v_logits = torch.sum(t2v_logits, dim=2) / (text_sum.unsqueeze(1)) # 对文本令牌得分进行加权平均
v2t_logits = torch.sum(v2t_logits, dim=2) / (video_sum.unsqueeze(0)) # 对视频令牌得分进行加权平均
retrieve_logits = (t2v_logits + v2t_logits) / 2.0 # 对文本到视频和视频到文本的交互得分进行平均
elif self.config.interaction == 'wti': # 如果交互方式为加权令牌级交互
t2v_logits, max_idx1 = retrieve_logits.max(dim=-1) # 最大化视频令牌得分,获得文本到视频的交互得分
t2v_logits = torch.einsum('abt,at->ab', [t2v_logits, text_weight]) # 对文本令牌得分进行加权
v2t_logits, max_idx2 = retrieve_logits.max(dim=-2) # 最大化文本令牌得分,获得视频到文本的交互得分
v2t_logits = torch.einsum('abv,bv->ab', [v2t_logits, video_weight]) # 对视频令牌得分进行加权
retrieve_logits = (t2v_logits + v2t_logits) / 2.0 # 对文本到视频和视频到文本的交互得分进行平均
if self.training:
# 缩放检索得分
logit_scale = self.clip.logit_scale.exp()
retrieve_logits = logit_scale * retrieve_logits
# 如果配置为 1,应用特定的损失函数
if self.config.cdcr == 1:
# ...(这部分代码用于特定的损失函数,返回对应的损失)
# 如果配置为 2,应用另一种特定的损失函数
elif self.config.cdcr == 2:
# ...(这部分代码用于另一种特定的损失函数,返回对应的损失)
# 如果配置为 3,应用另一种特定的损失函数
elif self.config.cdcr == 3:
# ...(这部分代码用于另一种特定的损失函数,返回对应的损失)
else:
return retrieve_logits, retrieve_logits.T, 0.0 # 返回检索得分
else:
return retrieve_logits, retrieve_logits.T, 0.0 # 返回检索得分
怎么把这个加进CLIP4Clip去?
发现DRL中的wit在get_similarity_logits()函数中被refer了,在modeling.py中
而CLIP4Clip中的modeling.py文件中同样含有函数get_similarity_logits(),思考怎么插入
get_similarity_logits()在DRL的调用位置:
def _run_on_single_gpu(model, t_mask_list, v_mask_list, t_feat_list, v_feat_list, mini_batch=32):
sim_matrix = [] # 创建一个空列表,用于存储相似度矩阵的结果
logger.info('[start] map to main gpu') # 记录日志,表示开始将数据映射到主 GPU
batch_t_mask = torch.split(t_mask_list, mini_batch) # 将文本掩码列表分割成小批次
batch_v_mask = torch.split(v_mask_list, mini_batch) # 将视频掩码列表分割成小批次
batch_t_feat = torch.split(t_feat_list, mini_batch) # 将文本特征列表分割成小批次
batch_v_feat = torch.split(v_feat_list, mini_batch) # 将视频特征列表分割成小批次
logger.info('[finish] map to main gpu') # 记录日志,表示完成数据映射到主 GPU
with torch.no_grad(): # 使用无梯度的上下文环境进行计算
for idx1, (t_mask, t_feat) in enumerate(zip(batch_t_mask, batch_t_feat)): # 遍历文本特征和掩码的小批次
each_row = [] # 创建一个空列表,用于存储每行的结果
for idx2, (v_mask, v_feat) in enumerate(zip(batch_v_mask, batch_v_feat)): # 遍历视频特征和掩码的小批次
# 计算文本特征和视频特征之间的相似度得分
b1b2_logits, *_tmp = model.get_similarity_logits(t_feat, v_feat, t_mask, v_mask)
# 将相似度得分转移到 CPU 上,并转换为 NumPy 数组
b1b2_logits = b1b2_logits.cpu().detach().numpy()
each_row.append(b1b2_logits) # 将得到的相似度得分添加到每行的结果中
# 将每个批次计算的相似度得分按照批次连接起来(水平连接)
each_row = np.concatenate(tuple(each_row), axis=-1)
sim_matrix.append(each_row) # 将每行的结果添加到相似度矩阵列表中
return sim_matrix # 返回计算得到的相似度矩阵
同时,get_similarity_logits()在CLIP4Clip中的调用位置:
def _run_on_single_gpu(model, batch_list_t, batch_list_v, batch_sequence_output_list, batch_visual_output_list):
sim_matrix = [] # 创建一个空列表,用于存储相似度矩阵的结果
for idx1, b1 in enumerate(batch_list_t): # 遍历文本特征列表
input_mask, segment_ids, *_tmp = b1 # 解包文本特征列表的元素
sequence_output = batch_sequence_output_list[idx1] # 获取对应序列输出列表的元素
each_row = [] # 创建一个空列表,用于存储每行的结果
for idx2, b2 in enumerate(batch_list_v): # 遍历视频特征列表
video_mask, *_tmp = b2 # 解包视频特征列表的元素
visual_output = batch_visual_output_list[idx2] # 获取对应视觉输出列表的元素
# 计算文本特征和视频特征之间的相似度得分
b1b2_logits, *_tmp = model.get_similarity_logits(sequence_output, visual_output, input_mask, video_mask,
loose_type=model.loose_type)
# 将相似度得分转移到 CPU 上,并转换为 NumPy 数组
b1b2_logits = b1b2_logits.cpu().detach().numpy()
each_row.append(b1b2_logits) # 将得到的相似度得分添加到每行的结果中
each_row = np.concatenate(tuple(each_row), axis=-1) # 将每个批次计算的相似度得分按照批次连接起来(水平连接)
sim_matrix.append(each_row) # 将每行的结果添加到相似度矩阵列表中
return sim_matrix # 返回计算得到的相似度矩阵
发现:
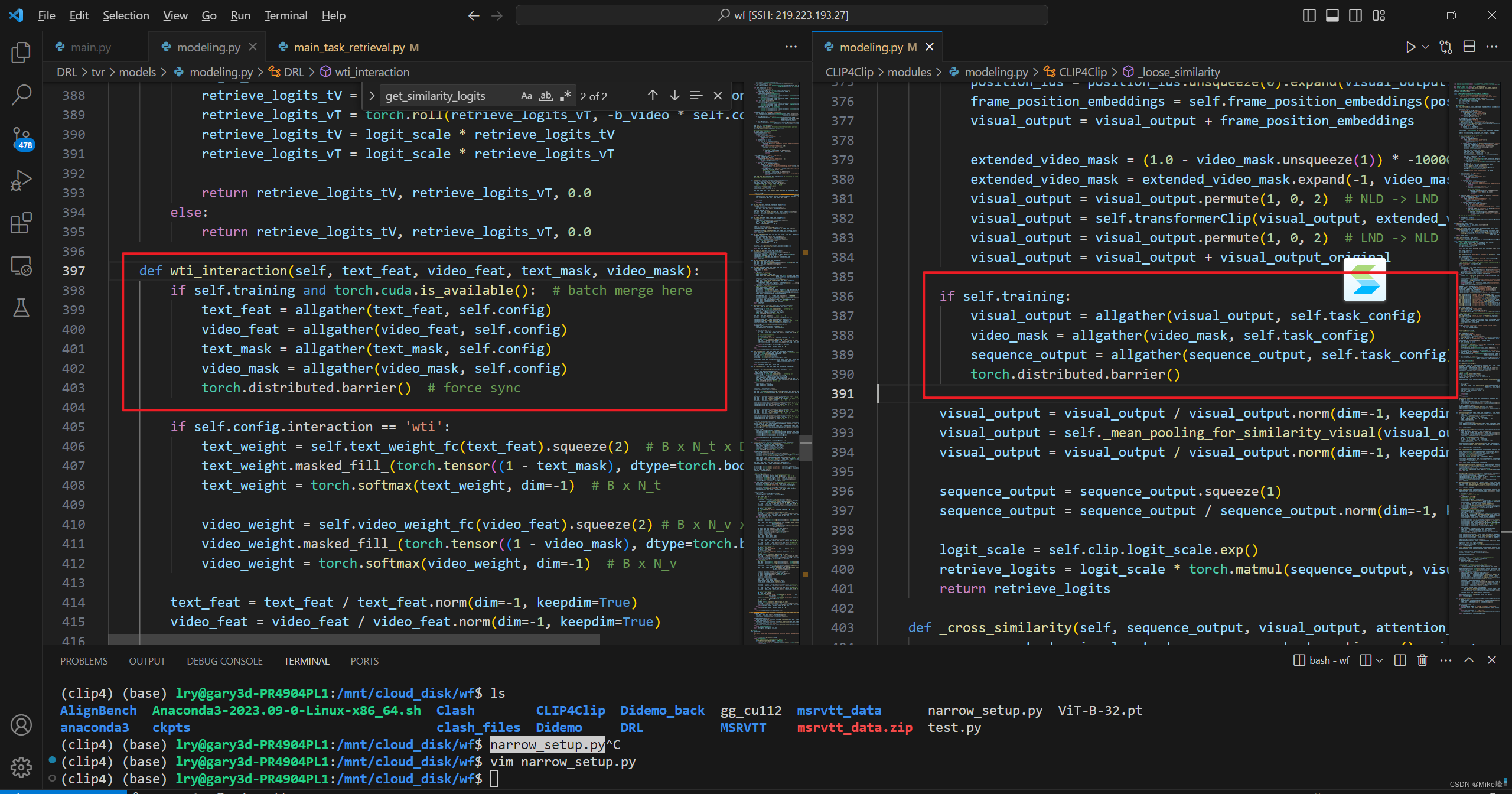
通过下图发现wti_interaction和_loose_similarity这两个函数调用都是在计算retrieve_logits
现在的工作是将wti_interaction的计算retrieval logits的步骤加入到_loose_similarity中
其实这个wti_interaction中的步骤就是上面的算法流程图的步骤
阅读CLIP4Clip代码:
发现有几个Encoder:CLIP Encoder以及Cross Encoder以及Transformer Encoder
cross encoder一般表示两个内容的相关程度
forward(): 模型的前向传播过程,在训练模式下计算损失值以进行模型训练,而在评估模式下则不返回任何损失。
感觉有点乱,因为代码中很少有注释,变量名还不是很有代表性(比如b、bs等等)
直接尝试以下移植过去怎么样。
发现CLIP4Clip和DRL的modeling.py都有以下的同步代码:
if self.training and torch.cuda.is_available(): # batch merge here
text_feat = allgather(text_feat, self.config)
video_feat = allgather(video_feat, self.config)
video_mask = allgather(video_mask, self.config)
torch.distributed.barrier() # force sync
可以从这个为出发点,同步这两个代码的相同部分。
看了半天,对于二者来说,都是类似的过程:
最重要的其实是突破口在于forward函数
forward函数调用get_similarity_logits,而DRL中的get_similarity_logits中则调用了wti_interaction
CLIP4Clip中以下的计算output的代码应该对应于DRL中计算feature的代码:
sequenceDiagram_output, visual_output = self.get_sequence_visual_output(input_ids, token_type_ids, attention_mask, video, video_mask, shaped=True, video_frame=video_frame)(CLIP4Clip)
text_feat, video_feat = self.get_text_video_feat(text_ids, text_mask, video, video_mask, shaped=True)(DRL)
第一处最大的区别就是get_similarity_logits这个函数的输出不一样:
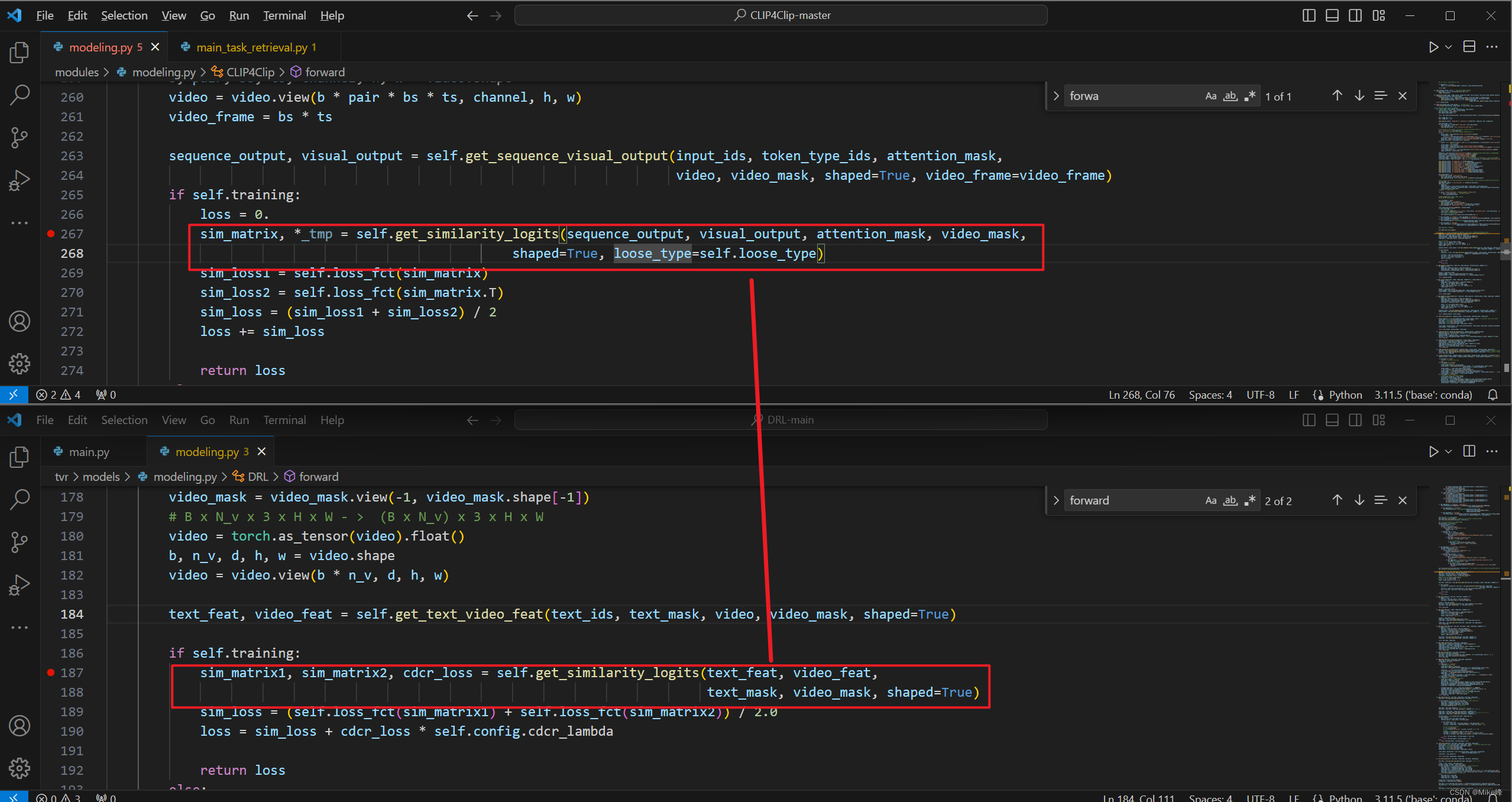
进入到具体的函数中发现确实是不一样:
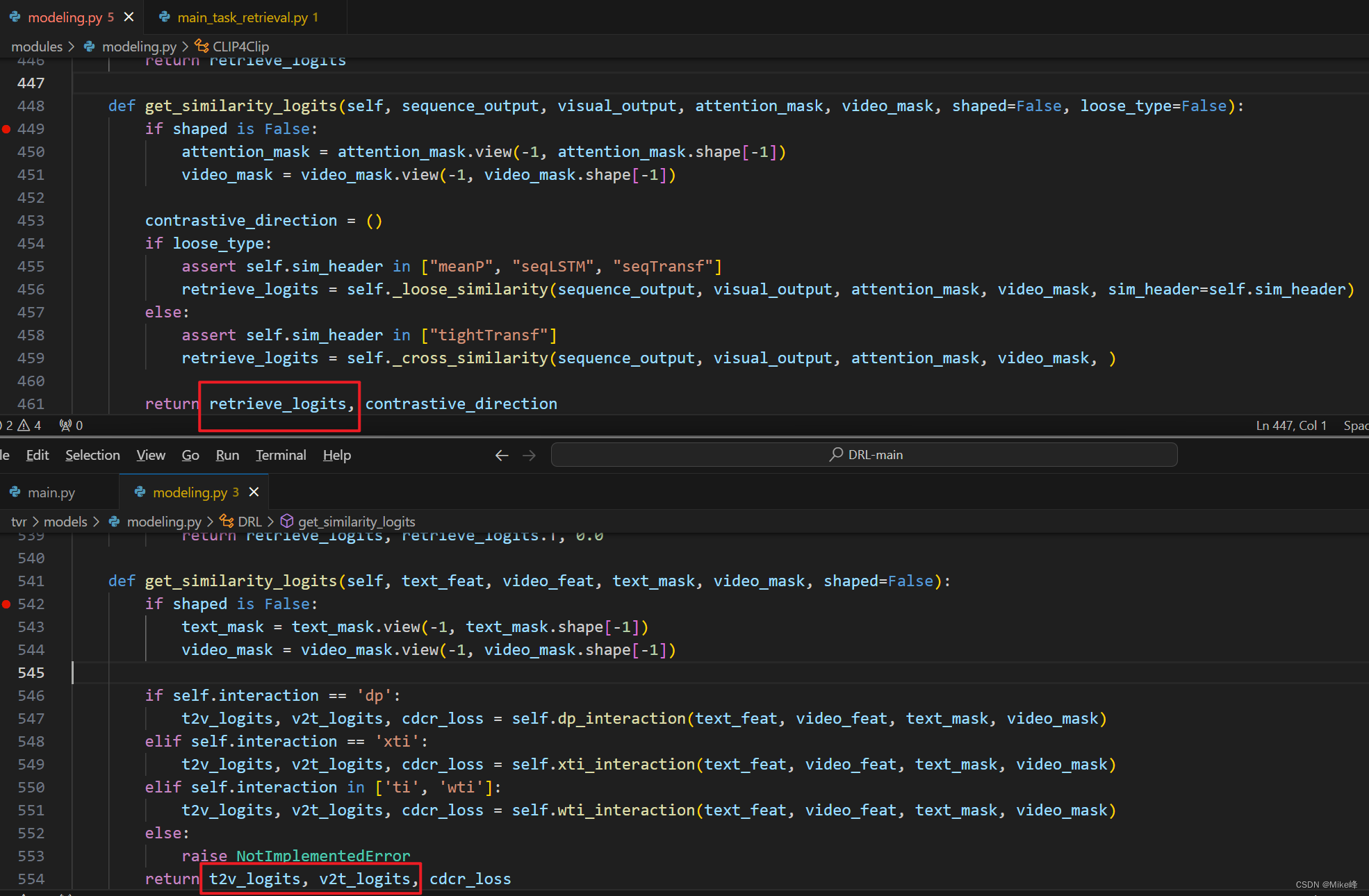
发现sequence_output和text_feature是一样的,visual_output和video_feature是一样的:
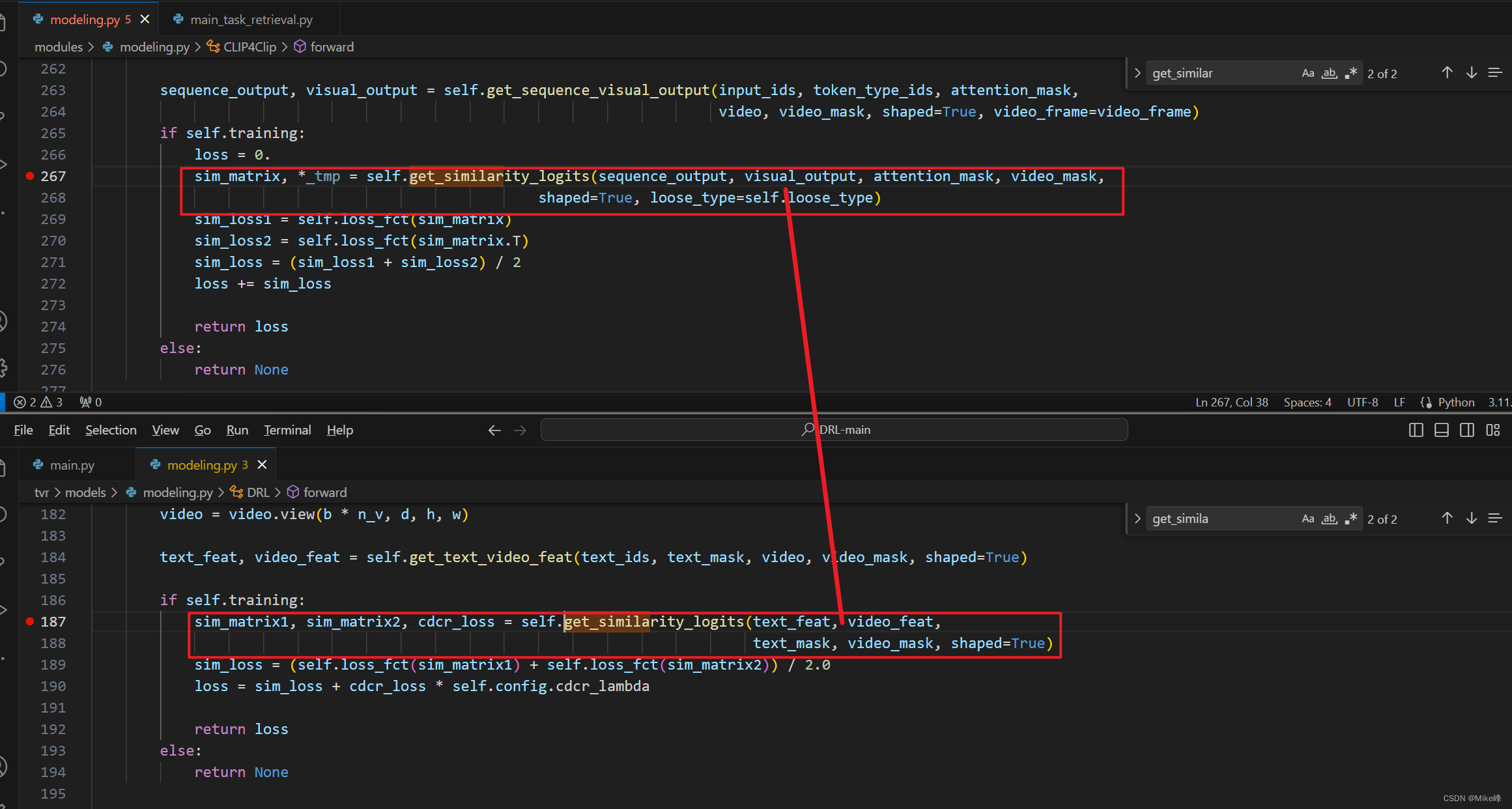
之后计算loss的过程也都大同小异:
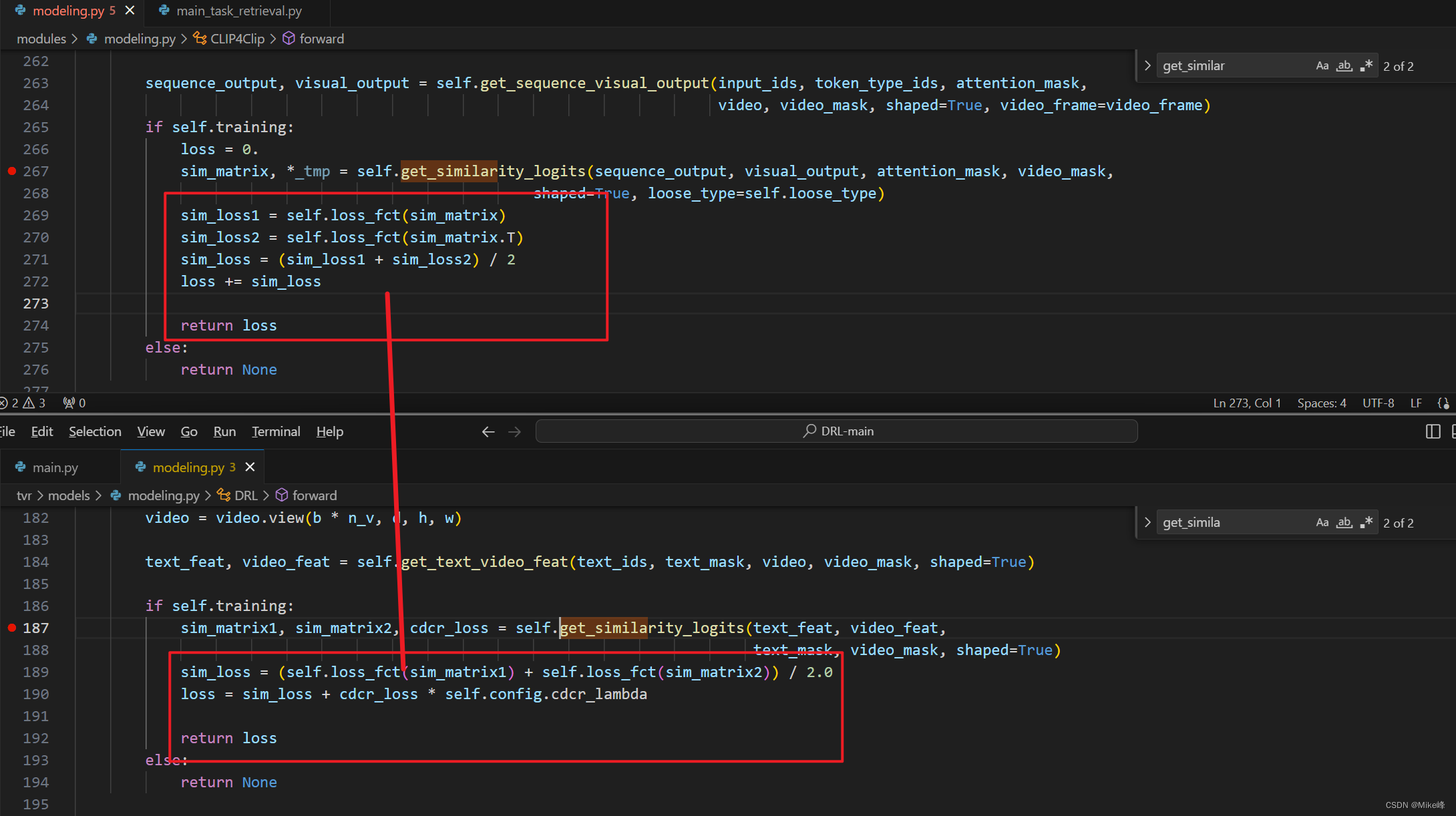
进入到get_similarity_logits函数之后,发现里面的区别在于_loose_similarity和wti_interaction
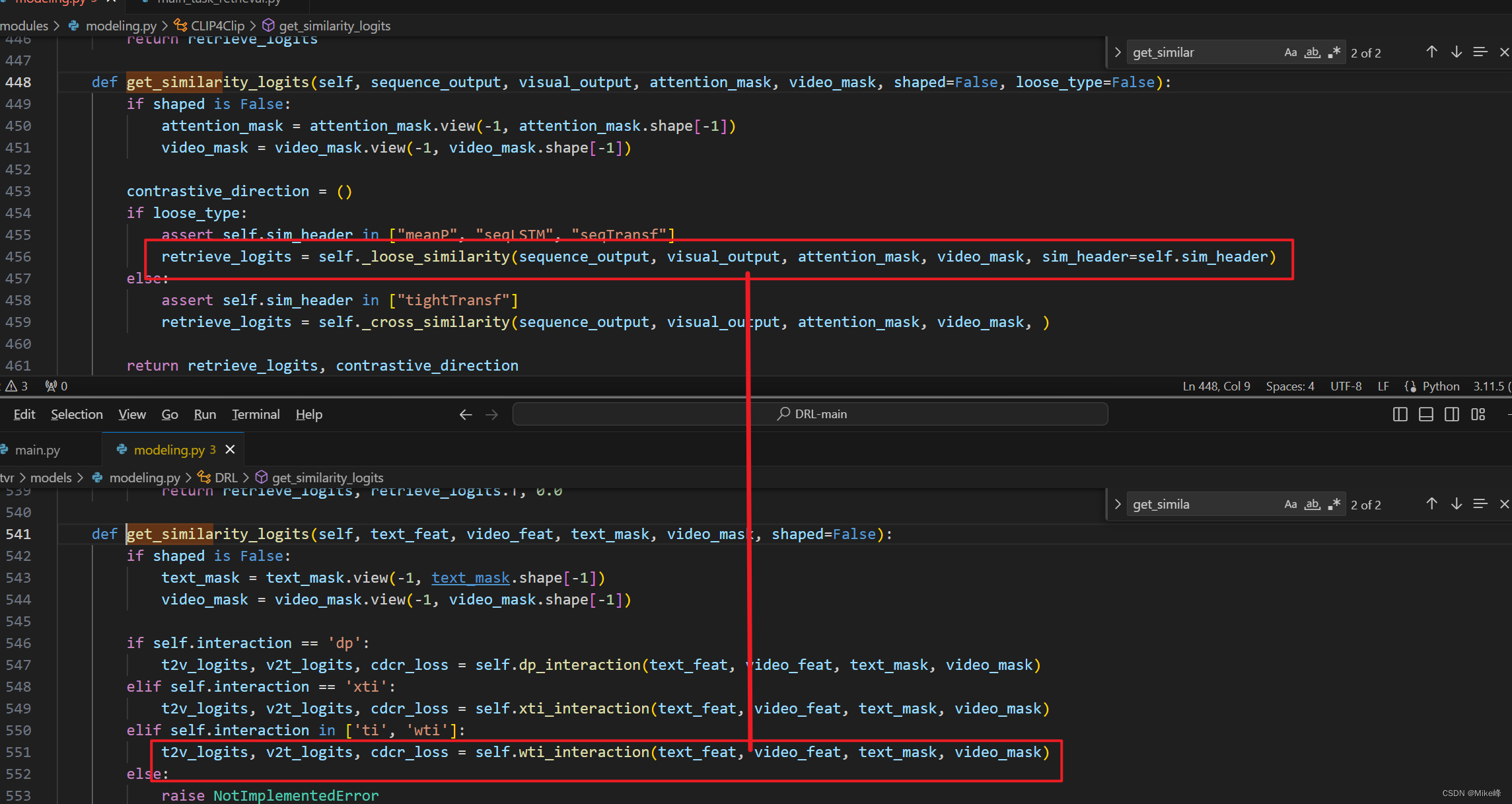
分别看一下loose_similarity以及wti_interaction的两个代码区别:
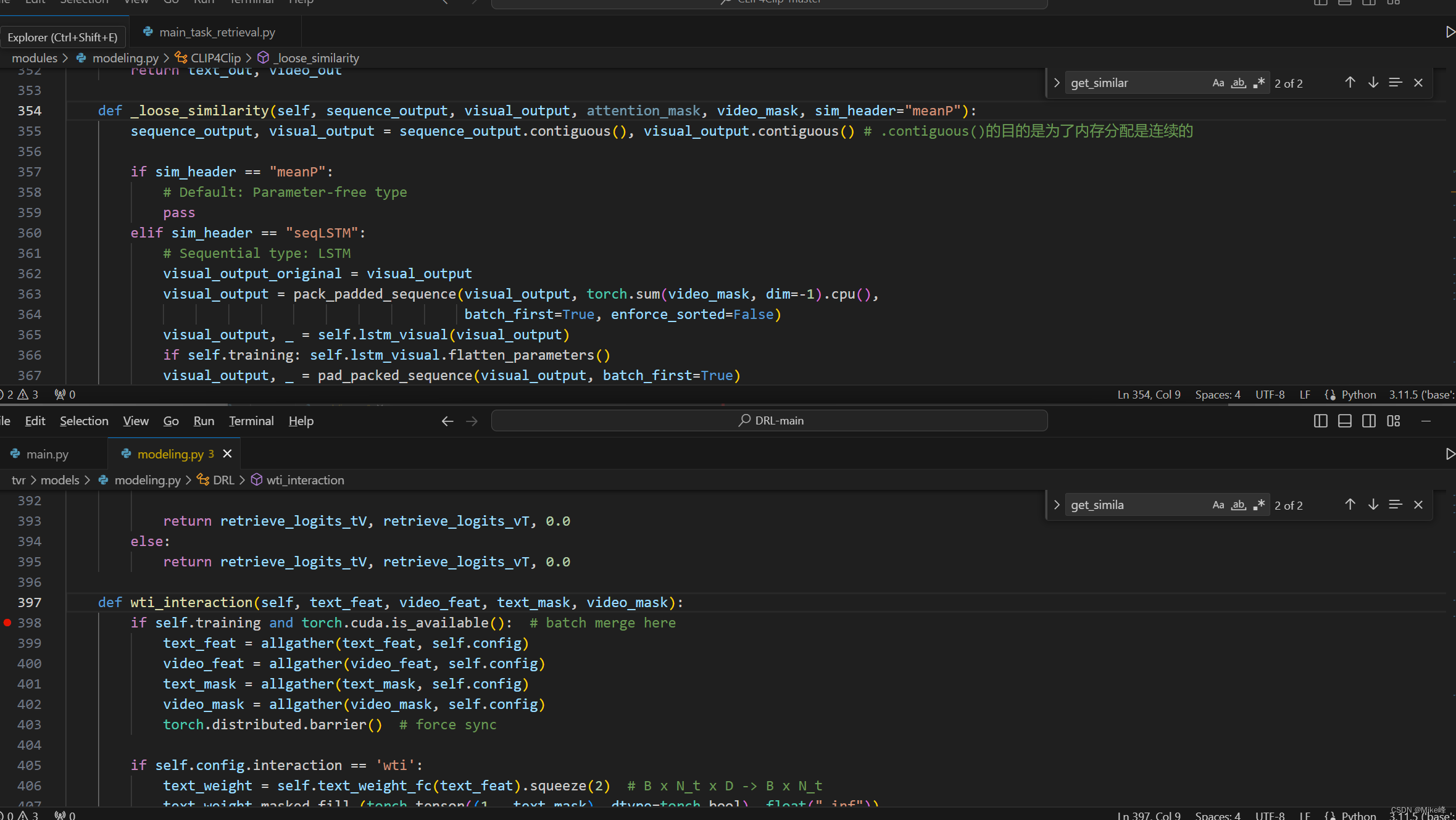
两者的输入应该是差不多的,都是两个模态的特征以及掩码mask
mean pooling的选项中,有关于其他选项的一些处理都被略过了。
首先二者都是先进行了一次同步操作

后面这块除了加入了平均池化之外,剩余的内容都是差不多的
运行DRL,发现它的读取json文件的标签出错了,因此报错了:
Traceback (most recent call last):
File "/mnt/cloud_disk/fw/DRL/main.py", line 552, in <module>
main()
File "/mnt/cloud_disk/fw/DRL/main.py", line 496, in main
test_dataloader, val_dataloader, train_dataloader, train_sampler = build_dataloader(args)
File "/mnt/cloud_disk/fw/DRL/main.py", line 166, in build_dataloader
train_dataloader, train_length, train_sampler = DATALOADER_DICT[args.datatype]["train"](args, tokenizer)
File "/mnt/cloud_disk/fw/DRL/tvr/dataloaders/data_dataloaders.py", line 7, in dataloader_msrvtt_train
msrvtt_dataset = MSRVTTDataset(
File "/mnt/cloud_disk/fw/DRL/tvr/dataloaders/dataloader_msrvtt_retrieval.py", line 19, in __init__
super(MSRVTTDataset, self).__init__(subset, anno_path, video_path, tokenizer, max_words,
File "/mnt/cloud_disk/fw/DRL/tvr/dataloaders/dataloader_retrieval.py", line 45, in __init__
self.video_dict, self.sentences_dict = self._get_anns(self.subset)
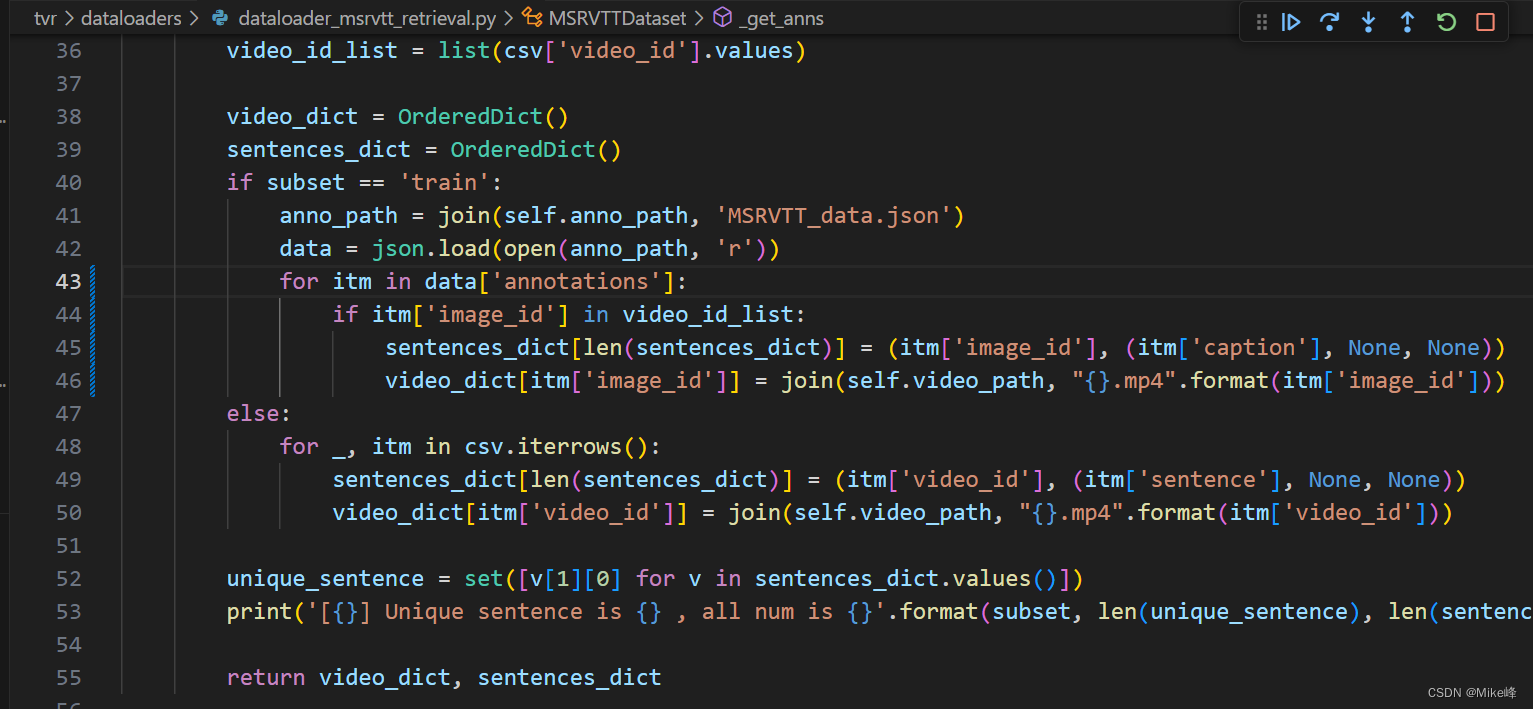
File "/mnt/cloud_disk/fw/DRL/tvr/dataloaders/dataloader_msrvtt_retrieval.py", line 43, in _get_anns
for itm in data['sentences']:
KeyError: 'sentences'
发现是json读取的时候标签中并没有sentences这个标签
发现这个json文件中的标签如下:
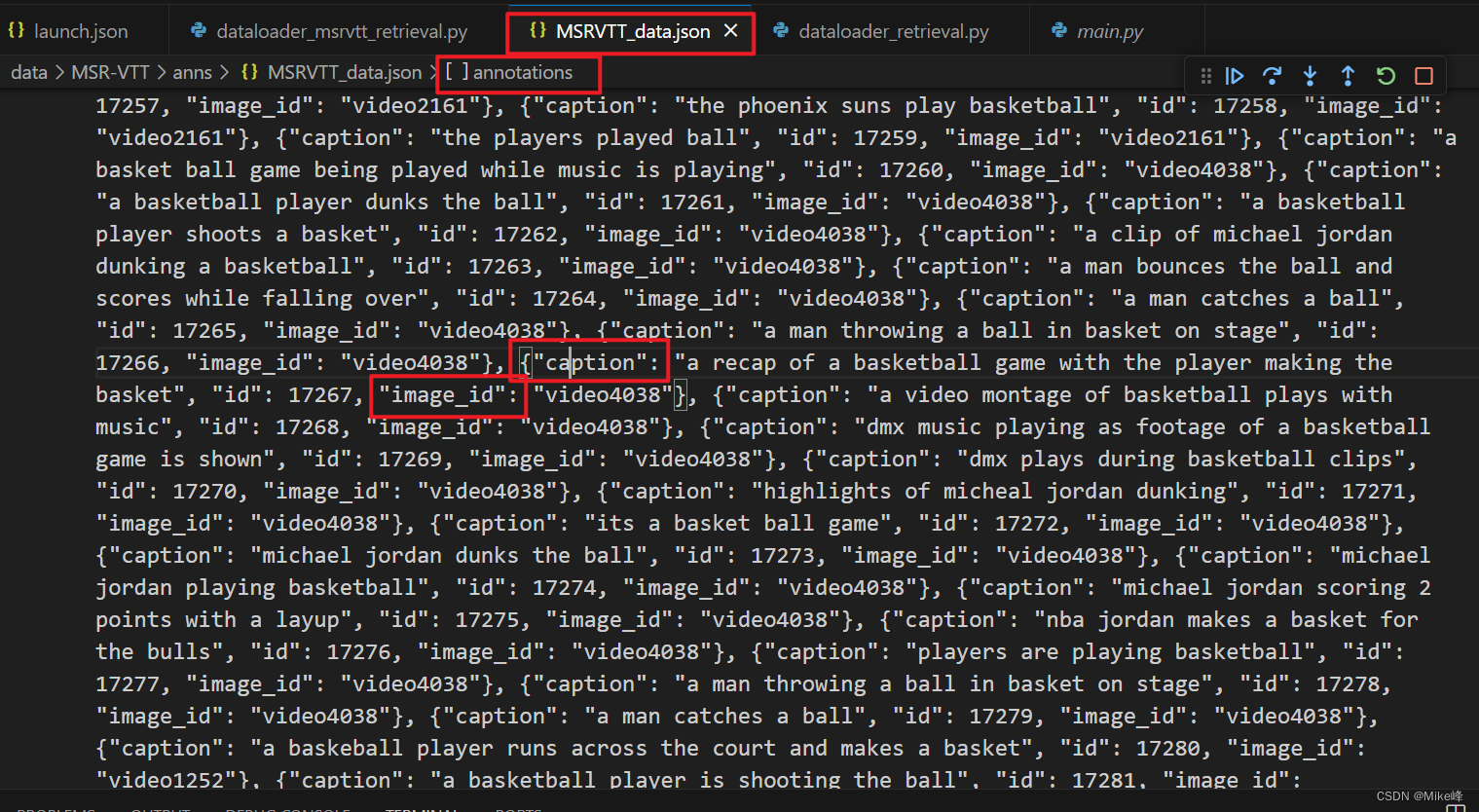
是data[‘annotations’]中的标签data[‘annotations’][‘caption’]以及[‘image_id’]
修改后如下:
重新安装numpy版本,发现以下bug:
(drl) lry@v100s003:/mnt/cloud_disk/fw/anaconda3/envs/drl/lib/python3.9/site-packages$ rm -r '~umpy.libs'
rm: cannot remove '~umpy.libs/.nfs000000008678fc7a000000d1': Device or resource busy
rm: cannot remove '~umpy.libs/.nfs000000008678fc7c000000d2': Device or resource busy
rm: cannot remove '~umpy.libs/.nfs000000008678fc7e000000d3': Device or resource busy
发现应该是我在vscode中的调试进程没有关闭,因此会有临时文件的残余被占用,无法rm;
在停止了调试进程后,就可以删除了。
事实证明DRL的文档写的真的很详细,直接照着做,就可以了(除了那个json标签出错的以及numpy需要更新版本)
之后发现cuda oom,结果是僵尸进程的问题:
fuser -v /dev/nvidia*
上面命令出现nvidia的僵尸进程:
(drl) xxx@v100s003:/xxx/DRL$ fuser -v /dev/nvidia*
USER PID ACCESS COMMAND
/dev/nvidia0: xxx 3551238 F...m python
xxx 3551797 F...m python
xxx 3552245 F...m python
xxx 3554186 F...m python
/dev/nvidia1: xxx 3551238 F...m python
xxx 3551797 F...m python
xxx 3552245 F...m python
xxx 3554186 F...m python
/dev/nvidia2: xxx 3551238 F...m python
xxx 3551797 F...m python
xxx 3552245 F...m python
xxx 3554186 F...m python
/dev/nvidia3: xxx 3551238 F...m python
xxx 3551797 F...m python
xxx 3552245 F...m python
xxx 3554186 F...m python
/dev/nvidia4: xxx 3551238 F.... python
xxx 3551797 F.... python
xxx 3552245 F.... python
xxx 3554186 F.... python
/dev/nvidia5: xxx 3551238 F.... python
xxx 3551797 F.... python
.........
之后运行 kil -9 进程号 进程号 ... 即可
(详细见我的知乎回答:为什么用pytorch cuda,明明显存很够用,却报错out of memory?)
之后就可以查看DRL的tensor的size了:
if self.config.interaction == 'wti':
# print("text_feat",text_feat.size()) # [batch_size(128), 32(max_words), 512]
text_weight = self.text_weight_fc(text_feat).squeeze(2) # B x N_t x D -> B x N_t
# print("text_weight_0",text_weight.size()) # [128, 32]
# print("text_mask",text_mask.size()) # [128, 32]
text_weight.masked_fill_(torch.tensor((1 - text_mask), dtype=torch.bool), float("-inf"))
# print("text_weight_1",text_weight.size()) # [128, 32]
text_weight = torch.softmax(text_weight, dim=-1) # B x N_t
# print("text_weight_2",text_weight.size()) # [128, 32]
# print("video_feat",video_feat.size()) # [128, 12, 512]
video_weight = self.video_weight_fc(video_feat).squeeze(2) # B x N_v x D -> B x N_v
# print("video_weight_0",text_weight.size()) # [128, 32]
# print("video_mask",text_mask.size()) # [128, 32]
video_weight.masked_fill_(torch.tensor((1 - video_mask), dtype=torch.bool), float("-inf"))
# print("video_weight_1",text_weight.size()) # [128, 32]
video_weight = torch.softmax(video_weight, dim=-1) # B x N_v
# print("video_weight_2",text_weight.size()) # [128, 32]
而我们可以借此机会看一下CLIP4Clip的几个Tensor的shape是什么样的
CLIP4Clip的参数使用默认的:
DATA_PATH=[Your MSRVTT data and videos path]
python -m torch.distributed.launch --nproc_per_node=4 \
main_task_retrieval.py --do_train --num_thread_reader=0 \
--epochs=5 --batch_size=128 --n_display=50 \
--train_csv ${DATA_PATH}/MSRVTT_train.9k.csv \
--val_csv ${DATA_PATH}/MSRVTT_JSFUSION_test.csv \
--data_path ${DATA_PATH}/MSRVTT_data.json \
--features_path ${DATA_PATH}/MSRVTT_Videos \
--output_dir ckpts/ckpt_msrvtt_retrieval_looseType \
--lr 1e-4 --max_words 32 --max_frames 12 --batch_size_val 16 \
--datatype msrvtt --expand_msrvtt_sentences \
--feature_framerate 1 --coef_lr 1e-3 \
--freeze_layer_num 0 --slice_framepos 2 \
--loose_type --linear_patch 2d --sim_header meanP \
--pretrained_clip_name ViT-B/32
我们发现video_mask的大小为torch.Size([16, 1, 12]),这个和DRL的有所不同,第一个16应该是batch_size_val那个,而为什么第二个维度是1,第三个维度是12?这个导致和后面的visual_output不兼容?
所以说我们要了解 text_weight_fc 和 video_weight_fc 函数是干什么的
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Zabbix相关问题及答案(2024)
- ubuntu 执行apt-get update报错
- 程序员的海外营收
- Python从入门到网络爬虫(文件I/O详解)
- 【使用python调用ChatGPT接口实现多轮连续对话】
- 线性代数-第五课,第六课,第七课,第八课
- NNDL 循环神经网络-梯度爆炸实验 [HBU]
- SQL基础:表的基本操作
- PythonStudio GUI窗体设计开发文档
- 阿里云Alibaba Cloud Linux 2镜像操作系统版本大全