python每日学11:xpath的使用与调试
发布时间:2023年12月18日
背景:最近在使用selenium 模拟浏览器作一些常规操作,在使用selenium的过程中接触到的一种定位方法,叫xpath, 这里说一下使用心得。
首先,我觉得如果只是简单使用的话是不用详细了解具体的语法规则的。
一、xpath怎么用?
以下是一些使用示例,find_element的第二个参数就是xpath路径。
el = web.find_element('xpath', '//*[@id="changeCityBox"]/p[1]/a')
web.find_element('xpath', '//*[@id="search_input"]').send_keys('python', Keys.ENTER)
二、xpath怎么获取?
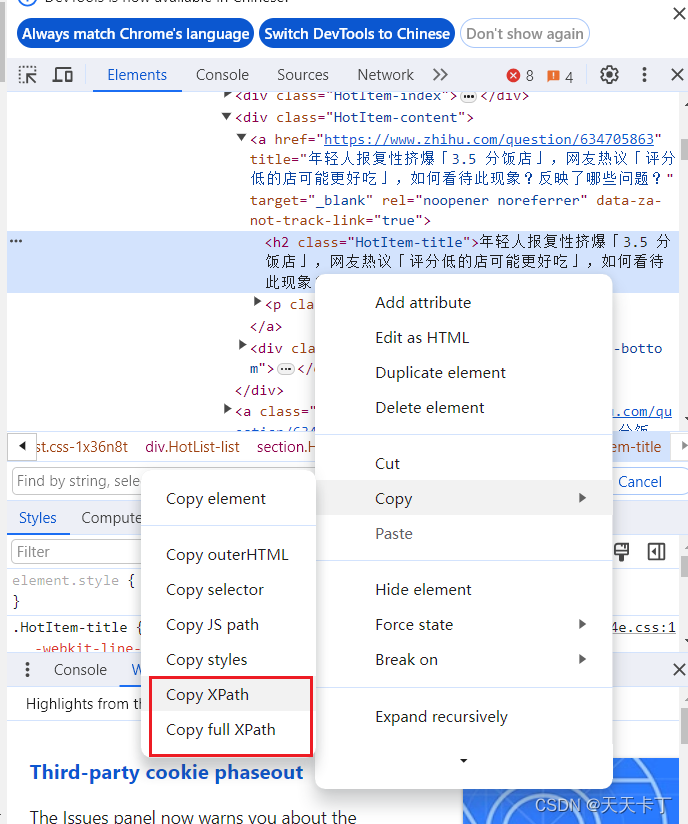
如果不知道xpath怎么写,(一般就算知道怎么写,也不会自己一个个的写,太麻烦)可以用浏览器的开发工具来复制 xpath路径,比如下面的截图是知乎热榜的一个标题,如果我想取这个标题的xpath,那么就直接选中这一段,右键——copy——copy xpath就行了,这样就得到了xpath路径,非常简单。
三、xpath与full xpath的区别?
至于xpath与full xpath的区别,看下面示例:
# full xpath
/html/body/div[1]/div/main/div/div[2]/div[1]/div/div[2]/div/div[2]/div[1]/section[2]/div[2]/a/h2
# xpath
//*[@id="TopstoryContent"]/div/div[2]/div[1]/section[2]/div[2]/a/h2
一个是从根节点开始的路径,一个是以某一个有id的元素开始的路径。(正常情况下,id应该唯一)
四、xpath与full xpath的适用场景
对应于文件夹目录的话,一个是绝对路径,一个是相对路径。两者使用各有好处。
比如说我抓取的一个网站,元素也有id,但id是动态生成的,这个时候就不能用xpath,要用full xpath. 但是也不是绝对的,有些网站经常加减一个模块(比如新闻网站临时性专题),那么绝对路径也会变,这时用相对路径可能会好一点。
五、xpath怎么调试?
有时候,需要自己写一些xpath路径,比方说系统自动获取的有误差,或者在路径中加上变量。或者有时就是从开发工具中复制的xpath,但在程序中不起作用,那就需要调试下了。这时也可以用到开发工具。
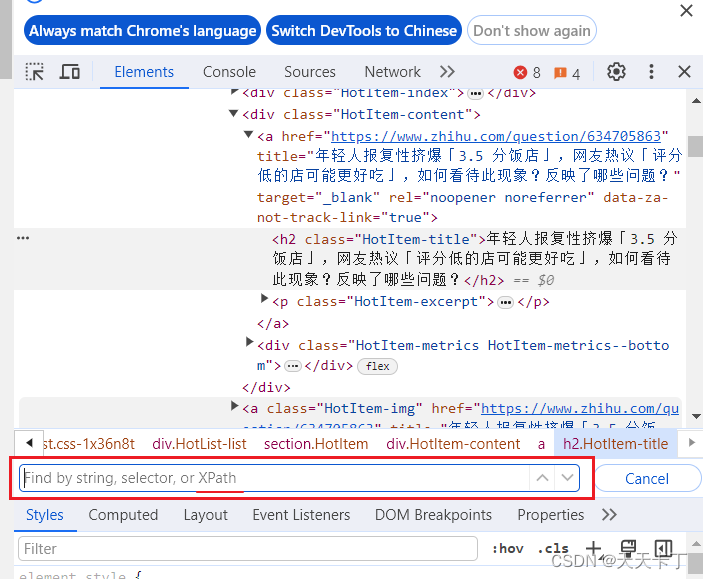
开发工具里其实是有一个搜索功能的,按ctrl+f可以出现搜索框,注意那个搜索框是可以搜索xpath的,那就可以把自己要测试的xpath放在这个里面搜索,如果能搜到,说明xpath是对的,不能搜到就是错的。
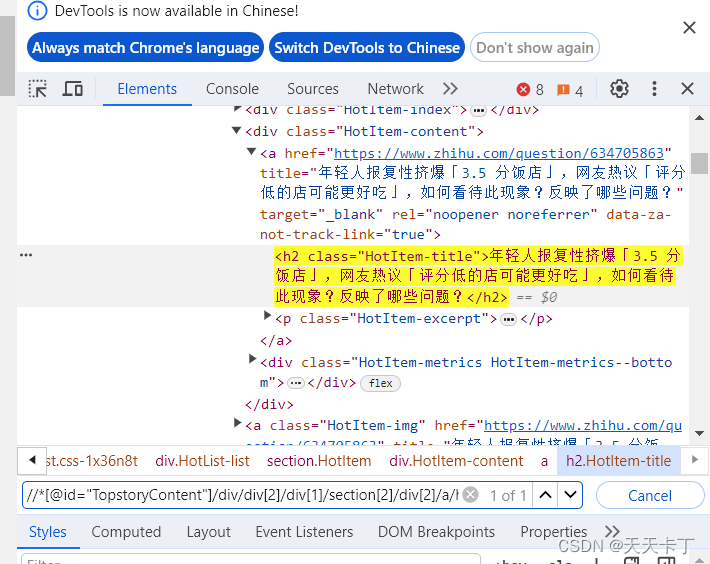
如果搜到内容了,会高亮
后记:
- 谷歌浏览器开发工具里的copy出现的 full xpath是新版本加的功能,老版本里面没有这个功能。
- 不知道有没有别的工具或插件能快速生成元素的xpath,大家要是知道的话,可以留言告诉我。
文章来源:https://blog.csdn.net/weixin_44981444/article/details/135025544
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- localstorage、sessionStorage和cookie区别
- 可看黄道吉日的 cal
- 算法与数据结构--有向图以及拓扑排序
- 蓝桥杯2019年11月青少组Python程序设计省赛真题
- Java静态代理和动态代理(JDK)的简单实现
- 【C++入门】C++ STL中string常用函数用法总结
- Java中的泛型
- EM(Expectation-Maximum)算法
- Go语言接口污染:你不得不知道的开发陷阱
- 区块链知识学习(一)