Flink运行架构以及容错机制
Flink运行架构以及容错机制
flink是一个开发框架,用于进行数据批处理,本文主要探讨Flink任务运行的的架构。由于在日常生产环境中,常用的是flink on yarn 和flink on k8s两种类型的模式,因此本文也主要探讨这两种类型的异同,以及不同角色的容错机制。
1. Flink的角色区分
1.1 JM
JM是一个独立的JVM进程,在HA场景下一个App能够同时启动多个JM,通常通过ZK进行选主,只有一个JM是active状态,其他的JM处于standby状态。
具有许多与协调 Flink 应用程序的分布式执行有关的职责:
- 决定何时调度下一个 task(或一组 task)
- 对完成的 task 或执行失败做出反应
- 协调 checkpoint
- 并且协调从失败中恢复
- 等等
JM在flink任务中起到总体的协调作用。
1.2 TM
TM是一个独立的JVM进程,负责具体的任务执行。TM在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JM 处接收需要部署的 Task,部署启动后,与自己的上游建立连接,接收数据并处理。
1.3 SLOT
是集群的工作节点,每个 TM 最少持有 1 个 Slot,Slot 是 Flink 执行 Job 时的最小资源分配单位,在 Slot 中运行着具体的 Task 任务。
2. Flink-Cluster模式的任务提交流程
2.1 Flink On Yarn的任务提交流程
2.1.1 yarn相关概念
2.1.2 运行模式
2.1.2.1 Session-Cluster模式
Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。

2.1.2.2 PreJob-Cluster模式
一个任务会对应一个Job,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
- Session-Cluster模式和PreJob模式的问题
这两种模式程序的入口 main 方法都是在客户端执行的,在 main 方法开始执行直到 env.execute() 方法之前,客户端也需要做一些工作,即:
1,获取作业所需的依赖项;
2,通过执行环境分析并取得逻辑计划,即StreamGraph→JobGraph;
3,将依赖项和JobGraph上传到集群中。
只有在这些都完成之后,才会通过 env.execute() 方法触发 Flink 运行时真正地开始执行作业。如果所有用户都在客户端上提交作业,较大的依赖会消耗更多的带宽,而较复杂的作业逻辑翻译成 JobGraph 也需要吃掉更多的 CPU 和内存,客户端的资源反而会成为瓶颈——不管 Session 还是 Per-Job 模式都存在此问题。为了解决它,社区在传统部署模式的基础上实现了 Application 模式。
2.1.2.3 Application模式
在 Flink-1.11 版本之前 Flink on yarn 有两种部署的模式, session 模式和 per-job 模式,但是这两种模式都存在一定的问题,所以在最新的 Flink-1.11 版本中引入了新的部署模式即 application 模式,支持 yarn 和 k8s。
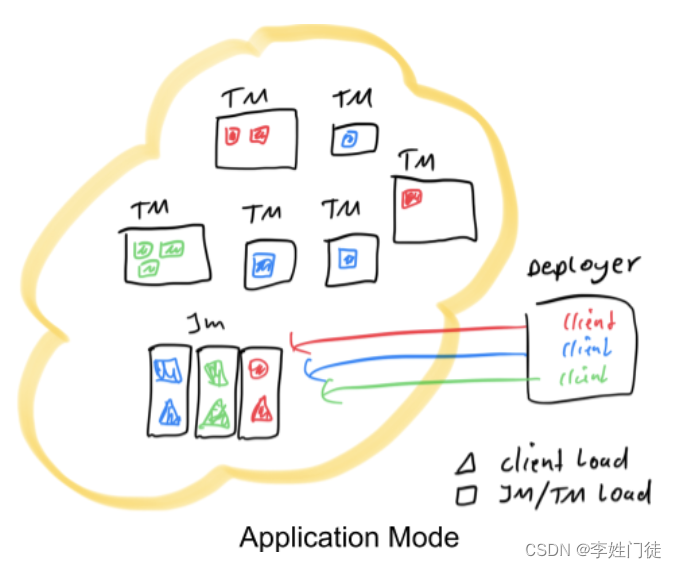
1, 原本需要客户端做的三件事被转移到了JobManager里,也就是说main()方法在集群中执行(入口点位于ApplicationClusterEntryPoint),Deployer只需要负责发起部署请求了。
2,如果一个main()方法中有多个env.execute()/executeAsync()调用,在Application模式下,这些作业会被视为属于同一个应用,在同一个集群中执行(如果在Per-Job模式下,就会启动多个集群)
2.1.3 任务提交流程
JM和AM是两个完全不同的东西,JM是控制Flink计算和任务资源的,而AM是控制yarn app运行和任务资源的。在Flink On Yarn模式中,JM运行在AM上,JM会和AM通信,资源的申请由AppMaster来完成,而任务的调度和执行则由JM完成,JM会通过与AppMaster通信来让TM的执行具体的任务。
任务提交流程图
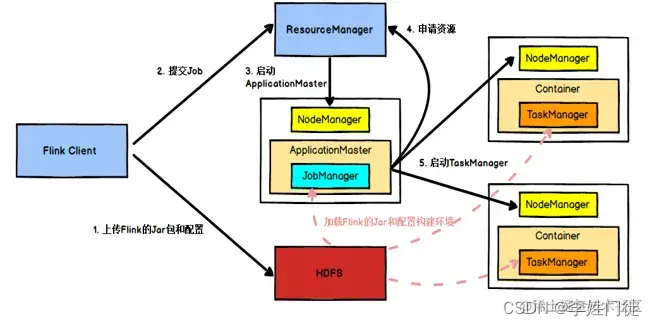
执行过程
- 提交App之前,先上传Flink的Jar包和配置到HDFS,以便JobManager和TaskManager共享HDFS的数据。
- 客户端向ResourceManager提交Job,ResouceManager接到请求后,先分配container资源,然后通知NodeManager启动ApplicationMaster。
- ApplicationMaster会加载HDFS的配置,启动对应的JobManager,然后JobManager会分析当前的作业图,将它转化成执行图(包含了所有可以并发执行的任务),从而知道当前需要的具体资源。
- 接着,JobManager会向ResourceManager申请资源,ResouceManager接到请求后,继续分配container资源,然后通知ApplictaionMaster启动更多的TaskManager(先分配好container资源,再启动TaskManager)。container在启动TaskManager时也会从HDFS加载数据。
- 最后,TaskManager启动后,会向JobManager发送心跳包。JobManager向TaskManager分配任务。
YARN-Cluster的执行,需要安装flink 客户端,并执行如下命令提交任务
bin/flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
2.2 Flink On K8S的任务提交流程
Flink 2.3开始,Flink官方就开始支持Kubernetes作为新的资源调度模式。
2.2.1 k8s相关概念
2.1.2 运行模式
- Flink session 模式
- Flink per-job 模式
- Flink native session 模式
- Flink native per-job 模式
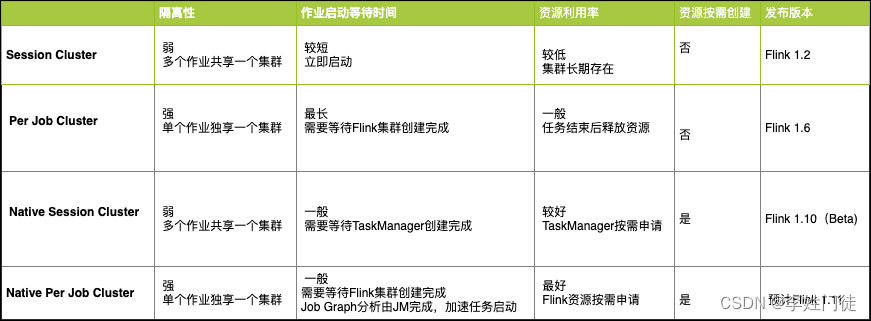
session模式和prejob模式跟yarn集群的模式类似,差别只是提交过程 有些异同。具体可以参考 Apache Flink on K8s:四种运行模式,我该选择哪种?
2.2.3 任务提交流程
总体提交流程如下
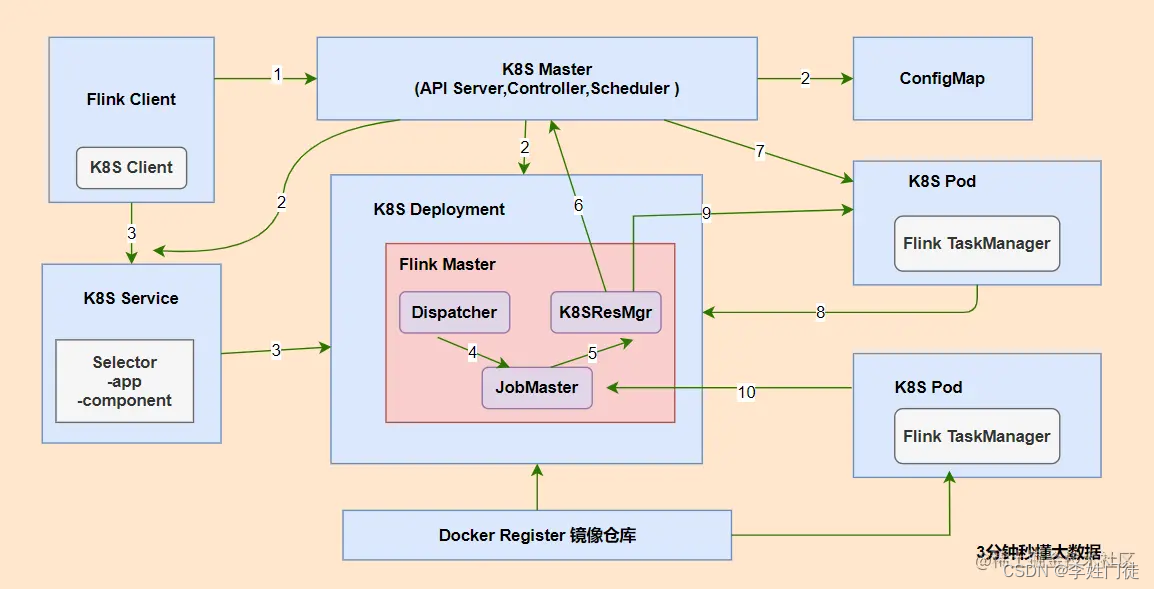
可以通过flink原生提交方式和 flink-on-k8s-operator提交 两种方式进行提交,两种方式实现上有些差异,但是总体流程是一致的。
1, flink原生提交方式
需要安装flink 客户端,并执行如下命令提交任务
./bin/flink run -m 192.168.244.131:8081 ./examples/batch/WordCount.jar --input aaa.txt --output bbb.txt/
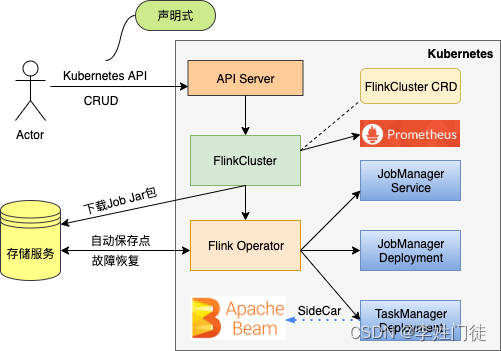
2, flink-on-k8s-operator提交
flink-on-k8s-operator[2],可以让用户以CRD(CustomResourceDefinition) [4] 的方式提交和管理Flink作业。这种方式能够更好的利用k8s原生的能力,具备更好的扩展性。并且在此之上增加了定时任务、重试、监控等一系列功能。具体的功能特性可以在github查看官方文档(kubernetes官方推荐)
需要
1, 需要提前在k8s集群中安装,此时会启动一个名为flinkoperator的pod
2,定义提交flink任务的相关CRD资源
3,提交作业时,无需准备一个具备Flink环境的Client,直接通过kubectl或者kubernetes api就可以提交Flink作业。
列入一个crd,命名flink.yaml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment # Flink集群在K8s的资源类型
metadata:
name: basic-example # 作业的名字
namespace: flink # 指定在flink命名空间下运行
spec:
image: flink:1.13.6 # Flink的镜像,改为使用1.13.6
# 如果官方Flink镜像下载不了,可以使用此镜像
# image: registry.cn-hangzhou.aliyuncs.com/cm_ns01/flink:1.13.6
flinkVersion: v1_13 # Flink的版本,与镜像版本保持一致
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
serviceAccount: flink
jobManager:
resource:
memory: "1024m"
cpu: 1
taskManager:
resource:
memory: "1024m"
cpu: 1
job:
jarURI: local:///opt/flink/examples/streaming/StateMachineExample.jar # Flink作业的启动类所在的Jar包路径
parallelism: 2
upgradeMode: stateless
执行如下命令即可启动相关的pod,并进行提交任务
kubectl apply -f flink.yaml
3. Flink-Cluster模式的容灾模式
3.1 JM容灾
同时部署多个JM,基于ZK进行选主,一个Job只有一个JM是active,其余是standby,如果active异常,standby进行竞争选主,进行HA容灾。
3.2 TM容灾
TM异常是日常生产环境中最常遇到的现象,造成的原因很多,最常见的是由于机器故障,从而导致就上运行的TM异常。
TM异常退出时,JM没有在规定时间内收到执行器的状态更新,于是JM会将注册的TM移除,并通过调度器自动重新拉起TM。新启动的TM会重新注册到JM中,JM会根据DAG给TM重新分配相关的Task。TM分配到到来自JM的Task,需要重checkpoint重新加载数据并继续执行计算。Flink运算数据行程DAG,如果遇到不同的TM之间有数据交互时(比如TMA的数据聚合依赖于TMB和TMC,TMB宕机,TMA的数据聚合也不准确),不能简单的通过启动对应的TM相关的数据进行恢复(可能会有数据紊乱),通常恢复的时间较久。
TM之间由于有复杂的数据交互,难以通过DAG重新计算局部TM任务资源恢复的成本很高,高于使用checkpoint进行任务恢复的成本,因此通常的做法是基于check进行任务重启。
4. 疑问和思考
4.1 是否可以部署多个JM,形成HA模式,如果主JM宕机,备JM自动接替?
可以,基于ZK进行选主。
5. 参考文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Maven环境的配置
- 软件设计师4--寻址方式
- 计算机速成课Crash Course - 18. 操作系统
- 【教学类-06-16】20231213 (按比例抽题+乱序or先加再减后乘)X-Y之间“加法减法乘法+-×混合题”
- 力扣题:高精度运算-1.3
- 信息安全等级保护的工作流程、内容及等级划分
- oj 1.9编程基础之顺序查找 10:找最大数序列
- java--拼图游戏
- 从0开始学C++ 第四课:常用C++编辑器和集成开发环境(IDE)的使用
- Java实现Excel导入和导出