逻辑回归中的损失函数
发布时间:2024年01月21日
一、引言
????????逻辑回归中的损失函数通常采用的是交叉熵损失函数(cross-entropy loss function)。在逻辑回归中,我们通常使用sigmoid函数将线性模型的输出转换为概率值,然后将这些概率值与实际标签进行比较,从而计算损失。
二、交叉熵损失函数
????????在逻辑回归解决二分类问题的学习中,我们认识到逻辑回归的输出结果可以看成输入时输出为正例(
)的概率。
分解如下:
????????于是我们便想到可以通过比较模型预测的概率分布和实际标签之间的差异来衡量模型的准确性。在信息论中,交叉熵用来比较两个概率分布之间的差异。
定义:交叉熵损失函数(Cross-entropy loss function)是一种用于衡量模型输出与实际标签之间差异的损失函数。在机器学习中,交叉熵损失函数通常用于分类问题中,特别是在逻辑回归和神经网络等模型中。
对于一个逻辑回归函数:
损失函数公式:? ?
简化后的公式:
根据损失函数的定义,当的值与目标值
越接近,损失函数值越小,预测越准确。
所以:
? ??
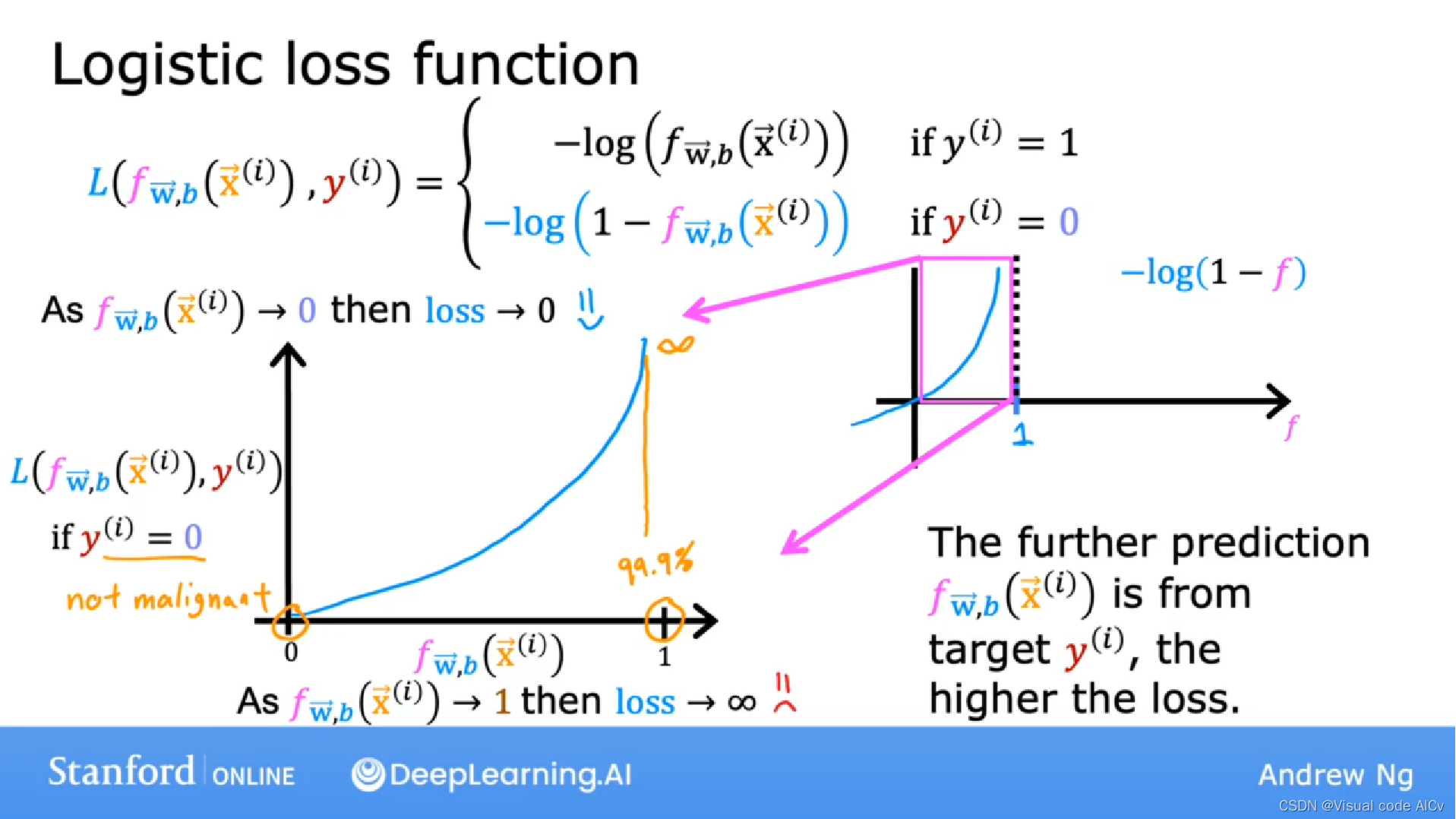
三、为什么不使用均方差损失函数
非凸性:均方差损失函数在逻辑回归中会导致损失函数变成非凸函数,这会导致优化过程变得非常困难。因为非凸函数有多个局部最小值, 而均方差损失函数可能会陷入局部最小值而无法到达全局最小值,这回影响模型的训练效果。

?
输出范围不同:逻辑回归的输出是概率值,范围在0到1之间,而均方差损失函数对于这种概率输出不敏感,它对于离群值(outliers)非常敏感。这意味着即使是一个很小的偏离,也会导致损失函数变得非常大,从而使得模型对于异常值非常敏感。
文章来源:https://blog.csdn.net/m0_65995252/article/details/135675959
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Oracle/DM序列基本使用
- 嵌入式面试题
- html+css 文本样式常用属性集合和总结
- 论文阅读<MULTISCALE DOMAIN ADAPTIVE YOLO FOR CROSS-DOMAIN OBJECT DETECTION>
- 一道面试题
- 自定义工作线程 HandlerThread + new Handler(handlerThread.getLooper())
- 从零开始学Flume:这个大数据框架学习网站让你快速上手!
- Ubuntu搭建Nodejs服务器
- ServletConfig和ServletContext对象
- DML语言(重点)———update