正则表达式和爬虫
发布时间:2024年01月16日
目录
一、正则表达式:
? ? ? ? 作用:
? ? ? ? ? ? ? ? 1、校验字符串是否满足规则
? ? ? ? ? ? ? ? 2、在一段文本中查找满足要求的内容(爬虫)
| [abc] | 只能是a,b或c |
| [^abc] | 除了这三个之外的任何字符 |
| [a-zA-Z] | a-z,A-Z(字符串出现的字符只要在两个范围(包括z,Z)之内就为true) |
| [a-d[m-p]] | a-d或者m-p |
| [a-z&&[def]] | a-z和def的交集 |
| [a-z&&[^bc]] | a-z和非def的交集(即:[ad-z]) |
| [a-z&&[^m-p]] | a-z和除了m-p的交集(即:[a-[q-z]]]) |
? ? ? ? ? ? ? ? 细节:如果要求两个范围的交集,那么需要写符号“&&”。如果写成一个&那么此时“&”表示的就不是交集了,而是一个简简单单的“&”符号。
System.out.println("&".matches("[a-z&&[def]]"));//false
System.out.println("&".matches("[a-z&[def]]"));//true?
| . | 任何字符 |
| \d | 一个数字[0-9] |
| \D | 非数字:[^0-9] |
| \s | 一个空白字符:[\t\n\x0B\f\r] |
| \S | 非空白字符 |
| \w | [a-za-Z_0-9]英文、数字、下划线 |
| \W | [^\w]一个非单词字符 |
? ? ? ? ? ? ? ? 细节:在Java中“\”为转义字符,表示改变后面那个字符原本的含义。双引号""在Java中表示字符串的开头或结尾。“\"”表示把"变成普普通通的"(仅仅只是一个符号,不具备任何含义)
“\\”表示把\变成普普通通的\
System.out.println("你a".matches("."));//false
System.out.println("你a".matches(".."));//true
System.out.println("你".matches("\\w"));//false
System.out.println("你".matches("\\W"));//true| X? | X出现一次或零次 |
| X* | X出现零次或多次 |
| X+ | X出现一次或多次 |
| X{n} | X出现正好n次 |
| X{n,} | X出现至少n次 |
| X{n,m} | X出现至少n次但不超过m次 |
二、爬虫
? ? ? ? Pattern:表示正则表达式
? ? ? ? Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取。在大串中去找符合匹配规则的子串
? ? ? ? ? ? ? ? eg.有如下文本:Java自从95年问世,经历了很多版本,目前企业中用到的最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在不久Java17也会逐渐登上历史舞台。
? ? ? ? ? ? ? ? 要求:找出里面所偶的JavaXX。
代码如下:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class 爬虫demo {
public static void main(String[] args) {
String str = "Java自从95年问世,经历了很多版本,目前企业中用到的最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在不久Java17也会逐渐登上历史舞台";
//获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//获取文本匹配器的对象
Matcher m = p.matcher(str);
//利用循环从头获取,寻找是否有满足规则的子串。
while(m.find()){
String s = m.group();
System.out.println(s);
}
}
}
运行结果如下:
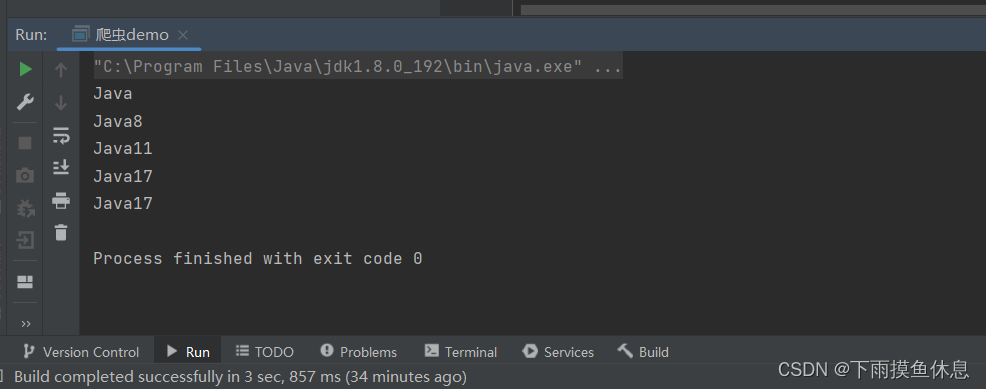
? ? ? ? ? ? ? ? 要点说明:代码:
Matcher m = p.matcher(str);
中的——m:文本匹配器的对象
str:大串
p:规则
m:要在str中找符合p规则的小串
m.find()会返回一个boolean类型的结果。如果没有,返回false。反之返回true,并在底层记录字串的起始索引和结束索引+1(+1之后再作为结束索引进行传递)
String s = m.group();————方法底层会根据find方法记录的索引进行字符串的获取:subString(起始索引,结束索引);包头不包尾(所以find方法在结束索引位置+1就很有必要)
文章来源:https://blog.csdn.net/2301_78496658/article/details/135561712
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Java SE】java中继承详解
- 原来SD-WAN底层是这些能力
- 甜美温柔有气质的衬衫穿搭
- 设计模式之观察者模式【行为型模式】
- GitLab升级版本(任意用户密码重置漏洞CVE-2023-7028)
- 使用Python将OSS文件免费下载到本地:第二步 将OSS文件下载到ECS中
- Ubuntu环境下SomeIP/CommonAPI环境搭建详细步骤
- 案例117:基于微信小程序的新闻资讯系统设计与实现
- 微信小程序-监听屏幕滚动
- 1. MyBatis 入门程序