3.5 RESOURCE ASSIGNMENT
发布时间:2024年01月08日
一旦内核启动,CUDA运行时系统将生成相应的线程网格。正如上一节所讨论的,这些线程被分配给逐个块执行资源。在当前一代硬件中,执行资源被组织成流式多处理器(SM)。图3.12说明可以为每个SM分配多个线程块。每个设备都对可以分配给每个SM的块数量设置限制。例如,让我们考虑一个CUDA设备,该设备可能允许为每个SM分配最多8个块。在同时执行8个块所需的一种或多种资源类型短缺的情况下,CUDA运行时会自动减少分配给每个SM的块数量,直到其合并资源使用量低于限制。由于可以分配给每个SM的SM数量有限,并且可以分配给每个SM的块数量有限,因此可以在CUDA设备中主动执行的块数量也有限。大多数网格包含的块比这个数字多得多。运行时系统维护需要执行的块列表,并在之前分配的块完成执行时将新块分配给SM。
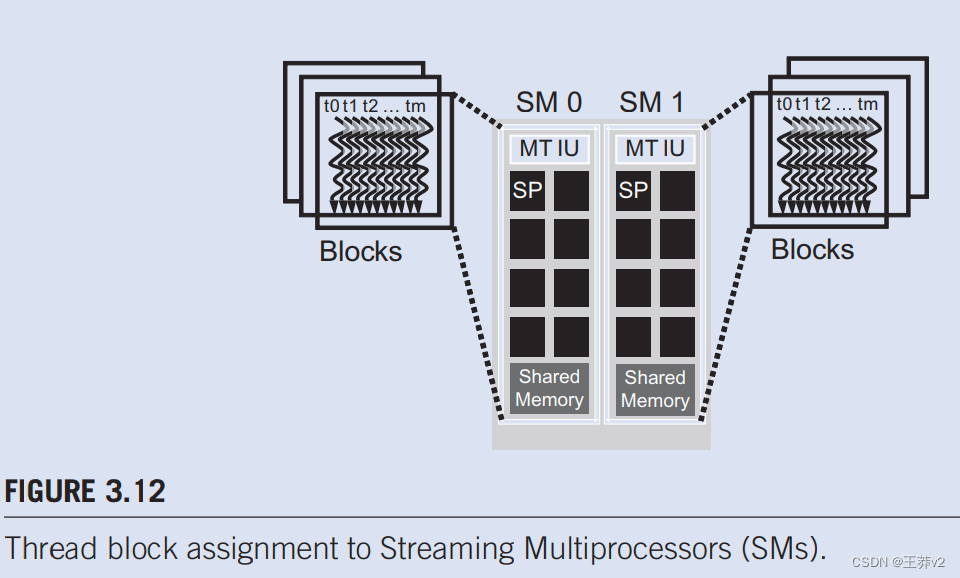
图3.12显示了为每个SM分配三个线程块的示例。SM资源限制之一是可以同时跟踪和调度的线程数量。SM需要硬件资源(内置寄存器)来维护线程和块索引并跟踪其执行状态。因此,每一代硬件都对可以分配给SM的块数和线程数设置了限制。例如,在Fermi架构中,每个SM最多可以分配8个块和1536个线程。这可以是6个块,每个256个线程,3个块,每个512个线程,以此为由之。如果设备在SM中只允许最多8个块,那么很明显,每个12个128个线程的12个块不是一个可行的选择。如果CUDA设备有30个SM,并且每个SM可以容纳多达1536个线程,则该设备可以同时拥有多达46,080个线程,同时驻留在CUDA设备中进行执行。
文章来源:https://blog.csdn.net/wangyifan123456zz/article/details/135458022
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!