Redis的概念与常见命令
🌇个人主页:平凡的小苏
📚学习格言:命运给你一个低的起点,是想看你精彩的翻盘,而不是让你自甘堕落,脚下的路虽然难走,但我还能走,比起向阳而生,我更想尝试逆风翻盘。
🛸Redis:Redis
> 家人们更新不易,你们的👍点赞👍和?关注?真的对我真重要,各位路 过的友友麻烦多多点赞关注。 欢迎你们的私信提问,感谢你们的转发! 关注我,关注我,关注我,你们将会看到更多的优质内容!!
一、redis全局命令
redis支持很多种数据结构
整体上来说,redis是键值对结构,Key固定就是字符串,value实际上会有多种类型
1、keys
用来查询当前服务器上匹配到的key
通过一些特殊符号(通配符)来描述key的模样,匹配上述模样的key就能被查询出来
语法:
KEYS pattern
返回所有满?样式(pattern)的 key。?持如下统配样式
h?llo: 匹配 hello , hallo 和 hxllo
h*llo: 匹配 hllo 和 heeeello
h[ae]llo: 匹配 hello 和 hallo 但不匹配 hillo
h[^e]llo :匹配 hallo , hbllo , … 但不匹配 hello
h[a-b]llo :匹配 hallo 和 hbllo,这个是匹配ascii编码的范围
注意事项:
keys时间复杂度为O(N)
所以,在生产环境下,一般会禁止使用keys命令
2、exists
判断某个 key 是否存在。
语法:
EXISTS key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:key 存在的个数。
redis> SET key1 "Hello"
"OK"
redis> EXISTS key1
(integer) 1
redis> EXISTS nosuchkey
(integer) 0
redis> SET key2 "World"
"OK"
redis> EXISTS key1 key2 nosuchkey
(integer) 2
3、del
删除指定的 key。
语法:
DEL key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:删除掉的 key 的个数。
?例:
redis> SET key1 "Hello"
"OK"
redis> SET key2 "World"
"OK"
redis> DEL key1 key2 key3
(integer) 2
4、EXPIRE
为指定的 key 添加秒级的过期时间(Time To Live TTL)
语法:
EXPIRE key seconds
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:1 表?设置成功。0 表?设置失败。
使用场景:如手机验证码,优惠卷(在指定时间有效)
?例:
redis> SET mykey "Hello"
"OK"
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 10
5、TTL
获取指定 key 的过期时间,秒级。
语法:
TTL key
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:剩余过期时间。-1 表?没有关联过期时间,-2 表? key 不存在。
?例:
redis> SET mykey "Hello"
"OK"
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 7
6、redis的过期策略(面试题)
整体策略:定期删除、惰性删除
惰性删除:假设key已经到过期时间了,但是暂时没删它,key还存在。紧接着,后面又一次访问,正好用到这个key,于是这次访问就会让redis服务器触发删除key的操作,同时返回nil
定期删除:使用惰性删除要结合定期删除操作,因为不进行定期删除,有可能在单线程的程序中,访问过多的过期数据导致效率下降
7、定时器
定时器:在某个时间到达之后,执行指定的任务
1.基于优先级队列/堆或者时间轮转(Redis并没有采取这种方案)
8、type
返回key对应的数据类型(value)
此处redis所有的key都是string
key对应的value可能会存在多种练习
语法:
TYPE key
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值: none , string , list , set , zset , hash and stream .。
?例:
redis> SET key1 "value"
"OK"
redis> LPUSH key2 "value"
(integer) 1
redis> SADD key3 "value"
(integer) 1
redis> TYPE key1
"string"
redis> TYPE key2
"list"
redis> TYPE key3
"set"
9、通用命令总结
keys:用来查看匹配规则的key
exists:用来判定指定的key是否存在
del:删除指定的key
expire:给key设置过期时间
ttl:查询key的过期时间
type:查询key对应的value类型
二、redis常见的数据类型
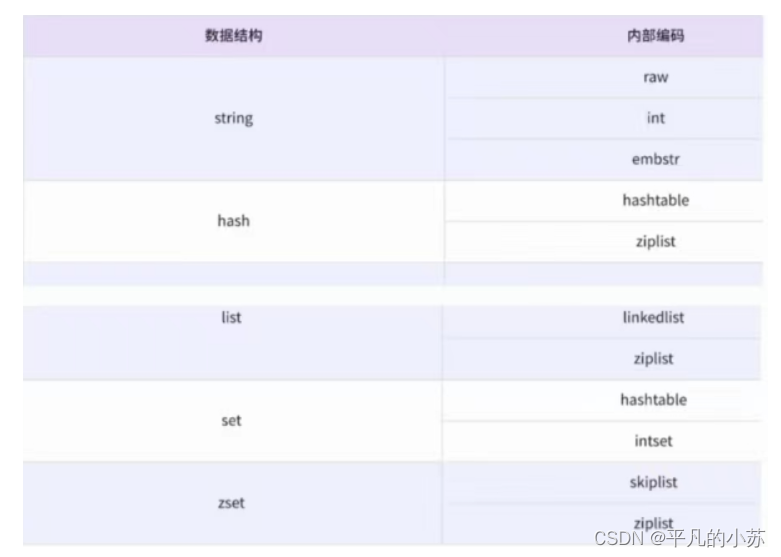
string
raw:底层就是一个char数组
int:当redis是一个整数的时候redis会直接使用int来保存
embstr:针对短字符串进行的特殊优化
hash
hashtable:redis内部最基本的哈希表
ziplist:在哈希中元素比较少是,就会使用压缩列表
list
linkedlist:链表
ziplist:压缩链表
set
hashtable:
intset:集合中存的都是整数
zset
skiplist:跳表
ziplist:
可以看到每种数据结构都有?少两种以上的内部编码实现,例如 list 数据结构包含了 linkedlist 和ziplist 两种内部编码。同时有些内部编码,例如 ziplist,可以作为多种数据结构的内部实现,可以通过 object encoding 命令查询内部编码:
三、单线程架构
现在开启了三个 redis-cli 客?端同时执?命令。
客?端 1 设置?个字符串键值对:
1 127.0.0.1:6379> set hello world
客?端 2 对 counter 做?增操作:
1 127.0.0.1:6379> incr counter
客?端 3 对 counter 做?增操作:
1 127.0.0.1:6379> incr counter
我们已经知道从客?端发送的命令经历了:发送命令、执?命令、返回结果三个阶段,其中我们重点关注第 2 步。我们所谓的 Redis 是采?单线程模型执?命令的是指:虽然三个客?端看起来是同时要求 Redis 去执?命令的,但微观?度,这些命令还是采?线性?式去执?的,只是原则上命令的执?顺序是不确定的,但?定不会有两条命令被同步执?.
1、为什么redis是单线程还这么快
a. 纯内存访问。Redis 将所有数据放在内存中,内存的响应时??约为 100 纳秒,这是 Redis 达到每秒万级别访问的重要基础。
b. ?阻塞 IO。Redis 使? epoll 作为 I/O 多路复?技术的实现,再加上 Redis ??的事件处理模型将 epoll 中的连接、读写、关闭都转换为事件,不在?络 I/O 上浪费过多的时间,如图 2-6 所?。
c. 单线程避免了线程切换和竞态产?的消耗。单线程可以简化数据结构和算法的实现,让程序模型更简单;其次多线程避免了在线程竞争同?份共享数据时带来的切换和等待消耗。
四、string类型
1、SET
将 string 类型的 value 设置到 key 中。如果 key 之前存在,则覆盖,?论原来的数据类型是什么。之前关于此 key 的 TTL 也全部失效。
语法:
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]
命令有效版本:1.0.0 之后
时间复杂度:O(1)
选项:
SET 命令?持多种选项来影响它的?为:
? EX seconds?使?秒作为单位设置 key 的过期时间。
? PX milliseconds?使?毫秒作为单位设置 key 的过期时间。
? NX ?只在 key 不存在时才进?设置,即如果 key 之前已经存在,设置不执?。
? XX ?只在 key 存在时才进?设置,即如果 key 之前不存在,设置不执?。
注意:由于带选项的 SET 命令可以被 SETNX 、 SETEX 、 PSETEX 等命令代替,所以之后的版本中,Redis 可能进?合并。
返回值:
? 如果设置成功,返回 OK。
? 如果由于 SET 指定了 NX 或者 XX 但条件不满?,SET 不会执?,并返回 (nil)。
?例:
redis> EXISTS mykey
(integer) 0
redis> SET mykey "Hello"
OK
redis> GET mykey
"Hello"
redis> SET mykey "World" NX
(nil)
redis> DEL mykey
(integer) 1
redis> EXISTS mykey
(integer) 0
redis> SET mykey "World" XX
(nil)
redis> GET mykey
(nil)
redis> SET mykey "World" NX
OK
redis> GET mykey
"World"
redis> SET mykey "Will expire in 10s" EX 10
OK
redis> GET mykey
"Will expire in 10s"
redis> GET mykey # 10秒之后
(nil)
2、GET
获取 key 对应的 value。如果 key 不存在,返回 nil。如果 value 的数据类型不是 string,会报错。
语法:
GET key
返回值:key 对应的 value,或者 nil 当 key 不存在。
?例:
redis> GET nonexisting
(nil)
redis> SET mykey "Hello"
"OK"
redis> GET mykey
"Hello"
redis> DEL mykey
(integer) 1
redis> EXISTS mykey
(integer) 0
redis> HSET mykey name Bob
(integer) 1
redis> GET mykey
(error) WRONGTYPE Operation against a key holding the wrong kind of value
3、MGET
?次性获取多个 key 的值。如果对应的 key 不存在或者对应的数据类型不是 string,返回 nil。
语法:
MGET key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(N) N 是 key 数量
返回值:对应 value 的列表
4、MSET
?次性设置多个 key 的值。
语法:
MSET key value [key value ...]
命令有效版本:1.0.1 之后
时间复杂度:O(N) N 是 key 数量
返回值:永远是 OK
5、计数命令
5.1、INCR
将 key 对应的 string 表?的数字加?。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是?个整型或者范围超过了 64 位有符号整型,则报错。
语法:
INCR key
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:integer 类型的加完后的数值。
5.2、INCRBY
将 key 对应的 string 表?的数字加上对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是?个整型或者范围超过了 64 位有符号整型,则报错。
语法:
INCRBY key decrement
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:integer 类型的加完后的数值。
5.3、DECR
将 key 对应的 string 表?的数字减?。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是?个整型或者范围超过了 64 位有符号整型,则报错。
语法:
DECR key
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:integer 类型的减完后的数值。
5.4、DECYBY
将 key 对应的 string 表?的数字减去对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是?个整型或者范围超过了 64 位有符号整型,则报错。
语法:
DECRBY key decrement
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:integer 类型的减完后的数值。
5.5、INCRBYFLOAT
将 key 对应的 string 表?的浮点数加上对应的值。如果对应的值是负数,则视为减去对应的值。如果key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的不是 string,或者不是?个浮点数,则报错。允许采?科学计数法表?浮点数。
语法:
INCRBYFLOAT key increment
命令有效版本:2.6.0 之后
时间复杂度:O(1)
返回值:加/减完后的数值。
6、其他命令
6.1、APPEND
如果 key 已经存在并且是?个 string,命令会将 value 追加到原有 string 的后边。如果 key 不存在,则效果等同于 SET 命令。
语法:
APPEND KEY VALUE
命令有效版本:2.0.0 之后
时间复杂度:O(1). 追加的字符串?般?度较短, 可以视为 O(1).
返回值:追加完成之后 string 的?度。
6.2、GETRANGE
返回 key 对应的 string 的?串,由 start 和 end 确定(左闭右闭)。可以使?负数表?倒数。-1 代表倒数第?个字符,-2 代表倒数第?个,其他的与此类似。超过范围的偏移量会根据 string 的?度调整成正确的值。
语法:
GETRANGE key start end
命令有效版本:2.4.0 之后
时间复杂度:O(N). N 为 [start, end] 区间的?度. 由于 string 通常?较短, 可以视为是 O(1)
返回值:string 类型的?串
6.3、SETRANGE
覆盖字符串的?部分,从指定的偏移开始。
语法:
SETRANGE key offset value
命令有效版本:2.2.0 之后
时间复杂度:O(N), N 为 value 的?度. 由于?般给的 value ?较短, 通常视为 O(1).
返回值:替换后的 string 的?度。
6.4、STRLEN
获取 key 对应的 string 的?度。当 key 存放的类似不是 string 时,报错。
语法:
STRLEN key
命令有效版本:2.2.0 之后
时间复杂度:O(1)
返回值:string 的?度。或者当 key 不存在时,返回 0。
7、string内部编码
字符串类型的内部编码有 3 种:
? int:8 个字节的?整型。
? embstr:?于等于 39 个字节的字符串。
? raw:?于 39 个字节的字符串。
Redis 会根据当前值的类型和?度动态决定使?哪种内部编码实现。
8、典型使用场景
8.1、缓存功能
其中 Redis 作为缓冲层,MySQL 作为存储层,绝?部分请求的数据都是从 Redis 中获取。
由于 Redis 具有?撑?并发的特性,所以缓存通常能起到加速读写和降低后端压?的作?。
我们可以将比较频繁访问的数据添加到redis。
当redis的key不断加入满了怎么办?
我们可以给key设置过期时间,如果到时间就给他删除,redis内部还有自己的淘汰策略
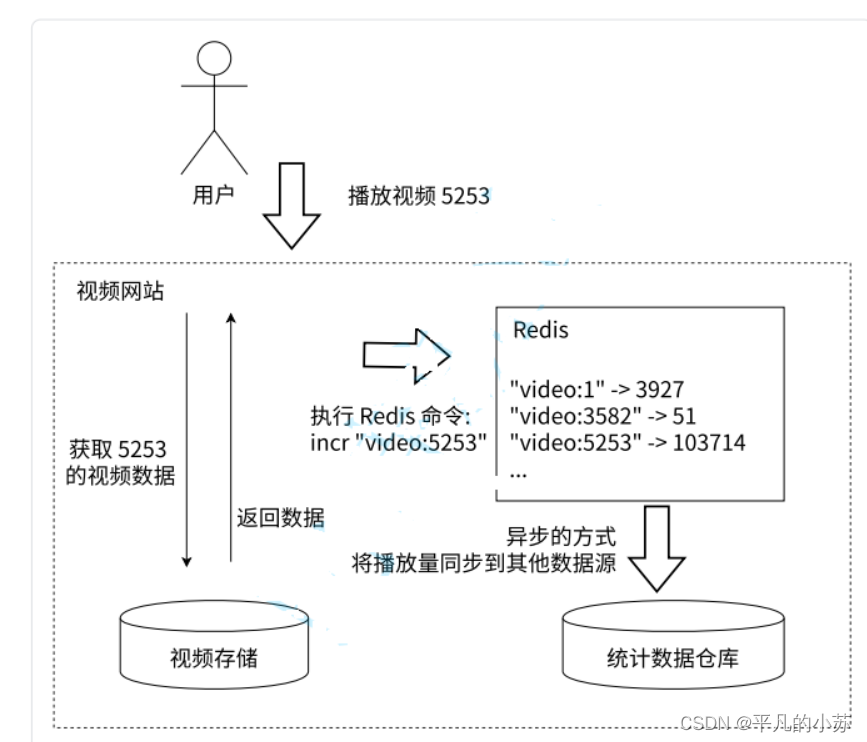
8.2、计数功能
Redis 作为计数的基础?具,它可以实现快速计数、查询缓存的功能,同时数据可以异步处理或者落地到其他数据源。如图 2-11 所?,例如视频?站的视频播放次数可以使?Redis 来完成:??每播放?次视频,相应的视频播放数就会?增 1
8.3、手机验证码
很多应?出于安全考虑,会在每次进?登录时,让??输??机号并且配合给?机发送验证码,然后让??再次输?收到的验证码并进?验证,从?确定是否是??本?。为了短信接?不会频繁访问,会限制??每分钟获取验证码的频率,例如?分钟不能超过 5 次,
此功能可以?以下伪代码说明基本实现思路:
String 发送验证码(phoneNumber) {
key = "shortMsg:limit:" + phoneNumber;
// 设置过期时间为 1 分钟(60 秒)
// 使? NX,只在不存在 key 时才能设置成功
bool r = Redis 执?命令:set key 1 ex 60 nx
if (r == false) {
// 说明之前设置过该?机的验证码了
long c = Redis 执?命令:incr key
if (c > 5) {
// 说明超过了?分钟 5 次的限制了
// 限制发送
return null;
}
}
// 说明要么之前没有设置过?机的验证码;要么次数没有超过 5 次
String validationCode = ?成随机的 6 位数的验证码();
validationKey = "validation:" + phoneNumber;
// 验证码 5 分钟(300 秒)内有效
Redis 执?命令:set validationKey validationCode ex 300;
// 返回验证码,随后通过?机短信发送给??
return validationCode ;
}
// 验证??输?的验证码是否正确
bool 验证验证码(phoneNumber, validationCode) {
validationKey = "validation:" + phoneNumber;
String value = Redis 执?命令:get validationKey;
if (value == null) {
// 说明没有这个?机的验证码记录,验证失败
return false;
}
if (value == validationCode) {
return true;
} else {
return false;
}
}
五、Hash哈希
哈希类型中的映射关系通常称为 field-value,?于区分 Redis 整体的键值对(key-value),注意这?的 value 是指 field 对应的值,不是键(key)对应的值,请注意 value 在不同上下?的作?。
1、HSET
设置 hash 中指定的字段(field)的值(value)。
语法:
HSET key field value [field value ...]
命令有效版本:2.0.0 之后
时间复杂度:插??组 field 为 O(1), 插? N 组 field 为 O(N)
返回值:添加的字段的个数。
?例:
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HGET myhash field1
"Hello"
2、HGET
获取 hash 中指定字段的值。
语法:
HGET key field
命令有效版本:2.0.0 之后
时间复杂度:O(1)
返回值:字段对应的值或者 nil。
3、HEXISTS
判断 hash 中是否有指定的字段。
语法:
HEXISTS key field
命令有效版本:2.0.0 之后
时间复杂度:O(1)
返回值:1 表?存在,0 表?不存在。
4、HDEL
删除 hash 中指定的字段。
语法:
HDEL key field [field ...]
命令有效版本:2.0.0 之后
时间复杂度:删除?个元素为 O(1). 删除 N 个元素为 O(N).
返回值:本次操作删除的字段个数
5、HKEYS
获取 hash 中的所有字段。
语法:
HKEYS key
这个操作,先根据key找到对应的hash(1),然后再遍历hash
6、HVALS
获取 hash 中的所有的值。
语法:
HVALS key
7、HGETALL
获取 hash 中的所有字段以及对应的值。
语法:
HGETALL key
命令有效版本:2.0.0 之后
时间复杂度:O(N), N 为 field 的个数.
返回值:字段和对应的值。
8、HMGET
?次获取 hash 中多个字段的值
语法:
HMGET key field [field ...]
命令有效版本:2.0.0 之后
时间复杂度:只查询?个元素为 O(1), 查询多个元素为 O(N), N 为查询元素个数.
返回值:字段对应的值或者 nil。
9、HLEN
获取 hash 中的所有字段的个数。
语法:
HLEN key
命令有效版本:2.0.0 之后
时间复杂度:O(1)
返回值:字段个数。
10、HSETNX
在字段不存在的情况下,设置 hash 中的字段和值。
语法:
HSETNX key field value
命令有效版本:2.0.0 之后
时间复杂度:O(1)
返回值:1 表?设置成功,0 表?失败。
?例:
redis> HSETNX myhash field "Hello"
(integer) 1
redis> HSETNX myhash field "World"
(integer) 0
redis> HGET myhash field
"Hello"
11、HINCRBY
将 hash 中字段对应的数值添加指定的值。
语法:
HINCRBY key field increment
命令有效版本:2.0.0 之后
时间复杂度:O(1)
返回值:该字段变化之后的值。
12、HINCRBYFLOAT
HINCRBY 的浮点数版本。
语法:
HINCRBYFLOAT key field increment
命令有效版本:2.6.0 之后
时间复杂度:O(1)
返回值:该字段变化之后的值。
六、List列表
list的特点
- 第?、列表中的元素是有序的,这意味着可以通过索引下标获取某个元素或者某个范围的元素列表,例如要获取图 2-20 的第 5 个元素,可以执? lindex user:1:messages 4 或者倒数第 1 个元素,lindex
user:1:messages -1 就可以得到元素 e。
-
第?、区分获取和删除的区别,例如图 2-20 中的 lrem 1 b 是从列表中把从左数遇到的前 1 个 b 元素删除,这个操作会导致列表的?度从 5 变成 4;但是执? lindex 4 只会获取元素,但列表?度是不会变化的。
-
第三、列表中的元素是允许重复的,例如图 2-21 中的列表中是包含了两个 a 元素的。
1、LPUSH
将?个或者多个元素从左侧放?(头插)到 list 中。
语法:
LPUSH key element [element ...]
命令有效版本:1.0.0 之后
时间复杂度:只插??个元素为 O(1), 插?多个元素为 O(N), N 为插?元素个数.
返回值:插?后 list 的?度。
2、LPUSHX
在 key 存在时,将?个或者多个元素从左侧放?(头插)到 list 中。不存在,直接返回
语法:
LPUSHX key element [element ...]
命令有效版本:2.0.0 之后
时间复杂度:只插??个元素为 O(1), 插?多个元素为 O(N), N 为插?元素个数.
返回值:插?后 list 的?度。
3、RPUSH
将?个或者多个元素从右侧放?(尾插)到 list 中。
语法:
RPUSH key element [element ...]
命令有效版本:1.0.0 之后
时间复杂度:只插??个元素为 O(1), 插?多个元素为 O(N), N 为插?元素个数.
返回值:插?后 list 的?度。
4、RPUSHX
在 key 存在时,将?个或者多个元素从右侧放?(尾插)到 list 中。
语法:
RPUSHX key element [element ...]
命令有效版本:2.0.0 之后
时间复杂度:只插??个元素为 O(1), 插?多个元素为 O(N), N 为插?元素个数.
返回值:插?后 list 的?度。
5、LRANGE
获取从 start 到 end 区间的所有元素,左闭右闭。
语法:
LRANGE key start stop
命令有效版本:1.0.0 之后
时间复杂度:O(N)
返回值:指定区间的元素。
6、LPOP
从 list 左侧取出元素(即头删)。
语法:
LPOP key
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:取出的元素或者 nil
7、RPOP
从 list 右侧取出元素(即尾删)。
语法:
RPOP key
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:取出的元素或者 nil。
8、LINDEX
获取从左数第 index 位置的元素。
语法:
LINDEX key index
命令有效版本:1.0.0 之后
时间复杂度:O(N)
返回值:取出的元素或者 nil
9、LINSERT
在特定位置插?元素。
语法:
LINSERT key <BEFORE | AFTER> pivot element
命令有效版本:2.2.0 之后
时间复杂度:O(N)
返回值:插?后的 list ?度。
?例:
redis> RPUSH mylist "Hello"
(integer) 1
redis> RPUSH mylist "World"
(integer) 2
redis> LINSERT mylist BEFORE "World" "There"
(integer) 3
redis> LRANGE mylist 0 -1
1) "Hello"
2) "There"
3) "World"
10、LLEN
获取 list ?度。
语法:
LLEN key
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:list 的?度。
11、LREM
语法:
LREM key count element //count表示删除几个,count为0就删除所有等于element的元素
count > 0:删除等同于从头到尾移动的元素。elementcount < 0:删除等同于从尾巴移动到头部的元素。elementcount = 0:删除所有等于 的元素。element
12、LTRIM
语法:
LTRIM key start stop
修剪现有列表,使其仅包含指定的范围 指定的元素。 两者都是从零开始的索引.
超出范围的索引不会产生错误:如果大于 列表的末尾结果将是一个空列表( 原因被删除)。 如果大于列表的末尾,Redis 会将其视为最后一个 元素。
13、LSET
语法:
LSET key index element
- 将下标index位置的元素进行修改
14、BLPOP
LPOP 的阻塞版本。
语法:
BLPOP key [key ...] timeout
如果list不为空,阻塞和不阻塞版本都一样,如果为空,则就需要阻塞等待。并且还可以设置阻塞时间,不让它无休止的阻塞下去(redis6允许设定成小数,redis5中,超时时间,只能是整数)
15、BRPOP
RPOP阻塞版本
语法:
BRPOP key [key ...] timeout
16、list内部编码
? ziplist(压缩列表):当列表的元素个数?于 list-max-ziplist-entries 配置(默认 512 个),同时列表中每个元素的?度都?于 list-max-ziplist-value 配置(默认 64 字节)时,Redis 会选?ziplist 来作为列表的内部编码实现来减少内存消耗。
? linkedlist(链表):当列表类型?法满? ziplist 的条件时,Redis 会使? linkedlist 作为列表的内
部实现。
七、Set集合
集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中 1)元素之间是?序的 2)元素不允许重复,如图 2-24 所?。?个集合中最多可以存储 个元素。Redis 除了?持集合内的增删查改操作,同时还?持多个集合取交集、并集、差集,合理地使?好集合类型,能在实际开发中解决很多问题。
1、SADD
将?个或者多个元素添加到 set 中。注意,重复的元素?法添加到 set 中。
语法:
SADD key member [member ...]
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:本次添加成功的元素个数
2、SMEMBERS
获取?个 set 中的所有元素,注意,元素间的顺序是?序的。
语法:
SMEMBERS key
命令有效版本:1.0.0 之后
时间复杂度:O(N)
返回值:所有元素的列表。
3、SISMEMBER
判断?个元素在不在 set 中。
语法:
SISMEMBER key member
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:1 表?元素在 set 中。0 表?元素不在 set 中或者 key 不存在。
4、SCARD
获取?个 set 的基数(cardinality),即 set 中的元素个数。
语法:
SCARD key
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:set 内的元素个数。
5、SPOP
从 set 中删除并返回?个或者多个元素。注意,由于 set 内的元素是?序的,所以取出哪个元素实际是
未定义?为,即可以看作随机的
语法:
SPOP key [count]
命令有效版本:1.0.0 之后
时间复杂度:O(N), n 是 count
返回值:取出的元素。
?例:
redis> SADD myset "one"
(integer) 1
redis> SADD myset "two"
(integer) 1
redis> SADD myset "three"
(integer) 1
redis> SPOP myset
"one"
redis> SMEMBERS myset
1) "three"
2) "two"
redis> SADD myset "four"
(integer) 1
redis> SADD myset "five"
(integer) 1
redis> SPOP myset 3
1) "three"
2) "four"
3) "two"
redis> SMEMBERS myset
1) "five"
6、SMOVE
将?个元素从源 set 取出并放??标 set 中。
语法:
SMOVE source destination member
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:1 表?移动成功,0 表?失败

7、SREM
将指定的元素从 set 中删除。
语法:
SREM key member [member ...]
命令有效版本:1.0.0 之后
时间复杂度:O(N), N 是要删除的元素个数.
返回值:本次操作删除的元素个数。
8、集合间操作
交集(inter)、并集(union)、差集(diff)
8.1、SINTER
获取给定 set 的交集中的元素。
语法:
SINTER key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(N * M), N 是最?的集合元素个数. M 是最?的集合元素个数.
返回值:交集的元素。
8.2、SINTERSTORE
获取给定 set 的交集中的元素并保存到?标 set 中。
语法:
SINTERSTORE destination key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(N * M), N 是最?的集合元素个数. M 是最?的集合元素个数.
返回值:交集的元素个数。
8.3、SUNION
获取给定 set 的并集中的元素。
语法:
SUNION key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(N), N 给定的所有集合的总的元素个数.
返回值:并集的元素。
8.4、SUNIONSTORE
获取给定 set 的并集中的元素并保存到?标 set 中。
语法:
SUNIONSTORE destination key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(N), N 给定的所有集合的总的元素个数.
返回值:并集的元素个数。
8.5、SDIFF
获取给定 set 的差集中的元素。
语法:
SDIFF key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(N), N 给定的所有集合的总的元素个数.
返回值:差集的元素。
注意:返回的是第一个key的差集元素
8.6、SDIFFSTORE
获取给定 set 的差集中的元素并保存到?标 set 中。
语法:
SDIFFSTORE destination key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(N), N 给定的所有集合的总的元素个数.
返回值:差集的元素个数。
注意:返回的是第一个key的差集元素
9、SET的内部编码
集合类型的内部编码有两种:
? intset(整数集合):当集合中的元素都是整数并且元素的个数?于 set-max-intset-entries 配置(默认 512 个)时,Redis 会选? intset 来作为集合的内部实现,从?减少内存的使?。
? hashtable(哈希表):当集合类型?法满? intset 的条件时,Redis 会使? hashtable 作为集合的内部实现。
八、ZSET有序集合
有序集合相对于字符串、列表、哈希、集合来说会有?些陌?。它保留了集合不能有重复成员的特点,但与集合不同的是,有序集合中的每个元素都有?个唯?的浮点类型的分数(score)与之关联,着使得有序集合中的元素是可以维护有序性的,但这个有序不是?下标作为排序依据?是?这个分数。
1、ZADD
添加或者更新指定的元素以及关联的分数到 zset 中,分数应该符合 double 类型,+inf/-inf 作为正负极限也是合法的。
ZADD 的相关选项:
? XX:仅仅?于更新已经存在的元素,不会添加新元素。
? NX:仅?于添加新元素,不会更新已经存在的元素。
? CH:默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更
新的元素的个数。
? INCR:此时命令类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定?个元素和分数。
语法:
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member...]
命令有效版本:1.2.0 之后
时间复杂度:O(log(N))
返回值:本次添加成功的元素个数。
2、ZCARD
获取?个 zset 的基数(cardinality),即 zset 中的元素个数。
语法:
ZCARD key
命令有效版本:1.2.0 之后
时间复杂度:O(1)
返回值:zset 内的元素个数
3、ZCOUNT
返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
语法:
ZCOUNT key min max
命令有效版本:2.0.0 之后
时间复杂度:O(log(N))
返回值:满?条件的元素列表个数。
4、ZRANGE
返回指定区间?的元素,分数按照升序。带上 WITHSCORES 可以把分数也返回。
语法:
ZRANGE key start stop [WITHSCORES]
此处的 [start, stop] 为下标构成的区间. 从 0 开始, ?持负数
命令有效版本:1.2.0 之后
时间复杂度:O(log(N)+M)
返回值:区间内的元素列表。
5、ZRANGEBYSCORE
返回分数在 min 和 max 之间的元素,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
备注:这个命令可能在 6.2.0 之后废弃,并且功能合并到 ZRANGE 中。
语法:
ZRANGEBYSCORE key min max [WITHSCORES]
命令有效版本:1.0.5 之后
时间复杂度:O(log(N)+M)
返回值:区间内的元素列表。
6、ZPOPMAX
删除并返回分数最?的 count 个元素。
语法:
ZPOPMAX key [count]
命令有效版本:5.0.0 之后
时间复杂度:O(log(N) * M)
返回值:分数和元素列表。
7、BZPOPMAX
ZPOPMAX 的阻塞版本。
语法:
BZPOPMAX key [key ...] timeout
8、ZPOPMIN
删除并返回分数最低的 count 个元素。
语法:
ZPOPMIN key [count]
命令有效版本:5.0.0 之后
时间复杂度:O(log(N) * M)
返回值:分数和元素列表。
9、ZRANK
返回指定元素的排名,升序。
语法:
ZRANK key member
返回 在 存储的排序集中的排名,分数为 从低到高排序。 排名(或索引)从 0 开始,这意味着具有最低的成员 分数有排名。
10、ZREVRANK
返回指定元素的排名,降序。
语法:
ZREVRANK key member
命令有效版本:2.0.0 之后
时间复杂度:O(log(N))
返回值:排名。
11、ZSCORE
返回指定元素的分数。
语法:
ZSCORE key member
命令有效版本:1.2.0 之后
时间复杂度:O(1)
返回值:分数。
12、ZREM
删除指定的元素。
语法:
ZREM key member [member ...]
命令有效版本:1.2.0 之后
时间复杂度:O(M*log(N))
返回值:本次操作删除的元素个数。
13、ZREMRANGEBYRANK
按照排序,升序删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYRANK key start stop
命令有效版本:2.0.0 之后
时间复杂度:O(log(N)+M)
返回值:本次操作删除的元素个数。
14、ZREMRANGEBYSCORE
按照分数删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYSCORE key min max
命令有效版本:1.2.0 之后
时间复杂度:O(log(N)+M)
返回值:本次操作删除的元素个数。
15、ZINCRBY
为指定的元素的关联分数添加指定的分数值。
语法:
ZINCRBY key increment member
命令有效版本:1.2.0 之后
时间复杂度:O(log(N))
返回值:增加后元素的分数。
16、集合间操作
16.1、ZINTERSTORE
求出给定有序集合中元素的交集并保存进?标有序集合中,在合并过程中以元素为单位进?合并,元素对应的分数按照不同的聚合?式和权重得到新的分数。
语法:
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight
[weight ...]] [AGGREGATE <SUM | MIN | MAX>]
numkeys:表示有几个key进行求集合
weights:表示权重,有多个权重就会全部加起来,然后乘每个元素的分数
如果member相同元素相同怎么办?
- 可以后面进行添加MIN或者MAX或者SUM,看我们想要按什么方式合并
命令有效版本:2.0.0 之后
时间复杂度:O(NK)+O(Mlog(M)) N 是输?的有序集合中, 最?的有序集合的元素个数; K 是输?了?个有序集合; M 是最终结果的有序集合的元素个数.
返回值:?标集合中的元素个数
16.2、ZUNIONSTORE
求出给定有序集合中元素的并集并保存进?标有序集合中,在合并过程中以元素为单位进?合并,元
素对应的分数按照不同的聚合?式和权重得到新的分数。
语法:
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight
[weight ...]] [AGGREGATE <SUM | MIN | MAX>]
命令有效版本:2.0.0 之后
时间复杂度:O(N)+O(M*log(M)) N 是输?的有序集合总的元素个数; M 是最终结果的有序集合的元素个数.
返回值:?标集合中的元素个数
17、渐进式遍历命令
scan
Redis 使? scan 命令进?渐进式遍历键,进?解决直接使? keys 获取键时可能出现的阻塞问题。每次 scan 命令的时间复杂度是 O(1),但是要完整地完成所有键的遍历,需要执?多次 scan。
? ?次 scan 从 0 开始.
? 当 scan 返回的下次位置为 0 时, 遍历结束.
以渐进式的?式进?键的遍历。
语法:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
cursor:表示从下标为多少的位置开始遍历
count:表示遍历多少个key
命令有效版本:2.8.0 之后
时间复杂度:O(1)
返回值:下?次 scan 的游标(cursor)以及本次得到的键。
九、数据库管理
Redis 提供了?个?向 Redis 数据库的操作,分别是 dbsize、select、flushdb、flushall 命令,
本机将通过具体的使?常?介绍这些命令
1、切换数据库
select dbIndex
select 0 操作会切换到第?个数据库,select 15 会切换到最后?个数据库.一般我们只默认用0号数据库
2、flushdb
删除当前数据库中所有的key
3、flushall
删除所有数据库中的key
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!