程序的编译、链接
目录
前言:
在ANSI C的任何一种实现中,存在两种不同的环境,第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令;第2种是执行环境,它用于实际执行代码,将磁盘中的可执行文件装载到内存中,CPU才能通过总线读取内存中的指令,才能真正执行程序;本文重点阐述程序的翻译坏境;

前置知识回顾
宏
#define 机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏(macro)或定义宏(define macro);命名习惯: 宏名全部大写
//宏的声明:
#define name( parament-list ) stuff
//其中的 parament-list 是一个由逗号隔开的符号表,它们可能出现在stuff中;
//注意:参数列表的左括号必须和宏名name紧邻;
//如果宏名与参数列表之间有任何空白存在,参数列表就会被解释为stuff的一部分;宏定义常量
# define ROW 10 //宏定义整型常量
# define PI 3.14 //宏定义浮点型常量
# define STR "hello world" //宏定义字符串
int main()
{
printf("%d %f %s\n", ROW, PI, STR);
return 0;
}
宏定义语句
# define PRINTF printf("Hello Linux!\n");
int main()
{
int i = 10;
PRINTF;
return 0;
}运行结果:

宏定义函数
宏可以接收参数且不用指定参数类型;
# define ADD(x,y) ((x)+(y))
int main()
{
int m = 10;
int n = 10;
float d1 = 4.5;
float d2 = 5.5;
printf("%d\n", ADD(m,n));
printf("%f\n", ADD(d1, d2));
return 0;
}运行结果:

条件编译
编译程序时使用条件编译指令选择性的将一条语句/一组语句编译或者放弃;
//常见的条件编译指令
#if: 如果条件为真,则执行相应的操作;
#elif: 类似于else if的用法,当前面条件为假,再判断该条件是否为真,如果是真,则执行相应操作;
#else: 如果前面所有条件均为假,则执行相应操作;
#ifdef: 如果该宏已定义,则执行相应操作;
#ifndef: 如果该宏没有定义,则执行相应操作;
#endif : 结束对应的条件编译指令(不能省略);
应用场景
# define VERSION1 1
//# define VERSION2 2
int main()
{
#ifdef VERSION1
printf("Hello Version1.0\n");
#elif VERSION2
printf("Hello Version2.0\n")
#else
printf("Hello Free Version");
#endif
return 0;
}运行结果:

//# define VERSION1 1
//# define VERSION2 2
int main()
{
#ifdef VERSION1
printf("Hello Version1.0\n");
#elif VERSION2
printf("Hello Version2.0\n")
#else
printf("Hello Free Version\n");
#endif
return 0;
}运行结果:

编译过程概览
将一个.c文件翻译为可执行文件,需要经过预编译(prepressing) 、编译(compliation)、汇编(assernbly)、链接(linking)四个阶段;

预编译阶段
- 头文件展开
- 去掉注释
- 宏替换
- 条件编译
//vim编辑器编写test.c文件
# include <stdio.h>
# define M 100
int main()
{
printf("%d\n",M);
//printf("hello Linux!\n");
//printf("hello Linux!\n");
//printf("hello Linux!\n");
printf("hello world!\n");
return 0;
}
Linux环境使用选项 gcc -E test.c -o test.i
此条语句的含义为从现在开始进行程序的翻译过程,当预处理结束时,停止程序的翻译过程;

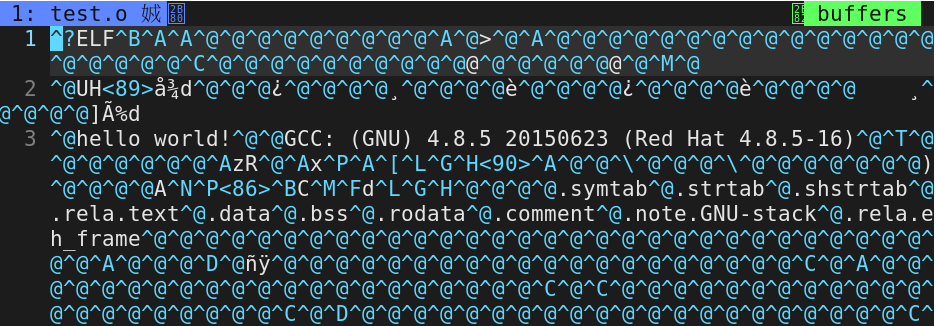
上图生成test.i文件,使用vim编辑器打开test.i文件;

注释被删除掉,宏定义的M被替换为100,使用选项 vim /usr/include/stdio.h 打开c标准库对比发现头文件被替换;
使用vim编辑器编写code.c代码,code.c代码使用条件编译指令;
//vim编辑器编写code.c代码
# define VERSION1 1
//# define VERSION2 2
int main()
{
#ifdef VERSION1
printf("Hello Version1.0\n");
#elif VERSION2
printf("Hello Version2.0\n")
#else
printf("Hello Free Version\n");
#endif
return 0;
}
编译阶段
1. 词法分析:词法分析器处理test.i文件,将字符串切割成一个个记号(mark);
????? 例如:sum=a+b;会产生五个记号:"sum" "=" "a" "+" "b"
2. 语法分析:语法分析器将产生的记号组织成一个个表达式,以表达式为节点,生成一颗语法树;
3. 语义分析:语义分析器处理声明以及数据类型、给语法树的节点赋予数据类型;
4. 中间代码:根据语法树生成中间代码,以上的步骤是硬件平台无关的,而中间代码之后的处理则需要根据程序运行的硬件平台来决定;
5. 代码生成器:代码生成器将中间代码转换成对应硬件平台的汇编代码test.s;
Linux环境使用选项 gcc -S test.c -o test.s
此条语句的含义为从现在开始进行程序的翻译过程,当编译结束时,停止程序的翻译过程;

?汇编阶段
汇编器:汇编器根据 汇编指令与机器指令的对照表 将汇编代码翻译成机器指令,生成目标文件test.o;
目标文件由若干个段(section)组成,每个段中存放不同的内容;
目标文件中的基本段类型:文件头、代码段、数据段、bss段、常量段、段表、符号表、重定位表;
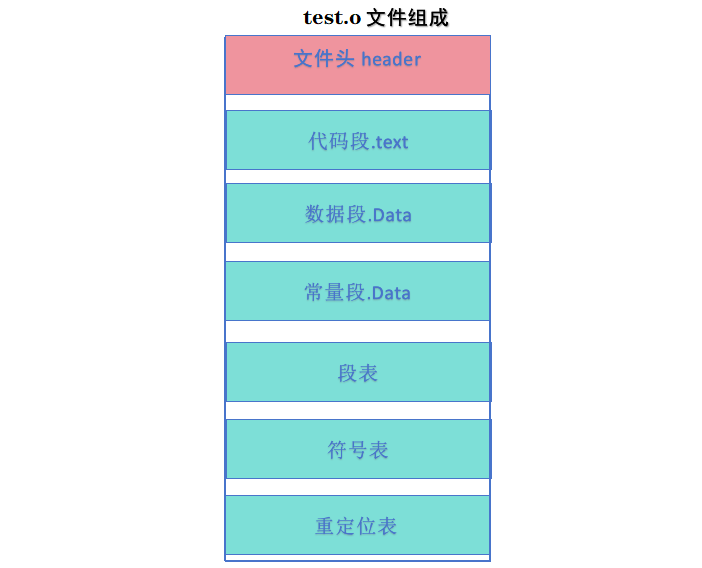
文件头:文件头位于目标文件开始位置,它定义了elf魔数,目标文件的属性、运行的软硬件平台、程序入口地址、段表的位置及长度、段的数量;
代码段:存放? 机器指令;
数据段:?? 存放 已经初始化的全局变量以及静态变量;
常量段:存放? 字符串常量以及被const修饰的变量;
bss段: 存放? 未初始化的全局变量以及静态变量所占用的内存大小;
段表:??? 记录了目标文件中所有段的地址以及属性(读写or可执行)等信息;
符号表:记录与程序相关的所有符号(如变量、函数名),变量或者函数所对应的地址和属性;
重定位表:重定位表用于指示需要进行重定位的指令或数据,记录了位置信息、长度以及对应的符号引用;
Linux环境使用选项 gcc -c test.c -o test.s
此条语句的含义为从现在开始进行程序的翻译过程,当汇编结束时,停止程序的翻译过程;
?链接阶段
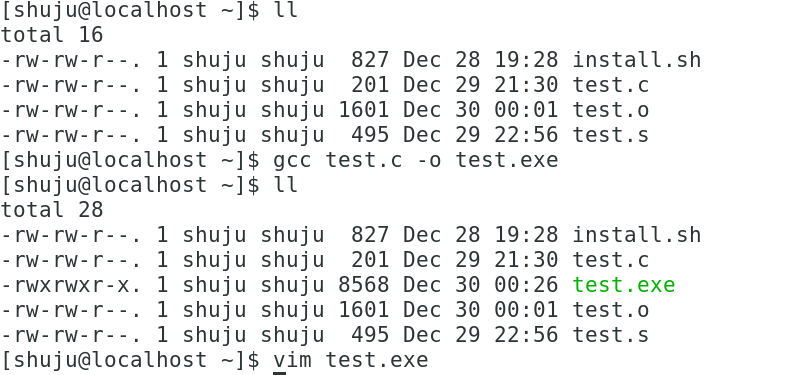
链接器:合并输入的.o文件、确定符号内存地址、进行符号重定位,输出可执行文件;

?Linux环境使用选项 gcc test.c -o test.exe
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RaspberryPi(树莓派)安装操作系统时配置 WIFI
- jupyter 配置
- 【ubuntu22.04安装mysql8并配置远程连接】
- JavaScript 中的双等号(==)和三等号(===)有何不同?何时使用它们?
- nohup命令详解
- 【知识分享】Java实现“羊了个羊”的思路和代码
- 【51单片机】LED 点阵
- PHP反序列化总结4--原生类总结
- 设计模式之单例模式
- 解决 微信小程序 40125invalid appsecret, rid: 6xxx9e2d-529xxxx4-42axxx2c