Python数据分析之Pandas的数据加载与预处理
一、数据分析
数据分析就是让看似杂乱无章的数据产生价值,通过数据的筛选、汇总等等操作将数据背后的信息集中和提炼出来,最终分析出一个结果或预测出事件的变化规律。

二、数据清洗
数据加载与预览
1、去除/填充有缺失的数据
2、去除/修改格式错误或内容错误的数据
3、去除/修改逻辑错误的数据
4、去除不需要的数据
5、关联性验证
三、Pandas简介
Pandas 库是一个基于NumPy的免费、开源的第三方 Python 库,是 Python 数据分析必不可少的工具之一,它为 Python 数据分析提供了高性能,且易于使用的数据结构,即 Series 和 DataFrame。Pandas 自诞生后被应用于众多的领域,比如财务系统、管理系统、金融、统计学、社会科学等。 Pandas享有Python数据分析“三剑客之一”的盛名,已经成为 Python 数据分析的必备高级工具
Pandas 主要是用作提炼数据使用
Numpy 则提供强大的科学计算
Matplotlib 负责数据可视化的操作
四、Pandas基本使用
1、常见格式数据读取
pd.read_excel() ?# 从excel的.xls或.xlsx格式读取表格数据
pd.read_csv() ? ?# 从csv文件读取数据
pd.read_table() ?# 从txt文件读取数据
pd.read_sql() ? ?# 将sql查询的结果(使用SQLAlchemy)读取为pandas的DataFrame
pd.read_html() ? # 读取网页中的表格数据
pd.read_json() ? # 从json字符串中读取数据
pd.read_xml # 从xml文件中读取数据

2、常用函数
data.shape ? ? ? # 数据维度,看看数据多少行,多少列
data.head(3) ? ? # 检查头数据
data.info() ? ? ?# 查看数据基本信息
data.dtypes # 查看数据类型
data.describe() ?# 查看数值数据统计信息
count:数量统计,此列共有多少有效值
unipue:不同的值有多少个
std:标准差
min:最小值
25%:四分之一分位数
50%:二分之一分位数
75%:四分之三分位数
max:最大值
mean:均值

3、数据存储
df.to_csv() # 存储为csv文件
df.to_excel() # 存储为excel文件
df.to_html() # 存储为html文件
df.to_json() # 存储为json文件
df.to_sql() # 存储为sql文件
4、查看指定多行、列
data.columns.tolist()
data[1:5]
data[[’ip’,’phone’]]


5、查看指定数据
data.loc[row,columns]??基于标签索引选取数据?前闭后闭
data.iloc[row,columns]?基于整数索引选取数据?前闭后开

6、缺失值检查与处理
data[data.isnull().values] # 查看缺失值

data.dropna() # 删除缺失值
data.fillna() # 填充缺失值
7、缺失值检查处理
data.isna().sum().sum() ?# 检查全部缺失值总数

data.isnull().sum() ? ? ?# 检查每列缺失值

# 将缺失值进行高亮?
(data[data.isnull().any(1) == True]
.style
.highlight_null(null_color='skyblue')
.set_table_attributes('style="font-size: 10px"'))
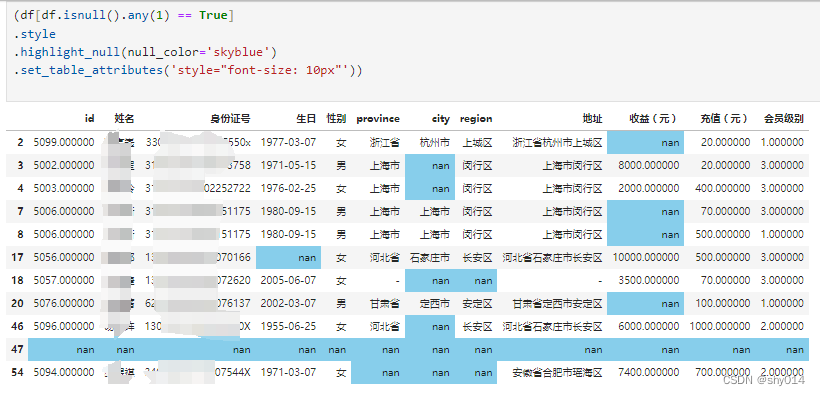
data1 = data.fillna('*********')?# 填充固定值

data2 = data.fillna(method='bfill')??# 向下填充
# # 均值填充
data3 = data['收益(元)'].fillna(data['收益(元)'].mean())
data3.map(lambda cell: '%.2f' % cell)
8、异常值检查与处理
# 大多数时候,我们是从csv文件中导入的数据,此时Dataframe中对应的时间列是字符串或时间戳的形式
# type(user['create_time'][1])
# 运用pd.to_datetime(),可以将对应的列转换为Pandas中的datetime64类型,便于后期的处理
user['create_time'] = pd.to_datetime(user['create_time'],unit='s')
user['create_time'] = user['create_time'].map(lambda x : pd.to_datetime(x,unit='s'))
type(user['create_time'][1])
# 时间序列的索引。和普通索引一样,调用.loc[row,columns]进行索引
user1 = user.set_index('create_time')
user1.loc['2022-05']
# 2022年5月-2022年7月的数据
user1.loc['2022-05':'2022-07’]
user[‘create_time’].dt.month
9、重复值检查与处理
data[data.duplicated()] # 筛选重复值所在行

data[data.duplicated([‘姓名’])] # 筛选指定列存在重复项所在的行

data.drop_duplicates() # 删除重复值所在行

10、数据修改
修改列名rename()
df.rename(columns={'姓名':'名字','性别':'男女'})

修改行索引set_index()
df.set_index('id',inplace=True) #指定字段,成为索引
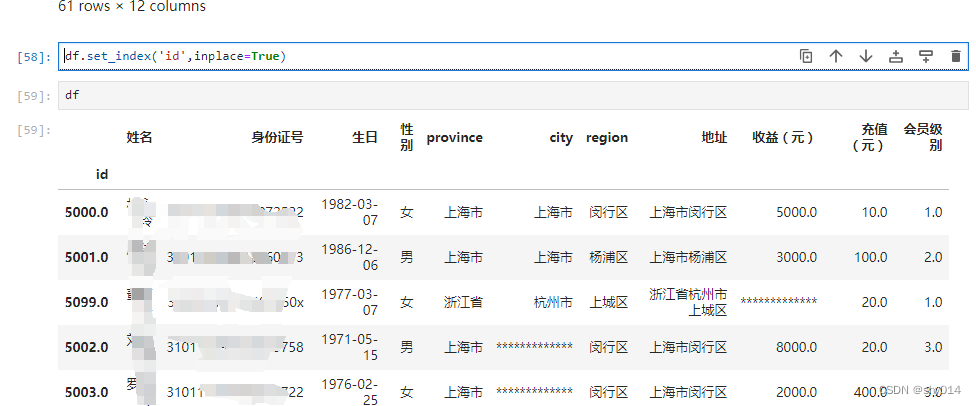
df.reset_index(inplace=True) #重置索引

df.drop(['index'])
修改索引名rename_axis()
# 修改索引名字 df.rename_axis('自加索引')
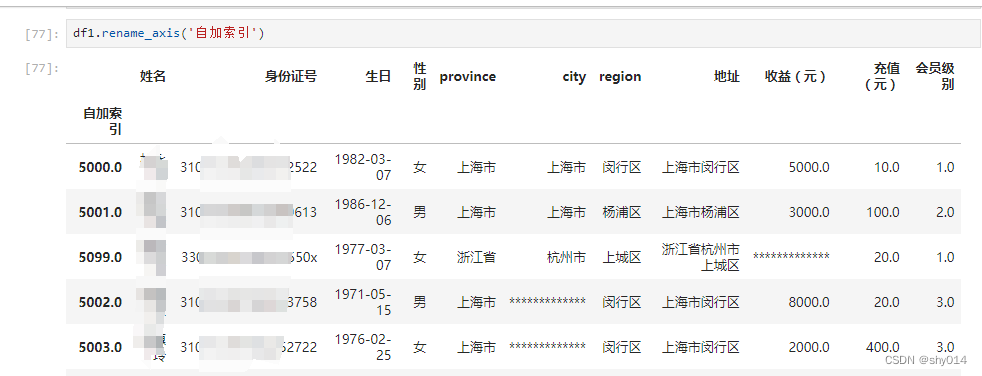
修改某一个值:df.iloc[0,1]='李三'

替换指定的值:
替换值(单值)replace()
将5000.0替换为4444:

替换值(多值)replace()
11、数据删除
1、删除指定行
df.drop(1)

2、删除条件行
删除id=5099.0的行
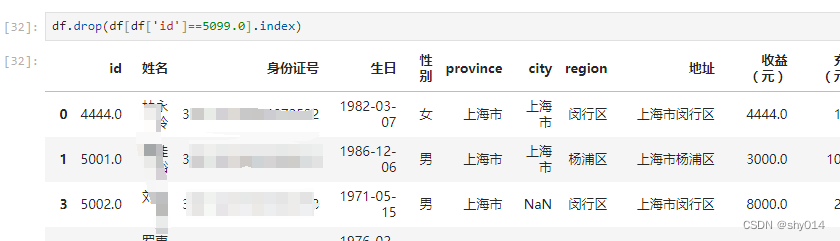
3、删除列
删除性别这一字段所在的列

4、按列号删除列

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024关于洋垃圾服务器避坑指南之CPU篇 #戴尔 #E5 #志强 #英特尔
- 【每日一题】构造限制重复的字符串
- SCT82A30大幅解决控制芯片发热难题,超宽输入电压范围,里程碑级作品
- linux下fdisk创建主分区、逻辑分区和扩展分区
- 【算法与数据结构】70、LeetCode爬楼梯
- 使用VS Code远程开发小游戏,并实现公网访问本地游戏
- Spring事务那些情况下会失效
- 渲染函数&JSX
- 【MySQL】创建和管理表
- Springboot+vue的工作流程管理系统(有报告),Javaee项目,springboot vue前后端分离项目