教你用python爬取『京东』商品数据,原来这么简单!
1
前言
本文将从小白的角度入手,一步一步教大家如何爬取『京东API』商品数据,文中以【笔记本】电脑为例!
干货内容包括:
如何爬取商品信息?
如何爬取下一页?
如何将爬取出来的内容保存到excel?
2
分析网页结构
1.查看网页
在『京东商城』搜索框输入:笔记本
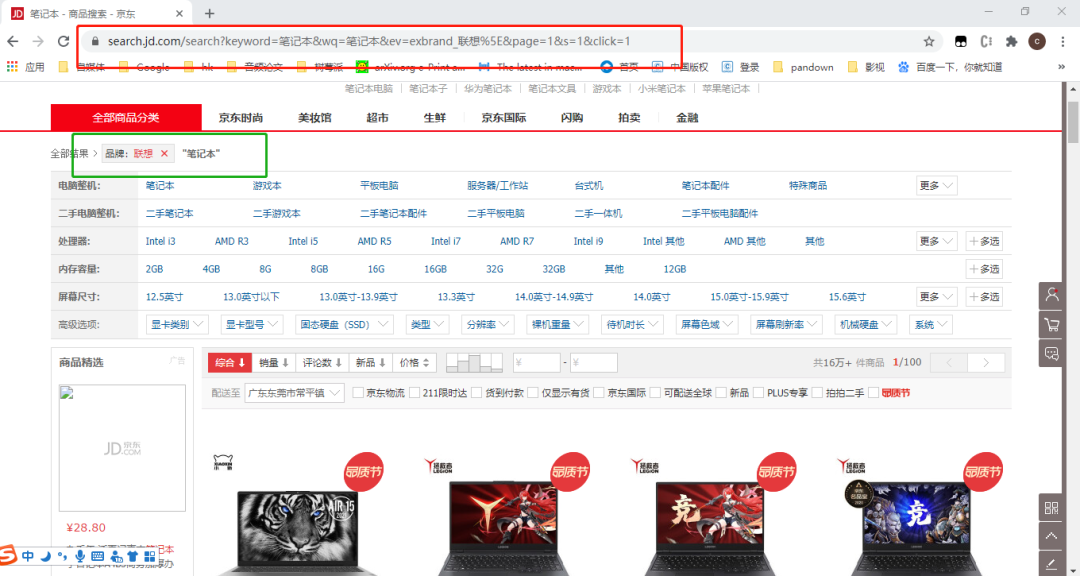
链接如下:
https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page=9&s=241&click=1在浏览器里面按F12,分析网页标签(这里我们需要爬取1.商品名称、2.商品价格、3.商品评论数)
2.分析网页标签
获取当前网页所有商品
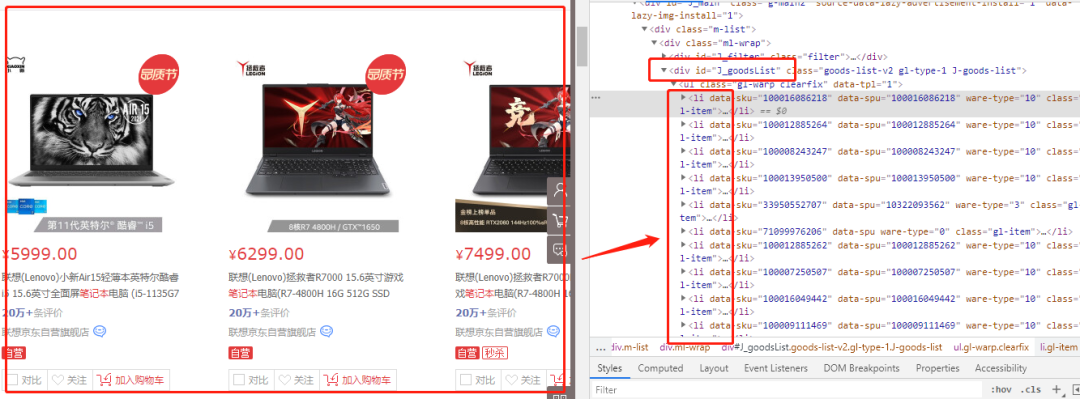
可以看到在class标签id=J_goodsList里ul->li,对应着所有商品列表
获取商品具体属性
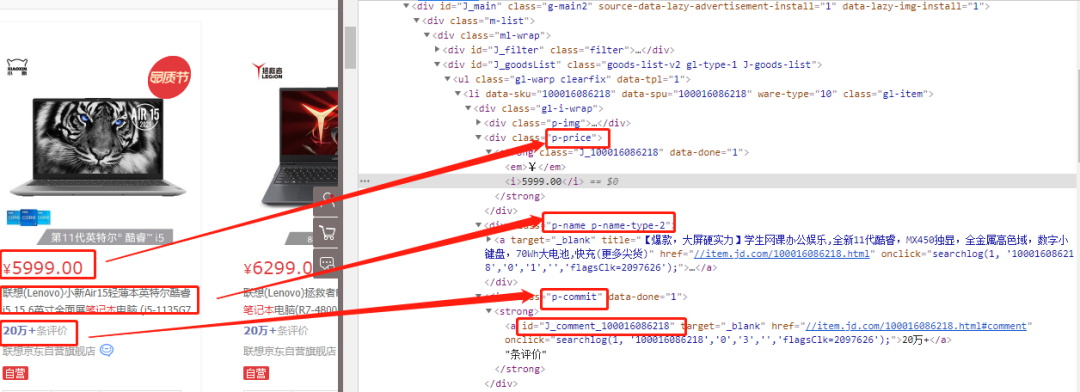
每一个li(商品)标签中,class=p-name p-name-type-2对应商品标题,class=p-price对应商品价格,class=p-commit对应商品ID(方便后面获取评论数)
避坑:
这里商品评论数不能直接在网页上获取!!!,需要根据商品ID去获取。
3
爬取数据
1.编程实现
url="https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page=9&s=241&click=1"res = requests.get(url,headers=headers)res.encoding = 'utf-8'text = res.textselector = etree.HTML(text)list = selector.xpath('//*[@id="J_goodsList"]/ul/li')for i in list:title=i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0]price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0]product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_","")print("title"+str(title))????print("price="+str(price))????print("product_id="+str(product_id))print("-----")
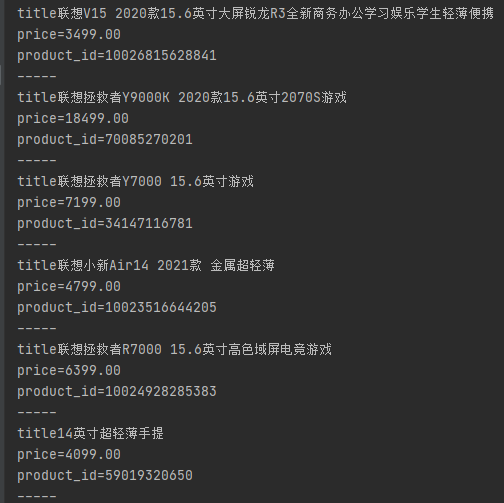
下面教大家如何获取商品评论数!
2.获取商品评论数
查看network,找到如下数据包
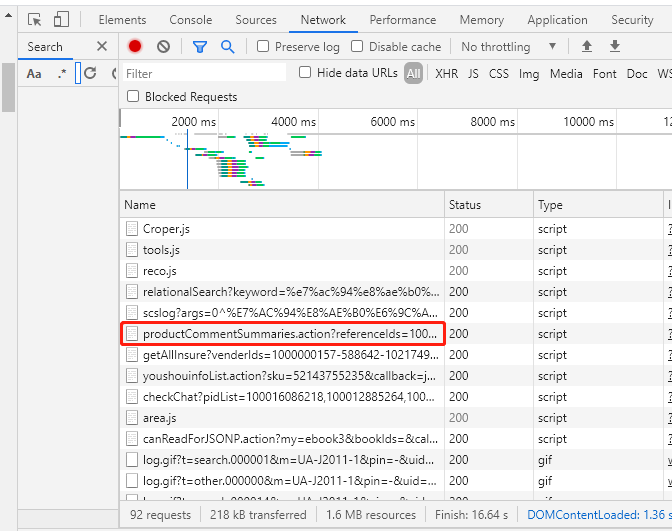

将该url链接放到浏览器里面可以获取到商品评论数

分析url

根据商品ID(可以同时多个ID一起获取)获取商品评论数

最后我们可以将获取商品评论数的方法封装成一个函数
###根据商品id获取评论数def commentcount(product_id):url = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds="+str(product_id)+"&callback=jQuery8827474&_=1615298058081"res = requests.get(url, headers=headers)res.encoding = 'gbk'text = (res.text).replace("jQuery8827474(","").replace(");","")text = json.loads(text)comment_count = text['CommentsCount'][0]['CommentCountStr']comment_count = comment_count.replace("+", "")###对“万”进行操作if "万" in comment_count:comment_count = comment_count.replace("万","")comment_count = str(int(comment_count)*10000)return comment_count
此外,我们可以发现在获取到的评论数包含“万”“+”等符号,需要进行相应处理!
for i in list:title=i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0]price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0]product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_","")###获取商品评论数comment_count = commentcount(product_id)print("title"+str(title))print("price="+str(price))print("product_id="+str(comment_count))
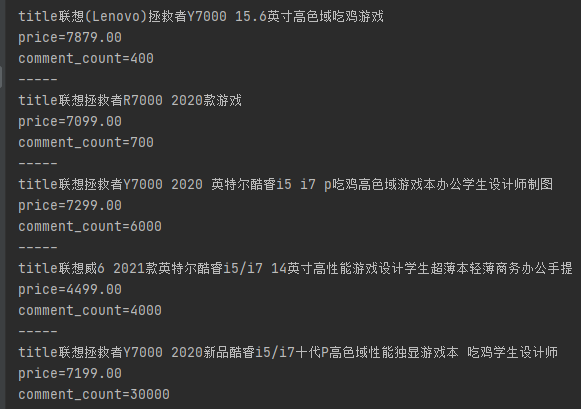
4
保存到excel
1.定义表头
import openpyxloutwb = openpyxl.Workbook()outws = outwb.create_sheet(index=0)outws.cell(row=1,column=1,value="index")outws.cell(row=1,column=2,value="title")outws.cell(row=1,column=3,value="price")outws.cell(row=1,column=4,value="CommentCount")
引入openpyxl库将数据保存到excel,表头内容包含(1.序号index、2.商品名称title、3.商品价格price、4.评论数CommentCount)
2.开始写入
for i in list:title=i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0]price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0]product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_","")###获取商品评论数comment_count = commentcount(product_id)print("title"+str(title))print("price="+str(price))print("comment_count="+str(comment_count))outws.cell(row=count, column=1, value=str(count-1))outws.cell(row=count, column=2, value=str(title))outws.cell(row=count, column=3, value=str(price))outws.cell(row=count, column=4, value=str(comment_count))outwb.save("京东商品-李运辰.xls")#保存
最后保存成京东商品-李运辰.xls

5
下一页分析
很重要!很重要!很重要!
1.分析下一页
这里的下一页与平常看到的不一样,有点特殊!



可以发现page和s有一下规律

page以2递增,s以60递增。
2.构造下一页链接
遍历每一页def getpage():page=1s = 1for i in range(1,6):print("page="+str(page)+",s="+str(s))url = "https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page="+str(page)+"&s="+str(s)+"&click=1"getlist(url)page = page+2s = s+60
这样就可以爬取下一页。
6
总结
1.入门爬虫(京东商品数据为例)。
2.如何获取网页标签。
3.获取『京东』商品评论数
4.如何通过python将数据保存到excel
5.分析构造『京东』商品网页下一页链接
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python毕设选题 - 基于时间序列的股票预测于分析
- 前端弹窗可拖拽功能实现
- 等等Domino 14.0FP1
- Eureka注册中心Eureka提供者与消费者,Eureka原理分析,创建EurekaServer和注册user-service
- ModuleNotFoundError: No module named ‘torchvision.models.utils‘
- grep笔记240103
- JavaWeb
- Pandas实战100例 | 案例 13: 数据分类 - 使用 `cut` 对数值进行分箱
- 小红书koc是什么?小红书koc投放策略总结
- uniapp和vue如何使用SheetJS导出excel?