NLP论文阅读记录 - 2022 | W0S 基于文本概念的多目标剪枝观点文本摘要
文章目录
前言

Opinion texts summarization based on texts concepts with multi?objective pruning approach(2209)
0、论文摘要
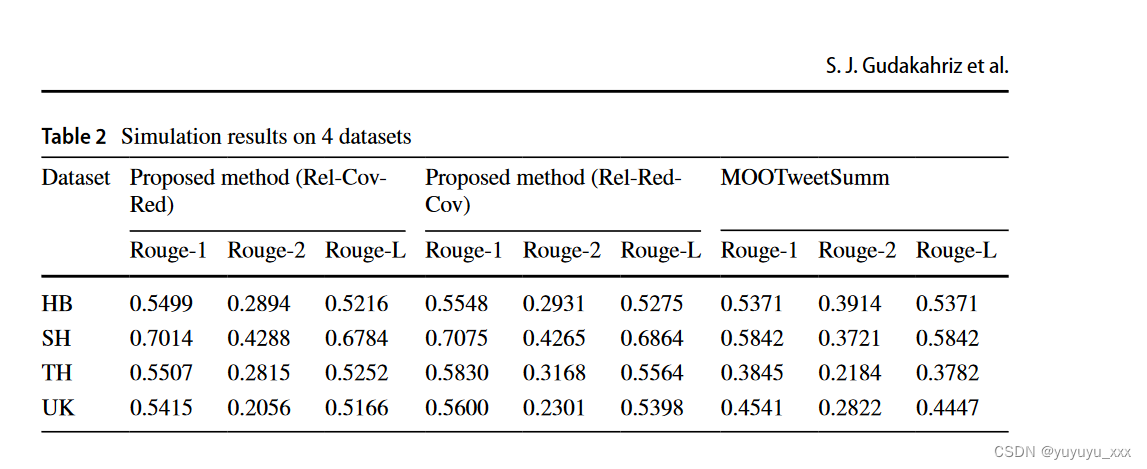
考虑到各种社交网络上发布的大量观点文本,阅读和使用这些文本极其困难。自动创建摘要可以为此类文本的用户提供很大帮助。当前的论文采用流形学习来缓解意见文本的复杂性和高维性以及用于聚类的 K-Means 算法的挑战。此外,基于文本概念的摘要可以提高摘要系统的性能。所提出的方法是无监督提取,并使用多目标修剪方法根据文本的概念进行摘要。用于执行多目标剪枝的主要参数包括相关性、冗余性和覆盖率。仿真结果表明,所提出的方法优于 MOOTweetSumm 方法,同时在 ROGUE-1 度量方面提高了 11%,在 ROGUE-L 度量方面提高了 9%。
一、Introduction
1.1目标问题
社交媒体上的通信导致创建和共享各种格式的大量数据,包括文本、音频、图像和视频。如此大量的数据可用于提取这些媒体平台中的模式和行为。这些平台上生成和共享的主要数据都是文本格式。这
数据需要进行汇总和缩小,以便于理解,从而使其易于各种应用程序访问[1]。有大量的应用程序,分析社交媒体上大量文本中表达的观点的可能性将使这些应用程序受益。因此,希望能够使用自动系统创建社交网络上发布的意见文本的摘要,并向用户提供这些摘要 [2, 3]。
意见和情感往往是由有相关经验的人表达的。顾客在购买商品或决定观看特定电影之前可能会征求其他人的意见,以根据其他人的经历了解对该特定行为的态度。此外,参与业务的人员一旦了解用户和/或客户的意见,就可以做出准确和优化的决策[4]。考虑到社交网络上发布的大量观点文本,个人很难轻松评估和利用这些观点。意见挖掘,也称为情感分析,是近十年来自然语言处理和计算机科学领域最活跃的研究领域之一。意见的目的是定义可以从意见文本中提取情感信息的自动工具。意见挖掘或情感分析有不同的领域,例如情感分类[5]、特征提取[6]和意见文本摘要[7]。意见文本的总结可以极大地帮助您从这些情绪中受益。本质上,在生成意见文本摘要后,用户可以轻松快速地使用这些文本。因此,研究人员越来越有兴趣开发新的观点文本摘要方法 [8, 9]。
一般来说,摘要技术根据其方法可以分为两大类,即基于语法的和基于语义的[10, 11]。第一种方法利用句法解析器根据语法分析和表示文本。相比之下,基于语义的方法的主要目标是基于文本的语义表示进行摘要。在基于句法的方法中,识别句子、文本或文本片段的句法结构,然后基于识别的结构执行摘要。为了确定句法结构,使用了解析树和图等方法。在基于语义的方法中,识别句子、文本或文本片段的语义,这构成了摘要的基础。基于语法的方法的主要局限性是缺乏初始文本的语义表示。另一方面,基于语义的方法的主要局限性是它依赖于人类专业知识来创建领域和规则的选集。
如前所述,意见文本摘要的目标是接收社交网络上表达的一组意见,以创建有用的摘要,其中包括大多数初始文本的内容 [1,12,13]。总结社交网络上表达的观点和情绪是一个前沿研究领域,已经进行了大量研究来提高语言质量并减少摘要方法的冗余。然而,由于自然语言处理的复杂性以及文本的高复杂性和大量性,意见文本的摘要面临着众多挑战[8]。因此,有必要开发一种方法,可以通过降低文本的复杂性来进行摘要,并提供质量可接受的摘要。
1.2相关的尝试
因此,当前研究的主要目标是提出一种总结意见文本的方法,与现有方法相比,该方法可以提供可接受的总结准确性和质量。
1.3本文贡献
总之,我们的贡献如下:
? 我们提出了一种基于文本概念和聚类步骤降维的意见文本摘要新方法。
? 在所提出的方法中,使用基于相关性、冗余性和覆盖参数的多目标修剪机制来执行摘要。
二.文本摘要的文献综述和分类
本节回顾了相关文献和本文领域的背景。作为第一步,讨论了各种文本摘要方法以及这些方法的分类。然后,简要回顾了之前针对该主题的研究。
2.1文本摘要分类
自动文本摘要几十年来一直受到研究人员的关注。文本摘要由一个或多个文本组成,涵盖初始文本或多个文本的重要信息。然而,摘要的长度不到原文长度的一半,而且通常要小得多[14]。不同的研究总结方法有所不同。有些以可视化或统计的方式创建摘要,而有些则考虑文本摘要 [8]。概括方法根据不同的标准进行分类,如图1所示。
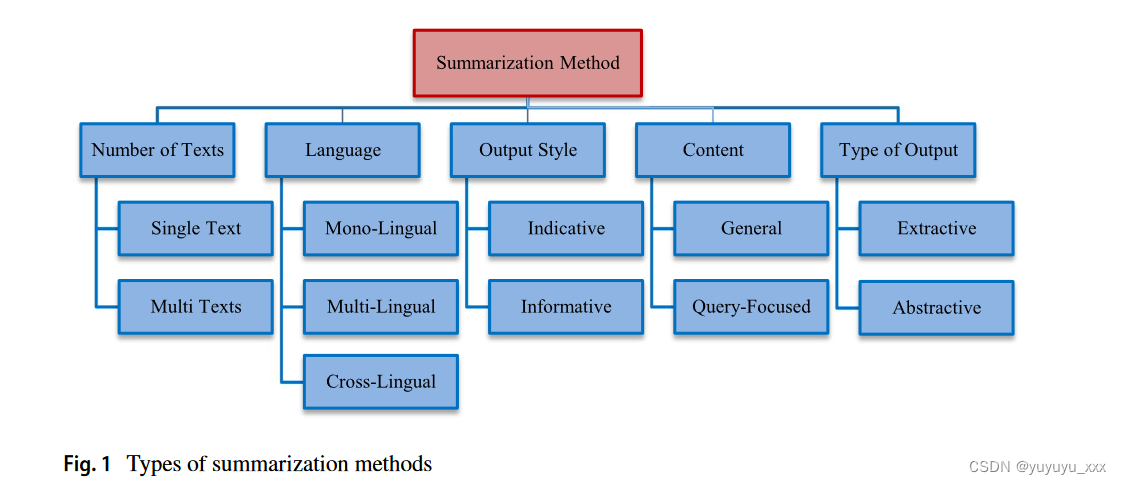
文本摘要的一种类型涉及单文档或多文档摘要[15]。在单文档摘要中,摘要是根据单个文本的内容创建的,而多文档摘要则使用各种文本来生成摘要[8]。从使用的语言来看,摘要有单语言、多语言和跨语言三种类型[16]。当被摘要文本的语言与摘要文本的语言相同时,摘要将被视为单语言。然而,当被概括的文本包括多种语言并且以其中一种语言进行概括时,该概括将被认为是多语言的。最后,当被总结的文本是一种语言时并且摘要是用另一种语言进行的,该摘要被认为是跨语言的。根据输出风格,还有指示性和信息性摘要[17]。指示性摘要的提取方式可以表达文本的主题。信息摘要的提取方式可以表达文本中包含的内容和信息。此外,生成的摘要还可以根据内容分为两大类,即一般或以查询为中心(或以主题为中心)和以用户为中心[18]。在以查询为中心的摘要中,摘要是根据与内容相关的查询(或问题)生成的,而在一般摘要中,摘要是根据对信息的一般看法生成的。
另一种重要且有用的文本摘要类型是基于输出的类型。在这种类型中,有两种类型的摘要,即提取摘要和抽象摘要[19]。抽取式摘要是从文本中提取代表性句子来表达文本的主要内容。从属句子的重要性取决于这些句子的统计和语言特征[10]。在抽象摘要中,创建文本摘要,其中包含与原始文本中不同的单词和句子;然而,生成的摘要的内容将表达原文的内容。本质上,在这种类型的摘要中,摘要是使用表达原始文本内容的新句子来生成的[20]。
2.2 以前的作品
本节回顾了之前的几篇专注于文本摘要的作品。一些研究将总结作为单目标问题来处理。这些作品包括[21-29],其中静态属性用于为文本分配值。在[21]中,Rudra 等人。根据重要实词(例如名词、动词和数字)的覆盖范围确定文本的价值。在[22]中,杜塔等人。提出了一种结合多种基本摘要算法的混合模型,以提供比每种基本算法生成的摘要更好的摘要。在[23]中,Garg 等人。提出一种基于聚类的总结方法,同时使用基于质心的方法为簇内的文本分配值的方法。在[24]中,Erkan 和 Radev 提出了一种基于图的随机方法。使用句子内余弦相似性准则作为句子的图形表示中的边的权重,同时使用相似性准则创建相似性矩阵。最后,应用阈值机制从相似度矩阵中识别和提取最重要的句子。在[25]中,Gong和Liu提出了一种无监督方法来提取信息,包括不同句子中使用的搭配和共享词。输入文本被转换为矩阵,其中行表示单个单词,列表示句子。最后,SVD [30] 应用于该矩阵以生成摘要。在[26]中,Luhn 通过确定高频和低频阈值来识别描述性单词。相应地,频率高于高频且低于低频的词语被剔除,而其余词语被选择作为表达原文重要内容的描述性词语。在[27]中,Radev 等人。提出了一种基于质心的多文档摘要方法。第一步,使用凝聚聚类来识别主题。然后,使用基于质心的方法来识别每个簇中的重要单词。在[28]中,Nenkova和Vanderwende提出了一种基于多文档频率的摘要方法。在该方法中,根据句子中单词出现的平均可能性为每个句子分配一个分数,然后选择得分最高的句子。在[29]中,Zhanying 等人。提出了一种基于数据重构的摘要框架,选择最能重构整个原始文本的句子作为摘要。
此外,在一些研究中,总结被视为多目标问题。其中一些研究包括[31-33]。在[31]中,Algholio 等人。提出一种单文档提取摘要方法。首先,使用 K-Means 算法对原文中的句子进行聚类,以发现文本中存在的所有主题。然后,为了选择簇中的重要句子,提出了一种优化模型,该模型使用满足为摘要选择的句子的覆盖范围和多样性的目标函数的均值和调和来优化目标函数。在[32]中,Chakrabouti 等人。将推文摘要视为多目标优化问题。选择三个关键特征,即相关性、多样性和覆盖率作为优化目标,其中目标是除了摘要之外还优化这些特征。在[33]中,Siney 等人。提出了一种基于多目标优化的推文摘要方法。使用多目标差分进化技术的查询能力同时优化各种标准,包括长度、TF-IDF、缺乏冗余以及摘要的不同方面的测量。
[34-39]中开展的工作重点是用于总结的聚类。在[34]中,杜塔等人。提出了一种基于推文相似度图的社区检测的推文摘要提取方法。在[35]中,朱等人。提出了一个中文微博意见挖掘系统,称为CMiner。获得意见的方面后,将意见的目标聚类为若干组,提取代表性目标,并对每组进行汇总。在[36]中,Jabrakumar 等人。提出了一种提取方法使用聚类技术对微博上发布的短文本进行摘要。为了识别每个集群中的优先和重要文本,使用了封闭词模型,并且还考虑了笑脸、主题标签和强调词的存在。为了减轻[37]中总结短文本的挑战,Neu 等人。提出了一种新方法,使用 BM25 为每个短文本分配权重并进行句法解析以产生重要信息。在[38]中,Waheeb 等人。提出了一种用于多文档阿拉伯文本摘要的无监督方法,其中使用聚类和 Word2Vec 模型来减少冗余。为了根据含义表示和存储文本,使用了 Word2Vec 模型,然后使用 K-Means 算法和余弦相似性标准根据距离标准从每个集合中选择不同的文档。 Yusho在[39]中提出了一种基于主题聚类的观点摘要方法。首先,根据模型对名词副词从句进行主题聚类。然后,从每个簇中选择多个名词副词从句来创建摘要。
基于语义的方法是情感摘要的重要方法之一。 Labourt 等人提出的工作。 [40]中的研究是少数专注于概念方法作为对观点进行抽象总结的尝试的研究之一。该方法简化了句子的语法,再现了句子,并提供了句子的概念表示来完成摘要过程。在[41]中,Amplayour和Sonagh提出了一种基于该模型的意见文本摘要新方法。在所提出的方法中,创建了一个用于对情感进行分类的模型,以及另一个用于提取意见方面的模型。然后,通过结合这两个模型的输出,对意见进行总结。在[42]中,Bahatia 等人。提出了一种基于使用 PCA 的方面的以查询为中心的提取摘要方法。在所提出的方法中,首先使用依赖规则提取主要方面。然后,从每个句子中提取与每个方面相关的意见。在[43]中,Raul 和 Maho 提出了一种分层摘要方法,用于在几个句子中总结大量意见文本。该方法首先使用四种基本方法将意见文本总结为一句话,包括 SumBasic、LSA、TextRank 和 LexRank。此外,在总结过程中还考虑了机器学习算法。在[44]中,Abdi 等人。提出了一种总结观点文本的方法。该方法是一种利用机器学习的提取方法。所提出的方法利用先验知识来识别每种情绪的类别和强度。然后,提取情感中存在的重要特征,并且该信息用于提取重要情感。在[45]中,Mauli 致力于总结长篇观点文本。所提出的方法以这样的方式总结长情感文本,即保留主要表达的情感并且不降低文本的可读性。
三.本文方法
3.1 总结为两阶段学习
3.1.1 基础系统
3.2 重构文本摘要
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
4.6 细粒度分析
五 总结
近年来,各种社交网络的使用显着增加,不同社会背景的人们以短文本的形式表达他们对各种问题的看法和观点。这些情绪和意见对于其他人来说是一个很好的决策来源,因为它们被用于不同的领域。由于这些文本的体量非常大,大家要分析和利用这些文本并不容易。因此,对这些观点文本的自动分析,特别是观点文本的摘要,可以在不同领域提供很大的帮助。总结观点文本时,目标是接收一组简短的文本,并对这些文本的观点和有用信息进行全面且有用的总结。在本文中,提出了一种总结意见文本的新方法。所提出的方法使用流形学习和这些文本中的概念对意见文本进行总结。因此,为了克服意见文本复杂性的挑战,首先使用流形学习来减少这些文本的维度。然后,使用文本中存在的概念作为基础,使用多目标修剪方法选择要添加到生成的摘要中的重要文本。为了生成高质量的摘要,根据相关性、冗余性和覆盖参数进行剪枝。基于Rel-Red-Cov和RelCov-Red的两种不同的剪枝方向应用于所提出的方法。模拟结果表明,Rel-Red-Cov 剪枝方向可以为意见文本的摘要提供更好的性能。此外,所提出的方法在 ROGUE-1、ROGUE-2 和 ROGUE-L 测量方面优于最先进的方法。
这项工作的局限性在于执行静态剪枝,并且 ROUGE-2 度量的改进微不足道。该领域的未来工作可以遵循两种不同的方法。在第一种方法中,可以评估修剪后的文本,如果修剪后的文本可以添加到最终摘要中,则可以再次将其添加到选定文本集中,我们也可以进行动态修剪。另外,由于ROGUE-2测度没有显着的改进,因此在制定剪枝参数时可以考虑这个问题,试图在该参数方面也达到显着的改进。
思考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 多个坐标点拟合平面方程(Java)
- nacos源码本地调试
- opencv003图像裁剪(应用NumPy矩阵的切片)
- hcip---ppp协议
- Citrix找不到ICAWebWrapper.msi所在的文件夹的路径
- 亚马逊鲲鹏系统:全自动多账号下单,打造真实浏览轨迹
- 学会这套Pytest接口自动化测试框架,击败99%的人
- 中山数字孪生赋能工业智能制造,助力制造业企业数字化转型
- 爱奇艺批量玩法以及技巧
- 数据处理系列课程 01:谈谈数据处理在数据分析中的重要性