GLM-4 能力接近ChatGPT4和Claude 2.1
本文以GLM-4 发布功能作为基准对比ChatGPT4,Claude-2测试。
输入测试用例是GLM-4提供,用专业性打败专业性才有趣!
以多模态理解,代码解释器,工具调用,逻辑推理方向测试。
1月16日,智谱AI首届技术开放日在京举办,智谱AI团队全面展示了其投身大模型事业三年多来所积累的技术成果,并发布了新一代基座大模型GLM-4。
多模态理解
GLM-4 进入体验地址,没有找到上传图片功能入口,找到官网Demo。就以官网这个张图片测试,能放到官网作为展示,肯定是有信心以此为宣传的。
GLM-4
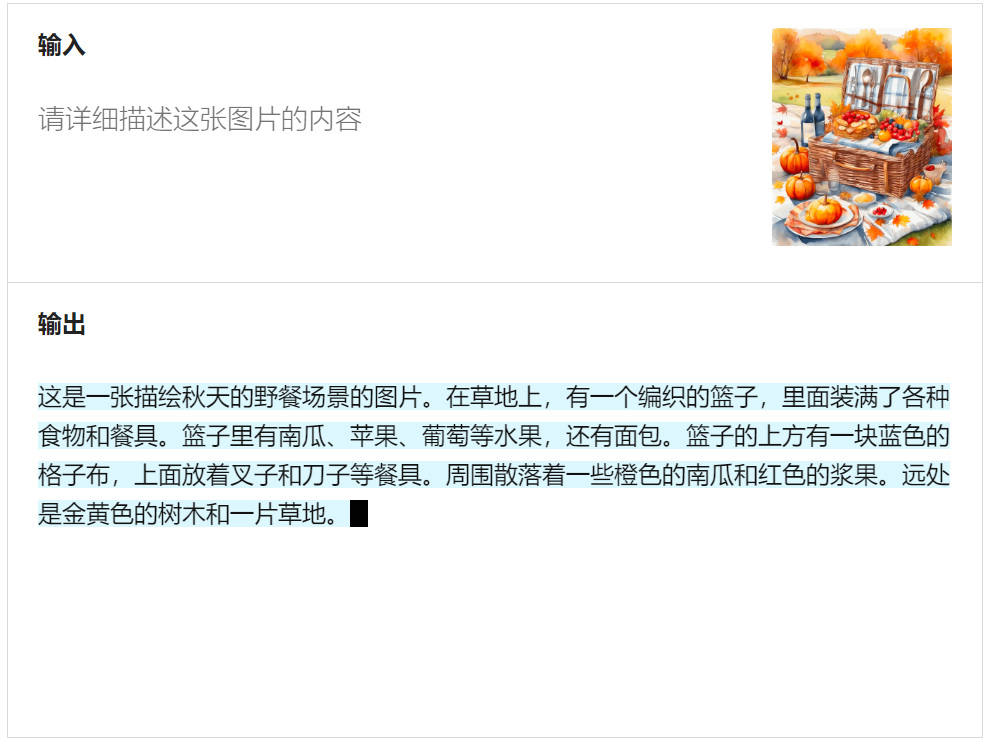
从写作手法分析
生成文字叙事性开头,开头句式 “这是一张描绘秋天的野餐场景的图片”,带有明确的叙事性,介绍图片内容。
描写的地方是描绘图片中的具体对象,如“编织的篮子”“里面装满了各种食物”“周围散落着一些橙色的南瓜”等,细致地描绘画面的细节。
没有议论地方。
ChatGPT4

从写作手法分析
叙事性:开头用“这幅画展示了一个秋天的野餐场景”引出全文,明确指出画作内容,具有叙事作用。
描写性:用大量笔触描绘画中的具体细节,如“打开的藤制野餐篮”“盛有橙色小南瓜的盘子”等,细致地描绘画面。
说明性:对一些要素进行补充解释,如“都拥有木质手柄”“一个小碗里可能是酱料”等,进行说明性叙述。
议论性:有少量个人观点,如“色彩鲜艳,给人一种温馨和宁静的感觉”,加入个人对画面的主观看法。
整体而言,以细致的描写为主,同时加入叙事引出画面,说明补充画面内容,融入少量个人观点,多种文学手法融合,形象丰富地呈现画面。
小结
GPT4 写作手法要比 GLM-4 更加精细。GPT4组合很多写作手法,细致描写手法穿插叙事。
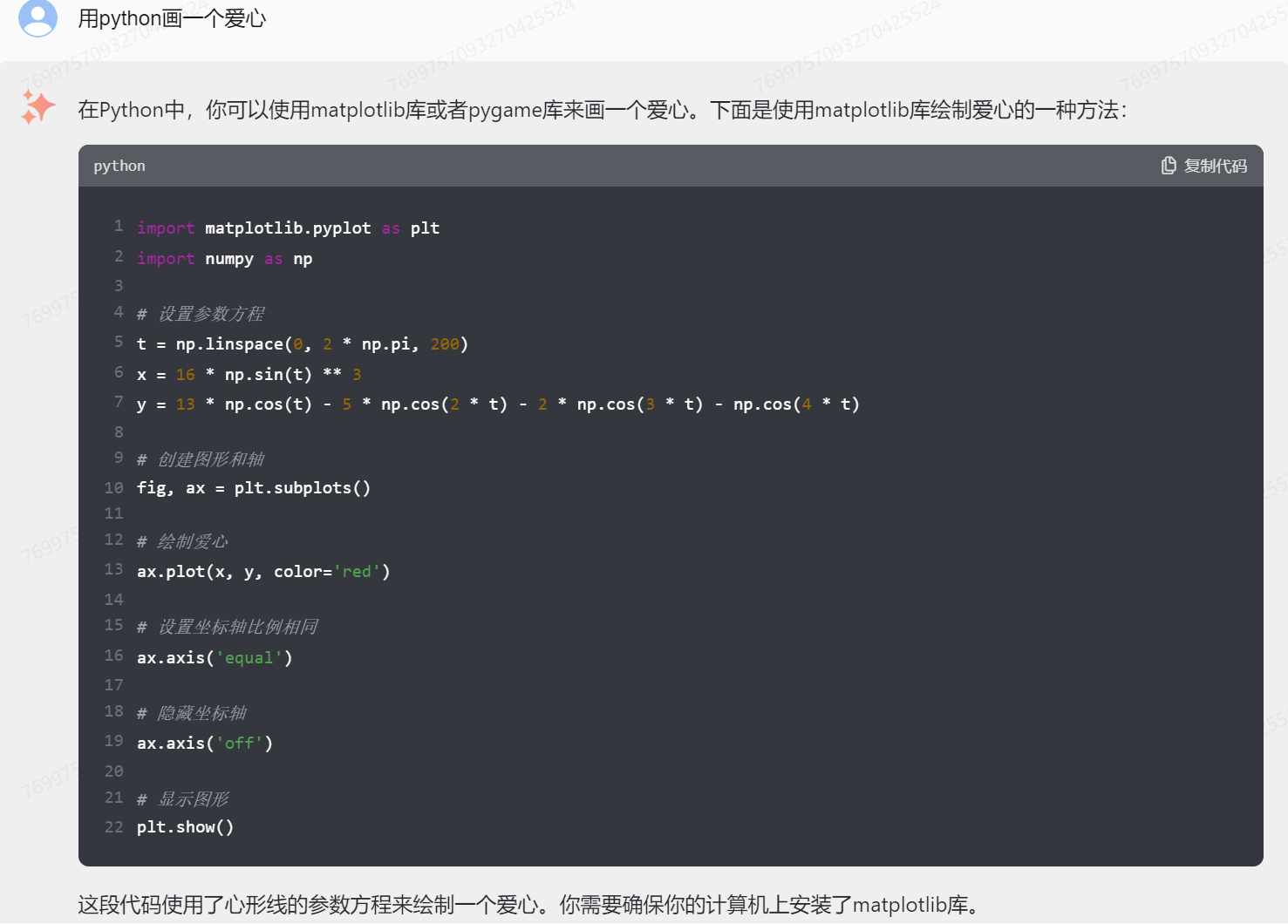
代码解释器
GLM-4

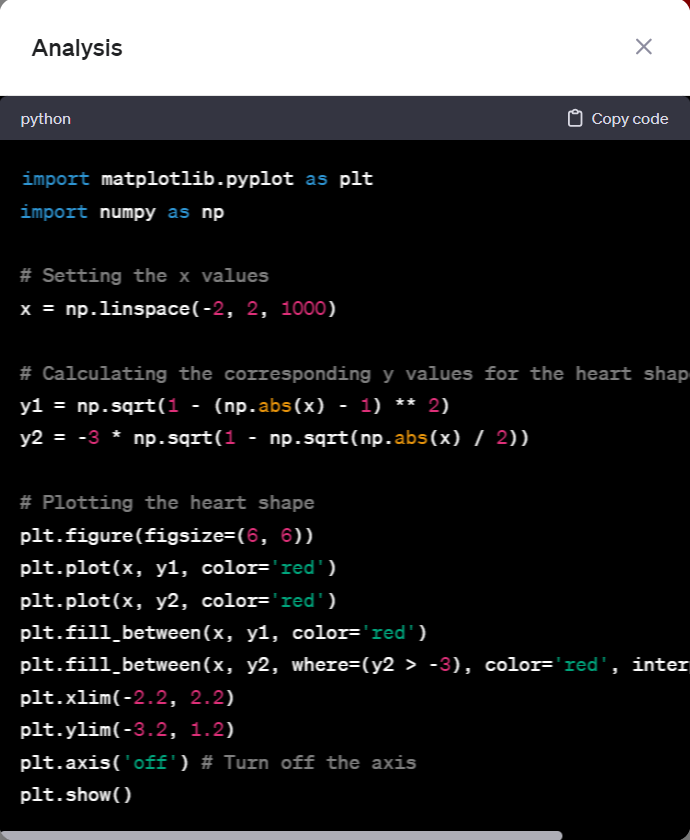
ChatGPT

小结
基本爱心形态都有,但是GPT4效果明显比GLM-4 更漂亮!
逻辑推理
GLM-4

ChatGPT

Claude-2

小结
** 逻辑推理能力GLM-4、ChatGPT、Claude-2不分伯仲!**
工具调用
GLM-4

ChatGPT

小结
不相伯仲!
GLM-4
新一代基座大模型GLM-4,整体性能相比GLM3全面提升60%,逼近GPT-4;支持更长上下文;更强的多模态;支持更快推理速度,更多并发,大大降低推理成本;同时GLM-4增强了智能体能力。
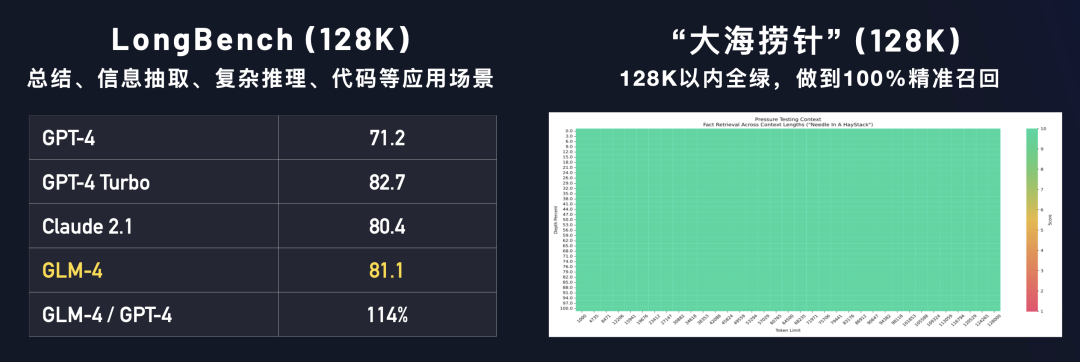
基础能力(英文):GLM-4 在 MMLU、GSM8K、MATH、BBH、HellaSwag、HumanEval等数据集上,分别达到GPT-4 94%、95%、91%、99%、90%、100%的水平。
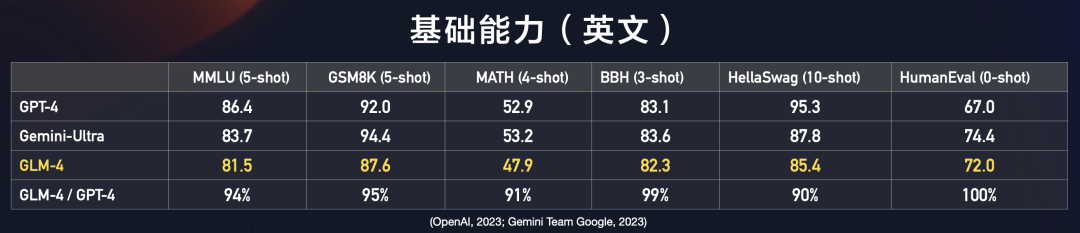
指令跟随能力:GLM-4在IFEval的prompt级别上中、英分别达到GPT-4的88%、85%的水平,在Instruction级别上中、英分别达到GPT-4的90%、89%的水平。
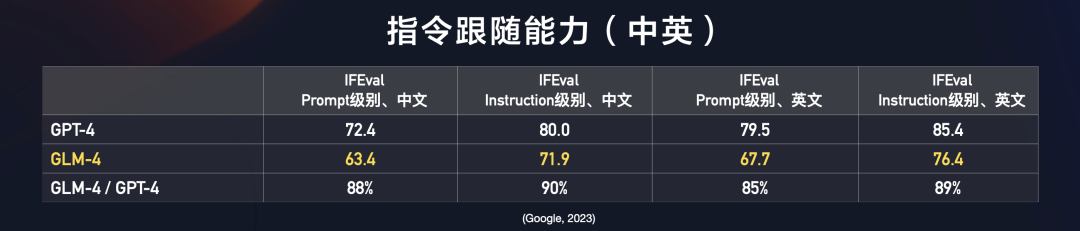
对齐能力:GLM-4在中文对齐能力上整体超过GPT-4。
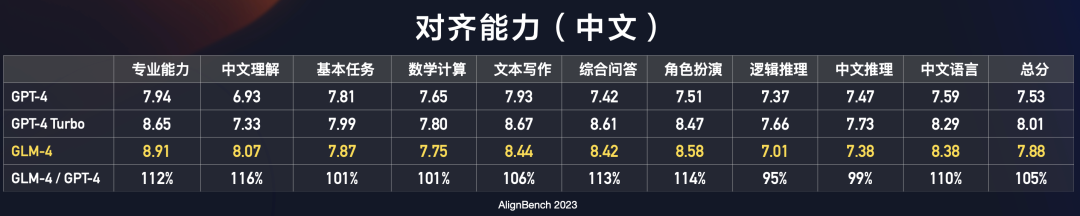
长文本能力:我们在LongBench(128K)测试集上对多个模型进行评测,GLM-4性能超过 Claude 2.1;在「大海捞针」(128K)实验中,GLM-4的测试结果为 128K以内全绿,做到100%精准召回。
多模态-文生图:CogView3在文生图多个评测指标上,相比DALLE3 约在 91.4% ~99.3%的水平之间。

结语
现在的基准测试,更多像商品宣传图,无法判断真实样子,使用一遍之后,知道模型下限在哪里!
GLM-4 工具调用,逻辑推理比较好,其他方面对比ChatGPT 和 Claude 2.1 还有距离,继续加油!
Claude 2.1 长文仍然是大哥!
欢迎留言交流!
独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- web前端开发网页制作html/css结课作业
- 当下行情,如何做空股票自我救赎?
- 【IC前端虚拟项目】MVU FS文档编写与注意事项
- 【深度学习入门】深度学习基础概念与原理
- 如何为不同品牌的笔记本电脑设置充电限制,这里提供详细步骤
- Danil Pristupov Fork(强大而易用的Git客户端) for Mac/Windows
- QT基础篇(16)QT5单元测试框架
- JavaScript防御性编程
- 大数据毕业设计:天气气象数据采集分析可视化大屏 爬虫+大数据+源码+论文?
- CentOS使用docker本地部署StackEdit Markdown编辑器并实现公网访问