(2021|WACV,TReCS,定位叙述数据集,图像分割,掩码到图像生成)基于细粒度用户注意力的文本到图像生成
Text-to-Image Generation Grounded by Fine-Grained User Attention
公和众和号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
Localized Narratives [29] 是一个包含图像详细自然语言描述的数据集,与鼠标轨迹(mouse traces)配对,提供了短小、细粒度的短语视觉基础。我们提出了 TReCS(Tag-Retrieve-Compose-Synthesize),这是一个利用这种基础来生成图像的顺序模型。TReCS 利用描述来检索分割掩模并预测与鼠标轨迹对齐的对象标签。这些对齐用于选择和定位掩模以生成完全覆盖的分割画布;最终图像是通过使用该画布的分割到图像生成器产生的。这种多步、基于检索的方法在自动度量和人工评估方面优于现有的直接文本到图像生成模型:总体而言,生成的图像更具照片般逼真,并更好地与描述相匹配。

2. TReCS 系统
定位叙述(Localized Narratives)数据集 [29] 提供了一种替代范例。与编写简短说明不同,标注者在描述图像的同时扫描鼠标指针,转录他们的描述,使文本和轨迹能够在时间上对齐(图1,顶部)。这些基于地面的叙述支持用户注意力基础的文本到图像生成任务 [29]:根据自由形式的叙述和对齐的轨迹生成图像(图1,底部)。
我们观察到领先的端到端文本到图像模型 [43, 40, 22] 的输出令人不满意;特别是,它们生成的图像捕捉了描述的视觉主旨,但缺乏清晰定义的对象和连贯的组合。受到像 SPADE [28] 这样的模型在给定金标准分割掩模时可以产生逼真图像的启发,[29] 简要概述了一种基于掩模检索和组合的替代方法,然后是分割到图像的生成。我们发现这种方法在某些情况下能够产生可识别的对象,但也经常产生空白图像,这主要是由于叙述中对语言的有限使用。我们的 TRECS 系统(图 2)通过更好地建模语言与视觉元素的选择和放置之间的关系,显著增强了这种策略。?
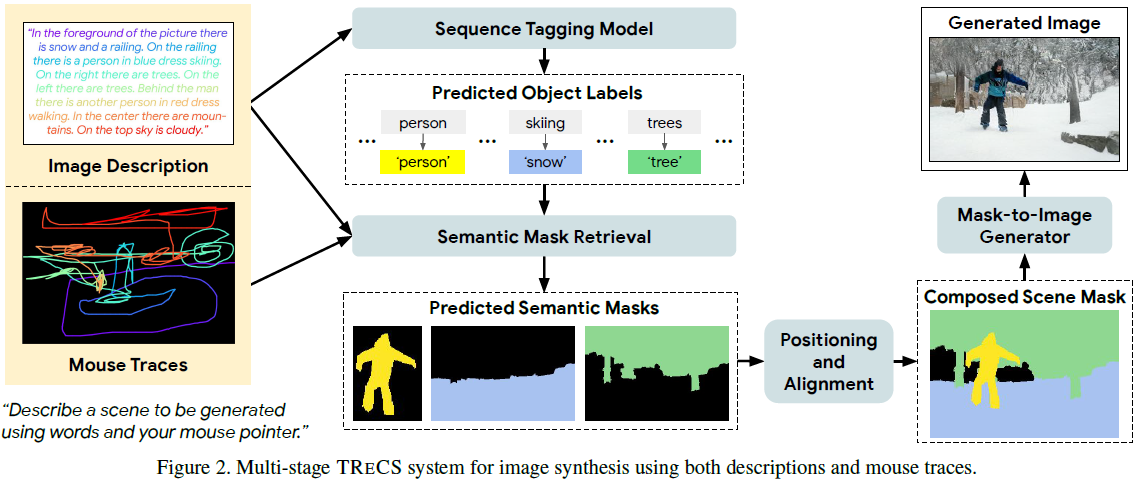
2.1 使用像素语义的序列标注
在定位叙述(Localized Narratives)中,轨迹覆盖图像的一小部分像素,但它们与叙述的细粒度对齐使它们成为描述物品放置和尺度的有价值的指标。考虑到这两方面的信息,一个熟练的艺术家可以渲染一个能够在视觉上捕捉叙述的场景。通常用于文本到图像生成的数据集,例如 COCO [23]、Caltech-UCSD Birds [39] 和 Oxford Flowers-102 [26],并不包含这样细粒度的描述。后两者还缺乏在描述和图像方面的多样性。

TRECS 利用单词-轨迹对齐和转移信息,为训练集叙述中的每个单词分配图像标签(图 3)。这些用于训练 BERT [8] 模型,以预测新叙述的标签。为了解决轨迹和对齐中的噪声,我们结合了三种长期存在的方法来自动优化单词-物体分配:tf-idf 加权 [25]、IBM Model 1 [4] 和隐马尔可夫模型 [30]。我们利用两个关键观察:(1)叙述提到在图像中存在的物品,和(2)轨迹穿过连贯的图像区域,因此提供有用的类别转换信息(例如,“云” 标签经常出现在 “天空” 标签旁边)。为了提取图像的语义标签,我们依赖于 COCO-Stuff 数据集 [5],该数据集为定位叙述的 COCO 部分提供了像素级的语义分割掩模。?
作为起点,我们直接使用训练集中每个图像的单词-轨迹对齐和黄金标准分割掩模,用图像标签标记其叙述。对于给定的短语及其对应的轨迹,我们获取轨迹的凸包并确定在其中最频繁分配的图像标签。此标签被分配给短语中的所有单词。与仅使用轨迹相比,使用凸包减少了噪声,特别是当标注者用鼠标指针画圈来描述物品时(描述对象时的一种常见方法)。这产生了这样的分配:

![]()
单词并不总是与它们分配的标签匹配,但整体短语范围与访问带有这些标签的图像区域的轨迹相对应。然而,强烈的单词-标签关联被忽略了,导致明显不合适的标签,如 he/snow 和 ski/other。?
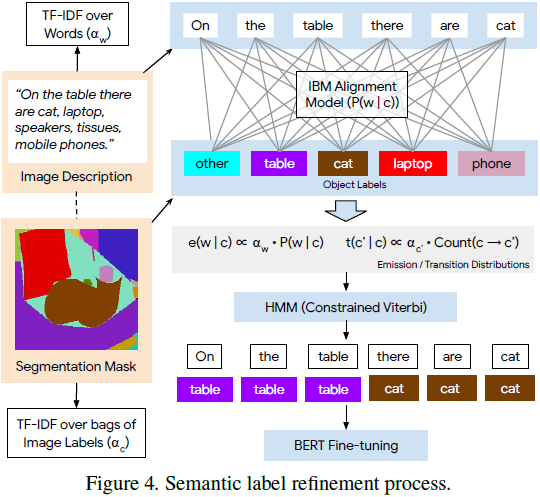
受限的标签细化。我们将这些分配与若干进一步的步骤结合起来,以获得更清晰的分配(图 4)。首先,我们计算每个词 w 在词汇表中的词频逆文档频率(term frequency-inverse document frequency,tf-idf)得分 α_w,将每个叙述视为一个文档。我们使用这些得分来减少常见、无信息的短语的影响(例如 “in the image”)。图像标签 c 的 tf-idf 得分 α_c 也类似地计算。接下来,我们通过将每个叙述与相应的图像标签包配对,并在此语料库上训练 IBM Model1 来学习单词-标签对齐。从中,我们获得了转换概率 P(w|c)。
我们用这些构建块构建了一个HMM。通过使用 α_c 得分对转换概率进行缩放来获得发射分布(emission distributions):
![]()
同样,转换概率被定义为:
![]()
其中,计数是从上述讨论的有噪的词-迹分配中获得的。对于这两个分布,我们使用 Add-1 平滑。最后,我们缩放转换的贡献:对于给定的步骤,我们使用 e(w?| c')·t(c' | c)^10,这是为了允许由于尖锐的发射而导致的标签翻转。为了给训练句子分配标签(如下一节所述,用于自动监督BERT),我们将维特比解码限制为仅对图像本身上注释的那些图像标签。HMM 生成更合适和语义对齐的标签;例如,上述叙述被标记为:

自动监督训练。当人工标注的数据稀缺时,具有强初始化的弱生成模型可以为更强大的模型标记示例,从而实现更好的泛化。Garrette 和 Baldridge(2012)[11] 表明,这种自动监督训练对于资源稀缺的词性标注是有效的。在这里,我们使用受限的 HMM 标签对一个预训练的 BERT 模型 [8] 进行微调。我们对序列标签进行了视觉检查,发现这提高了标签质量(请注意,没有每个单词图像类别的黄金标准注释),同时提高了最终图像生成质量(详细结果见第 4.2 节)。
2.2 语义对齐掩码检索
对于我们希望生成图像的叙述,BERT 标注器检测必须在 TRECS 最终生成的图像中包含的图像类别。我们通过以下方式准备完整的语义场景分割:(1)识别与检测到的类别相匹配的掩码,(2)与叙述相关,(3)在空间上与迹线对齐。
我们训练一个跨模态的双编码器来检索与叙述最匹配的 k 个训练集图像,然后从这些图像中选择检测到的类别的 COCO-Stuff 掩码。对于每个检测到的类别实例 c_i,我们从前 k 个图像中提取与该类别匹配的掩码;为了满足空间对齐,对于与实例 i 的迹线对应的凸包 S_i,我们选择与其平均交并比(mIOU)最高的掩码 m_i:
![]()
其中,M_ci,j 表示第 j 个检索图像的第 ci 个类别的掩码实例。
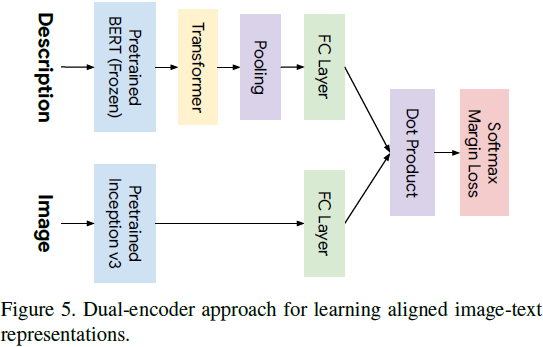
我们训练了一个图像-文本双编码器(图 5)[12, 6, 41],用于跨模态检索 [10],使用 Parekh 等人(2020)[27] 的模型和代码。对于文本,我们提取预训练的 BERT 嵌入,然后将其传递到一个具有 8 个注意头和 128 个隐藏单元的 1 层 transformer 中。输出传递到一个全连接层,将它们映射到R^2048。对于图像,我们使用在训练期间进行微调的预训练 Inception v3 模型 [35]。
在之前的工作 [17, 27] 的基础上,我们在 Conceptual Captions [33] 上进行预训练,然后在 LN-COCO(MS-COCO 图像的定位叙述部分)上进行训练。该模型通过最小化同一批次中来自负样本的 softmax 边际损失进行训练 [41],该过程在每个批次中模拟图像-标题和标题-图像检索。
2.3 掩码组合
在第二阶段选择的掩码必须被组合起来,以表示场景为一个完整的语义分割(图 2,右下角),并与语言和空间描述保持一致。物体(thing)类别(例如人,猫,飞机)具有特定的大小,形状和可识别的特征,而背景(stuff)类别(例如草,天空,水)是无定形的 [5]。stuff 掩码通常也更大,因此如果不小心的话,它们通常会遮挡 thing 掩码。在这里,我们使用一个简单但有效的策略,分别为 thing(前景)和 stuff(背景)掩码提出了组合层,然后将前者叠加在后者上。
thing 层是通过将每个掩码居中在其相应的迹线集上创建的。它们按照它们在叙述中出现的相反顺序放置 - 这是一个良好的默认策略,因为注释者倾向于在不那么显着的细节之前描述显著的物体。这种策略对于 stuff 层效果较差,因为掩码较大且彼此冲突 - 因此,以这种方式组成的许多背景场景可能只包含一两个 stuff 类别。为了解决这个问题,我们改用来自单个图像的完整语义分割图 - 对于从叙述和相应的迹线中识别的 stuff 凸包,分割图具有与其有最高 mIOU 的 stuff 对象。由于它们源自实际图像,因此这些背景 stuff 掩码在叙述和彼此之间在语义上是一致的。最后,未与明确语义掩码相关联的像素被分配给与最接近的 stuff 像素的类标签。除了提供更一致的背景外,这也减少了生成的图像中具有大面积空白区域的数量。
2.4 掩码到图像的转换
TRECS 的前三个阶段构建了一个新颖的对应于描述和迹线的场景分割。最后一阶段旨在在给定完整场景分割的情况下生成一张逼真的图像。与自由形式的文本到图像生成相比,从分割掩码生成要受到更多的限制。掩码到图像转换是一个近期取得显著进展的领域 [18, 38, 28, 24]。当为图像提供完整的分割掩码时,现有的网络能够生成高保真度的图像。
对于 TRECS 的最后阶段,我们尝试了两种最先进的掩码到图像生成模型:SPADE [28] 和 CC-FPSE [24],并发现 CC-FPSE 在我们的用例中效果更好(详见第 4.2 节)。SPADE 和 CC-FPSE由生成器和鉴别器组成,通过 GAN 框架 [13] 进行对抗训练。CC-FPSE 生成器使用条件卷积核学习了一个从掩码到图像的映射;每个卷积核的权重是基于掩码布局预测的。这使得模型能够根据每个空间位置的标签对生成过程进行明确控制。CC-FPSE 鉴别器整合了多尺度特征金字塔,促进更高保真度的细节和纹理。
TRECS 创建的场景分割掩码是由从不同图像中检索到的多个掩码组成的,并根据叙述的迹线放置,这与在黄金标准分割掩码上训练的 SPADE 和 CC-FPSE 存在不匹配。尽管如此,我们发现与直接的文本到图像生成相比,这种策略表现良好,如在第 4.1 节所示。?
4. 实验
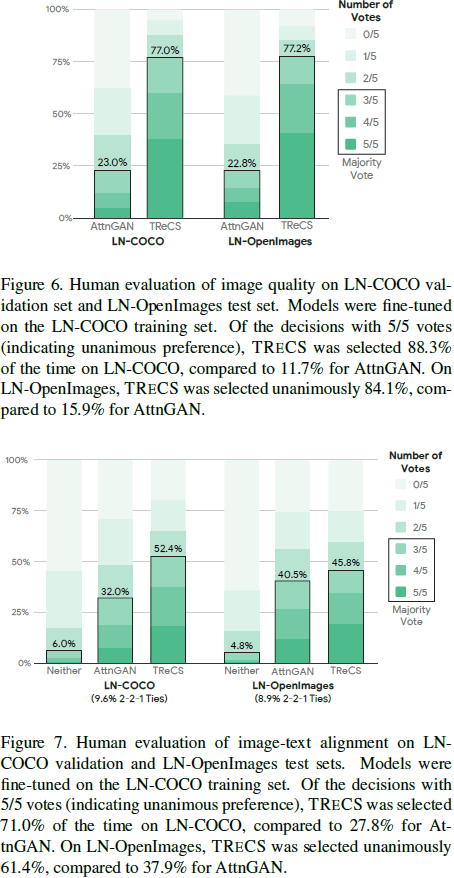
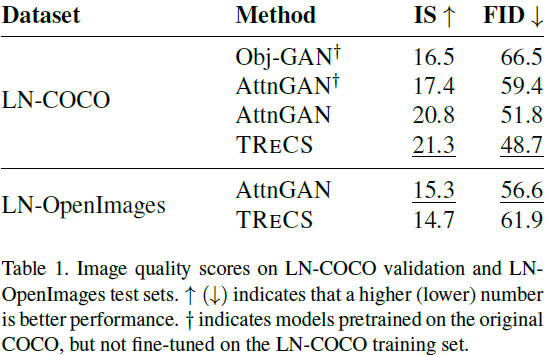
在人类评估(图像质量和图文对齐)和定量评估中,TRECS 表现良好。
?
S. 总结
S.1 主要贡献
Localized Narratives 是一个包含图像详细自然语言描述的数据集,文本描述与鼠标轨迹(划过的区域)在时间上对齐,提供了短小、细粒度的短语视觉基础。
基于此,本文提出了 TReCS(Tag?Retrieve?Compose?Synthesize)它利用描述来检索分割掩模并预测与鼠标轨迹(划过的区域)对齐的对象标签。这些对齐用于选择和定位掩模以生成完全覆盖的分割图,然后基于分割图生成图像。?
S.2 方法
标记-检索-组合-生成(Tag-Retrieve-Compose-Synthesize,TReCS)。
- 利用单词-轨迹对齐和转移信息,为训练集叙述中的每个单词分配图像标签。这些用于训练 BERT 模型,以预测新叙述的标签。
- 训练一个跨模态的双编码器来检索与叙述最匹配的 k 个训练集图像,然后从这些图像中选择检测到的类别的掩码。?
- 把在第二阶段选择的掩码组合起来,以表示场景为一个完整的语义分割(图 2,右下角),并与语言和空间描述保持一致。?
- 使用掩码到图像生成模型,基于组合的掩码生成图像。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据结构】栈和队列(栈的基本操作和基础知识)
- MFC 窗口创建过程与消息处理
- Bee的批量插入与事务使用
- 【Python】【Numpy】np.ma.array()函数详解和运行示例
- AUTOSAR从入门到精通-通信管理模块(CanNm)(二)
- STM32CubeMX教程26 FatFs 文件系统 - W25Q128读写
- 【一步一步学】ROS软路由设置代理IP教程
- Golang 里的 context
- nginx 一、安装与conf浅析
- 【AI】深度学习在编码中的应用(11)