STL第二讲
第二讲
视频标准库源码版本:gnu c++ 2.9.1/4.9/Visual C++
OOP vs GP
GP是将datas与methods分开,OOP相反;
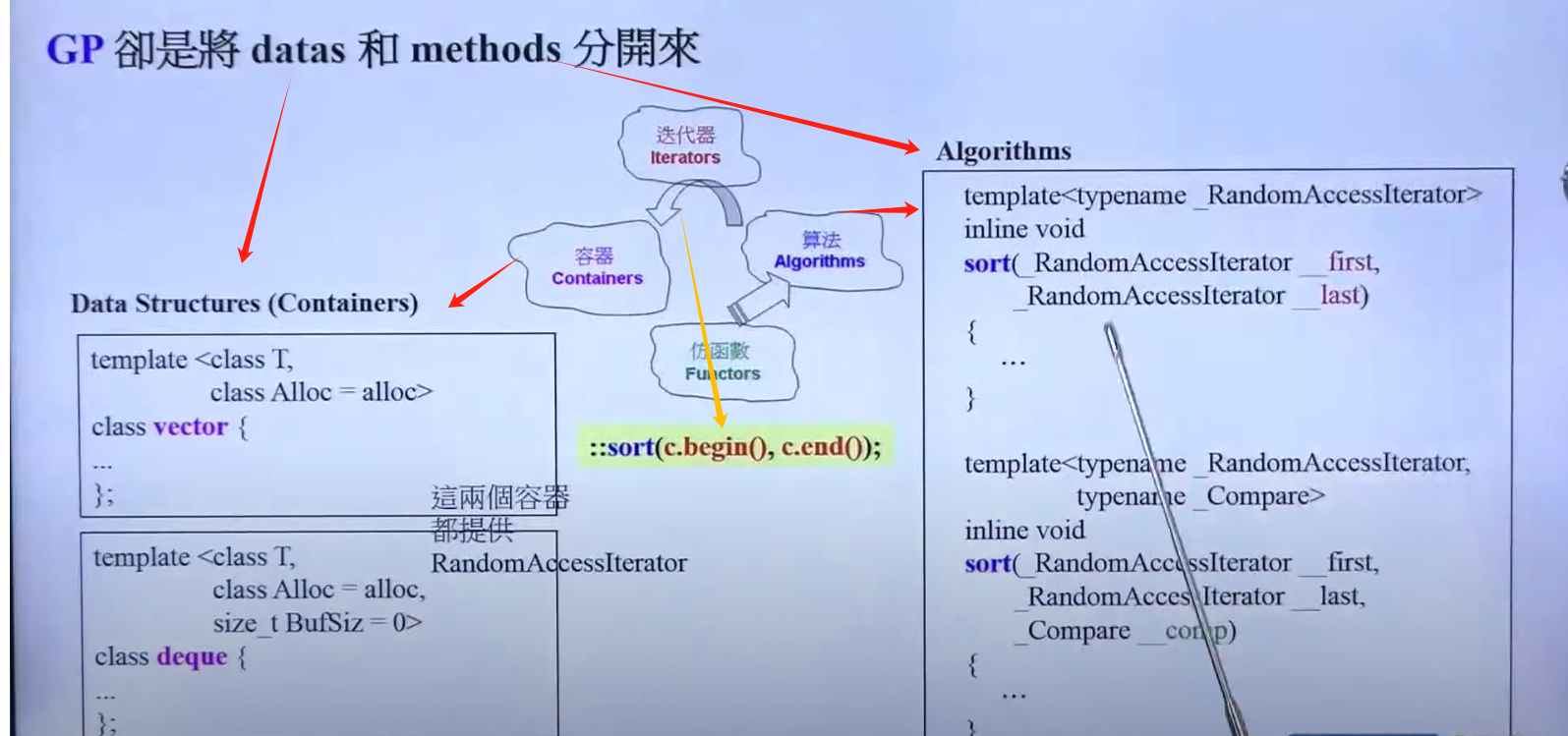
为什么list不能使用全局的sort?
因为sort源代码:
*(first + (last - first)/2)
// 此迭代器只能是随机访问迭代器
// list因为自身特性,其迭代器不支持随机访问
技术基础
1. 运算符重载
对于一个迭代器,基本都要重载*、->、后++、前++,当然还包括其他
2. 模板
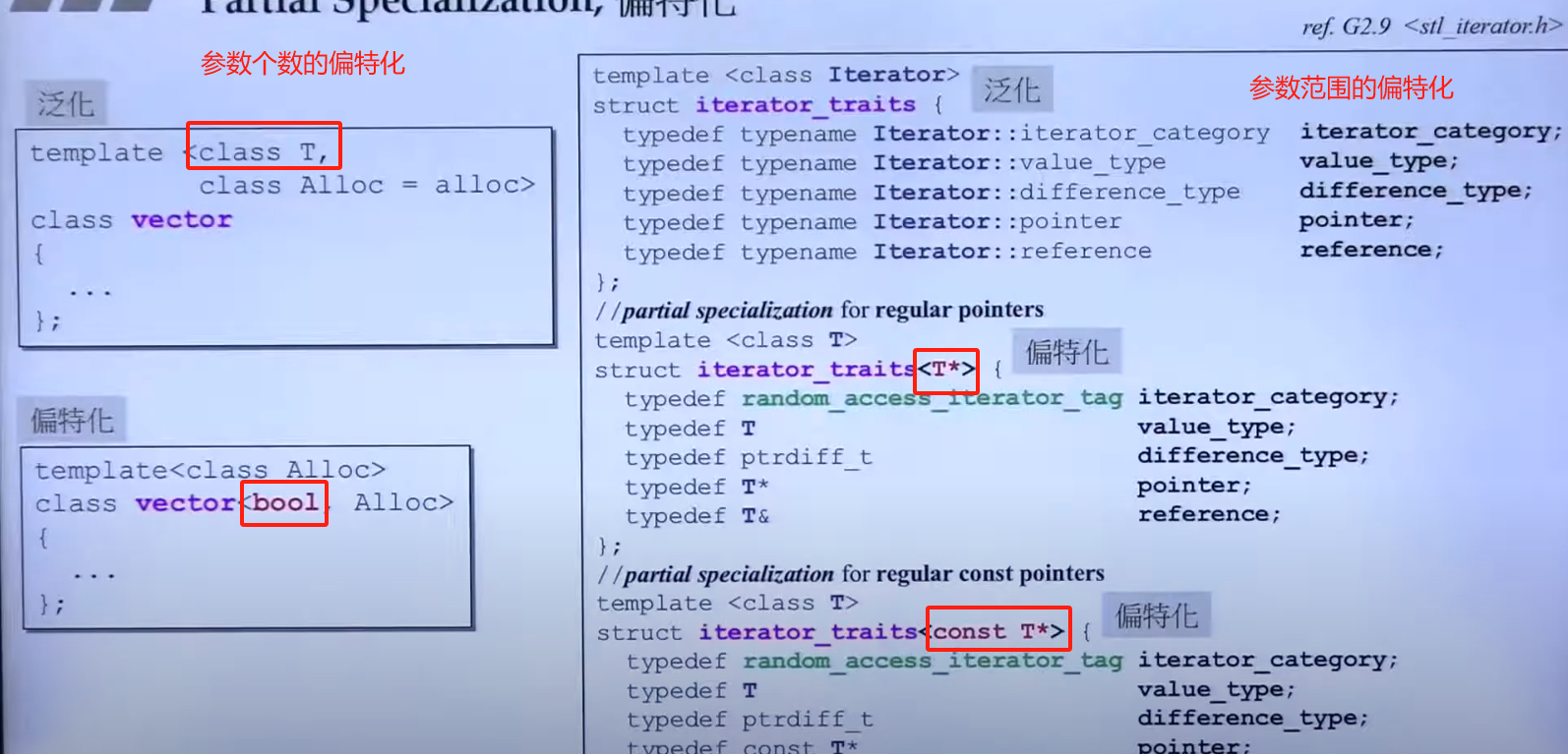
关于特化(全特化):

偏特化(Partial Specialization):
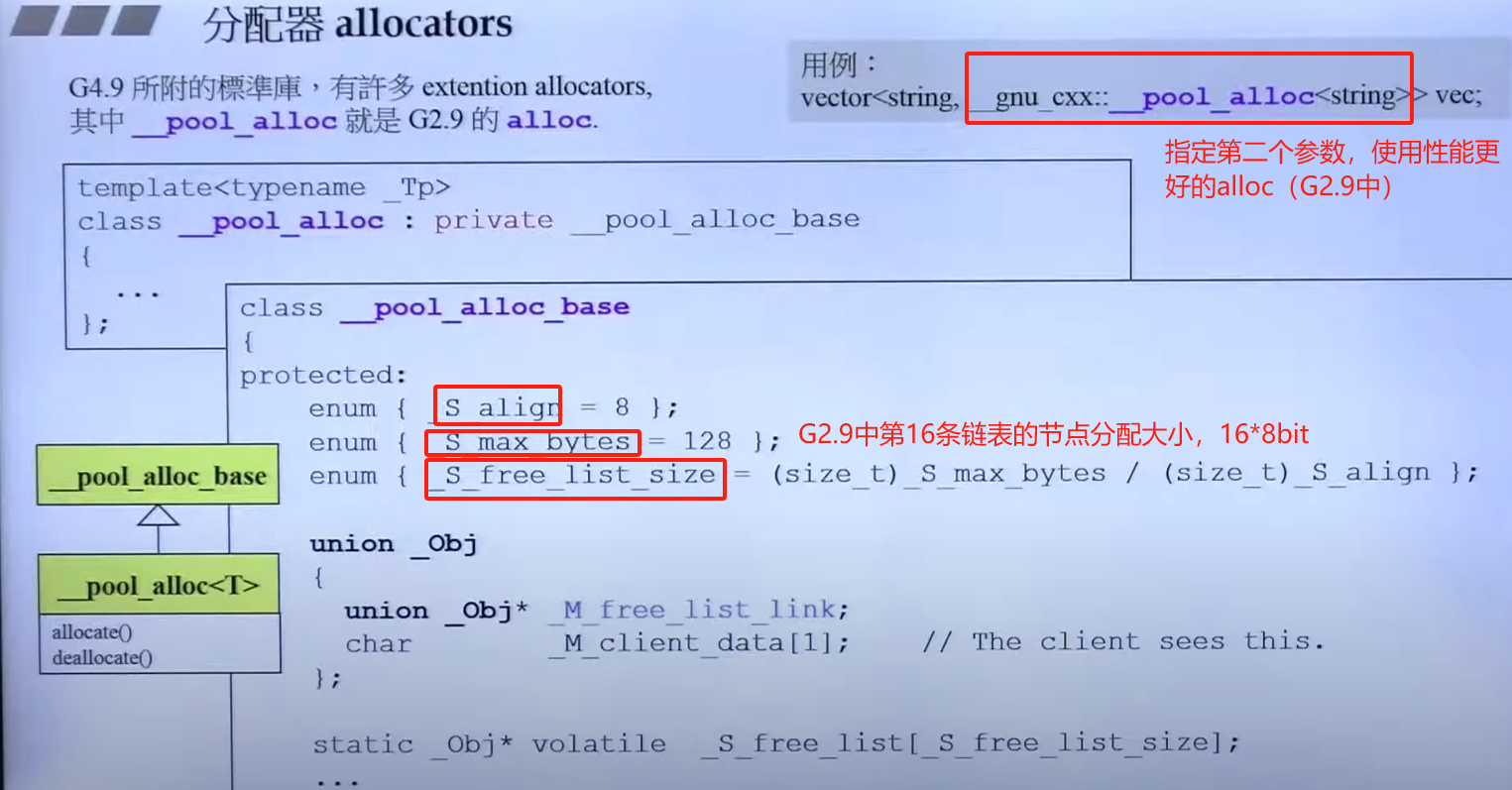
分配器allocator
一个观念:关于内存分配都会基于malloc(memory allocation), malloc再基于操作系统进行实现; 同理,回收基于delete
每次调用malloc,除了分配真正需要的内存,还有一些额外开销overhead(见内存管理课程)
VC6的allocator:位于头文件,查看源代码后,new和delete是基于malloc和delete,没有任何特殊设计,BC和GCC2.9一样。且直接使用allocator比较麻烦,更好的选择是使用迭代器。
GCC2.9真正只用的alloc:在stl_alloc.h

关于gcc4.9的allocator和__pool_alloc,见视频;
容器
一、顺序容器
list


详细的讲解看视频:深度探索list
- g2.9和g4.9的优劣对比;为什么2.9的list大小是4,4.9是8;
- list“前闭后开”的实现;
Iterator traits
迭代器要回答算法的五个问题:
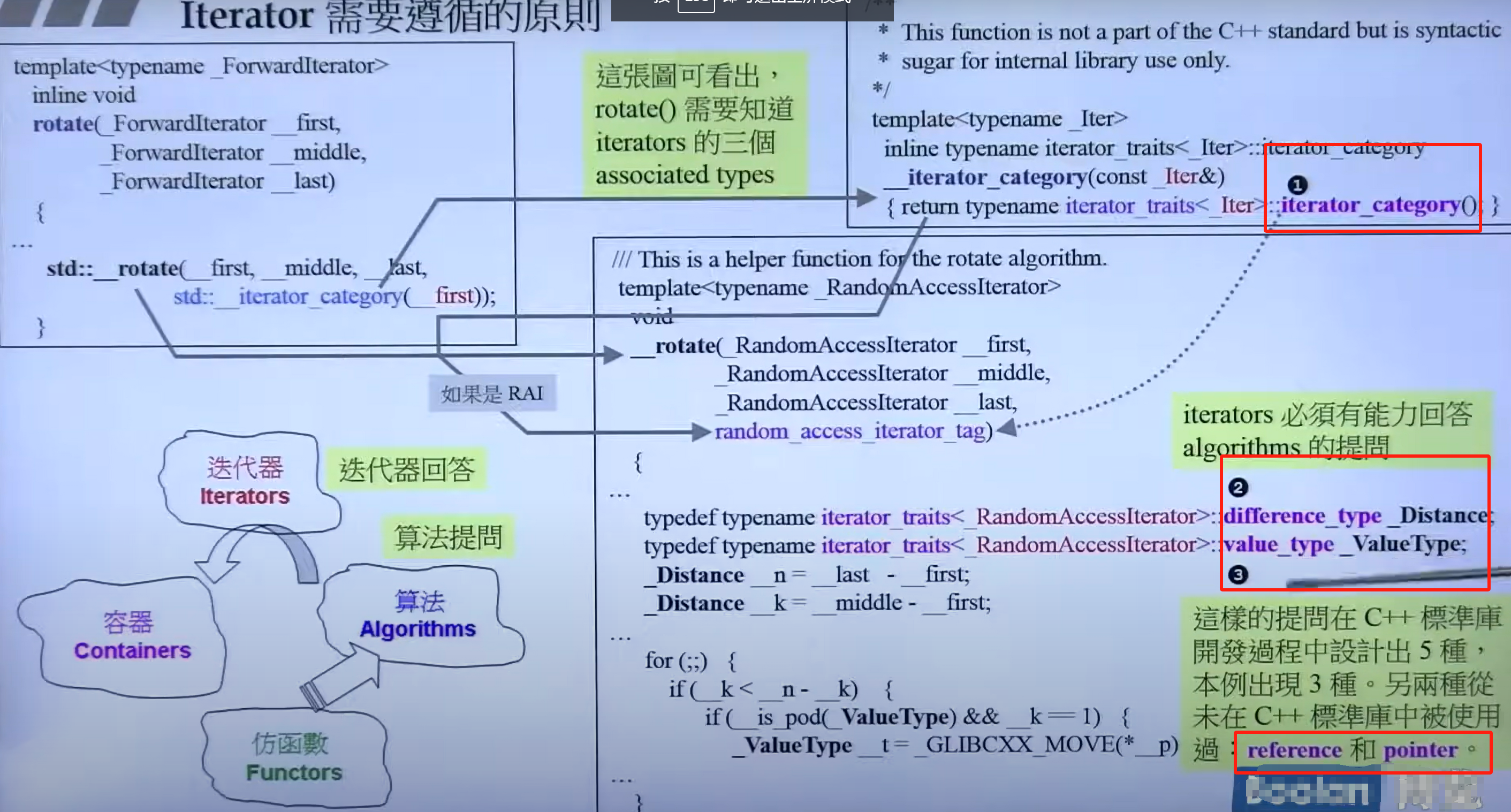
重点关注前三种;reference和pointer从未被使用过
iterator traits(萃取机):一个区分传入的是迭代器还是原生指针的中间层
vector

- vector的扩容:2倍扩容,很多编译器的具体实现都是如此
- finish:根据我们使用end的具体含义,可知finish指向的是尾后元素
- size的写法:调用成员函数
end()-begin()而没有直接使用finish-start,但这样方便后续代码尽量少的改动(empty等的实现也是如此)- 关于
[]:具有连续存储的容器,都要提供下标运算符
关于vector的2倍扩容
使用vector要注意:扩容时大量使用构造和析构函数!
其他方面看视频;
array
array是模拟C/C++语言本身的数组,但是可以更好地利用迭代器、泛型算法等
forward_list
单向链表,可以借鉴之前讲过的双向链表list
deque
只在尾部扩充:vector;双向扩充:deque


图中已经申请了三个buffer,向前/后扩充,就是要在map的五个buffer对应的指针的前/后的指针再次申请新的buffer。图中第一个buffer(左上)还未用完,用完需要图示中的map中的第一个指针再去申请buffer。向后扩充也是如此。
关于迭代器:
- first/last:每个buffer的前后边界;
- node的作用:为保持连续性,图中示例,元素99下一个元素是0(下个buffer)。即通过node来去map中寻找下个buffer
- cur:指向某个元素。图中是指向99
- start/finish:整个deque的头和尾元素
- 关于deque中iterator的大小及具体内容请看视频
deque如何模拟连续
与deque的迭代器相关,重要的点:重载了+=、++、[]等运算符
关于deque的map:是vector。在扩充时也是2倍扩充,但是复制旧元素到新的map的中间,保证可以双向扩充
queue和stack
queue和stack内部默认用deque实现。是通过改装其他容器来实现自身,所以称之为容器适配器
stack和deque不允许遍历,即不提供迭代器(否则可能会破坏两种容器适配器的特性:先进后出、先进先出)
可选择作为底层的容器:list、deque;stack可用vector,queue不能用vector(不支持
pop(),如果你的queue不调用pop,那也可用vector);二者均不可选的:set、map
二、关联容器
视频中的键是key,值data,二者合称value
红黑树

map/multimap
特点:
- 自动排序特性;
- 迭代器遍历;
- 不能通过迭代器修改key,但可以修改data
- insert调用底层红黑树的:
insert_unique()、insert_equal()
map中的定义:key定义为const,map的两个模板类型定义为pair
[]插入方式是map独有的
hashtable
底层实现:
链地址法(seperate chaining)- 当链表(篮子/桶bucket)太长(元素个数超过链表个数):rehashing,即增加链表个数(GNU是选取2倍篮子个数附近的质数)
- 重新计算每个元素的位置
关于hashtable源码:
- 模板参数HashFcn:计算哈希值;ExtractKey:取出key(红黑树中也有类似结构);EqualKey:比较大小的函数对象
- hashtable的data大小:private部分 (1+1+1+4+0+12 = 19,再经过内存对齐,20Bytes);
- 关于node:每个篮子中的节点struct
- 迭代器:cur指向某一个篮子中的节点;ht: 指向hashtable本身(要确保寻找遍历时能找到下一个篮子)
关于视频中hashtable测试
hash<const char*>:为对象元素生成hash值(配合视频内容和《C++Primer》P624第16.5节模板特例化)- 提供给
EqualKey函数对象必须返回bool值(也是为什么提供eqstr的原因) - 求余运算最后都归结为一个函数
bkt_num_key
视频中说标准库没有
hash<std::string>,但是《C++Primer》P396提到可以对内置类型、string、智能指针直接调用hash
hash set/hash multiset/hash map/ hash multimap
c++11后的叫法:hash_xxx —> unordered_xxx
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!