从斐波那契数列到递归

王有志,一个分享硬核Java技术的互金摸鱼侠
加入Java人的提桶跑路群:共同富裕的Java人
今天我们通过经典数学问题斐波那契数列来学习非常重要的编程技巧:递归。
斐波那契数列
关于斐波那契数列,我们直接引用百度百科中的定义:
斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多·斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”,指的是这样一个数列:1、1、2、3、5、8、13、21、34、…… 在数学上,斐波那契数列以如下被以递推的方法定义:F(0)=0,F(1)=1, F(n)=F(n - 1)+F(n - 2)(n ≥ 2,n ∈ N)
- 递推公式: F ( n ) = F ( n ? 1 ) + F ( n ? 2 ) F(n)=F(n-1)+F(n-2) F(n)=F(n?1)+F(n?2)
- 通项公式: 1 5 [ ( 1 + 5 2 ) n ? ( 1 ? 5 2 ) n ] \frac{1}{\sqrt{5}}[(\frac{1+\sqrt{5}}{2})^n-(\frac{1-\sqrt{5}}{2})^n] 5?1?[(21+5??)n?(21?5??)n]
好了,到目前为止,你应该了解了什么是斐波那契数列,那么我们来做一道题:509.斐波那契数。
如果我们要求解第4个斐波那契数,根据递推公式,可以得到:
F
(
4
)
=
F
(
3
)
+
F
(
2
)
=
(
F
(
2
)
+
F
(
1
)
)
+
F
(
1
)
F(4)=F(3)+F(2)=(F(2)+F(1))+F(1)
F(4)=F(3)+F(2)=(F(2)+F(1))+F(1)。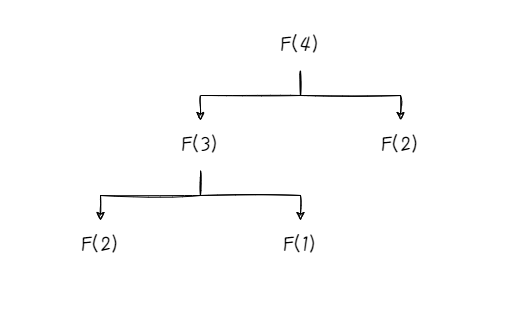
可以看到,在求解斐波那契数的过程中,最后都会拆解为对已知项F(1)和F(2)的求和,我们把通过代码来实现这个拆解的过程就是:
public int fib(int n) {
if (n < 3) {
return 1;
}
return fib(n - 1) + fib(n - 2);
}
代码的逻辑一目了然,对斐波那契数列中的第一项,第二项进行了特殊处理,从第三项开始,使用递推公式求解,每次拆分后调用函数自身。
我们将函数的自我调用被称为递归。递归通常是直接自我调用,但也允许通过调用其他方法,再辗转调用自身。
递归
使用递归求解的代码和斐波那契数列的递推公式是“一模一样”的,总结出反复出现的程序结构,并不断拆分问题进行自我调用,直到无法继续拆分。
反映在斐波那契数列上就是,将F(n)逐步拆解为F(2)和F(1)后求和的过程。补充一点邓俊峰老师的说明:
递归也是一种基本而典型的算法设计模式。这一模式可以对实际问题中反复出现的结构和形式做高度概括,并从本质层面加以描述与刻画,进而导出高效的算法。从程序结构的角度看,递归模式能够统筹纷繁多变的具体情况,避免复杂的分支以及嵌套的循环,从而更为简明地描述和实现算法,减少代码量,提高算法的可读性,保证算法的整体效率。
整体上我是赞同这段内容的,但我对“导出高效的算法”和“保证算法的整体效率”持有一定的怀疑。结合自身的实践,我认为“递归是优雅的实现,但可能会很低效”。
即便你使用语言的编译器有尾调用优化,你也将递归代码改写为尾递归(Tail Recursion)形式(尾递归是尾调用的特例,下文介绍),但效率依旧是差强人意。
终止递归
上面的代码中,存在一个无法继续拆解问题的条件n < 3,在这个条件下,问题不再继续拆分,而是返回计算结果,我个人习惯称这种条件为“出口条件”,即递归程序的出口。百度百科中称为边界条件,邓俊峰老师的书中称为递归基(base case of recursion),也有的书籍中称为基线条件或终止条件。
当然,无论怎么称呼,这个条件的作用是不变的,结束递归。如果没有这类条件,程序会进入无限循环,从而导致卡死或直到栈内存溢出。使用递归时,你必须时刻提醒自己,保证递归程序至少有一个出口。
尾递归
尾递归顾名思义,在“尾巴”处进行递归调用就称为尾递归。换个官方点(邓俊峰老师)的说法:
在线性递归算法中,若递归调用在递归实例中恰好以最后一步操作的形式出现,则称之为尾递归(tail recursion)。
比如说这里我们使用C语言实现阶乘(n为自然数,result的原始输入为1):
long factorial(long n, long result) {
if (n == 0) {
return 0;
} else if (n == 1) {
return result;
}
return factorial(n - 1, result * n);
}
这就是一个典型的尾递归程序。概念和程序都很容易理解,但是我们前面说到,尾递归会提升效率,这是为什么呢?
尾调用消除
我们先了解一个概念:调用栈。当然,在这里我们不需要太过深入,只需要记住:
- 调用栈使用栈这种结构,特点是先进后出;
- 调用栈使用栈帧存储方法的执行信息。
根据自顶向下的执行顺序,被调用到的方法依次压入调用栈中。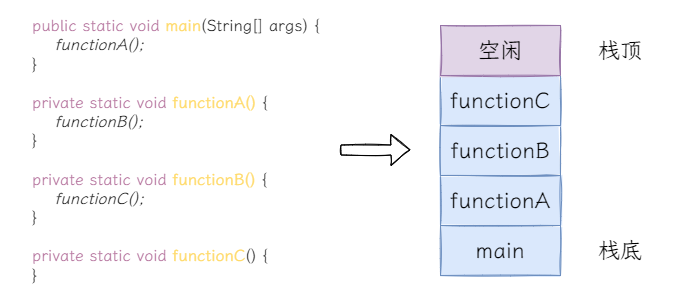
但栈内存是有限的,不可能无限压入。因此,对于递归次数(递归深度)很大的程序来说,调用栈的内存溢出是迟早的事情。那么尾递归是如何优化的呢?
其实道理很简单,方法在执行到最后一行时,此时要做的仅仅是返回结果,如果是再次调用方法,那么要做的是返回调用方法的结果。因此,该方法申请的栈空间也失去了作用,可以在校正栈帧上的执行信息后,提供给被调用方法使用。这种校正栈帧执行信息和跳转到被调用方法的过程被称为“尾调用消除(Tail Call Elimination)”。
但是,这个特性是需要语言支持的,很遗憾的是,Java并不支持尾调用消除,所以尾递归的示例代码使用C语言(虽然和Java一毛一样)。
不过根据Loom的介绍,Java的尾调用消除马上就要来了。
复杂度计算
关于递归复杂度的分析,在这里采用递归跟踪(递归树)的方式分析,此外还可以通过主定理,以及递推方程求解。主定理会在分治的内容开始之前讲解,递推方程可以参考邓俊峰老师的《数据结构》。
递归跟踪(递归树)
递归跟踪的方式很简单,我们假设每次执行递归程序的时间相同,并根据输入依次向下构建递归树,下面是第6个斐波那契数的递归过程: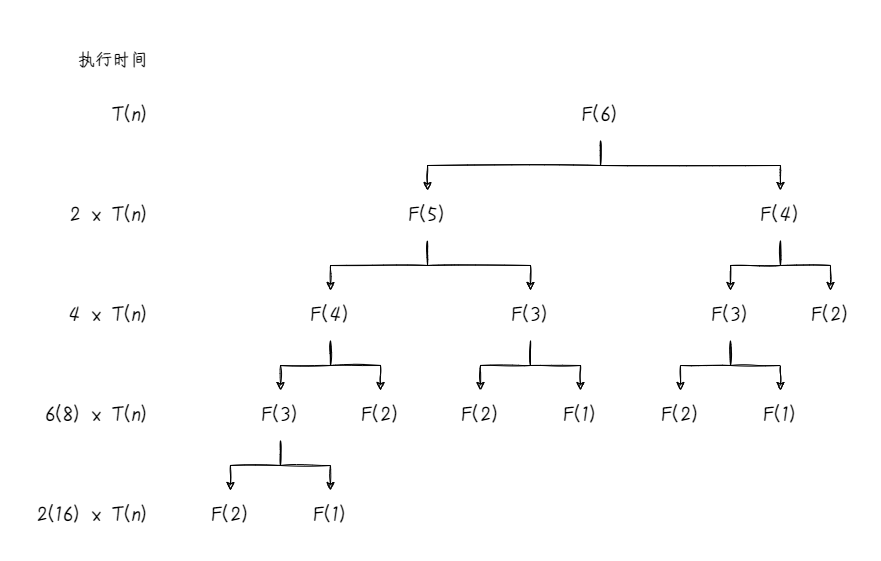
可以看到,相对于计算F(4),计算F(6)整体上看已经是原来的3倍了。我们假设每次执行fib方法的平均时间为T(n),通过递归树可以看到每一层计算了几次fib,我们可以得到:
2
O
T
(
n
)
+
2
1
T
(
n
)
+
2
2
T
(
n
)
+
(
2
3
?
2
)
T
(
n
)
+
(
2
4
?
14
)
T
(
n
)
≈
2
n
?
2
T
(
n
)
2^OT(n)+2^1T(n)+2^2T(n)+(2^3-2)T(n)+(2^4-14)T(n)\approx2^{n-2}T(n)
2OT(n)+21T(n)+22T(n)+(23?2)T(n)+(24?14)T(n)≈2n?2T(n)
根据大O记号的特性,我们可以得到求解第n个斐波那契数的渐进时间复杂度为:
O
(
n
)
=
2
n
O(n)=2^n
O(n)=2n。
如果是通过大θ记号来表示求解第n个斐波那契数列的时间复杂度:
Θ
(
n
)
=
(
1
+
5
)
n
2
≈
1.61
8
n
\Theta(n)=\frac{(1+\sqrt{5})^n}{2}\approx1.618^n
Θ(n)=2(1+5?)n?≈1.618n
通过函数曲线,可以看到随着输入的n逐渐增大,
O
(
n
)
O(n)
O(n)和
Θ
(
n
)
\Theta(n)
Θ(n)的差距越来越大。虽然计算结果的差距看起来很离谱,但是在它们各自的意义下是没有问题的。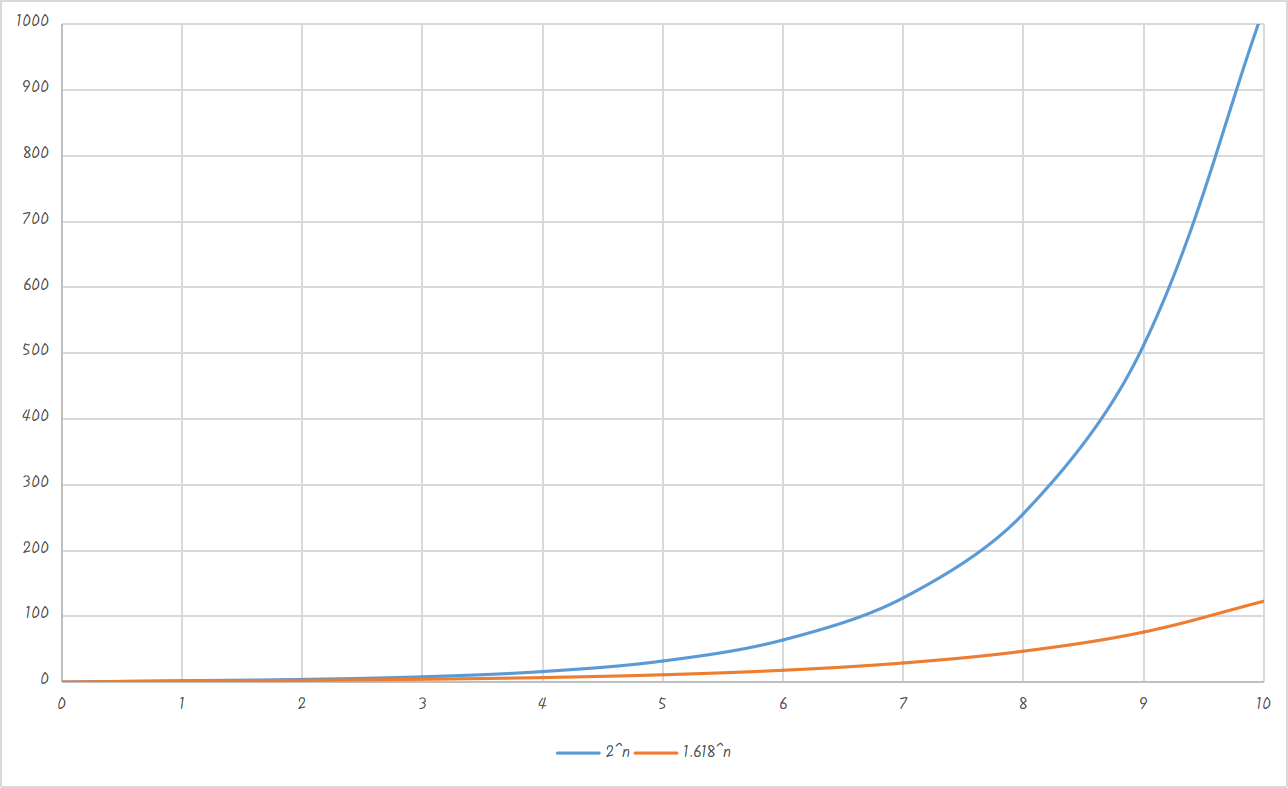
有兴趣的小伙伴可以自己尝试计算下大θ记号下的时间复杂度,我是算不出来了。
结语
今天的内容到这里就结束了,我们来回顾下都聊了哪些内容:
首先是认识了斐波那契数列,斐波那契数列远没有看起来这么简单,随着n的增大,斐波那契数列的相邻两数比值会越来越趋近于0.618,就是自然界中的黄金分割。
通过斐波那契数列,我们认识了递归这一编程技巧,以及编译器对递归的优化。最后我们通过递归跟踪的方式计算了大O记号下斐波那契数列的时间复杂度。
练习
我们来做几道简单的题目:
单纯涉及到递归的题目并不多,我们选几道简单的题目熟悉下递归,在后面链表和树的内容中会有更多关于递归的练习。
如果本文对你有帮助的话,还请多多点赞支持。如果文章中出现任何错误,还请批评指正。最后欢迎大家关注分享硬核Java技术的金融摸鱼侠王有志,我们下次再见!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AI绘图软件,科技之旅绘画
- 【贪心算法】之 分糖果(中等题)
- HackTheBox - Medium - Windows - Scrambled
- 【机电、机器人方向会议征稿|不限专业|见刊快】2024年机械、 图像与机器人国际会议(IACMIR 2024)
- 如何进行产品的人机交互设计?
- HiEV独家|蔚来子品牌切换纯视觉路线:将基于单Orin,去掉激光雷达
- 静态网页课程设计——十二花信(花朵科普)(HTML+CSS+JavaScript)
- 数据中心建设之——理解基于财务三大报表的BI指标体系搭建
- 掌握Lazada API接口:开启电商开发新篇章,引领业务增长潮流
- 中国关心下一代工作委员会健康体育发展中心美育舞蹈考官一王雪