数据转换的三剑客:Pandas 中 apply、map 和 applymap 方法的应用指南
发布时间:2024年01月01日
数据转换的三剑客:Pandas 中 apply、map 和 applymap 方法的应用指南
? 在 Pandas 中,apply、map 和 applymap 是常用的数据转换和处理方法,它们为数据分析和数据处理提供了灵活的功能。这些方法可以根据具体的需求选择合适的方法进行操作。
apply:
? apply 方法是 Pandas 中最常用的方法之一。它可用于在 DataFrame 或 Series 的行或列上应用函数。apply 方法接受一个函数作为参数,并将该函数应用于指定的轴或维度。返回值是一个新的 Series 或 DataFrame 对象,其中包含应用函数后的结果。
import pandas as pd
def square(x):
return x ** 2
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
print(df)
# 应用自定义函数到列
df['A'] = df['A'].apply(square)
print(df)

当然,对于这种简单的语句,我们可以直接使用lamba表达式来代替。
如下:
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
print(df)
# 应用自定义函数到列
df['A'] = df['A'].apply(lambda x: x ** 2)
# x相当于这一列中的每一个元素,对每一个元素都平方
print(df)
map:
? map 方法用于在 Series 对象上应用函数或字典映射。它将函数或映射应用于 Series 中的每个元素,并返回一个新的 Series 对象,其中包含映射后的结果。
import pandas as pd
# 创建一个示例 Series
data = pd.Series([1, 2, 3])
# 应用字典映射到元素
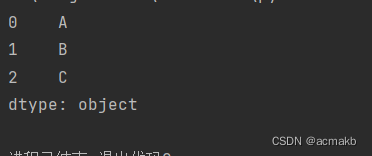
result = data.map({1: 'A', 2: 'B', 3: 'C'})
print(result)
applymap:
? applymap 方法用于在 DataFrame 中的每个元素上应用函数。它将函数应用于 DataFrame 的每个元素,并返回一个新的 DataFrame 对象,其中包含应用函数后的结果。
import pandas as pd
def square(x):
return x ** 2
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
# 应用自定义函数到每个元素
result = df.applymap(square)
print(result)

综合案例:
假设有一个包含学生信息的 DataFrame,其中包括学生姓名、年龄和成绩。现在需要进行以下操作:
- 将学生姓名的首字母大写。
- 根据不同年龄段给学生打上标签(如 “青少年”、“年轻人”、“成年人”)。
- 将成绩大于等于 90 的学生标记为 “优秀”,成绩大于等于 80 且小于 90 的学生标记为 “良好”,其他学生标记为 “一般”。
import pandas as pd
# 创建示例数据
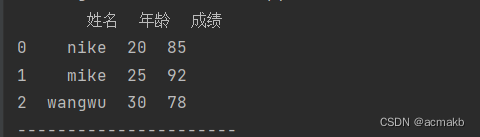
data = {'姓名': ['nike', 'mike', 'wangwu'],
'年龄': [20, 25, 30],
'成绩': [85, 92, 78]}
df = pd.DataFrame(data)
# 1. 将学生姓名的首字母大写
df['姓名'] = df['姓名'].apply(lambda x: x.capitalize())
# 2. 根据年龄段给学生打上标签
age_labels = {20: '青少年', 25: '年轻人', 30: '成年人'}
df['年龄段'] = df['年龄'].map(age_labels)
# 3. 根据成绩给学生打上标签
def grade_label(score):
if score >= 90:
return '优秀'
elif score >= 80:
return '良好'
else:
return '一般'
df['成绩标签'] = df['成绩'].apply(grade_label)
print(df)
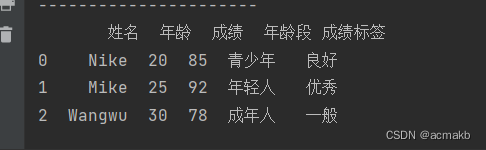
apply方法:通过apply方法将 lambda 函数应用于学生姓名的每个值,使其首字母大写。map方法:利用map方法根据年龄字典将年龄映射为对应的年龄段标签。apply方法:通过apply方法将自定义函数grade_label应用于学生成绩的每个值,生成成绩标签。
总结:
apply 方法适用于 DataFrame 和 Series 对象,可以将自定义函数应用于行或列,实现元素级别的转换和处理。
map 方法适用于 Series 对象,用于对每个元素进行映射操作,可以使用函数、字典或其他 Series 对象进行映射。
? applymap 方法适用于 DataFrame 对象,用于对每个元素进行元素级别的转换和处理。
文章来源:https://blog.csdn.net/ak_bingbing/article/details/135323461
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!