Java IO流
发布时间:2024年01月14日
目录
一.字符集
ASCII:一个字节存储,首尾是0
GBK:?两个字节存储,首位是1
Unicode:统一码,4个字节存储,容纳世界所有文字
UTF-8:Unicode的一种编码方案,英文数字占1字节,汉字占3个字节
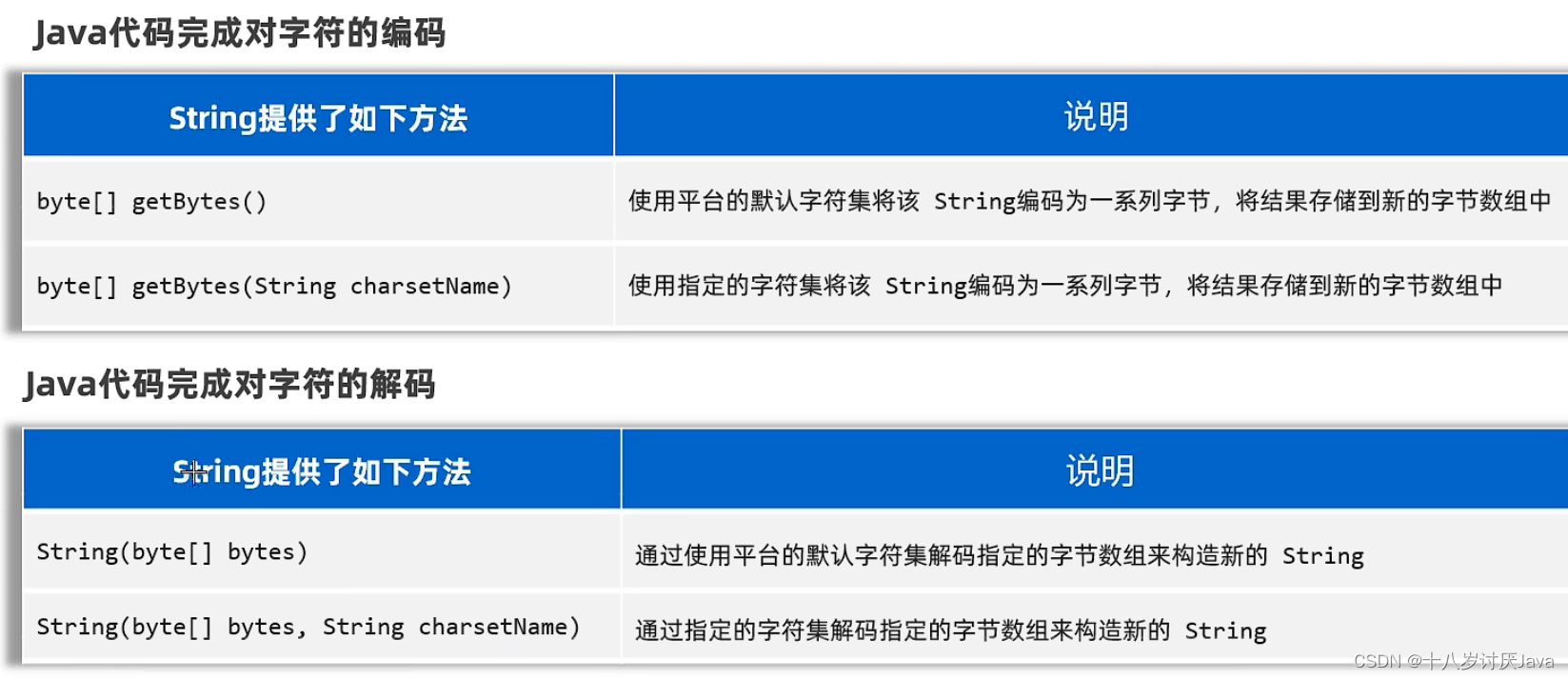
编码和解码必须使用一致字符集,否则会乱码
二.JavaIo流体系

三.如何提升读取和写入速度?
1.使用缓冲流,缓冲流默认有8K的缓冲区,使用缓冲流比原始流要更快
2.调大每次读取的字节或字符数组,可以使原始流的速度与缓冲流的速度不相上下;
那么,字节数组是否越大越好呢?答案是否定的,当字节数组达到一定程度时,对速度的影响是微乎其微的,反而会耗用更多的内存
四.文件读取乱码问题
Java中的io流会默认使用编译器的编码,当读取的文件编码与io流编码不一致时,会出现乱码;
解决:先获取文件的原始字节流,再将其按照真实的字符集编码转成字符输入流,这样字符输入流中的字符就不会乱码
使用InputStreamReader(InputStream is , String charset)可以把原始流按照文件的字符集转成字符流
OutputStreamReader(OutputStream is , String charset) 可以按照我们想要的编码进行写
文章来源:https://blog.csdn.net/w20001118/article/details/135566579
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章