基于电商场景的高并发RocketMQ实战-Commitlog基于内存的高并发写入优化、基于JVM offheap的内存读写分离机制
🌈🌈🌈🌈🌈🌈🌈🌈
【11来了】文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁
Commitlog 基于内存的高并发写入优化
首先,Commitlog 将数据写入磁盘使用的是 磁盘顺序写,这样带来的性能提升是很大的
但是仅仅使用磁盘顺序写,对写入性能的提升还是有限,于是还是用了 mapping 文件内存映射机制,即先把消息数据写入到内存中,再从内存将数据 异步 刷入到磁盘中去,那么就将 磁盘顺序写 又进一步优化为了 内存写 操作
那么通过内存映射优化写入过程,如下图红色部分:
总结:
那么这里基于磁盘顺序写,还添加了 mapping 文件映射机制 来进一步提升了文件性能,将磁盘顺序写优化为内存写操作!
基于 JVM offheap 的内存读写分离机制
broker busy 问题
一般来说,在服务器上部署了一个 java 应用之后,这个应用作为一个 jvm 进程在服务器运行,此时内存一般分为三种:
- jvm 堆内存:由 jvm 管理
- offheap 内存:jvm 堆外的内存
- page cache:操作系统管理的内存
那么通过将消息写入内存中的 page cache 中来大幅提高写消息的性能,但是在高并发的场景下,可能会出现 broker busy,也就是 broker 太繁忙,导致一些操作被阻塞,这是因为高并发下,大量读写操作对同一个 Commitlog 磁盘文件在内存中的映射文件 page cache 同时进行写操作,导致这一个 page cache 被竞争使用的太激烈
那么 RocketMQ 提供了 transientStorePoolEnabled(瞬时存储池启用) 机制来解决 broker busy 的问题,通过这个机制就可以实现 内存级别的读写分离
这个 transiendStorePoolEnabled 机制 也就是:在高并发消息写入 Broker 的时候,先将消息写在 JVM 的堆外内存中,有一个后台线程会定时将消息再刷入内存的 page cache 中,此时针对 MappedFile 的 page cache 的高并发写就转移到了 JVM 的堆外内存 中,而对于 Consumer 的高并发的读操作最终是落在了 MappedFile 的 page cache 中,实现了高并发读写的分离
总之呢,这个机制实现了高并发的读写分离,消费者高并发的读从 read queue 中读取数据,最终高并发的读肯定是落到了 MappedFile 的 page cache 中,而生产者高并发的写则是直接面向了 jvm offheap 堆外内存,就不会出现 MappedFile page cache 高并发情况下的争用问题了,如下图紫色部分:
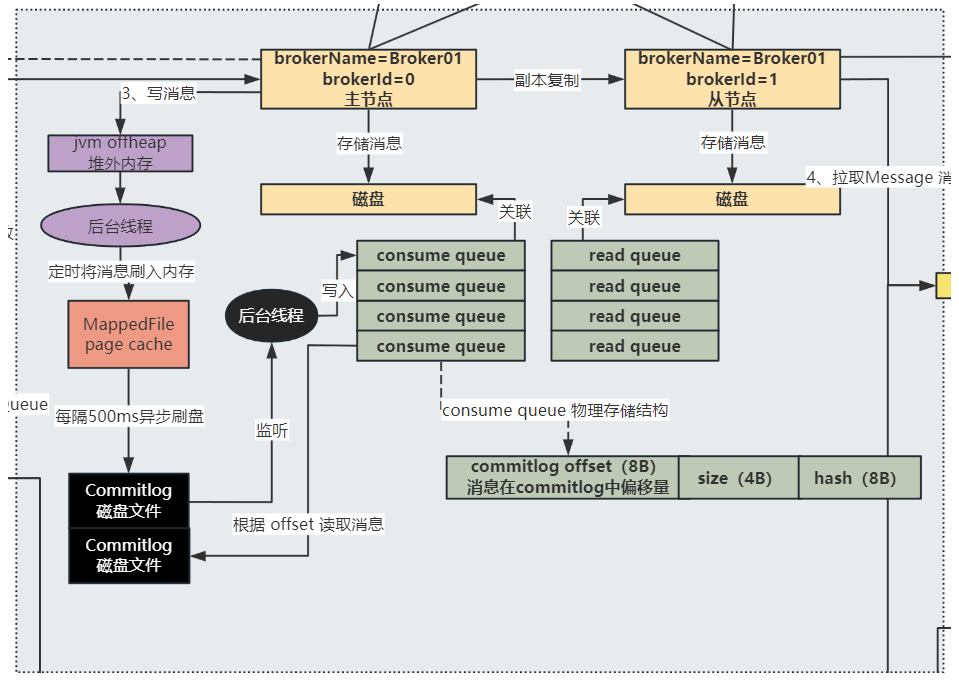
基于系统设计层面的考虑:
虽然使用 transiendStorePoolEnabled 机制可以提高高并发场景下 Broker 的读写性能,但是这可能会造成一定的数据丢失!
在这个机制之下,数据会先写入 jvm offheap 中,也就是堆外内存,如果 jvm 进程挂了,就会导致 jvm offheap 中的数据还没来得及刷到 MappedFile page cache 中就丢失了,而 jvm 进程挂掉的概率还是挺大的,因此这个机制是牺牲了一定的数据可靠性,来提升了性能!
所以,针对不同的场景,要做出不同的设计,如果是对消息严格要求可靠的金融等场景来说,那么就不能使用这个机制,其他情况下保持默认就可以了!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!