【Redis交响乐】Redis中的数据类型/内部编码/单线程模型
在上一篇博客中我们讲述了Redis中的通用命令,本篇博客中我们将围绕每个数据结构来介绍相关命令.
一. Redis中的数据类型和内部编码
type命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)、list(列表)、hash(哈希)、set(集合)、zset(有序集合),但这些只是Redis对外的数据结构.如下图所示:

(上述有序集合,相当于是除了存储member之外,还需要存储一个score(权重 分数))
实际上Redis针对每种数据结构都有自己的底层内部编码实现,而且是多种实现,这样Redis会在合适的场景选择合适的内部编码.
数据结构: value的数据类型.
编码方式: redis内部底层的实现.
在同一个数据结构中,背后的编码方式的实现可能是不同的.会根据特定场景进行优化.
| 数据类型 | 内部编码 | 解释说明 |
|---|---|---|
| string | raw | 最基本的字符(底层是一个byte数组(Java)) |
| int | redis通常也可以用来实现一些计数功能,当value是一个整数的时候,此时可能redis会直接使用int来保存 | |
| embstr | 针对短字符串进行的特殊优化 | |
| hash | hashtable | 最基本的哈希表,redis内部的哈希表的实现 |
| ziplist | 在哈希表里面的元素比较少时,可能就优化成ziplist 因为压缩列表能够节省空间 | |
| list | linkedlist | 链表 |
| ziplist | 压缩列表 | |
| set | hashtable | |
| intset | 集合中存的都是整数 | |
| zset | skiplist | 跳表 |
| ziplist |
查看key 对应的 value 的实际编码方式命令为 :object encoding key
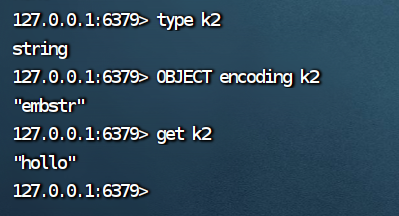
总的来说,redis会根据当前的实际情况选择内部的编码方式自适应.
二. Redis的单线程模型
假设此时有多个客户端,同时操作同一个redis服务器:
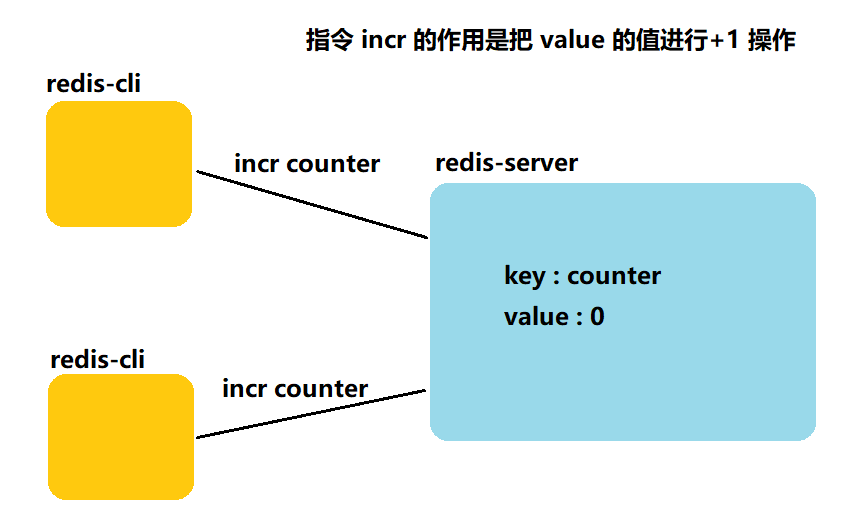
那么此时,这两个客户端相当于并发处理 value 值,同时使得 value 值+1,那么在这种情况下会不会出现线程安全的问题呢?
不会. 因为redis是单线程模型,就保证了当前收到的多个请求是串行执行的.也就是说,多个请求同时到达redis 服务器,也是要先在队列中排队的,再等待redis服务器一个一个取出里面的命令再执行,微观上讲,redis服务器是串行/顺序执行这多个命令的.
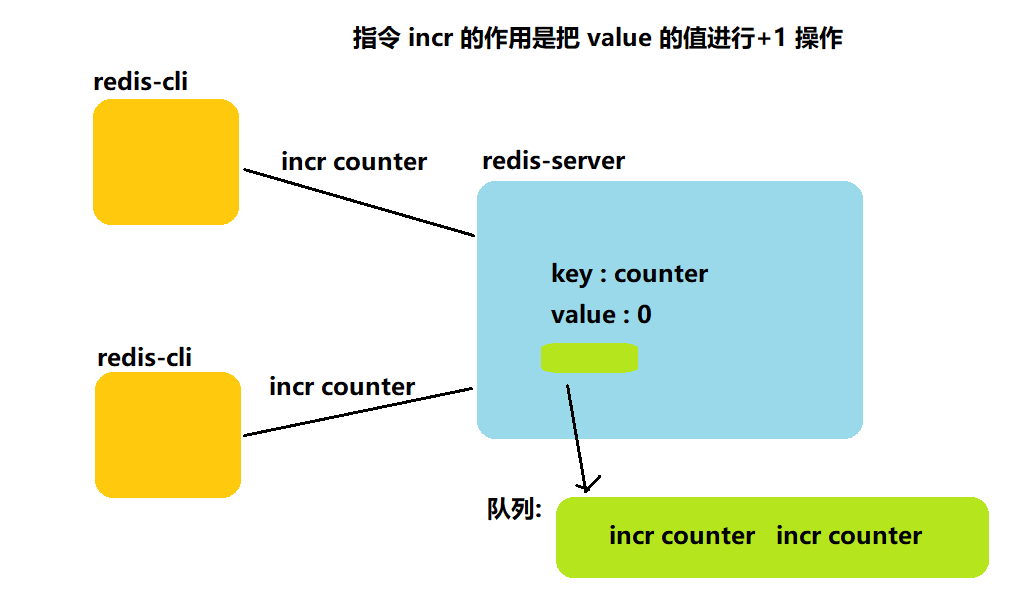
redis能够使用单线程模型很好地工作,原因主要在于redis的核心业务逻辑,都是短平快的,不消耗cpu资源.
单线程的弊端: 使用 redis 必须要特别小心,某个操作占用时间长,就会阻塞其他命令的执行.
面试题: redis是单线程模型,为什么效率之高,速度之快呢?
值得注意的是,在此面试题中的参考是像 MySQL,oracle,sql server这样的数据库.
- redis 访问内存,数据库则是访问硬盘.
- redis 核心功能,比数据库的核心功能更简单.
数据库对于数据的插入删除查询,都会有更复杂的功能支持.这样的功能势必要花费更多的开销.比如针对插入删除,数据库中的各种约束,都会使数据库做额外的工作. - 单线程模型,避免了一些不必要的线程竞争开销.
redis 每个基本操作,都是短平快的,即简单操作内存数据,不是什么特别消耗cpu的操作. - 处理网络IO的时候,使用了 epoll这样的IO多路复用机制.
IO 多路复用: 一个线程可以管理多个 socket ,针对TCP来说,服务器这边每次要服务一个客户端,都需要给这个客户端安排一个 socket .一个服务器服务多个客户端,同时就有很多个 socket .但是很多情况下,每个客户端和服务器之间的通信不是很频繁. 也就是说,同一时刻,只有少数socket是活跃的.此时我们就可以使用 IO多路复用.即一个线程来处理多个socket. Linux上提供的IO多路复用,主要有三套API : select poll epoll …
举个例子:
晚饭时间到,ABC三人决定晚上在夜市点饭吃.A想吃肠粉,B想吃蛋炒饭,C想吃羊杂.
于是有三种可执行方案:
a) A去. 先买肠粉,等待; 再买蛋炒饭,等待; 再买羊杂,等待;(效率最低)
b) ABC一起去. 各买各的.(效率大大提升,但是系统开销大)
c) A去. 先去买肠粉,等待的过程中买蛋炒饭,等待的过程中买羊杂.这三份饭,哪个先做好了,哪个老板就喊一声饭好了.(喊一声就相当于epoll 事件通知/回调机制)
可以看到c方案的效率是最高的.此时A就能同时完成三件事.且三件事的交互不频繁,大部分时间都在等待.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!