CLIP 对比预训练 + 文字图像相似度:离奇调查,如何训练视觉大模型?
CLIP:如何训练视觉大模型?
?
CLIP论文地址:https://arxiv.org/pdf/2103.00020.pdf
CLIP = 对比学习 + 预训练 + 文字图像相似度。
对比预训练
传统方法训练视觉模型的方式通常是使用有监督学习方法,需要收集大量图像和对应标签:
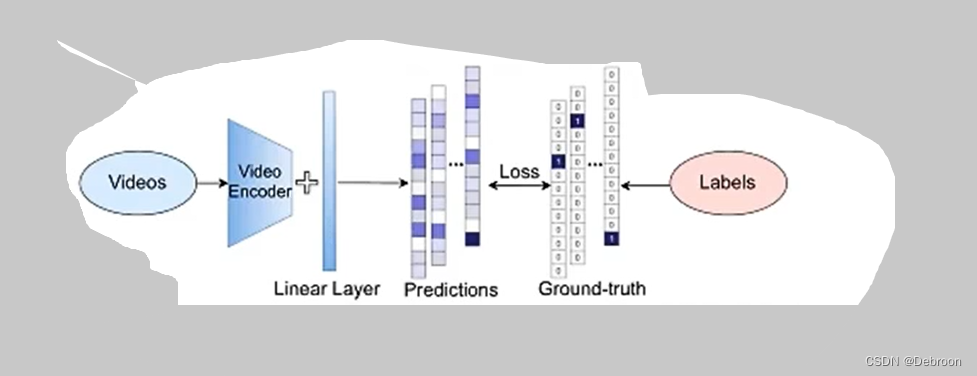
CLIP 采用了一种不需要人工大量标记数据的自监督学习方法。
CLIP 模型是一种基于对比学习的模型,可以将图像和文本进行联合编码,从而实现图像和文本之间的交叉检索。
-
传统方法:要构建一个图像-文本匹配数据集,需要收集大量的图像和与之相关联的文本描述,并对它们进行人工标注。比如,我们收集了10000张图像和与之对应的10000个文本描述,然后需要手动将每张图像与对应的文本进行匹配标注。
-
CLIP方法:相比之下,CLIP可以利用自监督学习和互联网上的数据进行训练,无需显式的人工标注。例如,我们可以利用互联网上的图像和相关联的文本数据,比如从社交媒体、图像搜索引擎或图像描述数据集中获取图像-文本对,不用人工标注。
-
openai 使用了 WebImage Text 上 4亿 对图像文本对训练 CLIP

CLIP会将图像和文本分别编码为特征向量,并通过比较这些特征向量的相似性来学习图像和文本之间的匹配关系。
比如图像和文本的匹配任务中,模型需要区分正样本(真实的图像-文本匹配对)和负样本(随机的图像-文本对)。
模型会通过最大化正样本的相似性,同时最小化负样本的相似性来学习。

对比预训练:
- 一个文本编码器,得到 n 个文本特征向量( T 1 . . . T n T_{1}...T_{n} T1?...Tn?)
- 一个图像编码器,得到 n 个图像特征向量( l 1 . . . l n l_{1}...l_{n} l1?...ln?)
- 将文本、图像映射到同一个特征空间
- 计算这对组合的相似度
- 最大化正样本相似度(对角线 l 1 T 1 、 l 2 T 2 、 l 3 T 3 、 . . . 、 l n T n l_{1}T_{1}、l_{2}T_{2}、l_{3}T_{3}、...、l_{n}T_{n} l1?T1?、l2?T2?、l3?T3?、...、ln?Tn? 是正样本)
- 最小化负样本相似度(其他是负样本)
完整版(参考知乎大佬):

动态过程:
图像编码器
使用 ResNet 作为初始的图像特征提取器,然后将 ResNet 的输出,传递给 ViT 模型。
利用 ResNet 在低层级特征提取方面的优势,同时使用 ViT 模型的自注意力机制来捕捉图像中的全局关系。
图像编码器 = ResNet + ViT。
ResNet 部分:
- 引入模糊池化,在下采样前加入一个高斯低通滤波。以减少特征图中的高频细节信息,从而实现更加鲁棒的下采样。
- 将全局平均池化,替换成注意力池化。对特征图的每个通道进行加权平均,从而将更多的注意力放在重要的特征上。
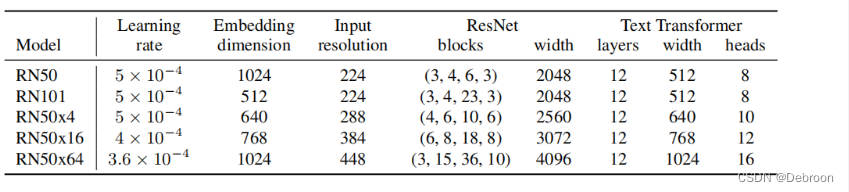
- 5 个模型的放缩:ResNet - 50、ResNet - 100、ResNet - 50x4、ResNet - 50x16、ResNet - 50x64
ViT 部分:
- 在 patch embedding 和 position embedding 后,添加一个额外的线性/全连接层,以增加模型的非线性表达能力。
- 更换了初始化方法,提升模型性能。
- 4 个模型的缩放:ViT-B/32、ViT-B/16、ViT-B/14、ViT-B/14-336px

文本编码器
没啥特殊的,就是 Transformer :
- 6 个编码器
- 6 个解码器
- 使用了 63M 个参数
- 有 8 个注意力头
最大的亮点:zero-shot图像分类
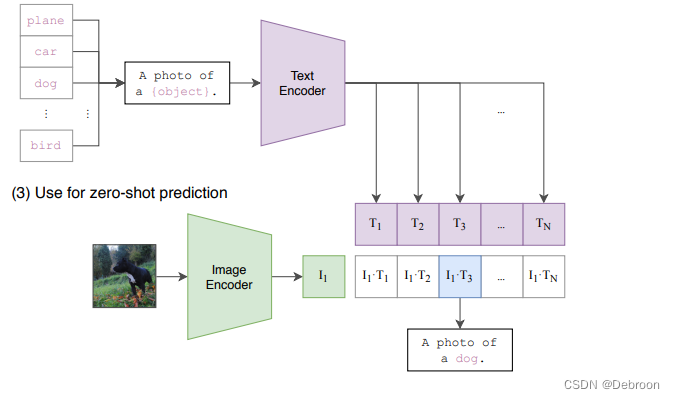
传统大模型预训练后,还需要微调,才能处理下游任务。
CLIP 出来后,不需要任何训练数据,就可以直接做图像分类。
分类过程:
- 将所有类别(汽车、狗、鸟等),转换为一个句子 A photo of a {object}
- 输入到文本编码器,得到 N 个特征向量
- 输入图像到图像编码器,得到 1 个特征向量
- 俩个特征向量相似度最高的,就是图像的类别
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!