《Python Advanced Programming + Design Patterns + Clean Code》
清洁代码 — 学习如何编写可读、可理解且可维护的代码
高级Python编程知识
Python之常用设计模式
Advanced Programming
Python高级编程主要补一下我不太熟悉的知识。
装饰器 decorators
装饰器就是把很多函数的执行前后需要的公用代码提取出来,构造为一个装饰器函数,当其他函数想调用装饰器函数时,在其他函数def的头上用@装饰即可。
装饰器函数是一个高阶函数(拿其他函数fun作为参数或返回值的函数),它接受一个函数func作为参数,内层在原始函数fun执行前后添加了一些额外的操作,返回fun执行机构,外层返回一内层函数wrapper。
自定义装饰器:装饰器可以是多层函数的嵌套,真正的装饰器接受fun函数,可能会加上外层 或 内层函数接受fun的万能动态参数(*args, **kwargs)。然后我们就可以对任意自定义的fun(*args, **kwargs)函数使用@装饰器了。
- 一般是2层嵌套:外层接收
fun,内层接收fun的参数(*args, **kwargs)。
如最简单的一个例子:装饰器@welcome外层接收一个fun函数,内层warpper接收万能动态参数(*args, **kwargs),在内层组织print("Welcome")和fun()的执行顺序,然后内层返回fun()执行结果,外层返回内层函数warpper。
def welcome(fun):
def warpper(*args, **kwargs):
print("Welcome")
return fun(*args, **kwargs)
return warpper
@welcome
def my_fun1(message: str) -> None:
print(f"Hello {message}. this is fun1")
my_fun1("Jack")
再如最常见的计时装饰器@_time:哪个函数需要计时,直接加上装饰器@_time即可,而不用再单独写计时的这部分代码,使代码更加简洁高效。
from time import time
def _time(f):
def warpper(*args, **kwargs):
start = time()
result = f(*args, **kwargs)
end = time()
print(f"{f.__name__} took {end - start} seconds")
return result
return warpper
- 也可以是3层嵌套:为了传入
装饰器函数的配置参数,添加一个最外层函数接收装饰器函数的配置参数,返回装饰器函数。而里面两层和原始的2层结构一模一样,中层接收fun,内层接收fun的参数(*args, **kwargs)。除了添加最外层用于接收装饰器函数的配置参数,使用时也需要给出装饰器函数的配置参数,@装饰器(装饰器参数)。
def welcome(name):
def decorator(fun):
def warpper(*args, **kwargs):
print(f"Welcome {name}")
return fun(*args, **kwargs)
return warpper
return decorator
@welcome("Tom")
def my_fun1(message: str) -> None:
print(f"Hello {message}. this is fun1")
my_fun1("Jack")
其中内层函数可以访问外层函数的对象,这个可以访问的空间叫做闭包。
具体可以看我这篇 深度学习代码优化(Config,Registry,Hook)的注册器机制 Registry部分对装饰器 和 闭包有详细的介绍。
@dataclass:当我们希望构造一个数据类时(如深度学习中的Output类),使用@dataclass装饰可以大大简化类的定义。
(1)省略__init__();
class UNetOutput:
def __init__(self, latents, nums=10):
self.latents = latents
self.nums = nums
from dataclasses import dataclass
@dataclass
class UNetOutput:
latents: list
nums: int = 10
(2)灵活设置(frozen=True),对象一旦创建就不可更改。
@dataclass(frozen=True)
class UNetOutput:
latents: list
nums: int
(3)实现了对比和排序(用第一个属性排序,如果第一个属性相同再比较第二个…)。
res1 = UNetOutput([1, 2, 3], 10)
res2 = UNetOutput([1, 2, 3], 10)
res1 == res2
# True
@dataclass(order=True)
class UNetOutput:
latents: list
nums: int
res1 = UNetOutput([1, 2, 3], 12)
res2 = UNetOutput([1, 2, 3], 10)
l = [res1, res2]
l.sort()
# [UNetOutput(latents=[1, 2, 3], nums=10), UNetOutput(latents=[1, 2, 3], nums=12)]
如果不想用第一个属性优先排序,就在.sort(key=operator.attrgetter('nums'))中指定排序优先的属性。
@dataclass
class UNetOutput:
latents: list
nums: int
res1 = UNetOutput([1, 2, 3], 12)
res2 = UNetOutput([1, 2, 3], 10)
l = [res1, res2]
import operator
l.sort(key=operator.attrgetter('nums'))
l
# [UNetOutput(latents=[1, 2, 3], nums=10), UNetOutput(latents=[1, 2, 3], nums=12)]
- 类装饰器:假如我们希望实现一个
装饰器类,在函数执行前打印entry,在函数执行后打印end:装饰器类在初始化__init__的时候传入fun,再定义__call__函数扮演真正的装饰的wapper函数。
class MyDecorator:
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
print("Before")
self.func(*args, **kwargs)
print("After")
@MyDecorator
def test():
print("Testing")
test()
如果希望实现前面那种3层的带装饰器配置参数的的装饰器,需要在__init__传入装饰器参数,在__call__传入fun函数:
class MyDecorator:
def __init__(self, num):
self.num = num
def __call__(self, func):
print(self.num)
self.func = func
def wrapper(*args, **kwargs):
print("Before")
res = self.func()
print("After")
return res
return wrapper
@MyDecorator(666)
def test():
print("Testing")
test()
生成器 & 迭代器
关键:(1)yield语句是生成器的核心、(2)生成器与迭代器是惰性列表。
一图解释 列表/元组/字典(list/tuple/dict)、容器(container)、可迭代对象(iterable)、迭代器(iterator)、生成器(generator)的关系:
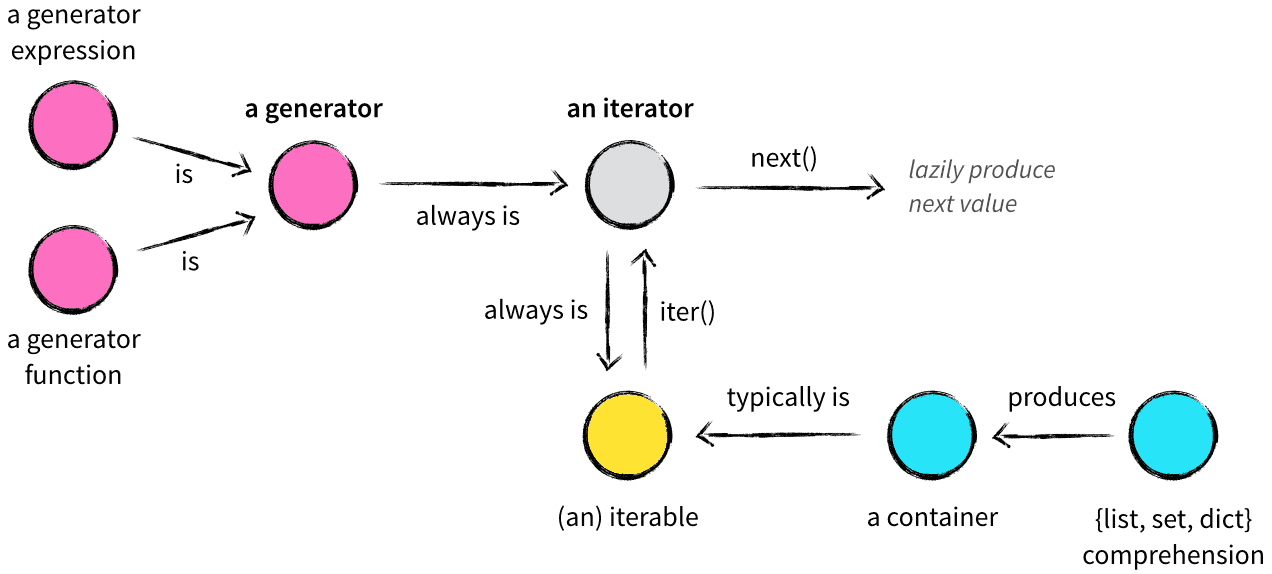
- 生成器 generator:构造生成器的方式有2种:
- 生成器表达式:
生成器表达式和列表推导式的写法几乎一样,只要把中括号[]换成圆括号()就好了
list_ = [x for x in range(1,11)] # 列表推导式
generator = (x for x in range(1,11)) # 生成器表达式
for i in generator:
print(i)
- yield语句——生成器函数:当
一个函数包含yield语句的时候,这个函数就不再是一个普通的函数了,而是一个生成器函数。yield和return的本质区别是:return一旦返回,下次执行该函数将从头开始;yield返回后,下次再次调用该函数时,将从上次yield返回的下一句接着执行。
如下例子,调用生成器函数返回一个生成器,(1)使用next(生成器)每次从生成器中取出一次数据(即执行到下一个yield) ;(2)当然生成器可以理解为一个可迭代对象,使用for循环遍历。
def yield_list():
print("step 1")
yield 1
print("step 2")
yield 2
print("step 3")
yield 3
print("step 4")
yield 4
generator = yield_list()
next(generator)
generator = yield_list()
for value in generator:
print(value)
更简洁的写法:
def yield_list():
for i in range(1,5):
print(f"step {i}")
yield i
generator = yield_list()
next(generator)
generator = yield_list()
for value in generator:
print(value)
- 迭代器 iterator:主要有2个来源,(1)生成器本质就是迭代器,其最大特点是代码简洁。(2)可迭代对象使用
iter(可迭代对象)得到迭代器。(3)自定义迭代器:任何实现了__iter__()和__next__()方法的对象都是迭代器,__iter__()返回迭代器自身,__next__()返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常。
迭代器是一个带状态的对象,它能在你调用__next__()方法时返回容器中的下一个值。
class My_Iterator:
def __init__(self, num):
self.num = num # 迭代器长度
self.index = 0 # 起始值
def __iter__(self):
return self
def __next__(self):
if self.index < self.num:
value = self.index
self.index += 1 # 每次加一
return value
else:
raise StopIteration
my_iterator = My_Iterator(5)
for value in my_iterator:
print(value)
当然,我们可以使用生成器更简洁的实现迭代器:
def My_Iterator(num):
for i in range(1,num):
yield i
my_iterator = My_Iterator(5)
for value in my_iterator:
print(value)
- 惰性列表:生成器和迭代器实现的是惰性列表,是
「需要时才计算出值」的列表,而不是一次将所有值全部加载到内存,而是每次只加载需要的值。这在深度学习加载超大规模数据集时是否有用! 带你从零掌握迭代器及构建最简 DataLoader
def get_list(num):
results = []
for i in range(1,num):
results.append(i)
return results
results = get_list(5)
for i in results
print(results[i])
############################
def yield_list(num):
for i in range(1,num):
yield i
generator = yield_list(5)
for value in generator:
print(value)
with 上下文管理器
上下文管理器是一个对象(with范围内的动态全局变量),定义了运行时的上下文,使用with 上下文管理器:来执行,在with的管辖范围内可以访问这个上下文管理器,在with运行前做一些预处理,在with运行结束再做一些后处理。
with context_manager as ctx_m:
# 前处理
# 随意访问 ctx_m
# 后处理
最经典的例子就是文件读写:不使用上下文管理器时,需要我们手动关闭文件。
file = open("data.txt", "w")
file.write("hello")
file.close()
使用上下文管理器后,open("data.txt", "w") 返回系统帮我们实现好的File上下文管理器,with范围结束时,自动执行file.close()关闭文件:
with open("data.txt", "w") as file:
file.write("hello")
自定义上下文管理器:必须实现__enter__和__exit__这两个方法。进入with时执行__enter__,返回ctx_m=self,退出with时执行__exit__:
class Context_Manager:
def __init__(self):
self.context = "this is my context"
def __enter__(self):
print("Entering context: PreProcess")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("Exiting context: PostProcess")
with Context_Manager() as ctx_m:
print(ctx_m.context)
Entering context: PreProcess
this is my context
Exiting context: PostProcess

面向对象
- 抽象和继承:定义的类可以作为一个基类(
抽象类ABC),里面的方法是抽象方法,用@abstractmethod装饰,这意味着任何继承自该类都必须重写这个方法。基类的函数没有主体,可以将所有可能需要的功能都声明为一个抽象方法或者类。可以先决定一个high-level的实现,然后定义一个新的类继承它,详细地处理每个部分。
from abc import ABC, abstractmethod
class BaseModel(ABC):
def __init__(self, cfg):
self.cfg = cfg
@abstractmethod
def train(self):
pass
@abstractmethod
def test(self):
pass
class YourNet(BaseModel):
def __init__(self, cfg):
super(YourNet, self).__init__(cfg)
# create model
def train(self):
# do train
pass
def test(self):
# do test
pass
- 静态方法和类方法:
静态方法@staticmethod:没有self,也没有cls参数,在定义类的时候,有时候部分函数跟类没关系,但是我们又需要用到它。可以在类外面单独定义这个函数,但是这样子会使代码变得难理解,因此使用静态方法,把这个单独的函数搬到类中表示。
class DataLoader:
@staticmethod
def load_data(file_name):
data = []
with open(file_name, 'r') as file:
for line in file:
data.append(line.strip())
return data
@staticmethod
def save_data(file_name, data):
with open(file_name, 'w') as file:
for item in data:
file.write(item + '\n')
类方法@classmethod :将实际的类作为参数,通常用作构造函数 ,用于创建类的新实例。类方法还有一个用途就是可以对类属性进行修改,在用类方法对类属性修改之后,通过类对象和实例对象访问都发生了改变。
形式上,类方法的第一个参数是类本身,我们通常用cls表示,通过cls可以调用类方法、类属性和静态方法。类内的其他常规方法,第一个参数是self,在调用的时候,是具体的类的实例。
import json
class Config:
"""
Configuration class for the application
"""
def __init__(self, data, train, model):
# 各个部分的超参数
self.data = data
self.train = train
self.model = model
@classmethod
def from_json(cls, cfg):
"""
Create a Config object from a JSON file
"""
with open(cfg, 'r') as f:
data = json.load(f)
return cls(data['data'], data['train'], data['model'])
我们从json文件构造一个配置,创建一个Config类,定义一个类方法from_json 去加载我们的配置信息(下图代码第20行起)。可以研究一下如何使用类方法和参数cls的。
Mixin 模式
Mix-in,常被译为“混入”,是一种编程模式,在 Python 等面向对象语言中,我们把某个功能类FuncMixin写好(实现了某种功能单元),其他类希望拥有这种功能的时候,继承对应的功能类FuncMixin即可,通过多继承可以将多个功能组合到子类中。理念上:类似@装饰器,当我们的函数希望使用对应功能的函数时,用@装饰器即可拥有对应的功能。
定义一个简单的类:
class Person:
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
我们可以通过调用实例属性的方式来访问:
p = Person("小陈", "男", 18)
print(p.name) # "小陈"
然后我们定义一个 Mixin 类:这个类可以让子类拥有像 字典dict 一样调用属性的功能
class MappingMixin:
def __getitem__(self, key):
return self.__dict__.get(key)
def __setitem__(self, key, value):
return self.__dict__.set(key, value)
我们将这个 Mixin 加入到 Person 类中:
class Person(MappingMixin):
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
现在 Person 拥有另一种调用属性方式了:
p = Person("小陈", "男", 18)
print(p['name']) # "小陈"
print(p['age']) # 18
再定义一个 Mixin 类,这个类实现了 __repr__ 方法,能自动将属性与值拼接成字符串:
class ReprMixin:
def __repr__(self):
s = self.__class__.__name__ + '('
for k, v in self.__dict__.items():
if not k.startswith('_'):
s += '{}={}, '.format(k, v)
s = s.rstrip(', ') + ')' # 将最后一个逗号和空格换成括号
return s
利用 Python 的特性,一个类可以继承多个父类:
class Person(MappingMixin, ReprMixin):
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
这样这个子类混入了两种功能:
p = Person("小陈", "男", 18)
print(p['name']) # "小陈"
print(p) # Person(name=小陈, gender=男, age=18)
反射机制
核心思想:利用字符串,去已存在的模块中找到指定的属性或方法,找到方法后自动执行——基于字符串的事件驱动。
hasattr(object,'attrName'):判断该对象是否有指定名字的属性或方法,返回值是bool类型setattr(object,'attrName',value):给指定的对象添加属性以及属性值getattr(object,'attrName'):获取对象指定名称的属性或方法,返回值是str类型delattr(object,'attrName'):删除对象指定名称的属性或方法值,无返回值
注:getattr,hasattr,setattr,delattr对模块的修改都在内存中进行,并不会影响模型class定义文件中真实内容!!下一次重新import创建模型对象时,还是原来的类结构。
在正式介绍实际应用场景之前,先来看看这样的一个importlib模块。输入多层的模块路径,自动生成对象并调用该类的方法。比如:notify.email.Email,notify包下面有模块email,模块email(.py文件)中包括了Email类,利用该类声明对象,并调用其中的send()方法。
# 模块:importlib
import importlib
#'notify.email.Email'
path_str = input("请输入包-模块-类的字符串路径:") # module_path.class_name
module_path,class_name = path_str.rsplit('.',maxsplit=1)
# 1 利用字符串导入模块,该方法最小只能到.py文件名即模块
module = importlib.import_module(module_path) # from notify import email
# 2 利用反射获取类名
cls = getattr(module,class_name) # Email、QQ、Wechat
# 3 生成类的对象
obj = cls()
# 4 直接调用send方法
obj.send()
一个通用的工具函数就是:
def get_obj_from_str(string, reload=False):
module, cls = string.rsplit(".", 1)
if reload:
module_imp = importlib.import_module(module)
importlib.reload(module_imp)
return getattr(importlib.import_module(module, package=None), cls)
常见的应用,还有就是对于已经创建好的UNet模型找到对应的CrossAttention类对象,然后修改CrossAttention类对象的forward函数:
def register_recr(net_, count, place_in_unet):
if net_.__class__.__name__ == 'CrossAttention':
net_.forward = ca_forward(net_, place_in_unet)
return count + 1
elif hasattr(net_, 'children'):
for net__ in net_.children():
count = register_recr(net__, count, place_in_unet)
return count
cross_att_count = 0
sub_nets = model.unet.named_children()
for net in sub_nets:
if "down" in net[0]:
cross_att_count += register_recr(net[1], 0, "down")
elif "up" in net[0]:
cross_att_count += register_recr(net[1], 0, "up")
elif "mid" in net[0]:
cross_att_count += register_recr(net[1], 0, "mid")
并发编程
https://www.bilibili.com/video/BV1BY411d7qr/?spm_id_from=333.788&vd_source=b2549fdee562c700f2b1f3f49065201b
Design Patterns
设计模式:前人将一类问题的统一解决办法总结为一种设计模式。当后人遇到相似问题时,就可以用对应的模式进行代码设计。
设计模式6个原则:
1、开闭原则(Open Close Principle):接口和抽象类的设计,对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。
2、里氏代换原则(Liskov Substitution Principle):任何基类可以使用的地方,派生类一定可以使用。LSP 是继承复用的基石,只有当派生类可以替换掉基类,且软件单位的功能不受到影响时,基类才能真正被复用,而派生类也能够在基类的基础上增加新的行为。
3、依赖倒转原则(Dependence Inversion Principle):针对接口编程(抽象),依赖于抽象类,而不依赖于具体类。
4、接口隔离原则(Interface Segregation Principle):使用多个隔离的专门接口(多继承抽象类),比使用单个总的接口要好。它还有另外一个意思是:降低抽象类之间的耦合度,强调降低依赖,降低耦合。
5、单一职责原则,又称最少知道原则(Demeter Principle):一个类只负责一个职责。一个实体应当尽量少地与其他实体之间发生相互作用,使得系统功能模块相对独立。
6、合成复用原则(Composite Reuse Principle):尽量使用合成/聚合的方式,而不是使用继承。
设计模式分类

1、创建型模式:关注怎么创建对象。这些设计模式提供了一种在创建对象的同时,隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象。这使得程序在判断针对某个给定实例需要创建哪些对象时更加灵活。

2、结构型模式:关注几个类之间如何耦合。这些模式关注对象之间的组合和关系,旨在解决如何构建灵活且可复用的类和对象结构。
3、行为型模式:关注几个类之间如何交互。这些模式关注对象之间的通信和交互,旨在解决对象之间的责任分配和算法的封装。
接下来将讲述各种具体的设计模式,我会在比较重要的模式后面打√。
简单工厂模式
工厂模式,在创建对象时不会对客户端暴露对象的创建逻辑,提供了一种将对象的实例化过程封装在工厂类中的方式,通过使用一个共同的工厂类接口来创建不同类型的对象,可以将对象的创建与使用代码分离,提供一种统一的接口。
角色:
- 工厂角色:PaymentFactory
- 抽象产品:Payment
- 具体产品:WechatPayment、CashPayment
from abc import ABC, abstractmethod
class Payment(ABC):
@abstractmethod
def pay(self, money):
pass
class WechatPayment(Payment):
def __init__(self, use_card=False):
super().__init__()
self.use_card = use_card
def pay(self, money):
if self.use_card:
print(f"Using WeChat BankCard Pay {money}") # 用微信的银行卡支付
else:
print(f"Using WeChat LingQian Pay {money}") # 用微信零钱支付
class CashPayment(Payment):
def pay(self, money):
print(f"Using Cash Paying {money}")
class PaymentFactory:
def create_payment(self, payment_type):
if payment_type == "wechat_lingqian":
return WechatPayment(use_card=False)
elif payment_type == "wechat_bankcard":
return WechatPayment(use_card=True)
elif payment_type == "cash":
return CashPayment()
else:
raise ValueError("Unknown payment type")
factory = PaymentFactory()
payment = factory.create_payment("wechat_lingqian")
payment.pay(100
优点: 1、隐藏了对象创建的细节,一个调用者想创建一个对象,调用者只关心产品的接口。 2、扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以,客户端不需要修改代码。
缺点:1、违反了单一职责原则,将创建逻辑集中到一个工厂中。2、违法开闭原则,每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
工厂模式 √
为了避免简单工厂模式中工厂类集中所有对象创建的逻辑,我们引入抽象工厂类,对起进行解耦,便于修改和维护,增加产品时,只需要继承抽象工厂,创建新的工厂类即可,而不需要修改抽象工厂类。
主要解决:主要解决接口选择的问题。
何时使用:我们明确地计划不同条件下创建不同实例时。
角色:
- 抽象产品(Abstract Product):定义了产品的共同接口或抽象类。它可以是具体产品类的父类或接口,规定了产品对象的共同方法。
- 具体产品(Concrete Product):实现了抽象产品接口,定义了具体产品的特定行为和属性。
- 抽象工厂(Abstract Factory):声明了创建产品的抽象方法,可以是接口或抽象类。它可以有多个方法用于创建不同类型的产品。
- 具体工厂(Concrete Factory):实现了抽象工厂接口,负责实际创建具体产品的对象。
from abc import ABC, abstractmethod
class Payment(ABC):
@abstractmethod
def pay(self, money):
pass
class WechatPayment(Payment):
def __init__(self, use_card=False):
super().__init__()
self.use_card = use_card
def pay(self, money):
if self.use_card:
print(f"Using WeChat BankCard Pay {money}") # 用微信的银行卡支付
else:
print(f"Using WeChat LingQian Pay {money}") # 用微信零钱支付
class CashPayment(Payment):
def pay(self, money):
print(f"Using Cash Paying {money}")
class PaymentFactory(ABC):
@abstractmethod
def create_payment(self):
pass
class WechatLingQianPaymentFactory(PaymentFactory):
def create_payment(self):
return WechatPayment(use_card=False)
class WechatBankCardPaymentFactory(PaymentFactory):
def create_payment(self):
return WechatPayment(use_card=True)
class CashPaymentFactory(PaymentFactory):
def create_payment(self):
return CashPayment()
factory = WechatLingQianPaymentFactory()
payment = factory.create_payment()
payment.pay(100)
优点:(1)每个具体产品都对应一个具体工厂类,不需要修改工厂类代码。(2)隐藏了对象创建的实现细节。
缺点:每增加一个具体产品类,就必须增加一个想应的具体工厂类,代码太多。
抽象工厂模式
定义一个工厂类接口,让工厂子类创建一系列相关或相互依赖的对象。相比工厂模式,抽象工厂模式中,每个具体的工厂都生产一套产品。如,生产一部手机,需要手机壳、CPU、操作系统三类对象进行组装其中每类对象都有不同的种类。对每个具体工厂,分别生产一部手机所需要的三个对象。
角色:
- 抽象工厂(Abstract Factory):声明了一组用于创建产品对象的方法,
每个方法对应一种产品类型。抽象工厂可以是接口或抽象类。 - 具体工厂(Concrete Factory):实现了抽象工厂接口,负责创建具体产品对象的实例。
- 抽象产品(Abstract Product):定义了一组产品对象的共同接口或抽象类,描述了产品对象的公共方法。
- 具体产品(Concrete Product):实现了抽象产品接口,定义了具体产品的特定行为和属性。
from abc import ABC, abstractmethod
# 抽象产品
class PhoneShell(ABC):
@abstractmethod
def show_shell(self):
pass
class CPU(ABC):
@abstractmethod
def show_cpu(self):
pass
class OS(ABC):
@abstractmethod
def show_os(self):
pass
# 抽象工厂
class PhoneFactory(ABC):
@abstractmethod
def make_shell(self):
pass
@abstractmethod
def make_cpu(self):
pass
@abstractmethod
def make_os(self):
pass
# 具体产品
class SmallShell(PhoneShell):
def show_shell(self):
print("small shell")
class BigShell(PhoneShell):
def show_shell(self):
print("big shell")
class HighEndCPU(CPU):
def show_cpu(self):
print("high end cpu")
class LowEndCPU(CPU):
def show_cpu(self):
print("low end cpu")
class AndroidOS(OS):
def show_os(self):
print("android os")
class IOSOS(OS):
def show_os(self):
print("ios os")
# 具体工厂
class HuaWei_S_H(PhoneFactory):
def make_shell(self):
return SmallShell()
def make_cpu(self):
return HighEndCPU()
def make_os(self):
return AndroidOS()
class Apple_B_L(PhoneFactory):
def make_shell(self):
return BigShell()
def make_cpu(self):
return LowEndCPU()
def make_os(self):
return IOSOS()
# 客户端
class Phone:
def __init__(self, shell, cpu, os):
self.shell = shell
self.cpu = cpu
self.os = os
def show_info(self):
print("phone info:")
self.shell.show_shell()
self.cpu.show_cpu()
self.os.show_os()
def make_phone(phone_factory):
return Phone(phone_factory.make_shell(),
phone_factory.make_cpu(),
phone_factory.make_os())
p = make_phone(HuaWei_S_H())
p.show_info()
优点:当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
缺点:产品族扩展非常困难,要增加一个系列的某一产品,既要在抽象的 Creator 里加代码,又要在具体的里面加代码。如Phone的组件中加一个GPU,既要修改Phone抽象工厂和抽象产品代码,又要增加GPU具体产品代码。
建造者模式 √
建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象。一个 Builder 类会一步一步构造最终的对象。该 Builder 类是独立于其他对象的。
主要解决:主要解决在软件系统中,有时候面临着复杂对象的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定。
何时使用:一些基本部件不会变,而其组合经常变化的时候。
角色:
- 复杂类:由多个组件构成的复杂类。
- 抽象Builder:使用抽象方法定义复杂类每个组件的build抽象方法。
- 具体Builder:具体实现抽象build方法,从而可以构造多种类型的复杂类的具体类。
- 导演Director:定义Builder中每个组件build方法的执行顺序。
from abc import ABC, abstractmethod
# 复杂类
class Player:
def __init__(self, face=None, body=None, arm=None, leg=None):
self.face = face
self.body = body
self.arm = arm
self.leg = leg
def __str__(self):
return f"Player(face={self.face}, body={self.body}, arm={self.arm}, leg={self.leg})"
# 抽象Builder
class PlayerBuilder(ABC):
@abstractmethod
def build_face(self):
pass
@abstractmethod
def build_body(self):
pass
@abstractmethod
def build_arm(self):
pass
@abstractmethod
def build_leg(self):
pass
# 具体Builder
class SexyGirlBuilder(PlayerBuilder):
def __init__(self):
self.player = Player()
def build_face(self):
self.player.face = "Beautiful face"
def build_body(self):
self.player.body = "Sexy body"
def build_arm(self):
self.player.arm = "Slim arm"
def build_leg(self):
self.player.leg = "Long leg"
class MonsterBuilder(PlayerBuilder):
def __init__(self):
self.player = Player()
def build_face(self):
self.player.face = "Monster face"
def build_body(self):
self.player.body = "Monster body"
def build_arm(self):
self.player.arm = "Monster arm"
def build_leg(self):
self.player.leg = "Monster leg"
# Director
class PlayerDirector: # 定义build顺序
def build_player(self, builder):
builder.build_face()
builder.build_body()
builder.build_arm()
builder.build_leg()
return builder.player
# 客户端
builder = SexyGirlBuilder()
director = PlayerDirector()
sexy_girl = director.build_player(builder)
print(sexy_girl.__str__())
优点:(1)分离构建过程和表示,使得构建过程更加灵活,可以构建不同的表示。(2)可以更好地控制构建过程,隐藏具体构建细节。(3)代码复用性高,可以在不同的构建过程中重复使用相同的建造者。
缺点:(1)如果产品的属性较少,建造者模式可能会导致代码冗余。(2)建造者模式增加了系统的类和对象数量。
单例模式 √
单例模式(Singleton Pattern)确保一个单例类只创建一个实例,并给所有其他对象提供这一实例的全局访问点,来访问该实例。
主要解决:一个全局使用的类频繁地创建与销毁。
何时使用:当您想控制实例数目,节省系统资源的时候。如日志对象我们希望是单例的,不希望每个进程都创建一个然后同时对log文件进行写入。
在讲单例模式前,我们先来回顾一下类的实例化:
class MyClass:
def __init__(self, num):
self.num = num
my_class_instance = MyClass(10)
Python类默认继承Object类,在使用MyClass(10)后,先用 __new__方法创建这个类的实例,然后__init__是在类实例创建之后用于初始化实例的属性值。
角色:
- Singleton单例基类:重写Obect类的
__new__方法,控制cls子类创建实例时检查是否已经有已经创建的实例。
class Singleton:
def __new__(cls, *args, **kwargs):
if not hasattr(cls, '_instance'):
cls._instance = super(Singleton, cls).__new__(cls)
return cls._instance
class MyClass(Singleton):
def __init__(self, num):
self.num = num
a = MyClass(10)
print(a.num)
b = MyClass(20)
print(b.num)
优点:1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。2、避免对资源的多重占用(比如写文件操作)。
缺点:没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
适配器模式 √
当2个类不能一起工作时,引入适配器类,作为两个不兼容的接口之间的桥梁。
主要解决:主要解决在软件系统中,常常要将一些"现存的对象"放到新的环境中,而新环境要求的接口是现对象不能满足的。
何时使用: 系统需要使用现有的类,而此类的接口不符合系统的需要。
还是支付类的例子,新加一个不适配Payment的支付类ZFBPayment,不能之间对ZFBPayment的对象调用.pay方法,而且**cost方法在其他很多模块中已经使用,修改成本很大**。
- 只有一个类接口有问题时(多继承),我们可以重写一个
NewZFBPayment类,继承两种接口(pay和cost),然后统一接口:
from abc import ABC, abstractmethod
class Payment(ABC):
@abstractmethod
def pay(self, money):
pass
class WechatPayment(Payment):
def pay(self, money):
print(f"Using WeChat Pay {money}")
class CashPayment(Payment):
def pay(self, money):
print(f"Using Cash Paying {money}")
class ZFBPayment: # 新加一个不适配Payment的支付类,而且cost方法在其他很多模块中已经使用,修改成本很大
def cost(self, amount):
print(f"Using ZFB Pay {amount}")
class NewZFBPayment(Payment, ZFBPayment): # 适配器
def pay(self, money):
self.cost(amount = money)
zfb_pay = NewZFBPayment()
zfb_pay.pay(100)
- 如果有很多类接口都不匹配(组合),对每个不匹配的类都重写一个适配器类太繁琐,可以定义一个总的适配器
PaymentAdapeter,传入任意的类,在PaymentAdapeter中统一接口:
from abc import ABC, abstractmethod
class Payment(ABC):
@abstractmethod
def pay(self, money):
pass
class WechatPayment(Payment):
def pay(self, money):
print(f"Using WeChat Pay {money}")
class CashPayment(Payment):
def pay(self, money):
print(f"Using Cash Paying {money}")
class ZFBPayment:
def cost(self, amount):
print(f"Using ZFB Pay {amount}")
class ApplePayment:
def cost(self, amount):
print(f"Using Apple Pay {amount}")
class PaymentAdapeter(Payment):
def __init__(self, payment):
self.payment = payment
def pay(self, money):
self.payment.cost(money)
apple_pay = ApplePayment()
adapter = PaymentAdapeter(apple_pay)
adapter.pay(100)
zfb_pay = ZFBPayment()
adapter = PaymentAdapeter(zfb_pay)
adapter.pay(100)
优点: 1、可以让任何两个没有关联的类一起运行。 2、提高了类的复用。 3、增加了类的透明度。 4、灵活性好。
缺点: 1、过多地使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是 A 接口,其实内部被适配成了 B 接口的实现,一个系统如果太多出现这种情况,无异于一场灾难。因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。 2.由于 JAVA 至多继承一个类,所以至多只能适配一个适配者类,而且目标类必须是抽象类。
观察者模式 √
观察者模式(Observer Pattern)定义了一种一对多的依赖关系,当一个对象的(发布者)状态发生改变时,其所有依赖者(订阅者)都会收到通知并自动更新。也叫“发布-订阅“模式。
主要解决:一个对象状态改变给其他对象通知的问题,而且要考虑到易用和低耦合,保证高度的协作。
何时使用:一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。
角色:
- 抽象主题Subject:
- 具体主题ConcreteSubject:发布者
- 抽象观察者Observer:
- 具体观察者ConcreteObserver:订阅者
from abc import ABC, abstractmethod
# 抽象订阅者
class Observer(ABC):
@abstractmethod
def update(self, subject, arg): # Update observer
pass
# 抽象发布者
class Subject:
def __init__(self):
self._observers = [] # Save all observers
def register(self, observer):
self._observers.append(observer) # Register observer to subscribe subject
def remove(self, observer):
self._observers.remove(observer) # observer cancel subscribe
def notify(self, arg):
for observer in self._observers: # Notify all observers
observer.update(self, arg) # 传入subject和arg
# 具体订阅者
class ConcreteObserver(Observer):
def update(self, subject, arg):
print(f"{self.__class__.__name__ }: {arg}")
# 具体发布者
class ConcreteSubject(Subject):
def __init__(self):
super().__init__()
self._state = 0 # 私有属性
@property # 属性装饰器
def state(self): # 读subject.state自动返回subject._state
return self._state
@state.setter
def state(self, value): # 写subject.state自动修改subject._state
self._state = value
self.notify(self._state) # 同时自动通知所有订阅者
subject = ConcreteSubject()
observer1 = ConcreteObserver()
observer2 = ConcreteObserver()
subject.register(observer1)
subject.register(observer2)
subject.state = 10
subject.state = 20
优点: 1、观察者和被观察者是抽象耦合的。 2、建立一套触发机制。
缺点: 1、如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。 2、如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。 3、观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
策略模式 √
策略模式定义了一系列算法或策略,并将每个算法封装在独立的类中,使得它们可以互相替换。通过使用策略模式,可以在运行时根据需要选择不同的算法,而不需要修改客户端代码。创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
主要解决:在有多种算法相似的情况下,使用 if…else 所带来的复杂和难以维护。
何时使用:一个系统有许多许多类,而区分它们的只是他们直接的行为。
角色:
- 抽象策略Strategy:
- 具体策略ConcreteStrategy:
- 上下文Context:
from abc import ABC, abstractmethod
# 抽象策略
class Strategy(ABC):
@abstractmethod
def execute(self, data):
pass
# 具体策略
class FastStrategy(Strategy):
def execute(self, data):
print(f"Fast strategy using data {data}")
class SlowStrategy(Strategy):
def execute(self, data):
print(f"Slow strategy using data {data}")
# 上下文
class Context:
def __init__(self, strategy, data):
self._strategy = strategy
self.data = data
def set_strategy(self, strategy): # 切换策略
self._strategy = strategy
def do_strategy(self): # 执行策略
self._strategy.execute(self.data)
# 客户端
context = Context(FastStrategy(), "666")
context.do_strategy()
context.set_strategy(SlowStrategy())
context.do_strategy()
优点: 1、算法可以自由切换。 2、避免使用多重条件判断。 3、扩展性良好。
缺点: 1、策略类会增多。 2、所有策略类都需要对外暴露。
模板方法模式 √
模板模式(Template Pattern)定义一个操作中的算法的骨架,而将一些具体步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构(如下面的run),即可重定义该算法的某些特定步骤。子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。
主要解决:一些方法通用,却在每一个子类都重新写了这一方法。
何时使用:有一些通用的方法。
角色:
- 抽象类 (AbstractClass):定义抽象的原子操作(钩子操作) ; 实现一个模板方法作为算法的骨架。同时
抽象模板类已经把每个抽象方法的执行顺序定义好了。 - 具体类 (ConcreteClass):实现原子操作。
例子,窗口显示类Window抽象类,定义好算法在执行流程与结构run(子类不可该改变),但抽象的原子操作没有定义。子类实现抽象的原子操作。
from abc import ABC, abstractmethod
from time import sleep
# 抽象模板类
class Window(ABC):
@abstractmethod
def start(self):
pass
@abstractmethod
def repaint(self):
pass
@abstractmethod
def stop(self):
pass
def run(self): # 模板类已经把每个抽象方法的执行顺序定义好了
self.start()
while True:
try:
self.repaint()
sleep(1)
except KeyboardInterrupt:
break
self.stop()
class Window1(Window):
def __init__(self, msg):
self.msg = msg
def start(self):
print("Window1 started")
def repaint(self):
print(f"Window1 repainted {self.msg}")
def stop(self):
print("Window1 stopped")
win = Window1("Hello")
win.run()
优点: 1、封装不变部分,扩展可变部分。 2、提取公共代码,便于维护。 3、行为由父类控制,子类实现。
缺点:每一个不同的实现都需要一个子类来实现,导致类的个数增加,使得系统更加庞大。
Clean Code
3个核心概念:
- 可扩展性:在
功能演进时,是否容易维护,还是要修改大量代码、甚至是重构? - 可读性:是否很容易让人
读懂,并且没有歧义?Make code easy to understanding! - 简洁性:代码的
逻辑、实现是否精简?
只要在写代码的时候,大脑里时刻想着这3个概念,就能联想到这本书里的诸多方法,就能做到“下笔如有神了”!Write your code as a good story! 写好代码就像写好文章一样,好的代码、文章都需要通过符合一定的规范,让别人很轻易地读懂。
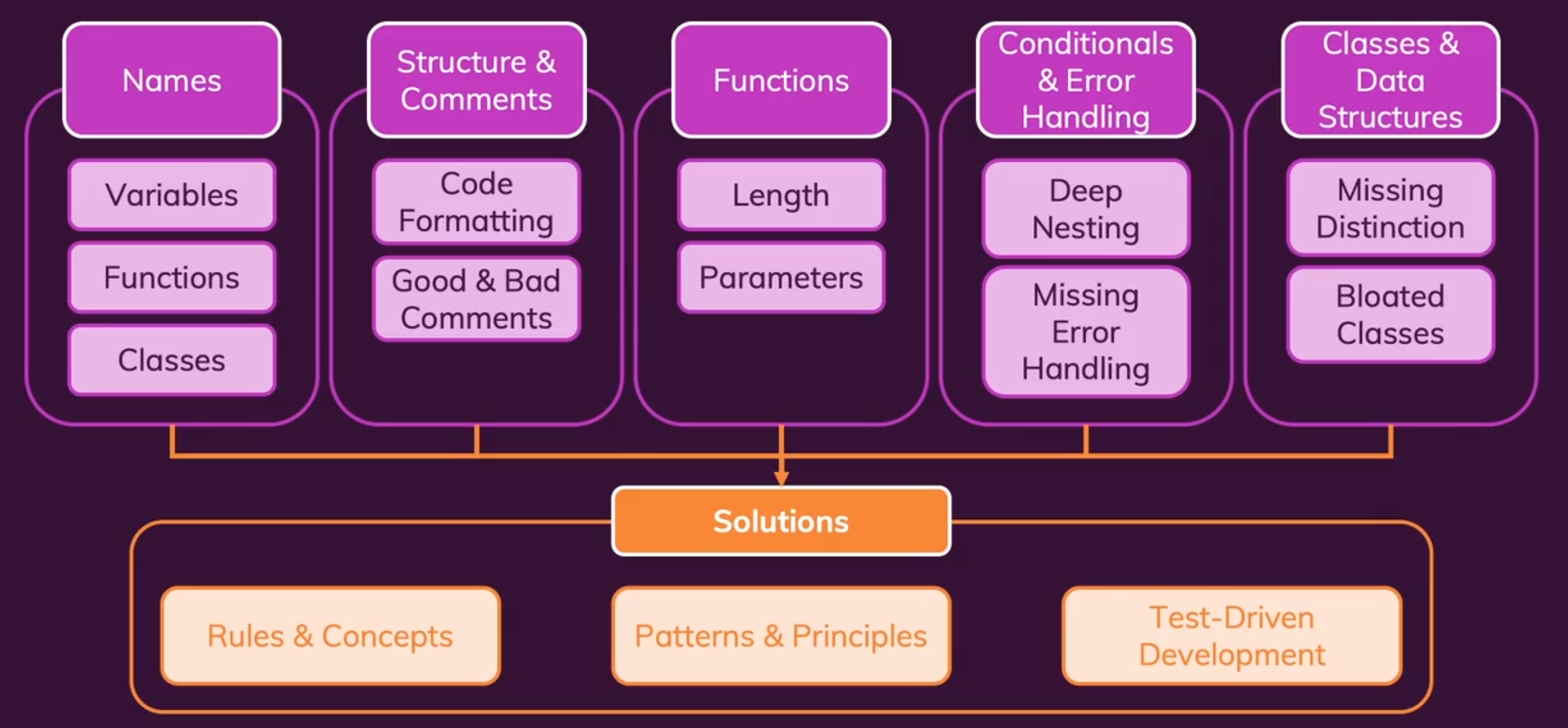
Clean Code的关键:命名、代码结构、注释、函数、控制结构、错误处理、类与数据结构
命名 Naming
3种命名格式:
- 小驼峰式命名法:第一个单词首字母小写,后面其他单词首字母大写,如
userData。JAVA的变量和函数使用。 - 大驼峰式命名法:每个单词的第一个字母都要大写,如
UserData。Python和JAVA的类名使用。 - 下划线命名法:单词与单词之间通过下划线连接即可,如
user_data。Python的变量和函数使用。
命名的核心思想:①Names should be meaningful ! ,好的名字是有明确意义的,应该向读者反映出一个变量或者一个函数代表什么,而不必 dive into 去查看内部是实现细节,应避免歧义的缩写。②Don't Include Redundant Information In Names !,并不是名字越长越好,清晰没有歧义即可,如user_with_name_and_age,我们并不需要把一个对象的所有属性等冗余信息都体现在名字里。③Avoid Slang, Unclear Abbreviations & Disinformation !,避免使用俗语,语义不明的缩写,以及误导性的名字。
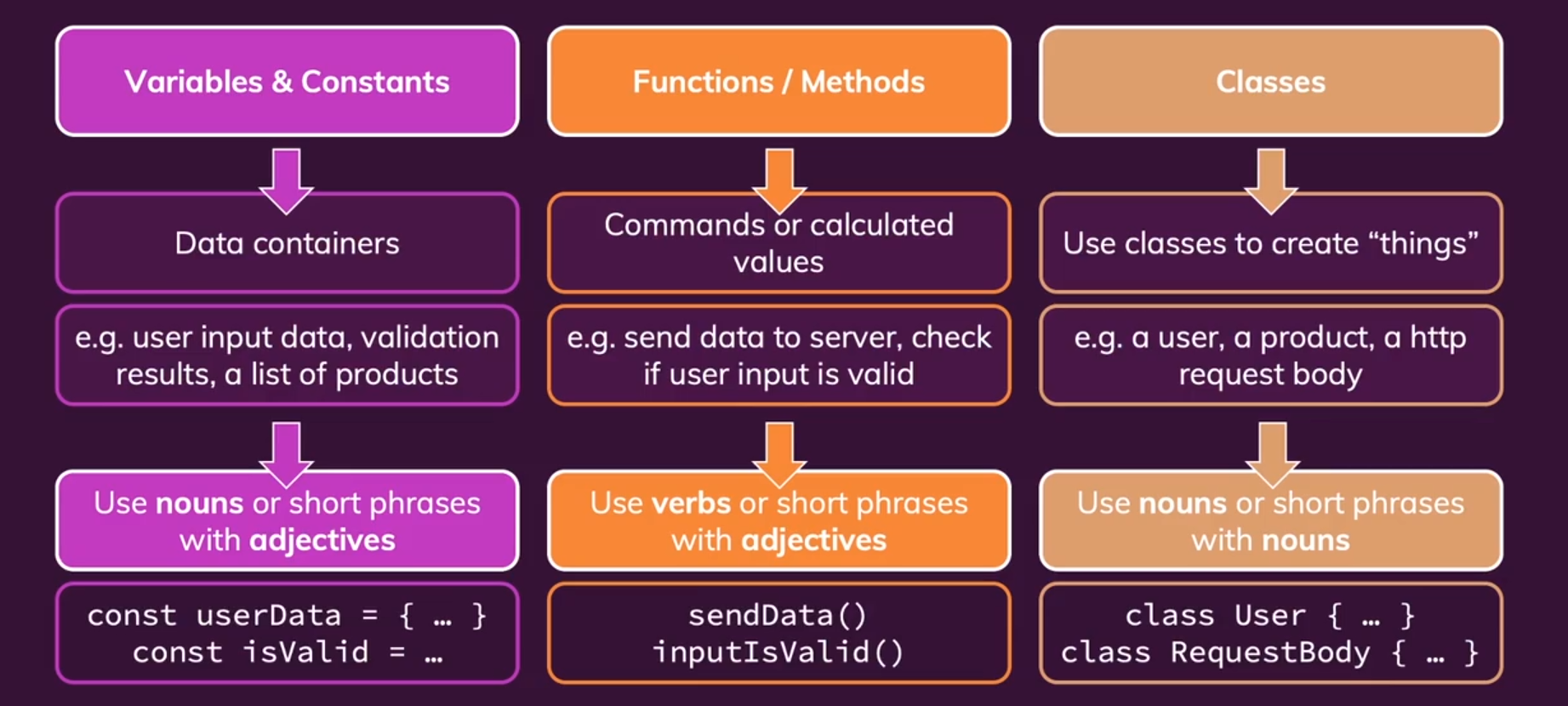
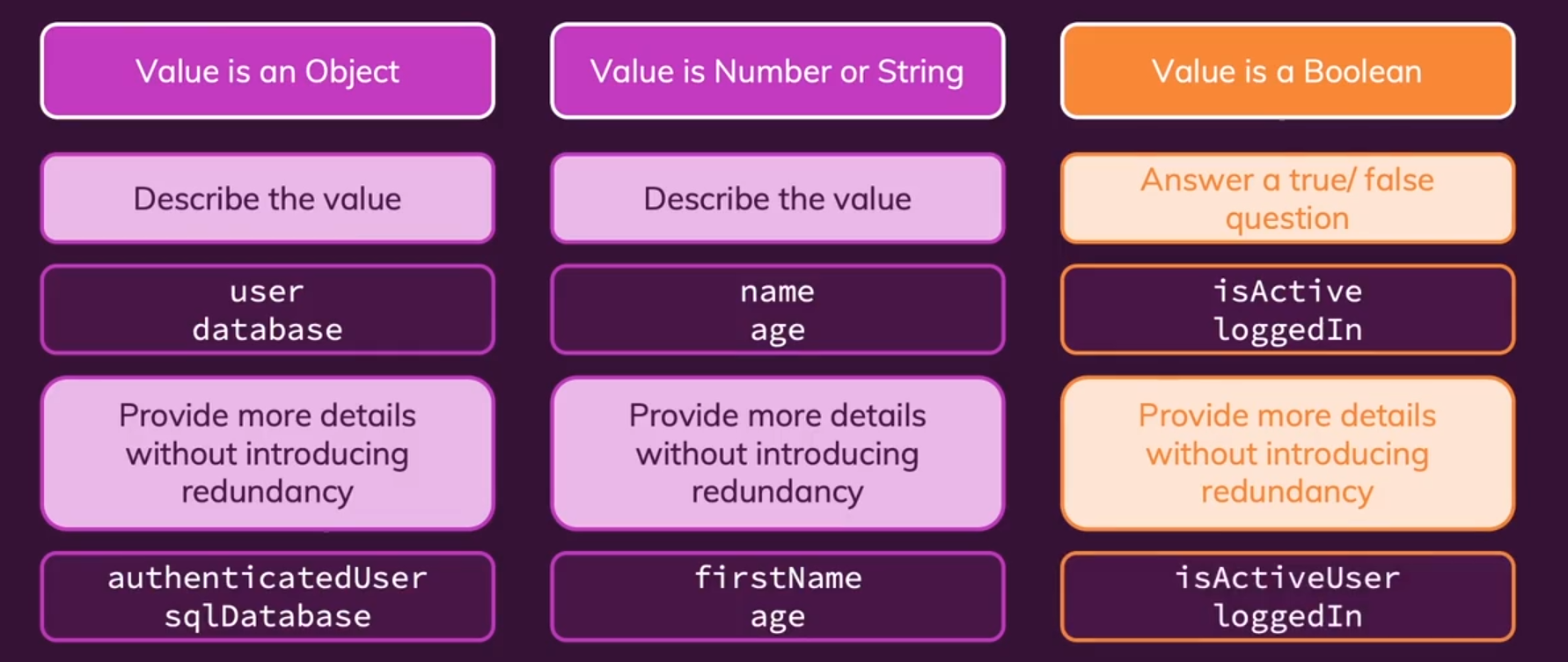
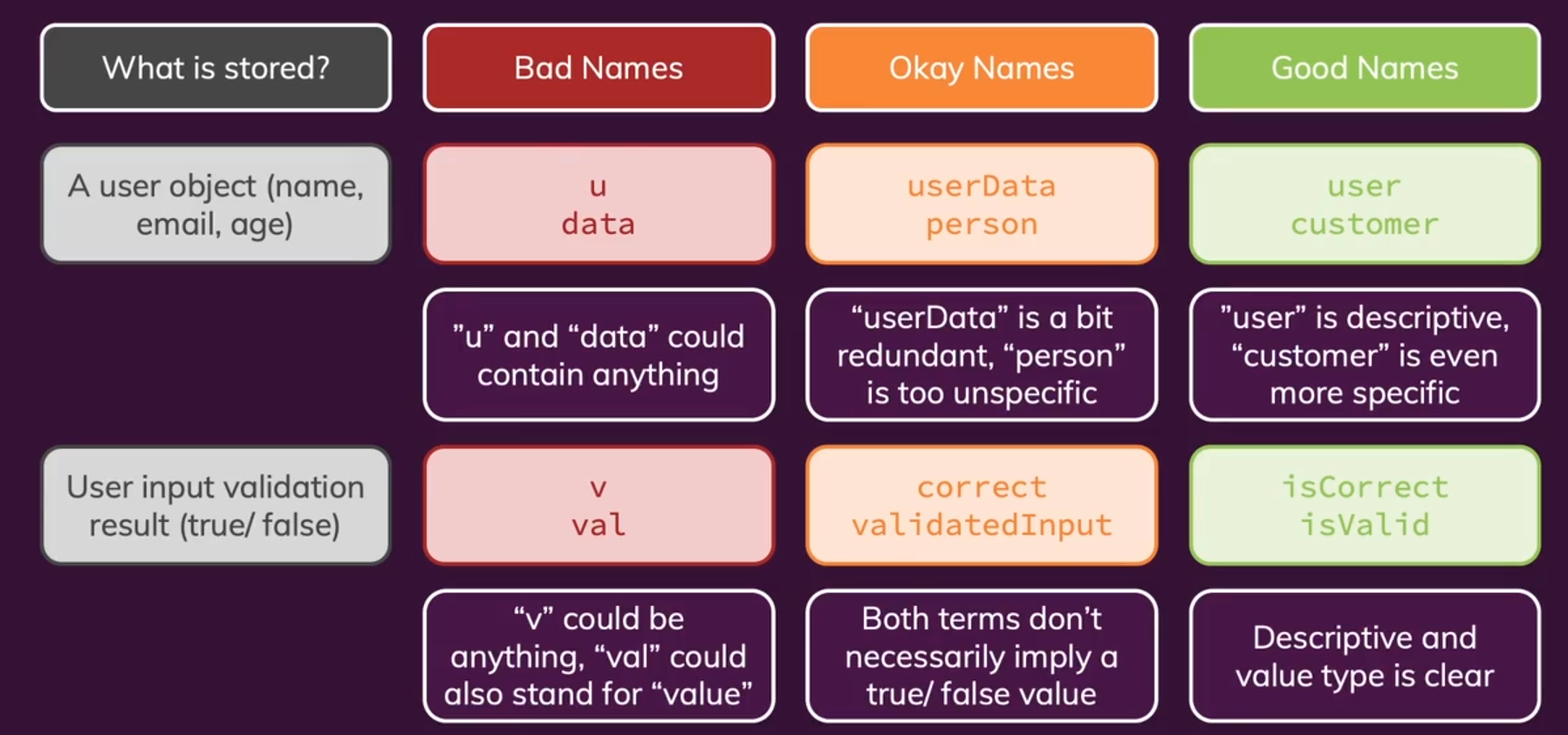
- 变量名&常量名&属性名:本质是数据容器,因为我们想强调的是存储在其中的数据内容,使用
名词(组合)或is+形容词短语。一般用下划线命名法。
# 下划线命名法
user_data = [...]
is_valid = True
总结:数据型变量可以直接使用名词(组合),布尔型变量通常使用is + 形容词短语,来指示True/False。
例子:
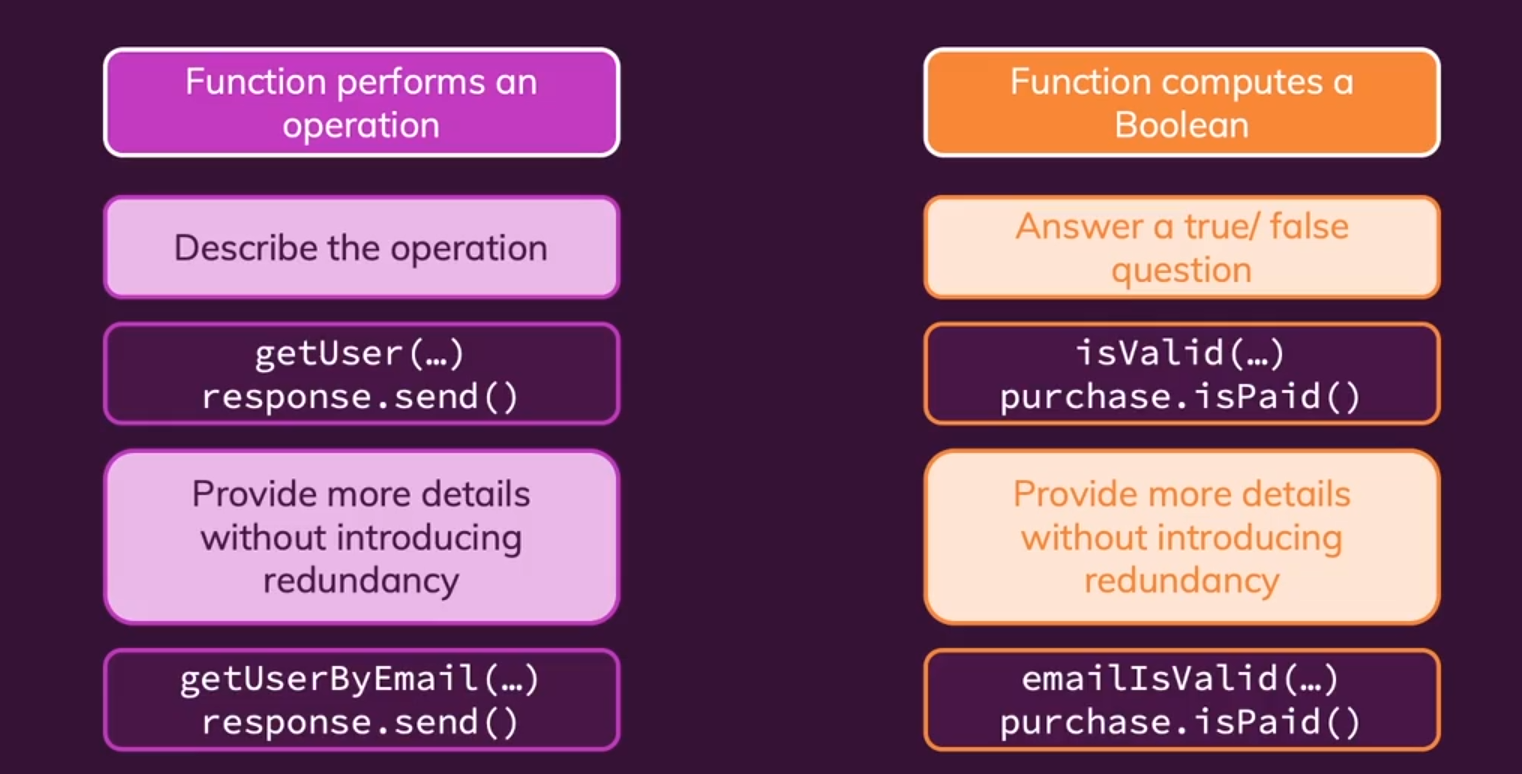
- 函数名:本质是命令指令,因为我们想强调的是函数执行的功能,使用
动词(+名词短语)或is+形容词短语。一般用下划线命名法。
# 下划线命名法
def send_data():
def is_input_valid():
总结:操作型函数可以直接使用动词(+名词短语),判断型函数则使用is + 形容词短语。
例子:
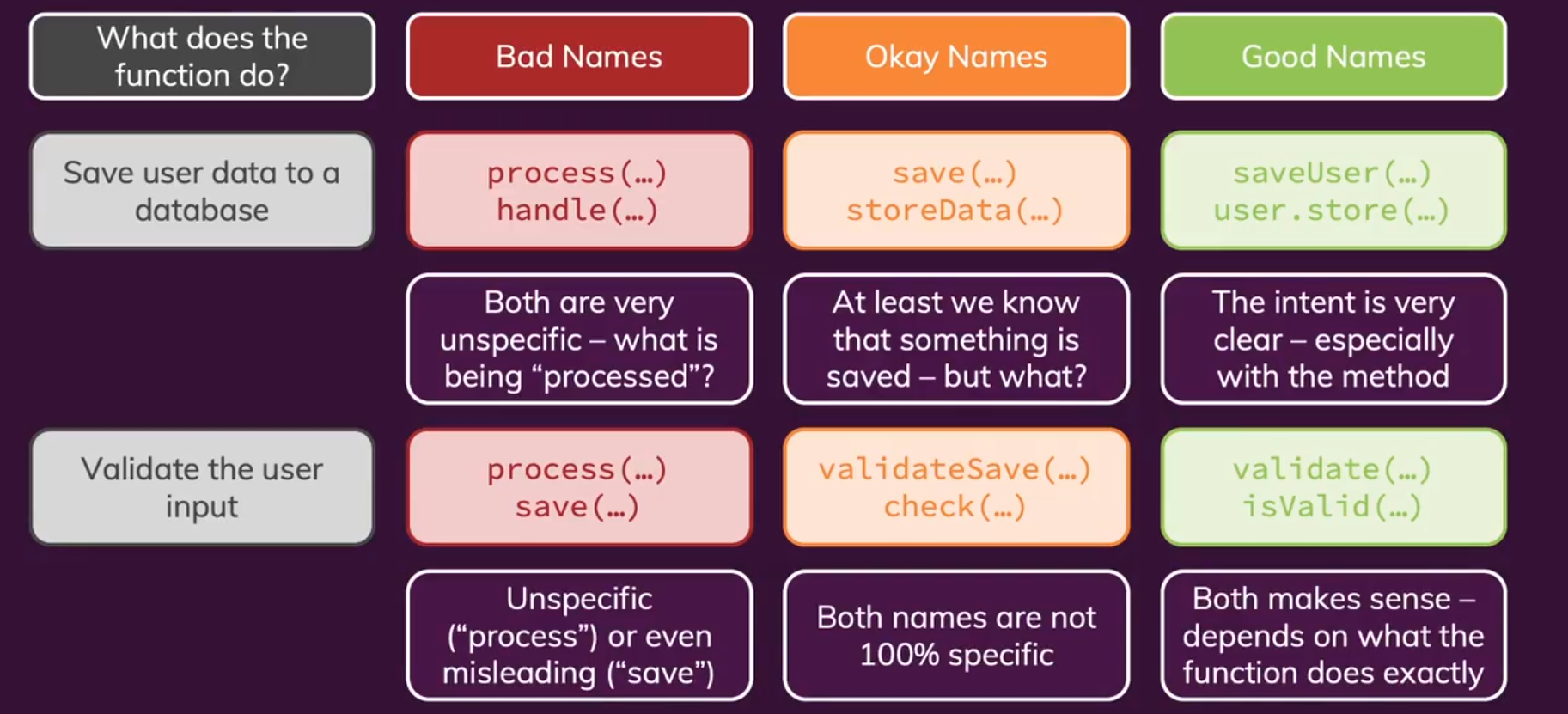
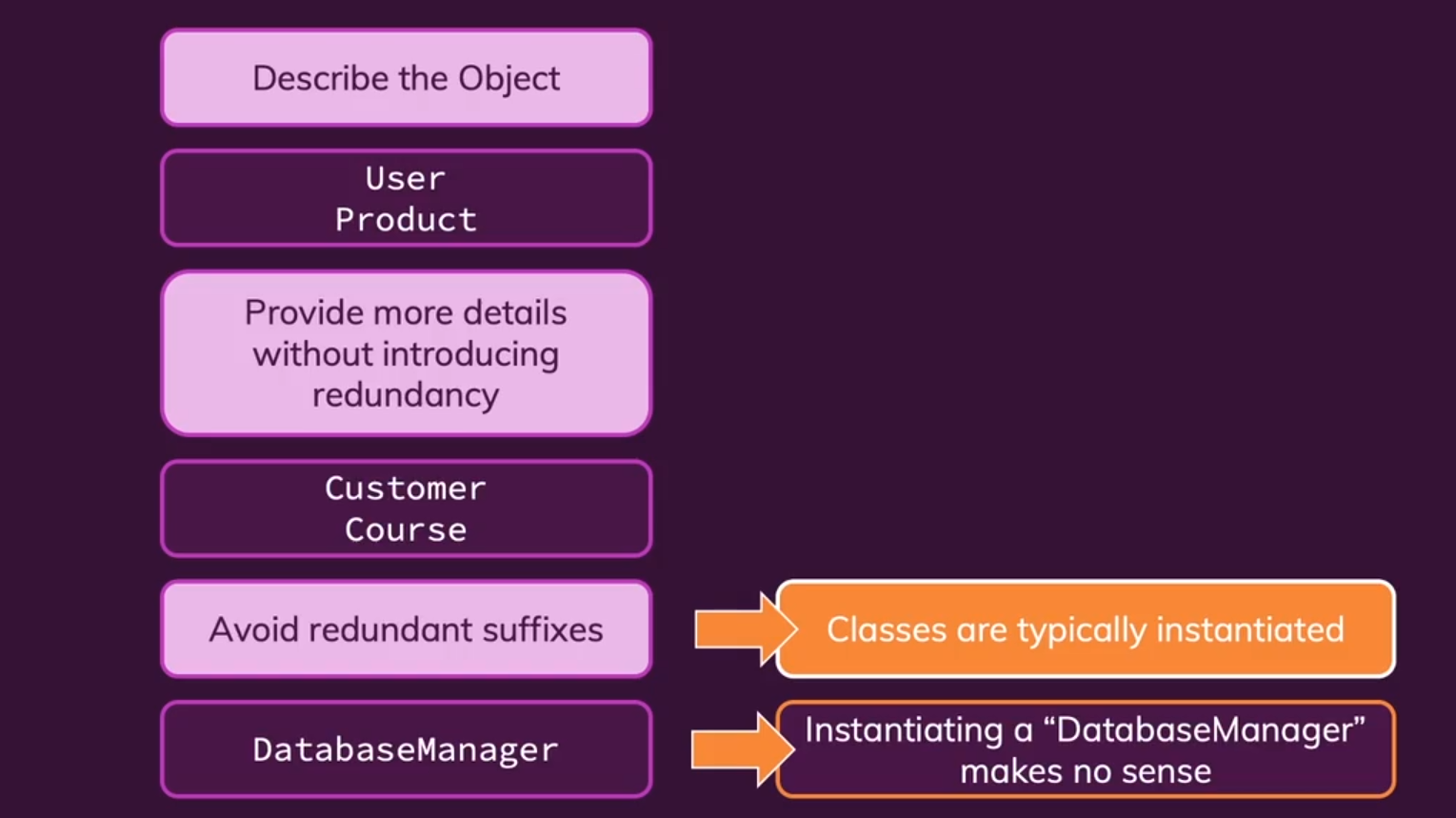
- 类名:本质是创建一个事物,因为我们想强调的是事物的类型,使用
名词或多个名词组合短语。一般用大驼峰命名法。
# 大驼峰命名法
class User:
class RequestBody:
总结:随着类从抽象到不断派生继承,我们可以逐渐将类名设置的越来越具体。
例子:
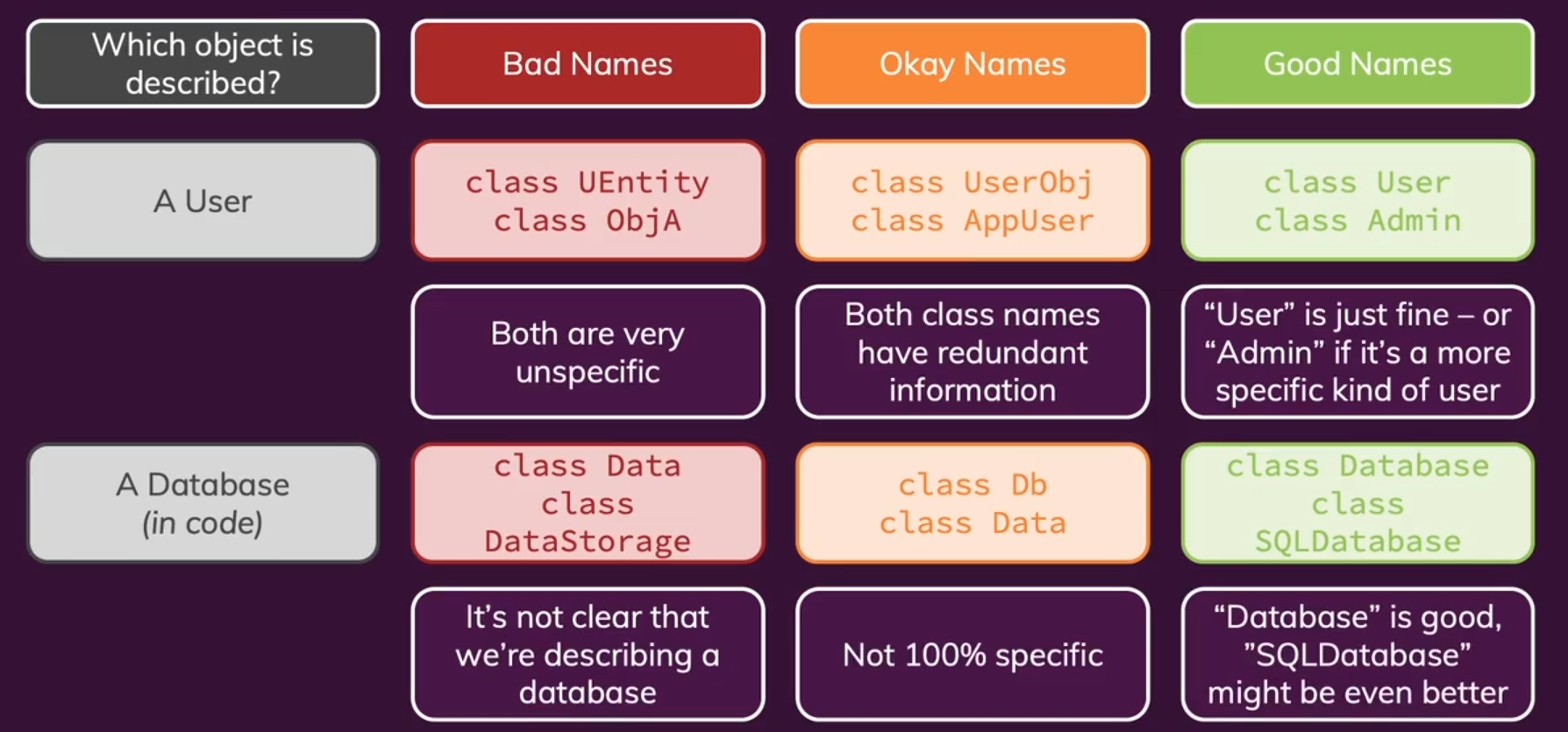
本节测试题(博客发表):将下面的dirty code中的对象的坏的名字重命名为好的名字,转换为clean code。
dirty code:
from datetime import datetime
class Entity:
def __init__(self, title, description, ymdhm):
self.title = title
self.description = description
self.ymdhm = ymdhm
def output(item):
print("Title: " + item.title)
print("Description: " + item.description)
print("Published: " + item.ymdhm)
summary = 'Clean Code Is Great!'
desc = 'Actually, writing Clean Code can be pretty fun. You\'ll see'
new_data = datetime.now()
publish = new_data.strftime('%Y-%m-%d %H:%M')
item = Entity(summary, desc, publish)
output(item)
clean_code:
from datetime import datetime
class BlogPost:
def __init__(self, title, description, publish_time):
self.title = title
self.description = description
self.publish_time = publish_time
def print(self):
print("Title: " + self.title)
print("Description: " + self.description)
print("Published: " + self.publish_time)
title = 'Clean Code Is Great!'
description = 'Actually, writing Clean Code can be pretty fun. You\'ll see'
now_time = datetime.now()
publish_time = now_time.strftime('%Y-%m-%d %H:%M')
blog_post = BlogPost(title, description, publish_time)
blog_post.print()
- 总结:

注释 Comments
核心思想:① Avoid Comments !,因为大多数注释都是冗余的,命名清晰的代码完全可以像文章一样阅读,除了某些特殊情况应该尽量避免注释,预期添加注释,不如优化代码命名Naming方式。② Avoid Divider or Block Marks !,当你很想使用####### Do Something ######这种分隔符或块标记,来显著地给代码分块时,说明一个文件中写了太多代码了,你应该考虑将代码拆开,而不是添加这些冗余的分隔符。③ Avoid Commented-Out Code !,永远不会使用的代码应该大胆删除,而不是将其永久性的注释掉。
- 法律信息Legal Information:在文件顶部的
Legal Information通常是被要求具有的,而且在文件顶部不影响代码的阅读。
# (c) Maximilian Schwarzmuller Academind GmbH
# Created in 2020
- 代码表意不清:当我们使用
正则表达式或者计算数学公式时,无法使用合适的命名来清晰的表达代码的含义,可以通过注释来进一步解释。
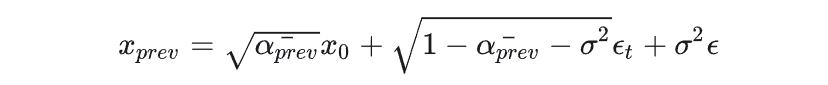
# compute epsilon
eps = self.model(x_t, t - 1)
# compute x_0 for first item
x_0 = self.predict_xstart_from_eps(x_t, t - 1, eps)
if self.clip_denoised:
x_0 = torch.clamp(x_0, min=-1., max=1.) # 裁剪梯度
# compute sigma for thrid item
sigma_t = self.ddim_eta * torch.sqrt(
(1 - alpha_cumprod_t_prev) / (1 - alpha_cumprod_t) * (1 - alpha_cumprod_t / alpha_cumprod_t_prev))
# compute pred_dir_xt for second item
pred_dir_xt = torch.sqrt(1 - alpha_cumprod_t_prev - sigma_t ** 2) * eps
x_prev = torch.sqrt(alpha_cumprod_t_prev) * x_0 + pred_dir_xt + sigma_t ** 2 * torch.randn_like(x_t)
- 警告信息Warning:提示如何正确的使用代码,否则可能会报错。
# only run in fp32, not suppurt fp16
weight_dtype = 'fp32'
- 待做TODO:在多人协作编写的大型项目中,你需要在未完成的部分写上TODO note,表示待办事项,方便其他合作者一起编写,
待实现的功能在TODO中会简略说明。
def register_attention(model):
# TODO: Needs to be implemented register attention for UNet
- 待维护FIXME:如果代码中有该标识,说明代码存在缺陷,需要修复,甚至代码是错误的,不能工作,
如何修正会在FIXME中简略说明。
# FIXME: Don't sure deepcopy is necessary
latents = copy.deepcopy(latents.detch())
代码格式化 Code Formatting
核心思想:代码的格式应该像文章一样,可以从上倒下的流畅阅读,该缩进的缩进,该分段的分段(根据语义),没有太多的跳跃。①Splitting files with multiple concepts into multiple files,对于一个多大的文件(一个文件定义了很多类)将代码按照语义划分到不同的文件中,尽量保证每个文件只用一个类,或者一个种类的几个类。
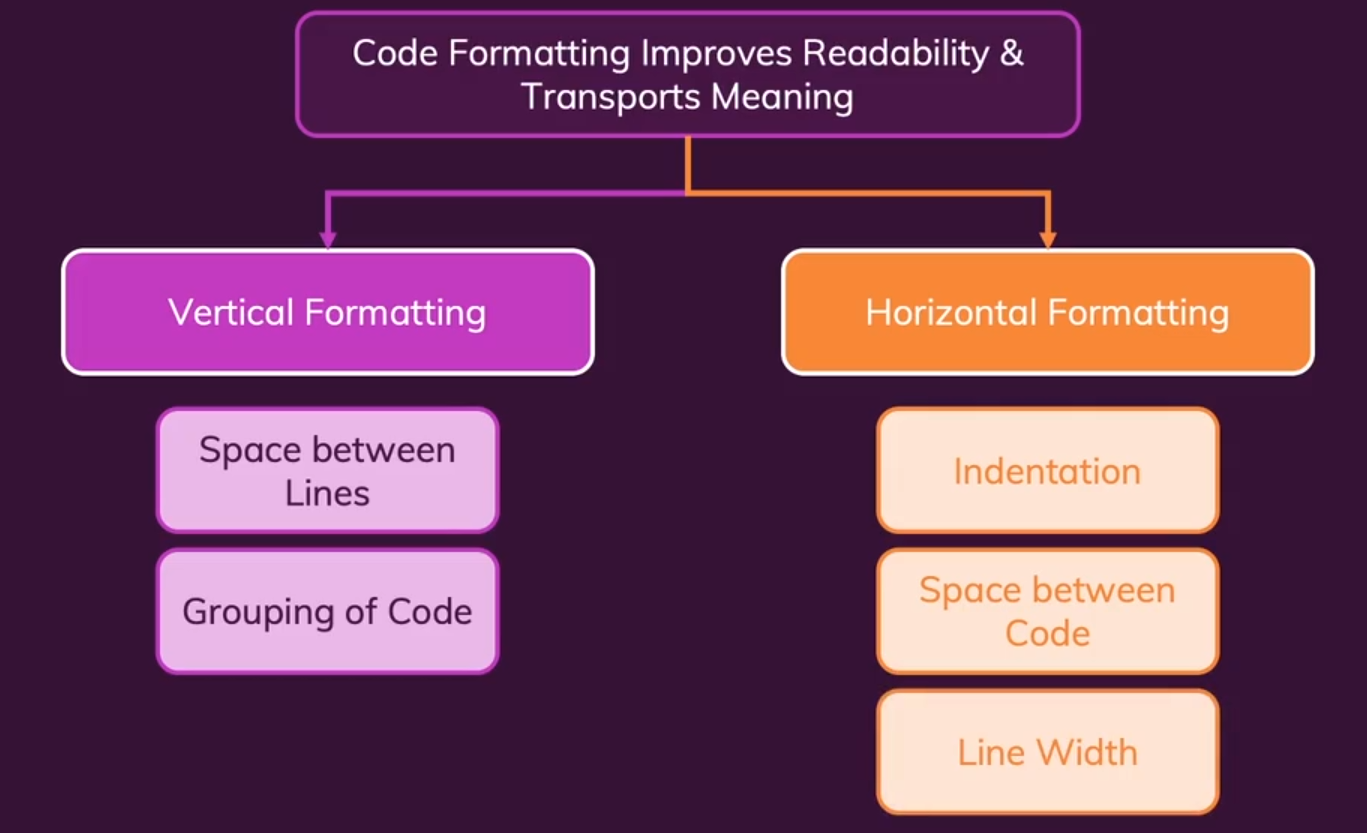
- 垂直格式化:①
不同语义的代码块用行间隔blink lines,而相似语义的代码不应该被插入行间隔。②相关联的代码应该彼此靠近,比如一个类内的不同方法彼此调用,我们应该按照他们的先后执行顺序与相互调用关系,来调整每个类方法的位置,尽量让先调用的方法在上面,紧接着被调用的方法。这样可以避免混乱的跳转。
class Excute_Order:
def last(self):
print("Last")
def next(self):
print("Next")
self.last()
def start(self):
print("Start")
self.next()
excute_order = Excute_Order()
excute_order.start()
- 水平格式化:①缩进Indendation是Python必须的语法。②代码间的空格可以使代码看起来更加简洁清晰。③保证每行代码不要太长,可以使用换行符
\来续行。
sigma_t = self.ddim_eta * torch.sqrt( \
(1 - alpha_cumprod_t_prev) / \
(1 - alpha_cumprod_t) * \
(1 - alpha_cumprod_t / alpha_cumprod_t_prev))
- 总结:

函数 Functions
核心思想:①Calling and Working of functions should be readable and easy !,函数的调用和本体执行部分都应该易于理解和简洁,函数调用应当具有可读性,函数本体应当简洁,不要太长。
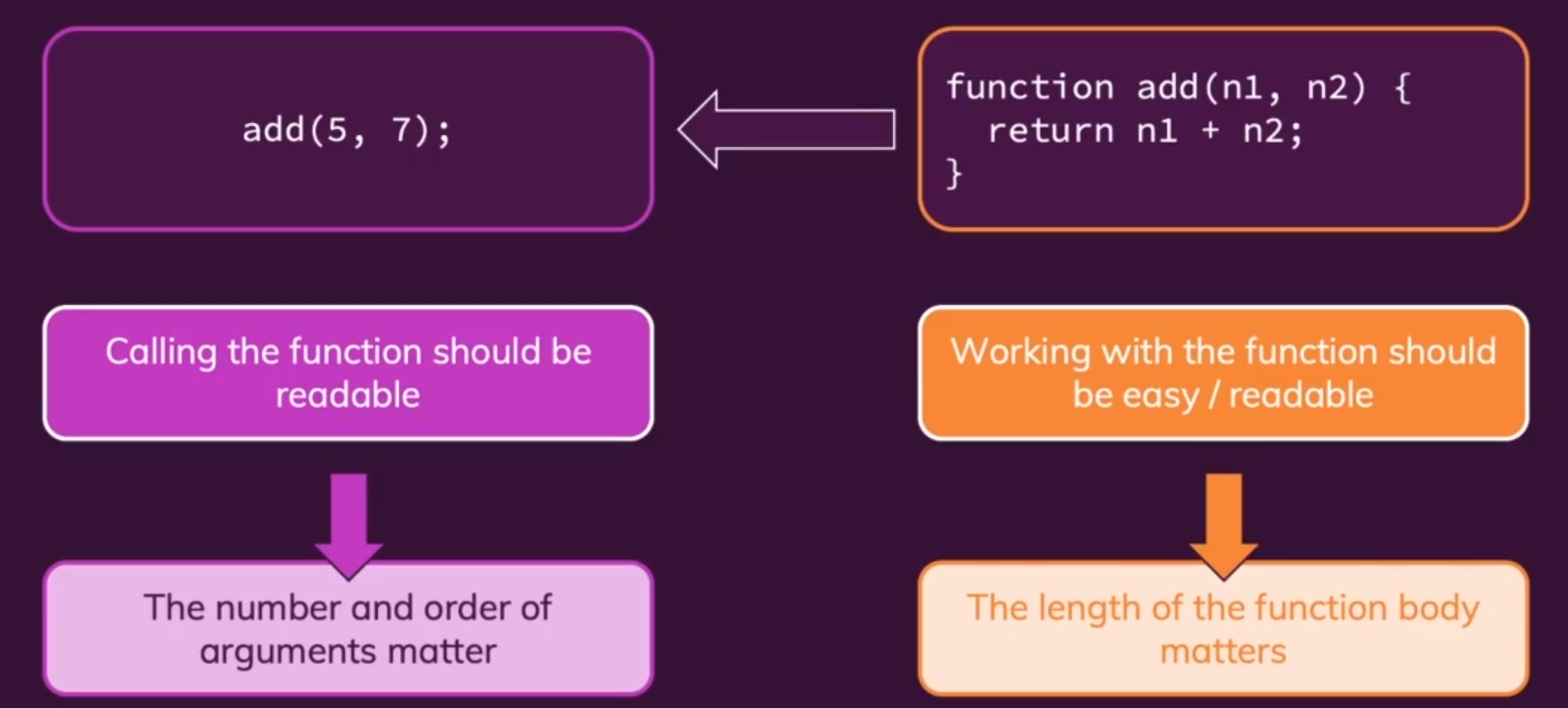
- 输入参数Input Parameters:
Minimize the number of parameters !,函数需要传入的参数越多,这个函数就越难以调用,函数的可读性就会下降。函数传入的参数个数应当适中(一般小于等于3个),不能增加用户的理解负担。
例子:函数的参数个数与调用的难易程度
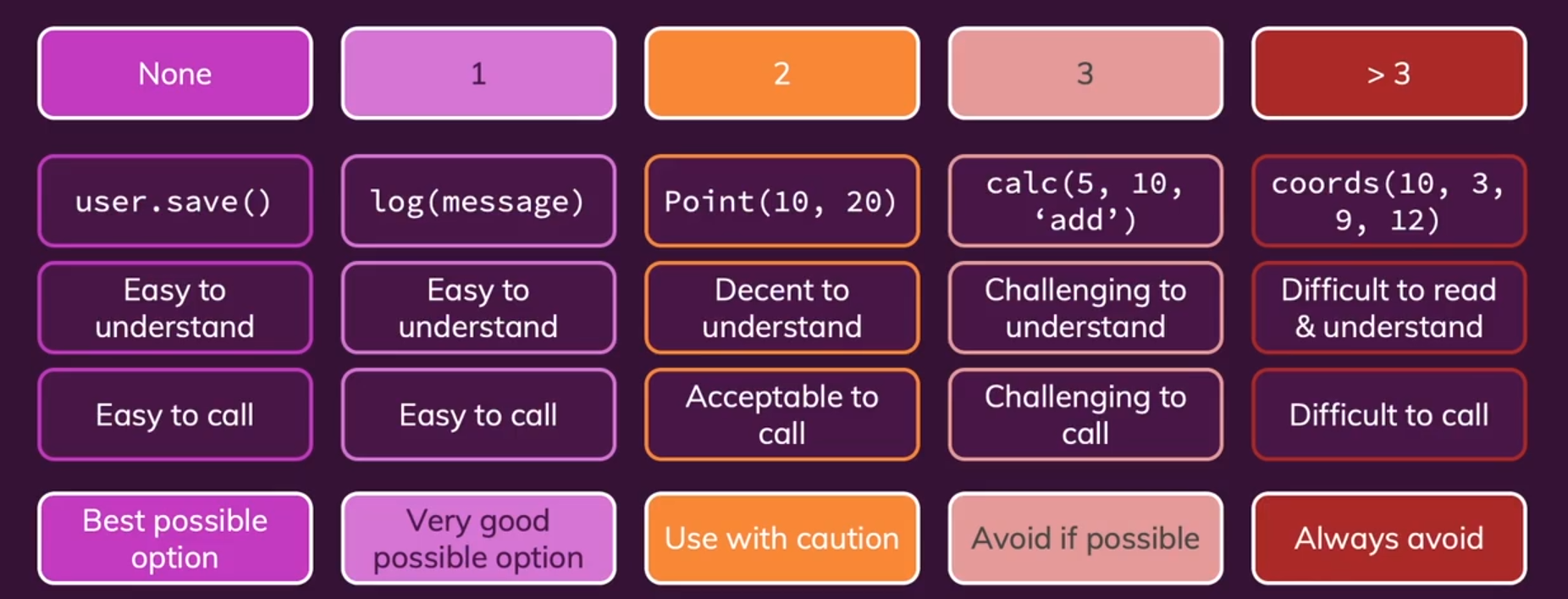
2个参数的例子:我们应当尽量避免is_error这种bool型的参数,可以重构函数,将其划分为两个不同功能的函数:
from warnings import warn
def log(message, is_error):
if is_error:
warn(message)
else:
print(message)
log("Hello, World!", False)
log("This is an error message", True)
def log(message):
print(message)
def log_error(error_message):
warn(error_message)
log("Hello, World!")
log_error("This is an error message")
多个参数的例子:当我们不得不传入多个参数时,不要一个一个的无结构化传入(参数的名称和顺序会变得混乱),可以将多个参数重构打包为一个结构化容器参数,例如一个对象objec或一个字典dict。
class User:
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
user = User('张三', 30, '男')
class User:
def __init__(self, user_data:dict):
self.name = user_data['name']
self.age = user_data['age']
self.sex = user_data['sex']
user = User({'name': '张三', 'age': 30, 'sex': '男'})
同时也应当注意*args和**kwargs的使用:*args将无名参数value打包为一个tuple元组使用args[i]访问,**kwargs将有名参数key=value打包为一个dict字典使用kwargs['key']
class User:
def __init__(self, *args, **kwargs):
self.user_num = args[0]
self.name = kwargs['name']
self.age = kwargs['age']
self.gender = kwargs['gender']
self.address = kwargs['address']
user = User(1, name='John', age=20, gender='Male', address='New York')
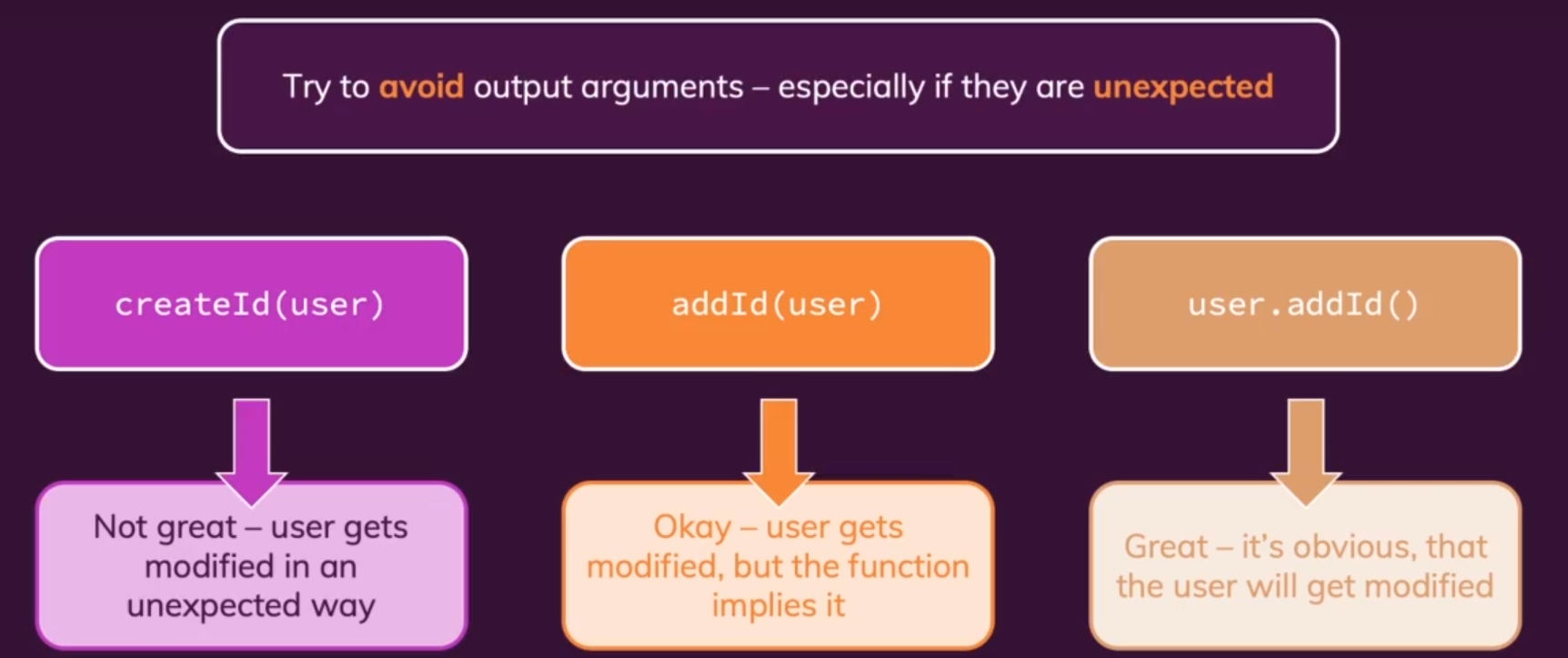
- 输出参数Oputut Parameters:我们应该
避免输出不必要的参数。如下给user添加id的操作。
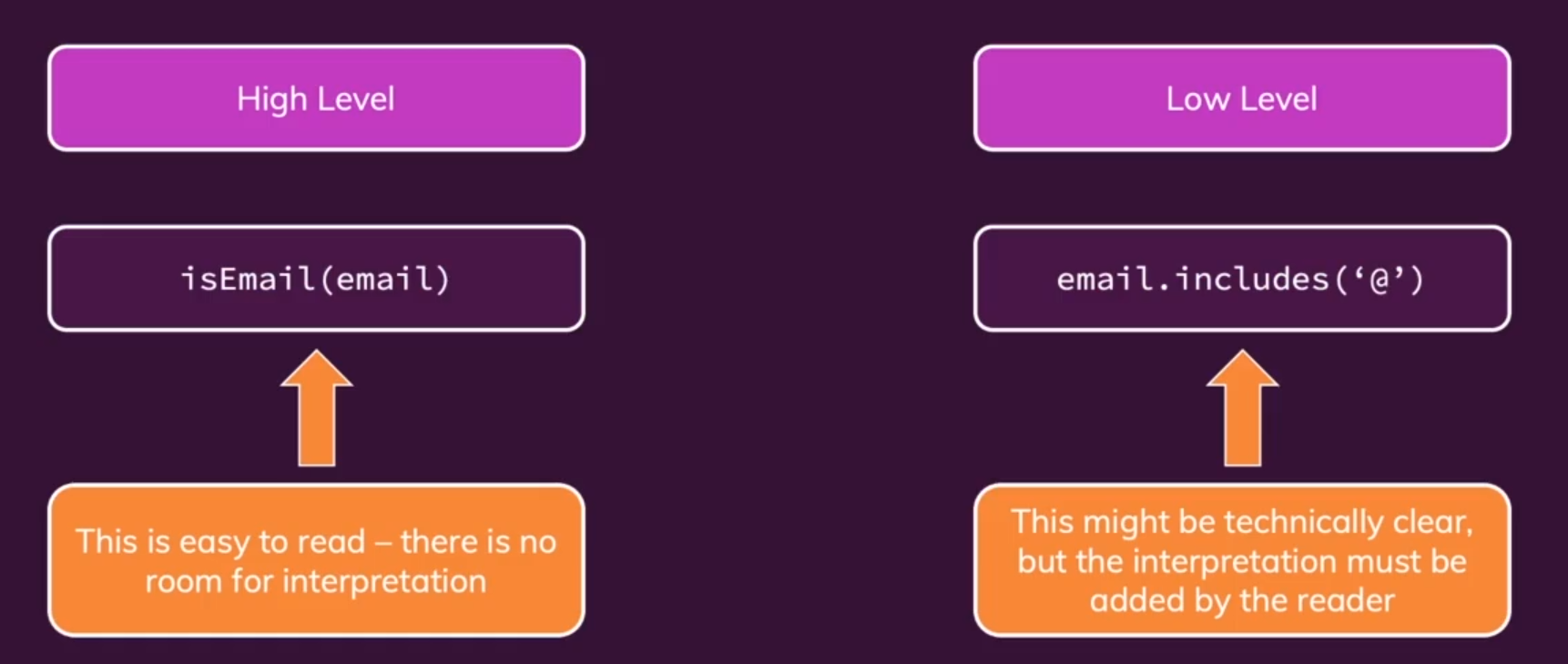
- 抽象程度Abstract Level:抽象程度分为
heigh-level和low-level的代码,heigh-level代码是调用我们自己编写的代码完成一件事情,如email.include('@'),low-level的代码是直接使用原始代码或三方库的API完成一件事情,如isEmail(mail)。Don't Mix Levels of Abstract !,在一个函数中不要多种层次的代码混用,尽量将low-level的操作封装为high-level的代码,然后在函数中进行调用,这样我们就可以像阅读文章一样读代码了,清晰明了。

heigh-level 和 low-level 的例子:
- 函数长度Length:
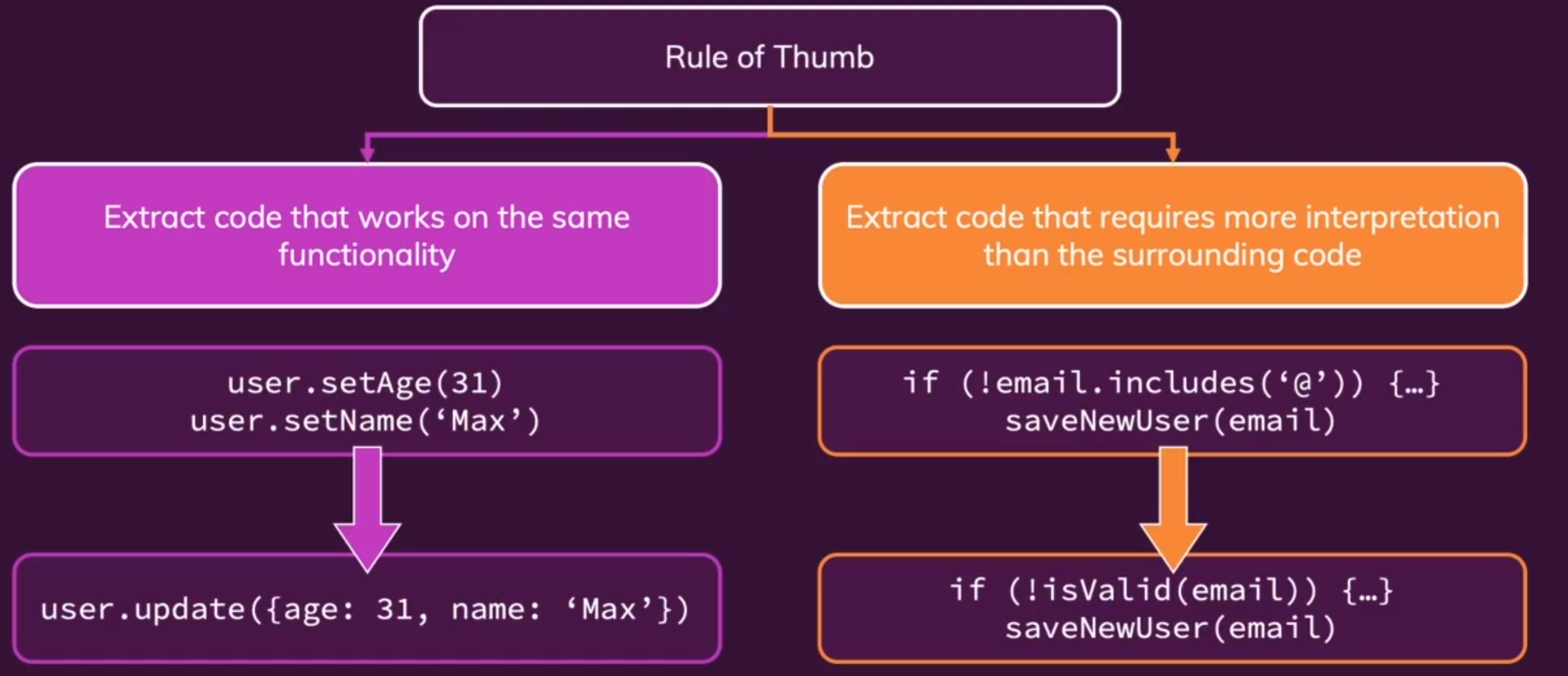
Function should be small !,函数体应当简洁,如果过长需要划分为多个函数。当你想用注释# 1. do something、# 2. do something来标记或者划分代码时,说明你的函数过长了,可以按照不同功能的代码块重新组建子函数(子函数是相当短小简洁的,每个子函数只完成概念层面的一件事情,封装好的子函数可以在很多地方重用)。
划分函数的两个法则:①当我们可以提取功能相似的代码,将其封装为单个操作时。②因为抽象程度Abstract Level不一致,某部分代码比周围的代码需要更多注释时。
本节测试题(创建数据库用户):优化dirty code的函数,转换为clean code。
dirty code:
from warnings import warn
database = []
def create_database_user(email, password):
if ((not email) or ('@' not in email) or (not password)): # low level
warn('Invalid email or password') # low level
user = {'email': email, 'password': password} # low level
database.append(user) # low level
create_database_user('test@test.com', 'test')
clean code:
from warnings import warn
database = []
def is_input_invalid(email, password):
if (not email) or ('@' not in email) or (not password):
warn('Invalid email or password')
def save_user(email, password):
user = {'email': email, 'password': password}
database.append(user)
def create_database_user(email, password):
is_input_invalid(email, password)
save_user(email, password)
create_database_user('test@test.com', 'test')
- 可重用性Reusablility:
DRY: Don't repeat yourself !,不要重复!要重用!相同的代码复制粘贴在很多地方重用会导致修改时要改很多地方,而将简单的功能封装为一个子函数,就可以在任意的地方调用。
dirty code:
from warnings import warn
database = []
def is_input_invalid(email, password):
if (not email) or ('@' not in email) or (not password) or (password.strip() == ''):
warn('Invalid email or password')
def create_database_user(email, password):
is_input_invalid(email, password)
# TODO: save user data
def create_support_channel(email):
if (not email) or ('@' not in email):
warn('Invalid email')
# TODO: save support channel
clean code:
from warnings import warn
database = []
def is_email_invalid(email):
if (not email) or ('@' not in email):
warn('Invalid email')
def is_password_invalid(password):
if (not password) or (password.strip() == ''):
warn('Invalid password')
def create_database_user(email, password):
is_email_invalid(email)
is_password_invalid(password)
# TODO: save user data
def create_support_channel(email):
is_email_invalid(email)
# TODO: save support channel
- 合理划分:
Split Functions Reasonably !,过度细化的划分函数会造成碎片化,当我们想要划分函数时,思考划分后是否会增加代码的可读性,同时保证代码足够简洁。
例如对上述例子中的warn函数再封装一层log_error是没有必要的,因为原始代码已经足够简洁,再封装一层做的也只是ReName重命名操作:
warn('Invalid email')
def log_error(message):
warn(message)
- 单元测试Unit Testing:当我们写完一个函数时,可以
模拟函数输入来进行单元测试。如果我们发现我们不能很简单的测试我们的函数,说明这个函数可能需要被划分为多个。
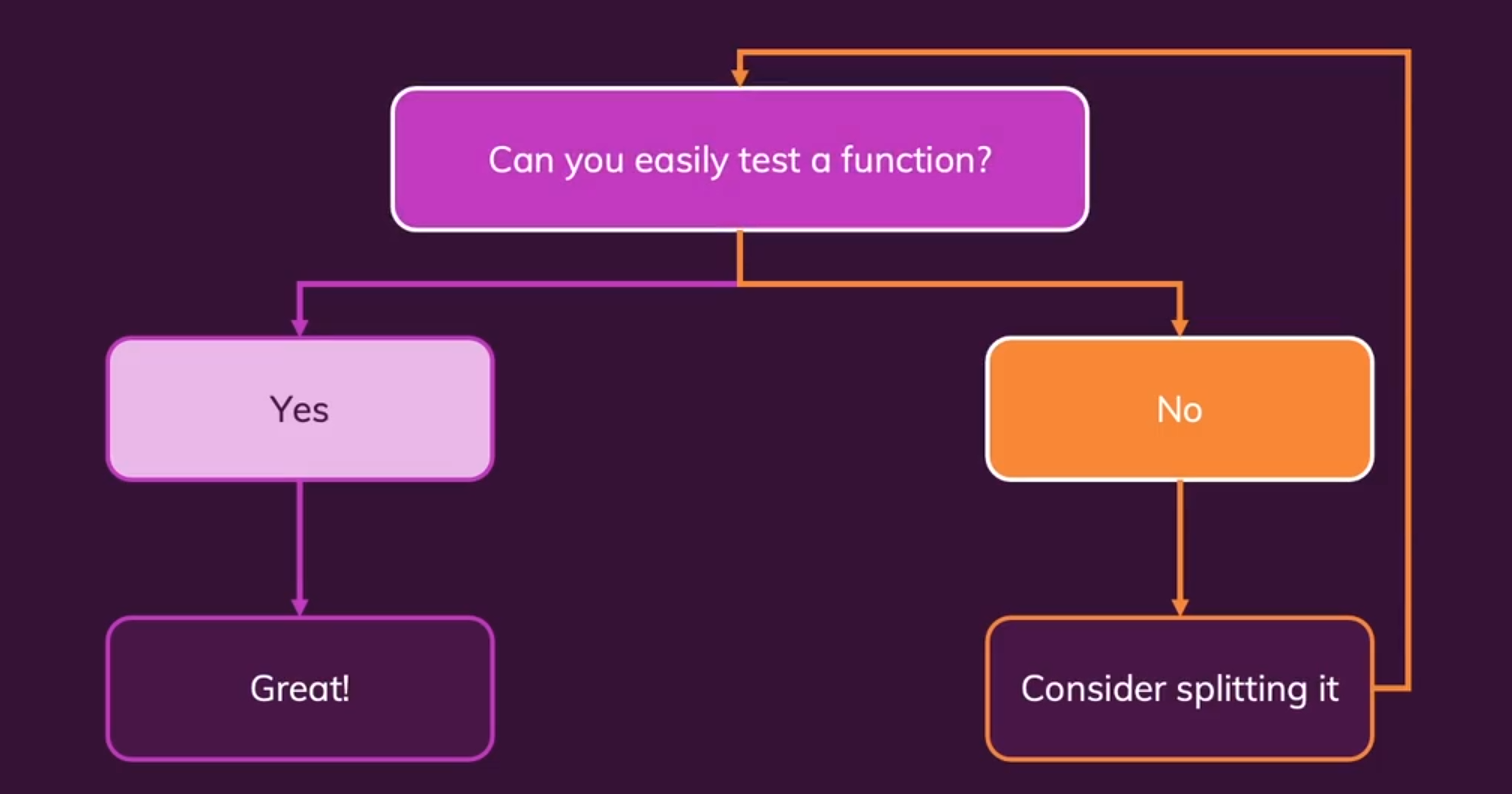
- 总结:

控制结构 Control Structures
核心思想:①Avoid deeply nested control structure !,我们应当避免深度嵌套的控制结果。
- 用
警卫Guard进行早退出:利用 if 构造Guard,当Guard条件不满足的时候直接return进行早退出,这样可以避免不必要的嵌套,同时减少不必要的代码运行。
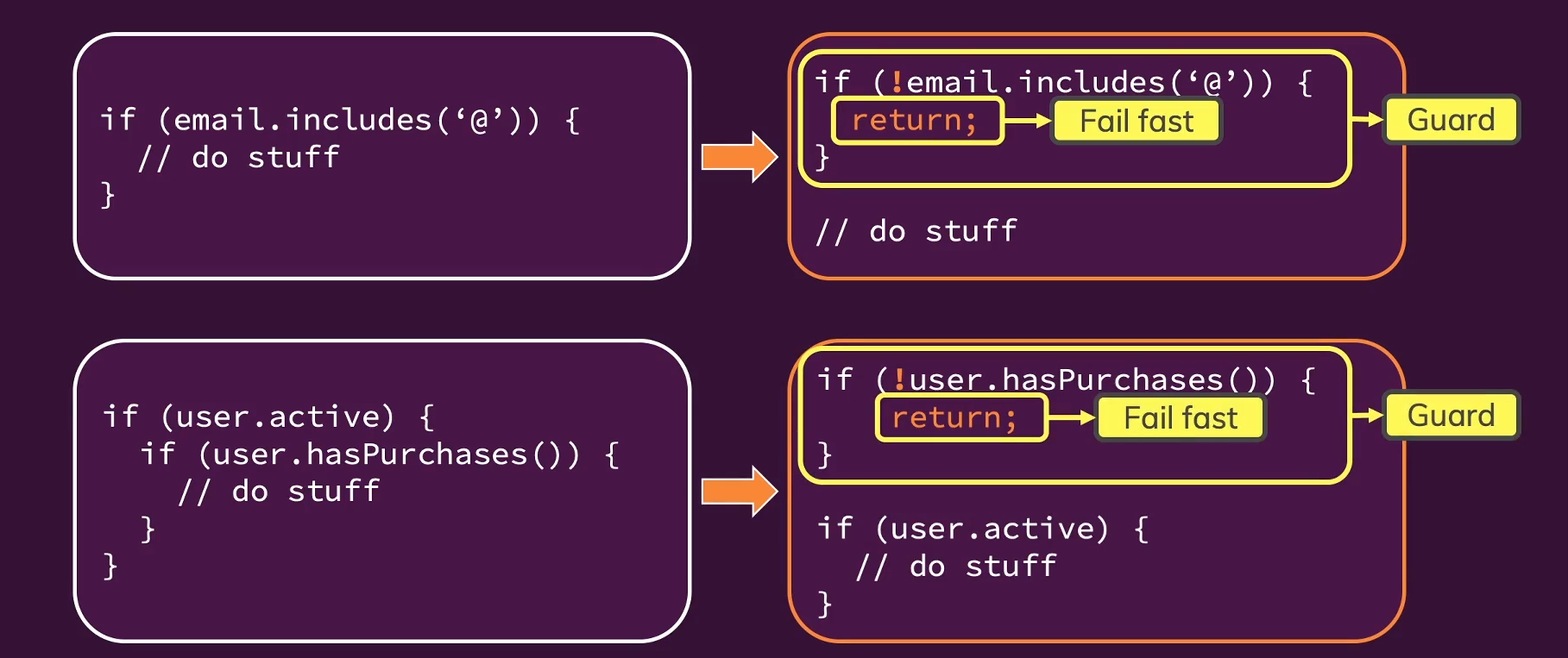
dirty code:
def deep_if(x):
if x > 10:
if x > 20:
if x > 30:
if x > 40:
print("x > 40")
else:
print("30 <= x <= 40")
else:
print("20 <= x <= 30")
else:
print("10 <= x <= 20")
else:
print("x <= 10")
print(deep_if(50))
clean code:
def deep_if_guard(x):
if x <= 10:
print("x <= 10")
return
if x <= 20:
print("10 <= x <= 20")
return
if x <= 30:
print("20 <= x <= 30")
return
print("x > 30")
print(deep_if_guard(50))
- 使用正向判断Postive Checks:多用
if is_empty(),而不是if is_not_empty(),因为正向的判断函数更加易于理解。
def login(user_id, password):
if (not user_id is '') and (not password is ''):
# do login
pass
return True
else:
return False
def is_empty(str):
return True if str is '' else False
def login(user_id, password):
if is_empty(user_id) or is_empty(password): # guard
return False # early return
# do login
return True
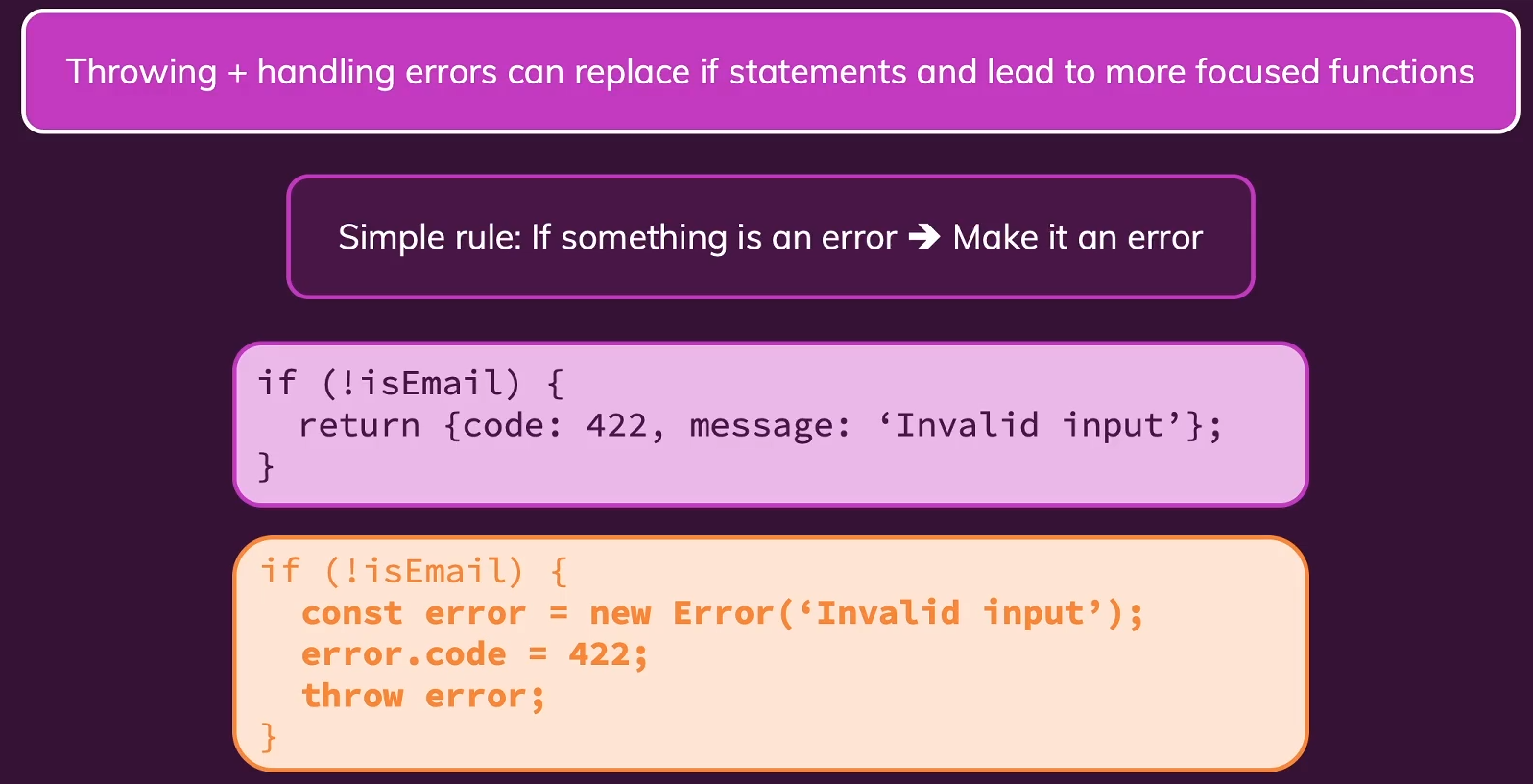
- 错误处理Errors Handling:
Work with error !,大胆拥抱Errors,要学会合理地使用try: ... \ except Exception as e: ...进行错误处理,而不是一味的嵌套if-else,合理的Throwing和Handling errors可以替代无用的if,让我们专注函数的功能实现。
from warnings import warn
try:
print(1 // 0)
except Exception as e:
print(e) # 不触发异常,正常执行,只打印Error信息
print("end print")
warn("e") # 不触发异常,只出发警告UserWarning
print("end warn")
raise e # 触发异常,终止运行
integer division or modulo by zero
end print
end warn
C:\Users\Lenovo\AppData\Local\Temp\ipykernel_21700\687186242.py:7: UserWarning: e
warn("e") # 不触发异常,只出发警告warn
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
Cell In[13], line 9
7 warn("e") # 不触发异常,只出发警告warn
8 print("end warn")
----> 9 raise e # 触发异常,终端运行
10 print("end error")
Cell In[13], line 3
1 from warnings import warn
2 try:
----> 3 print(1 // 0)
4 except Exception as e:
5 print(e) # 不触发异常,正常执行,只打印error信息
ZeroDivisionError: integer division or modulo by zero
- 使用工厂Factory和多态Polymorphism:
工厂函数用于创建一类产品(是一种设计模式的思维),多态是类与对象中相同函数可以传入不同的参数。两者都在说:我们使用相同的函数接口,在不同的环境或者条件下,创建不同的对象,或调用不同的功能。
dirty code:
def process_by_method(transaction):
if transaction.method == "CREDIT_CARD":
processCreditCardTransaction(transaction)
elif transaction.method == "PAYPAL":
processPaypalTransaction(transaction)
elif transaction.method == "CASH":
processCashTransaction(transaction)
clean code:
def get_transaction_processor(transaction):
if transaction.method == "CREDIT_CARD":
return processCreditCardTransaction
elif transaction.method == "PAYPAL":
return processPaypalTransaction
elif transaction.method == "CASH":
return processCashTransaction
def process_by_method(transaction):
processor = get_transaction_processor(transaction)
processor(transaction)
- 总结:

类与对象 Class&Object
- 总结:

设计模式 Design Patterns
鉴于Python的特征,有些经典设计模式在Python中并不需要,以不可见的方式提供了这些模式:Python并不适用工厂模式!而其他设计模式也不应强行在解决方案中使用设计模式,而应通过演进、重构和改善解决方案,让设计模式浮现出来。
不用 工厂模式:由于Python在类、函数和自定义对象没有什么不同,都可以作为参数进行传递、被赋值,只需要定义一个创建对象的函数,通过参数将要创建的对象所属的类传递给它。
Python比较适用的模式:
- 单态模式:可以有很多属于常规对象的实例,而无须关心它们是否是单例。其优点是这些对象包含的信息将以完全透明的方式同步。
- 适配器模式:也被称为包装器模式,解决适应多个不兼容对象的接口问题
- 装饰器模式:无须使用继承就能动态地扩展对象的功能
- 门面模式:适用于需要交互的多个对象之间存在多对多关系的情形,不仅适用于类和对象,还适用于包
- 职责链模式:适用合适的事件对象来处理数据,通过封装在类中的方法来分配职责
- 模板方法模式:在类层次结构中定义某种行为,这个层次结构中的所有类都使用相同的模板,很容易保留多态性
- 命令模式:将请求执行操作和实际执行操作的时间分开,将客户端发出的请求与接收方分开
- 状态模式:使域问题中的概念成为一个显式的对象,而不仅仅是一个边值
- 空对象模式:函数和方法必须返回类型始终一致的对象
Clean Architecture
- 关注点分离:组件尽可能小,高内聚和低耦合,让不同的组件承担不同的职责
- 找出可能被重用多次的通用逻辑,并将其放在一个Python包中
- 采用微服务架构,将应用程序分成多个小型服务
- 将不同职责分配给不同的服务,将其封装在可被众多其他服务调用的微服务中
- 抽象:代码必须有很强的表达力,并使用正确的抽象来揭示核心问题的解决方案
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CommonJS规范相关知识点
- 不是小米SU7买不起,而是17.58万的银河E8更有性价比
- 【JavaSE】Java入门九(异常详解)
- 【机器学习 | 假设检验系列】假设检验系列—卡方检验(详细案例,数学公式原理推导),最常被忽视得假设检验确定不来看看?
- 手写数组去重
- Ansible的Jinja test
- GBASE南大通用-Command 构 造 函 数 (String, GBaseConnection, GBaseTransaction)
- 旧衣回收小程序,降低企业商家成本,推动行业发展!
- 基于机器视觉的害虫种类及计数检测研究-人工智能项目-附代码
- 智能执法记录仪、智能安全帽在建筑工程监理行业的应用,可视化监管、人员考勤、劳务实名制、与BIM系统的对接融合