看图识熊(五)
其它信息
点击界面右上角的齿轮,可以看到免费用户每个项目能够使用的服务额度:
一共可以上传5000张图片,创建50个不同标签,保存10次迭代的结果。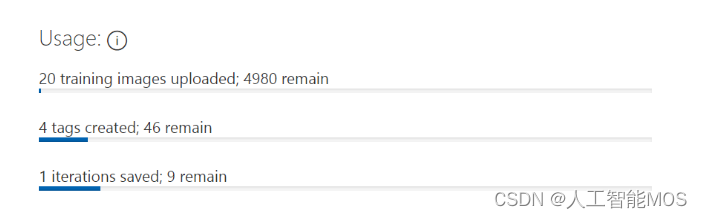
这十次迭代有什么用呢?当需要增删标签、给标签添加或删除训练图片时,这次再训练,就会花费掉一次迭代。
这些都是当前项目的总数而不是累计值。对于一般的免费用户,这基本上就相当于你可以随意使用这项服务了,如果有大量的训练数据,那么建议您还是订阅Azure云服务,Azure秉持着使用多少收费多少的原则,即使收费,也仍然良心。
导出模型
为了构建本地离线推理应用,我们需要下载模型。点击顶部Performance按钮回到训练结果页面并切换到要使用的Iteration,然后点击Export按钮,可以看到如下所示的导出页面。
定制化视觉服务一共提供了四种模型的导出,对三大操作系统都能支持,这里我们选择ONNX。
ONNX,全称Open Neural Network Exchange,即开放神经网络交换格式,是由微软、FaceBook等多个相关公司一起推动的深度学习模型标准。Microsoft Cognitive Toolkit、Caffe2、PyTorch等工具已经支持ONNX。
选择ONNX后,在Choose a version下拉框中选择ONNX1.2,点击Export,等待服务器把模型导出后,然后点击Download,即可下载模型,这里将名字改为BearModel.onnx。
注意,存放模型文件的路径不要包含中文。
查看模型
Netron是一个开源的模型信息的查看器,支持多种模型格式,可以下载安装使用,也可以在线查看模型信息。
Netron打开后,点击Open model选择打开之前下载的BearModel.onnx文件。然后点击左上角的汉堡菜单显示模型的输入输出。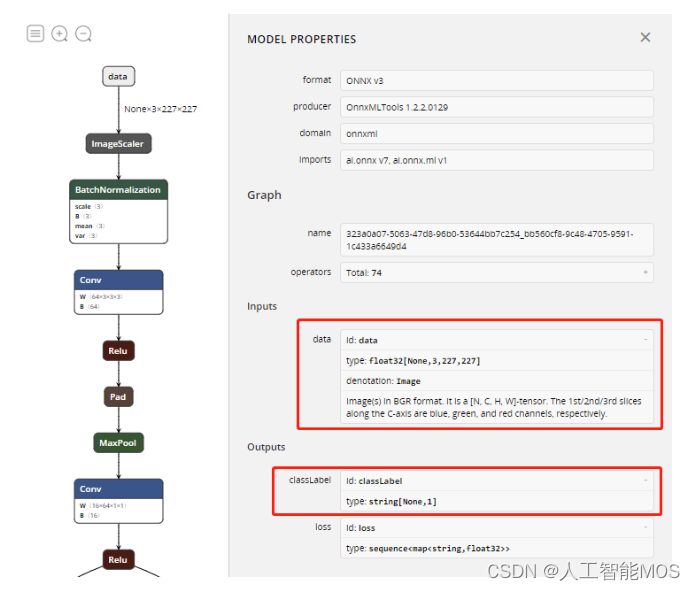
上图中可以看到该模型需要的输入data是一个float数组,数组中要求依次放置227*227图片的所有蓝色分量、绿色分量和红色分量,后面程序中调用时要对输入图片做相应的处理。
上图中还可以看到输出有两个值,第一个值classLabel是确定的分类的标签,这里只需用到第二个输出即可,第二个值loss包含所有分类的得分。
构建应用
模型有了之后,这里就可着手构建应用程序来使用模型了。
这里以Windows平台为例,应用程序使用C#语言。我们有三种方案:
-
使用Windows Machine Learning加载模型并推理,这种方式要求系统必须是Windows 10,版本号大于等于17763,详细步骤在这个文档
-
使用ONNX Runtime加载模型并推理。这是微软开源项目,会持续更新,跨平台、跨语言,而且支持CPU、GPU推理,使用也十分方便。详细步骤在这个文档
-
不推荐使用 Tools for AI对模型进行封装,可以运行在 Windows 7 或 Windows 10,但目前仅支持x64平台,详细步骤在这个文档
小结
我们回顾一下本案例体验了哪些过程。首先,我们收集了一些数据,并给它们进行了分类。然后,使用定制化视觉服务训练并导出了模型。再然后就是代码部分,设计了界面、让它与代码能够联动。再然后就是代码中比较复杂的部分,即数据的规范化。最后的推理预测其实只有一行代码就够了。完成后,我们又添加新数据重新训练了一遍。
这个案例很简单,主要是希望大家体验一下AI应用开发。其实AI应用开发和我们传统的应用开发没有太大区别,可以认为就是调用了一个神奇的函数,给它一些数据,它就还给你一个答案。如果多有几个神奇的函数,那么就能做出更加智能的程序,就成为了真正的产品了。
最后,给大家留个小作业:大家可以用卡通熊或者毛绒熊玩具的照片测试一下,然后考虑如何能把这几种熊从真实熊的照片中区分出来。完成后可以找出一些新的卡通熊或毛绒熊图片进行测试,看看能否达到较好的分类效果。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!