批量归一化:彻底改变深度学习架构
一、介绍
????????在深度学习的动态领域,批量归一化的引入标志着神经网络训练方法的关键转变。这项创新技术由 Sergey Ioffe 和 Christian Szegedy 在 2015 年提出,已成为现代神经网络架构的基石。它解决了训练深度网络的关键挑战,特别是处理臭名昭著的内部协变量偏移问题。本文旨在阐明批量归一化的概念、其对深度网络训练的深远影响及其在各种应用中的实际意义。
在神经计算领域,批量归一化类似于风暴中的指南针,可以稳定学习算法在内部协变量变化的汹涌海洋中的航行。
二、了解批量归一化
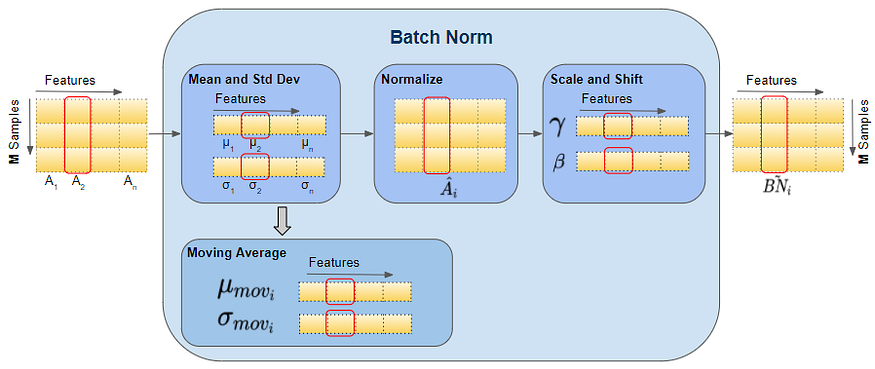
????????批量归一化的核心是一种用于标准化神经网络中某一层的输入的技术。它的工作原理是通过减去批次均值并将其除以批次标准差来标准化先前激活层的输出。因此,这种归一化过程确保后续层的输入具有稳定的分布,从而促进更平滑和更快的训练过程。
????????批量归一化是神经网络中使用的一种技术,用于标准化每个小批量的层输入。这具有稳定学习过程并显着减少训练深度网络所需的训练周期数的效果。
以下是其工作原理的更详细分解:
- 归一化:对于每个特征,均值和方差是在小批量上计算的。然后,根据该均值和方差对特征进行归一化。
- 缩放和平移:归一化后,使用在训练过程中学习到的两个参数 γ(缩放)和 β(平移)对特征进行缩放和平移。此步骤至关重要,因为标准化过程有时会以网络无法学习的方式改变特征的表示。如果需要最大程度地减少损失,则缩放和移位允许网络撤消标准化。
- 改进训练:批量归一化允许网络的每一层独立于其他层学习更多一点。它还有助于减少内部协变量偏移问题,即随着前一层参数的变化,每层输入的分布在训练过程中发生变化,这可能会因为需要较低的学习率和仔细的参数初始化而减慢训练速度。
- 正则化效果:它还具有轻微的正则化效果,导致(但不能消除)dropout 的需要。
- 实现:它通常在深度学习框架中的层中实现,并在卷积层或全连接层之后、非线性层(如 ReLU)之前使用。
人们发现批量归一化对于训练深度网络非常有效,特别是在计算机视觉和语音识别领域。
三、内部协变量偏移问题
????????在批量归一化出现之前,深度学习网络一直受到内部协变量偏移问题的困扰。这种现象是指训练过程中权重的不断更新导致网络激活分布发生变化,导致需要较低的学习率和谨慎的参数初始化。批量归一化的引入通过稳定每层输入的分布有效地缓解了这个问题。
3.1 批量归一化的优点
- 提高训练速度:通过稳定输入分布,批量归一化允许使用更高的学习率,显着加速深度网络的训练过程。
- 减少对初始化的依赖:它降低了网络对初始权重的敏感性,为选择初始化方法提供了更大的灵活性。
- 正则化效果:批量归一化本质上具有温和的正则化效果,可以减少过度拟合并通常减少对 dropout 层的需求。
- 促进更深层次的网络:通过缓解梯度消失和爆炸问题,它可以构建和有效训练更深层次的网络。
3.2 挑战和限制
????????尽管批量归一化有很多优点,但它也并非没有局限性。一项重大挑战是它对小批量大小的依赖。小批量可能会导致均值和方差估计不准确,从而影响模型性能。此外,批量归一化假设训练和推理期间输入分布一致,但情况可能并非总是如此。
3.3 应用和影响
????????批量归一化的实际影响是巨大且多样的。它已成为计算机视觉、自然语言处理和语音识别领域最先进架构的基本组成部分。它在图像分类中的 ResNets 和语言模型中的 Transformer 等模型的成功中发挥的作用凸显了它在推进深度学习领域的重要性。
四、代码
????????使用批量归一化创建完整的示例涉及几个步骤:生成合成数据集、使用批量归一化构建神经网络模型、训练模型以及绘制结果。为此,我们将使用 Python 以及 TensorFlow(或 Keras)和 matplotlib 等流行库。
首先,我们概述一下步骤:
- 生成综合数据集:我们将创建一个适合分类或回归任务的简单数据集。
- 构建神经网络模型:将批量归一化层合并到模型中。
- 训练模型:使用合成数据集来训练模型。
- 绘制结果:显示训练损失和准确性,以了解批量归一化的影响。
现在,让我们用代码来完成每个步骤。
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, BatchNormalization
from sklearn.datasets import make_classification
# Generate synthetic dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# Split into training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Build the model
model = Sequential([
Dense(64, input_dim=20, activation='relu'),
BatchNormalization(),
Dense(64, activation='relu'),
BatchNormalization(),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=50, batch_size=32)
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()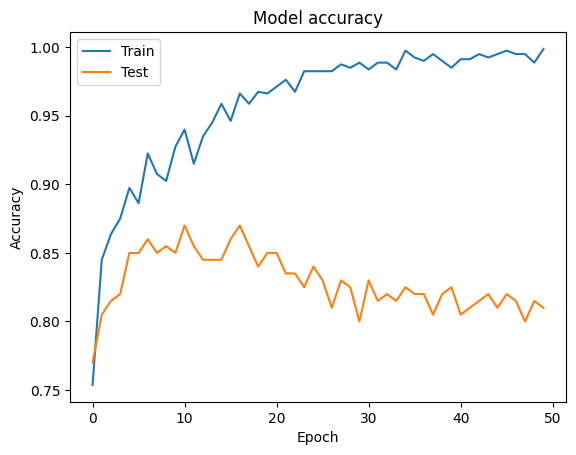
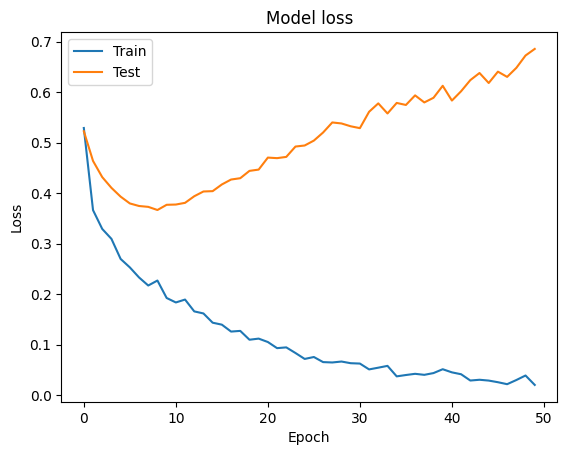
????????此代码提供了在具有合成数据集的神经网络中使用批量归一化的完整端到端示例。请记住,批量归一化的有效性可能会根据数据集和模型架构的不同而有所不同,因此尝试不同的配置总是好的。
五、结论
????????批量归一化代表了神经网络训练发展中的一个重要里程碑。通过解决内部协变量偏移的关键挑战,它不仅简化而且增强了深度神经网络的训练过程。虽然它有其自身的一系列挑战和限制,但它在训练稳定性、速度和网络深度方面提供的好处是不可否认的。随着深度学习领域的不断发展和发展,批量归一化无疑仍将是神经网络架构中的关键工具。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- c++day3(2023/12/28)
- EOCR电动机保护器故障原因查询
- Mybatis事务如何跟Spring结合到一起?
- 13. 抽象类(abstract关键字)
- MIT 6s081 blog2.xv6 Trap(陷阱)机制
- 面向对象三大特征之二:继承
- 现在做视频号小店晚吗?还有发展空间吗?
- OpenSSH升级openssh-9.3p2.tar.gz(漏洞修复)
- 使用Burp Collaborator验证无回显的RCE漏洞
- 第二篇:新建node项目并运行