深度学习中指定特定的GPU使用
发布时间:2024年01月16日
前言
老生常谈,同样的问题,主要来源于:RuntimeError: CUDA error: out of memory
当使用完之后,想从其他方式调试,具体可看我这篇文章的:出现 CUDA out of memory 的解决方法
如果还有的空间使用,可看我下面的方式
1. 问题所示
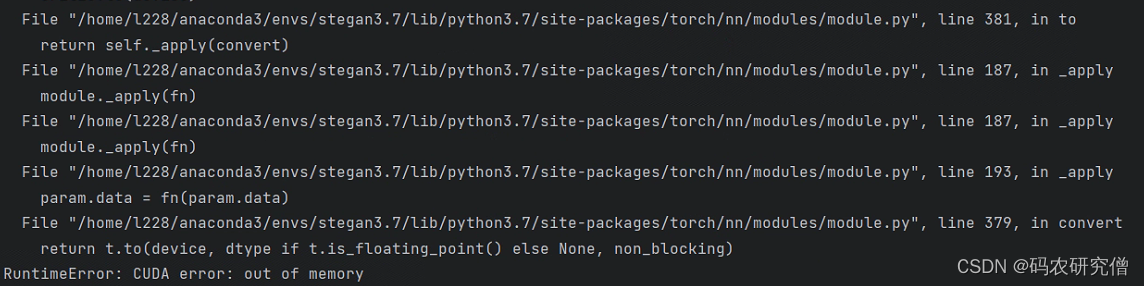
执行代码的时候,出现如下问题:
File "/home/l228/anaconda3/envs/stegan3.7/lib/python3.7/site-packages/torch/nn/modules/module.py", line 381, in to
return self._apply(convert)
File "/home/l228/anaconda3/envs/stegan3.7/lib/python3.7/site-packages/torch/nn/modules/module.py", line 187, in _apply
module._apply(fn)
File "/home/l228/anaconda3/envs/stegan3.7/lib/python3.7/site-packages/torch/nn/modules/module.py", line 187, in _apply
module._apply(fn)
File "/home/l228/anaconda3/envs/stegan3.7/lib/python3.7/site-packages/torch/nn/modules/module.py", line 193, in _apply
param.data = fn(param.data)
File "/home/l228/anaconda3/envs/stegan3.7/lib/python3.7/site-packages/torch/nn/modules/module.py", line 379, in convert
return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
RuntimeError: CUDA error: out of memory
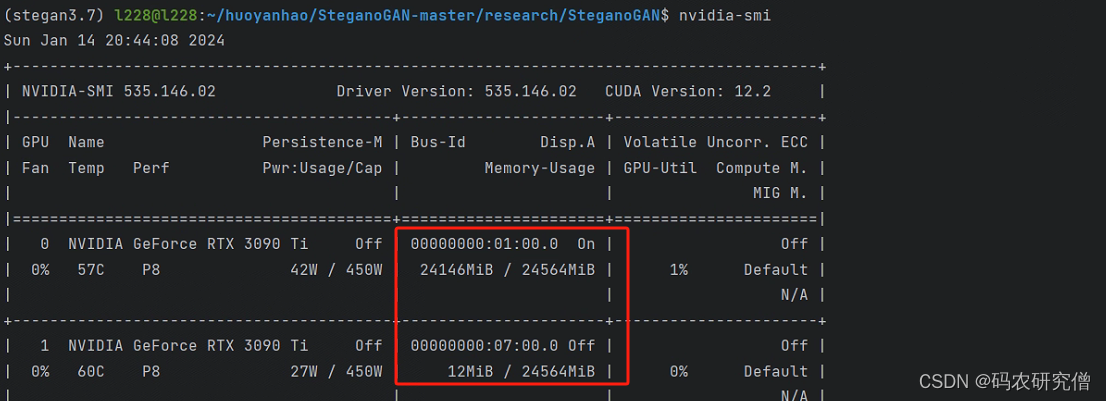
截图如下所示:
最终查看是否还有已存的显卡供使用的时候,发现第一个显卡占用满了,但是第二个显卡不会自动使用:nvidia-smi
2. 解决方法
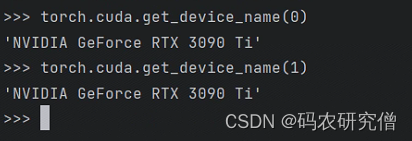
通过执行torch.cuda.get_device_name(id) 也可看到显卡的各个信息。单机多显卡:
方案一:通过命令行(最简单的方式)
使用命令如下:
CUDA_VISIBLE_DEVICES=1 python main.py
截图如下所示:

方案二:通过代码
指定多个空闲的GPU,供选择:
os.environ['CUDA_VISIBLE_DEVICES'] = "0, 1"
model = torch.nn.DataParallel(model, device_ids=[0, 1])
device = torch.device("cuda:0" if torch.cuda.is_available() and not args.no_cuda else "cpu") # cuda 指定使用GPU设备
指定特定空闲的GPU,供选择:
os.environ['CUDA_VISIBLE_DEVICES'] = "1"
model = torch.nn.DataParallel(model, device_ids=[1])
device = torch.device("cuda:1" if torch.cuda.is_available() and not args.no_cuda else "cpu") # cuda 指定使用GPU设备
补充:对于序号可不是按照nvidia-smi显示的前后,需要通过输入名字来查找空闲的GPU
文章来源:https://blog.csdn.net/weixin_47872288/article/details/135588508
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 为什么蜣螂优化算法DBO改进如此简单?
- 系列三、DDL
- 奋楫扬帆,奔赴新程:2023 图扑大事记回顾,愿携手共迎 2024
- 【LeetCode】151. 反转字符串中的单词(中等)——代码随想录算法训练营Day08
- 【C语言】大小端字节序详解
- 【CentOS8】使用 Tomcat 部署 Java Web 项目(使用 sdkman)
- 内网穿透NPS搭建以及使用
- c++ STL六大部件
- 【JVM故障问题排查心得】「Java技术体系方向」Java虚拟机内存优化之虚拟机参数调优原理介绍
- vivado 时钟延迟、抖动和不确定性