随机森林中每个树模型分裂时的特征选取方式
随机森林中每个树模型分裂时的特征选取方式
随机森林中每个树模型的每次分裂都是基于随机选取的特征子集进行分裂的。
具体来说,对于每个决策树,在每个节点的分裂过程中,随机森林算法会从原始特征集合中随机选择一个特征子集,然后从该子集中选取最优的分裂特征。这种方式可以减少模型的方差,使得模型更加鲁棒,防止模型出现过拟合的现象。同时,由于每棵树都是使用不同的特征子集进行分裂的,因此每棵树的结构都不同,可以提高模型的多样性,进一步提高模型的泛化能力。
需要注意的是,每次分裂时使用的特征子集大小是可以调整的,可以根据数据集的大小和特征的数量来选择合适的值。通常来说,特征子集的大小一般设定为 m \sqrt{m} m?或者 l o g 2 m log_2{m} log2?m,其中m是原始特征集合的大小。
总之,随机森林中每个树模型的每次分裂都是基于随机选取的特征子集进行分裂的,这种方式可以提高模型的鲁棒性和泛化能力,防止模型出现过拟合现象。
这里又牵扯出另一个问题:为什么Bagging降低的是方差?Boosting降低的是偏差
先来了解什么是方差和偏差

至于为什么Bagging可以降低方差,可以通过数学推导来论证,这里我就不推导了,因为数学论证挺复杂的,这里就以我个人理解来回答为什么Bagging降低的是方差Boosting降低的是偏差,仅仅是个人理解啊,勿喷!
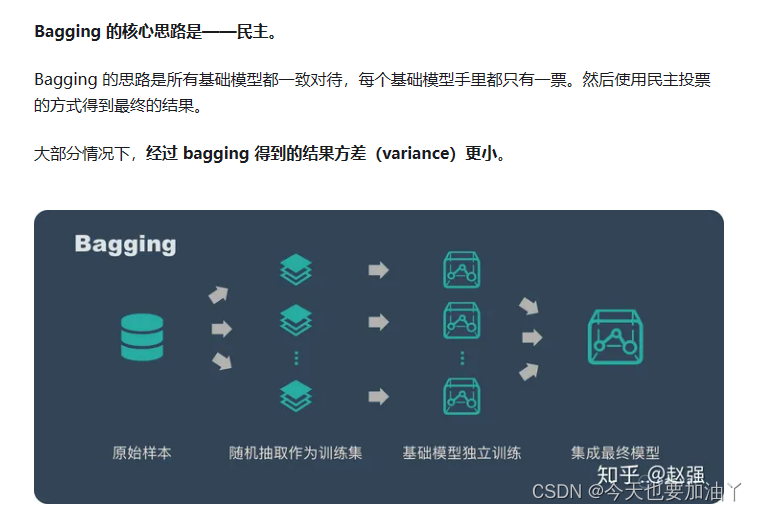
Bagging方法可以通俗理解为使用多个模型对数据进行训练,然后将它们的预测结果进行平均或投票,从而降低了单个模型预测的不稳定性,也就是降低了预测结果的方差。这样可以提高整体模型的稳定性和准确性。
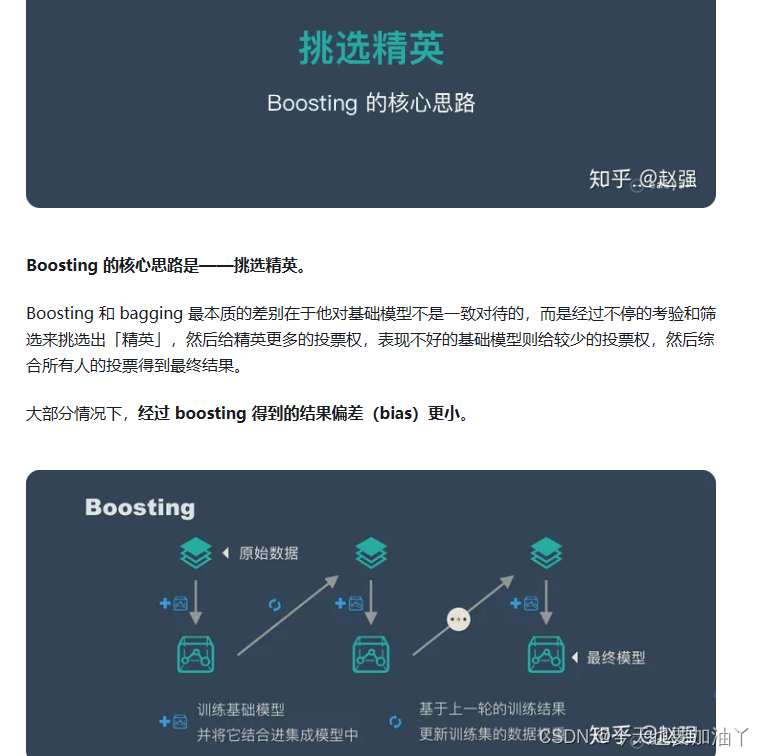
而Boosting方法可以通俗地理解为通过训练多个模型,然后根据前一个模型的表现对下一个模型的训练数据进行调整,以便提高整体模型的准确性。这样可以降低模型的偏差,因为每个新模型都会尝试修正前一个模型的错误,从而使最终的整体模型更加准确。所以,Boosting方法可以帮助降低模型的偏差,提高模型的准确性。
但Bagging不是总是有效的,Bagging提升模型效果的条件有三个:
- 弱评估器的偏差较低,特别地来说,弱分类器的准确率至少要达50%;
- 弱评估器之间相关性弱,最好相互独立;
- 弱评估器是方差较高,不稳定的评估器。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一键转换TXT文本编码,从UTF-8到ANSI,释放无限可能!
- 各类产业园区点位数据, Shp、excel数据,园区名称、类型、行业、批准时间均有所涉及
- STM32单片机输出频率及占空比可调的PWM波
- Vue v-model 详解
- 03-编码篇-x264编译与介绍
- LandrayOA内存调优 / JAVA内存调优 / Tomcat web.xml 超时时间调优实战
- 资源分享栏目一直会更新
- 关于log4j的那些坑
- Vue3的computed和watch
- Git指令集合