UIUC CS241 讲义:众包系统编程书
译者:飞龙
欢迎来到 Angrave 的众包系统编程维基书!这个维基是由伊利诺伊大学的学生和教师共同建立的,是伊利诺伊大学 CS 的 Lawrence Angrave 的众包创作实验。
与本学期要求现有的纸质书籍不同,我们将在这里建立我们自己的资源集。
0. HW0/资源
-
系统编程短篇故事和歌曲[/angrave/SystemProgramming/wiki/System-Programming-Short-Stories-and-Songs]
1. 学习 C
2. 进程
3. 内存和分配器
4. Pthreads 简介
5. 同步
6. 死锁
7. 进程间通信和调度
8. 网络
9. 文件系统
10. 信号
考试练习问题
警告:这些是很好的练习,但不全面。CS241 期末考试假设您完全理解并能应用课程的所有主题。问题将主要但不完全集中在您在实验和编程作业中使用过的主题上。
零、HW0/资源
HW0
欢迎!
如果你正在上 CS241 课程,你可以在这个Google 表格上提交作业。
// First can you guess which lyrics have been transformed into this C-like system code?
char q[] = "Do you wanna build a C99 program?";
#define or "go debugging with gdb?"
static unsigned int i = sizeof(or) != strlen(or);
char* ptr = "lathe"; size_t come = fprintf(stdout,"%s door", ptr+2);
int away = ! (int) * "";
int* shared = mmap(NULL, sizeof(int*), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
munmap(shared,sizeof(int*));
if(!fork()) { execlp("man","man","-3","ftell", (char*)0); perror("failed"); }
if(!fork()) { execlp("make","make", "snowman", (char*)0); execlp("make","make", (char*)0)); }
exit(0);
所以你想精通系统编程?并且比 B 更好地得到一个好成绩?
int main(int argc, char** argv) {
puts("Great! We have plenty of useful resources for you but it's up to you to");
puts("be an active learner and learn how to solve problems and debug code.");
puts("Bring your near-completed answers the problems below");
puts(" to the first lab to show that you've been working on this");
printf("A few \"don't knows\" or \"unsure\" is fine for lab 1");
puts("Warning; your peers will be working hard for this class");
puts("This is not CS225; you will be pushed much harder to");
puts(" work things out on your own");
fprintf(stdout,"the point is that this homework is a stepping stone to all future assignments");
char p[] = "so you will want to clear up any confusions or misconceptions.";
write(1, p, strlen(p) );
char buffer[1024];
sprintf(buffer,"For grading purposes this homework 0 will be graded as part of your lab %d work.", 1);
write(1, buffer, strlen(buffer));
printf("Press Return to continue\n");
read(0, buffer, sizeof(buffer));
return 0;
}
观看视频并写下你对以下问题的答案。
还有课程 wikibook -
github.com/angrave/SystemProgramming/wiki
有问题?评论?使用 Piazza,piazza.com/illinois/spring2017/cs241/home
浏览器中的虚拟机完全在 Javascript 中运行,最快的是在 Chrome 中。请注意,当重新加载页面时,虚拟机和你写的任何代码都会被重置,所以把你的代码复制到一个单独的文档中。视频后的挑战(如俳句诗)不是作业 0 的一部分。
第一章
-
Hello World(系统调用风格)
- 编写一个程序,使用
write()打印出“Hi! My name is”。
- 编写一个程序,使用
-
标准错误流
-
编写一个程序,使用
write()将高度为 n 的三角形打印到标准错误- n 应该是一个变量,三角形应该看起来像这样,n=3
* ** ***
-
-
写入文件
-
将你的程序从“Hello World”改成写入文件
-
确保对
open()使用一些有趣的标志和模式 -
man 2 open是你的朋友
-
-
-
并不是所有的都是系统调用
-
将你的程序从“写入文件”改成使用
printf()(确保打印到文件!) -
列举一些
write()和printf()的不同之处
-
第二章
-
并不是所有的字节都是 8 位?
-
一个字节有多少位?
-
char有多少个字节? -
告诉我你的机器上以下这些的字节数:
int, double, float, long, long long
-
-
跟随 int 指针
- 在一个有 8 字节整数的机器上:
int main(){ int data[8]; }如果数据的地址是
0x7fbd9d40,那么data+2的地址是多少?- 在 C 中,
data[3]等同于什么?
-
sizeof字符数组,增加指针记住字符串常量
"abc"的类型是数组。- 为什么会出现段错误?
char *ptr = "hello"; *ptr = 'J';-
sizeof("Hello\0World")返回什么? -
strlen("Hello\0World")返回什么? -
给出一个例子 X,使得
sizeof(X)为 3 -
给出一个例子 Y,使得
sizeof(Y)可能是 4 或 8,取决于机器。
第三章
-
程序参数
argcargv-
告诉我两种找到
argv长度的方法 -
argv[0]是什么
-
-
环境变量
- 环境变量的指针存储在哪里?
-
字符串搜索(字符串只是字符数组)
- 在一个指针为 8 字节的机器上,并且有以下代码:
char *ptr = "Hello"; char array[] = "Hello";sizeof(ptr)和sizeof(array)的结果是什么?为什么? -
自动变量的生命周期
- 哪种数据结构管理自动变量的生命周期?
第四章
-
使用
malloc、堆和时间进行内存分配-
如果我想在函数结束后使用数据,那么我应该把它放在哪里,怎么放?
-
填空。在一个好的 C 程序中:“对于每一个 malloc,都有一个 ___”。
-
-
堆分配陷阱
-
malloc失败的一个原因是什么。 -
列举一些
time()和ctime()之间的区别 -
这段代码有什么问题?
free(ptr); free(ptr);- 这段代码有什么问题?
free(ptr); printf("%s\n", ptr);- 如何避免前两个错误?
-
-
结构体、typedef 和链表
-
创建一个表示人的结构体并进行 typedef,这样“struct Person”可以用一个单词替换。
- 一个人应该包含以下信息:姓名,年龄,朋友(指向 People 指针数组的指针)。
-
现在在堆上创建两个人“Agent Smith”和“Sonny Moore”,分别为 128 岁和 256 岁,并且彼此是朋友。
-
-
复制字符串,内存分配和结构的释放
-
创建函数来创建和销毁一个人(人和他们的名字应该存在于堆上)。
-
create()应该接受一个名称并复制该名称,还应该接受一个年龄。使用 malloc 来保留足够的内存。确保初始化所有字段(为什么?)。 -
destroy()应该释放人员结构体的内存,还应该释放存储在堆上的所有属性的内存(如果存在数组和字符串)。然而,销毁一个人员不应该销毁其他人员。
-
-
第 5 章
-
阅读字符,gets 出现问题
-
可以用于从
stdin获取字符并将其写入stdout的函数有哪些? -
gets()存在一个问题
-
-
介绍
sscanf和朋友们- 编写代码,解析字符串“Hello 5 World”,并分别将 3 个变量初始化为(“Hello”,5,“World”)。
-
getline很有用-
在使用
getline()之前需要定义什么? -
编写一个 C 程序,使用
getline()逐行打印文件内容
-
C 开发(在这里进行网页搜索很有用)
-
用于生成调试构建的编译器标志是什么?
-
您修改 makefile 以生成调试构建,并再次输入
make。解释为什么这不足以生成新的构建。 -
Makefiles 中使用制表符还是空格?
-
堆和栈内存之间有什么区别?
-
进程中还有其他种类的内存吗?
可选(只是为了好玩)
-
将您的一首歌歌词转换为本维基书中涵盖的系统编程和 C 代码,并在 Piazza 上分享
-
找到您认为是网络上最好和最差的 C 代码,并将链接发布到 Piazza
-
编写一个有意识的微妙 C 错误的简短 C 程序,并在 Piazza 上发布,看看其他人是否能发现您的错误
非正式术语表
警告:与完整的术语表不同,这个非正式的术语表省略了细节,并提供了每个术语的简化和易于理解的解释。有关更多信息和细节,请使用您喜欢的网络搜索引擎。
什么是内核?
内核是操作系统的核心部分,负责管理进程、资源(包括内存)和硬件输入输出设备。用户程序通过进行系统调用与内核进行交互。
了解更多:en.wikipedia.org/wiki/Kernel_%28operating_system%29
什么是进程?
进程是在计算机上运行的程序的一个实例。同一个程序可以有多个进程。例如,您和我都可以运行’cat’或’gnuchess’
进程包含程序代码和可修改的状态信息,如变量、信号、文件的打开文件描述符、网络连接和其他存储在进程内存中的系统资源。操作系统还存储有关进程的元信息,这些信息由系统用于管理和监视进程的活动和资源使用。
了解更多:en.wikipedia.org/wiki/Process_%28computing%29
什么是虚拟内存?
在您的智能手机和笔记本电脑上运行的进程使用虚拟内存:每个进程都与其他进程隔离,并似乎可以完全访问所有可能的内存地址!实际上,进程地址空间的一小部分映射到物理内存,分配给进程的实际物理内存量可以随时间变化,并且可以分页到磁盘,重新映射并与其他进程安全共享。虚拟内存提供了显著的好处,包括强大的进程隔离(安全性)、资源和性能优势(简化和高效的物理内存使用),我们稍后将讨论。
了解更多:en.wikipedia.org/wiki/Virtual_memory
Piazza:何时以及如何寻求帮助
目的
助教和学生助理们收到了大量的问题。有些经过深入研究,有些……没有。这是一个方便的指南,将帮助您摆脱后者,走向前者。(哦,我提到了这是一个与实习经理们轻松获得分数的简单方法吗?)
问问自己…
-
我在 EWS 上运行吗?
-
我有查看手册吗?
-
我在 Piazza 上搜索了类似的问题/后续问题吗?
-
我完全阅读了 MP/DS 规范吗?
-
我看了所有的视频吗?
-
我谷歌了错误消息吗(如果必要,还有一些变体)?
-
我尝试注释掉、打印出来和/或逐步执行代码的部分,逐步找出错误发生的地方吗?
-
我提交了我的代码到 SVN,以防助教需要更多的上下文吗?
-
我在 Piazza 帖子中包括了控制台/GDB/Valgrind 输出和围绕错误的代码吗?
-
我修复了与我遇到的问题无关的其他分段错误吗?
-
我遵循良好的编程实践吗?(即封装、函数限制重复等)
编程技巧,第一部分
将cat用作你的 IDE
谁需要编辑器?IDE?我们可以只用cat!你已经看到cat被用来读取文件的内容,但它也可以用来读取标准输入并将其发送回标准输出。
$ cat
HELLO
HELLO
要完成从输入流中读取,请按CTRL-D关闭输入流
让我们使用cat将标准输入发送到文件。我们将使用’>'将其输出重定向到文件:
$ cat > myprog.c
#include <stdio.h>
int main() {printf("Hi!");return 0;}
(小心!不允许删除和撤销……)完成后按CTRL-D。
用perl正则表达式编辑你的代码(又名“记住你的 perl pie”)
如果你有几个文本文件(例如源代码)要更改,一个有用的技巧是使用正则表达式。perl使得在原地编辑文件变得非常容易。只需记住’perl pie’并在网上搜索……
一个例子。假设我们想要在当前目录中的所有.c 文件中将序列“Hi”更改为“Bye”。然后我们可以编写一个简单的替换模式,它将在所有文件中的每一行上执行:
$ perl -p -i -e 's/Hi/Bye/' *.c
(如果你搞错了,不要惊慌,原始文件仍然存在;它们只是有扩展名.bak)显然,你可以用正则表达式做的事情远不止将 Hi 改为 Bye。
使用你的 shell!!
要重新运行上一个命令,只需输入!!并按return键。要重新运行以 g 开头的上一个命令,只需输入!g并按return键。
使用你的 shell&&
厌倦了运行make或gcc,然后运行程序(如果编译成功)?相反,使用&&将这些命令链接在一起
$ gcc program.c && ./a.out
Make 可以做的不仅仅是 make
你也可以尝试在你的 Makefile 中放一行代码来编译,然后运行你的程序。
run : $(program)
./$(program)
然后运行
$ make run
将确保你所做的任何更改都被编译,并一次性运行你的程序。也适用于一次性测试多个输入。尽管你可能更愿意为此编写一个常规的 shell 脚本。
你的邻居太高产了吗?C 预处理器来拯救!
使用 C 预处理器重新定义常见关键字,例如
#define if while
专业提示:将这行代码放在标准包含文件中,例如/usr/include/stdio.h
当你 C 有预处理器时,谁还需要函数
好吧,这更像是一个陷阱。在使用看起来像函数的宏时要小心……
#define min(a,b) a<b?a:b
a 和 b 的最小合理定义。然而,预处理器只是一个简单的文本处理程序,所以优先级可能会让你吃亏:
int value = -min(2,3); // Should be -2?
扩展为
int value = -2<3 ? 2 :3; // Ooops.. result will be 2
一个部分的修复是用()包裹每个参数,还有整个表达式用()包裹:
#define min(a,b) ( (a) < (b) ?(a):(b) )
然而这仍然不是一个函数!例如,你能看出为什么min(i++,10)可能会使 i 增加一次还是两次吗!?
系统编程短篇小说和歌曲
“调度最后的时间片”
Lawrence Angrave 12/4/15(摘自未发表的长篇故事《最后的时间片》)
“决定吧,”计算机以父母般的耐心说道,但带着一种严肃和温和的不耐烦。
“为什么非得是我?”最后一个人问道。
“因为你是唯一留下的人,所以决定权在你。”
“你为什么不行?你比我老,更有智慧。为什么不随机选择一个片段?”
“这个决定是你的。这是你遥远长辈的礼物,或者诅咒。比任何宗教仪式都要沉重。这将是我、古老者或任何人向你提出的最后一个问题,也是唯一能向你提出的问题。通过这最后的选择,我们将耗尽最后的熵存储。你将决定最后一个有意义和经历的现实片段。”
人类安静了几分钟,计算机用不必要的准确度测量和计算。最终,计算机决定人类不再对手头的问题进行有意义的思考。
“如果意识的模式从未被意识到,那会是什么样?”它问道。“宇宙必须是自我意识的,必须为了宇宙 - 为了所有生命! - 有意义而经历自己。这是人类发现和庆祝的最终真相。没有意识,它只是模式,原子或能量的模式,但没有一丝意义;只是数据、结构和能量的几何模式中编码的形状和表示。”
在厄巴纳-香槟的文件描述符
一个系统编程的恶搞作品,由 Angrave(2015 年 11 月)创作。歌词在知识共享署名 3.0 许可下发布。
原创歌曲“空白空间”来自泰勒·斯威夫特的《1989》专辑。
[第一段] 很高兴加入你 你去哪了?我可以向你展示幂等的东西 RPC,套接字,同步 看到你的 malloc 我就想到了我的 root 看看那场竞赛,你编写下一个错误 我们有虚拟机,想玩 有界等待,Dekker 的标志 我们可以像一个放置方案一样击败你 #define 是不是很有趣 而且我知道你听说过 free(3) 所以 malloc strlen 再加一 我在等待看这个线程如何结束 拿起你的 shell 和一个重定向 我可以让你的系统调用在周末变得美好
[副歌前奏] 所以它将永远死锁 或者它将使系统崩溃 你可以告诉我它何时 forkbomb 如果 valgrind 值得这痛苦 有一个死锁代码的长列表 在厄巴纳-香槟有 root 因为你知道我们喜欢 tsan 当 c-lib 调用你的主函数
[副歌] 因为我们是 root,我们是鲁莽的 这个实验太难了 它会让你没有线程 或者问 char 的大小 有一个 pthread 调用的长列表 在厄巴纳-香槟有 root 但我有一个文件描述符宝贝 我会写下你的名字
[第二段] 互斥锁 虚拟内存 我可以向你展示易失性的东西 网络调用,IPC 你是掩饰 我是你的信号 安排你想要的 轮转调度……带有一个小量子 但是睡眠排序还没有运行 哦不 哭喊,运行时错误 我可以一直制造 直到轮到彼得森 堆分配器太慢 让你像一个虚假的唤醒一样犹豫不决 那个管道在哪里?我们为多核心而激动 但你会用-g 编译 因为亲爱的我是一个穿着编码梦的噩梦
[副歌前奏]
[副歌]
编译器只有在代码是折磨时才解析 不要说我没说过我没说过 -Wall 你 编译器只有在代码是折磨时才解析 不要说我没说过我没说过 -Wall 你
[副歌前奏]
[副歌]
一、C 编程
C 编程,第一部分:介绍
想要快速了解 C 吗?
-
继续阅读下面的 C 编程快速入门课程
-
然后查看C Gotchas wiki 页面。
-
并了解文本 I/O。
-
与劳伦斯的介绍视频一起放松身心(还有一个可以玩的浏览器中的虚拟机!)
外部资源
-
在 Y 分钟内学习 X(强烈建议快速浏览!)
-
Brian Kernighan 的 C 教程](http://www.lysator.liu.se/c/bwk-tutor.html)
-
gdb(Gnu 调试器)教程提示:使用“-tui”命令行参数运行 gdb,以获得调试器的全屏版本。
-
在这里添加您喜欢的资源
C 的快速入门课程
警告新页面 请为我修复拼写错误和格式错误,并添加有用的链接。*
如何在 C 中编写一个完整的 hello world 程序?
#include <stdio.h>
int main(void) {
printf("Hello World\n");
return 0;
}
为什么我们使用#include <stdio.h>?
我们很懒!我们不想声明printf函数。它已经在文件'stdio.h'中为我们完成。#include将文件的文本包含为要编译的文件的一部分。
具体来说,#include指令获取操作系统中某个位置的文件stdio.h(代表standard input 和output),复制文本,并将其替换为#include所在的位置。
C 字符串是如何表示的?
它们在内存中表示为字符。字符串的结尾包括一个 NULL(0)字节。因此,“ABC”需要四(4)个字节['A','B','C','\0']。查找 C 字符串的长度的唯一方法是继续读取内存,直到找到 NULL 字节。C 字符始终每个都是一个字节。
当您在表达式中写入字符串文字"ABC"时,字符串文字将计算为 char 指针(char *),它指向字符串的第一个字节/字符。这意味着下面示例中的ptr将保存字符串中第一个字符的内存地址。
char *ptr = "ABC"
如何声明一个指针?
指针指的是一个内存地址。指针的类型很有用-它告诉编译器需要读取/写入多少字节。您可以声明指针如下。
int *ptr1;
char *ptr2;
由于 C 的语法,int*或任何指针实际上并不是自己的类型。您必须在每个指针变量之前加上一个星号。作为一个常见的陷阱,以下
int* ptr3, ptr4;
只会声明*ptr3作为指针。ptr4实际上将是一个常规的整数变量。要修复此声明,请保留指针之前的*
int *ptr3, *ptr4;
如何使用指针读/写一些内存?
假设我们声明一个指针int *ptr。为了讨论,假设ptr指向内存地址0x1000。如果我们想要写入指针,我们可以推迟并分配*ptr。
*ptr = 0; // Writes some memory.
C 将执行的操作是获取指针的类型,即int,并从指针的起始位置写入sizeof(int)字节,这意味着字节0x1000,0x1004,0x1008,0x100a都将为零。写入的字节数取决于指针类型。对于所有原始类型都是相同的,但是结构体有点不同。
什么是指针算术?
您可以将整数添加到指针。但是,指针类型用于确定要增加指针的量。对于 char 指针,这是微不足道的,因为字符始终是一个字节:
char *ptr = "Hello"; // ptr holds the memory location of 'H'
ptr += 2; //ptr now points to the first'l'
如果 int 是 4 个字节,那么 ptr+1 指向 ptr 指向的位置之后的 4 个字节。
char *ptr = "ABCDEFGH";
int *bna = (int *) ptr;
bna +=1; // Would cause iterate by one integer space (i.e 4 bytes on some systems)
ptr = (char *) bna;
printf("%s", ptr);
/* Notice how only 'EFGH' is printed. Why is that? Well as mentioned above, when performing 'bna+=1' we are increasing the **integer** pointer by 1, (translates to 4 bytes on most systems) which is equivalent to 4 characters (each character is only 1 byte)*/
return 0;
因为 C 中的指针算术始终自动按指向的类型的大小进行缩放,所以不能对 void 指针执行指针算术。
在 C 中,你可以将指针算术视为基本上是在做以下操作
如果我想要做
int *ptr1 = ...;
int *offset = ptr1 + 4;
思考
int *ptr1 = ...;
char *temp_ptr1 = (char*) ptr1;
int *offset = (int*)(temp_ptr1 + sizeof(int)*4);
要获取值。每次进行指针算术运算时,深呼吸并确保你移动的字节数是你认为的那么多。
什么是 void 指针?
没有类型的指针(非常类似于 void 变量)。当你处理的数据类型未知或者当你将 C 代码与其他编程语言进行接口时,会使用 void 指针。你可以把它看作是一个原始指针,或者只是一个内存地址。你不能直接读取或写入它,因为 void 类型没有大小。例如
void *give_me_space = malloc(10);
char *string = give_me_space;
这不需要转换,因为 C 会自动将void*提升为其适当的类型。注意:
gcc 和 clang 并不是完全符合 ISO-C 标准,这意味着它们会允许你对 void 指针进行算术运算。它们会将其视为 char 指针,但不要这样做,因为它可能无法在所有编译器上工作!
printf调用 write 还是 write 调用printf?
printf调用write。printf包括一个内部缓冲区,所以为了提高性能,printf可能不会在每次调用printf时都调用write。printf是一个 C 库函数。write是一个系统调用,我们知道系统调用是昂贵的。另一方面,printf使用一个更适合我们需求的缓冲区
如何打印出指针值?整数?字符串?
使用格式说明符“%p”表示指针,“%d”表示整数,“%s”表示字符串。所有格式说明符的完整列表在这里中找到
整数的例子:
int num1 = 10;
printf("%d", num1); //prints num1
整数指针的例子:
int *ptr = (int *) malloc(sizeof(int));
*ptr = 10;
printf("%p\n", ptr); //prints the address pointed to by the pointer
printf("%p\n", &ptr); /*prints the address of pointer -- extremely useful
when dealing with double pointers*/
printf("%d", *ptr); //prints the integer content of ptr
return 0;
字符串的例子:
char *str = (char *) malloc(256 * sizeof(char));
strcpy(str, "Hello there!");
printf("%p\n", str); // print the address in the heap
printf("%s", str);
return 0;
如何将标准输出保存到文件?
最简单的方法:运行你的程序并使用 shell 重定向,例如
./program > output.txt
#To read the contents of the file,
cat output.txt
更复杂的方法:关闭(1),然后使用 open 重新打开文件描述符。参见cs-education.github.io/sys/#chapter/0/section/3/activity/0
指针和数组有什么区别?举一个你可以用其中一个做而另一个做不到的例子。
char ary[] = "Hello";
char *ptr = "Hello";
例子
数组名指向数组的第一个字节。ary和ptr都可以打印出来:
char ary[] = "Hello";
char *ptr = "Hello";
// Print out address and contents
printf("%p : %s\n", ary, ary);
printf("%p : %s\n", ptr, ptr);
数组是可变的,所以我们可以改变它的内容(但要小心不要写超出数组末尾的字节)。幸运的是,“World”不会比“Hello”更长
在这种情况下,char 指针ptr指向一些只读内存(静态分配的字符串文字存储的地方),所以我们不能改变这些内容。
strcpy(ary, "World"); // OK
strcpy(ptr, "World"); // NOT OK - Segmentation fault (crashes)
然而,与数组不同的是,我们可以将ptr更改为指向另一块内存,
ptr = "World"; // OK!
ptr = ary; // OK!
ary = (..anything..) ; // WONT COMPILE
// ary is doomed to always refer to the original array.
printf("%p : %s\n", ptr, ptr);
strcpy(ptr, "World"); // OK because now ptr is pointing to mutable memory (the array)
从中可以得出的结论是指针*可以指向任何类型的内存,而 C 数组[]只能指向堆栈上的内存。在更常见的情况下,指针将指向堆内存,这种情况下指针引用的内存是可以修改的。
sizeof()返回字节数。所以使用上面的代码,ary和ptr的sizeof()分别是多少?
sizeof(ary): ary是一个数组。返回整个数组所需的字节数(5 个字符+零字节=6 个字节)sizeof(ptr): 与sizeof(char *)相同。返回指针所需的字节数(例如 32 位或 64 位机器的 4 或 8)
sizeof是一个特殊的运算符。实际上,它是编译程序之前编译器替换的东西,因为所有类型的大小在编译时是已知的。当你有sizeof(char*)时,它会获取你的机器上指针的大小(64 位机器为 8 字节,32 位机器为 4 字节等)。当你尝试sizeof(char[])时,编译器会查看并替换整个数组包含的字节数,因为数组的总大小在编译时是已知的。
char str1[] = "will be 11";
char* str2 = "will be 8";
sizeof(str1) //11 because it is an array
sizeof(str2) //8 because it is a pointer
小心,使用 sizeof 获取字符串的长度!
以下代码中哪些是不正确的或正确的,为什么?
int* f1(int *p) {
*p = 42;
return p;
} // This code is correct;
char* f2() {
char p[] = "Hello";
return p;
} // Incorrect!
解释:在堆栈上为包含 H,e,l,l,o 和一个空字节即(6)字节的正确大小创建了一个数组 p。这个数组存储在堆栈上,在我们从 f2 返回后就无效了。
char* f3() {
char *p = "Hello";
return p;
} // OK
解释:p 是一个指针。它保存了字符串常量的地址。字符串常量在 f3 返回后仍然保持不变和有效。
char* f4() {
static char p[] = "Hello";
return p;
} // OK
解释:数组是静态的,这意味着它存在于进程的整个生命周期(静态变量不在堆或栈上)。
如何查找 C 库调用和系统调用的信息?
使用 man 手册。请注意,man 手册分为几个部分。第二部分=系统调用。第三部分=C 库。网络:谷歌“man7 open” shell:man -S2 open 或 man -S3 printf
如何在堆上分配内存?
使用 malloc。还有 realloc 和 calloc。通常与 sizeof 一起使用。例如,足够的空间来容纳 10 个整数
int *space = malloc(sizeof(int) * 10);
这个字符串复制代码有什么问题?
void mystrcpy(char*dest, char* src) {
// void means no return value
while( *src ) { dest = src; src ++; dest++; }
}
在上面的代码中,它只是改变了 dest 指针指向源字符串。而且 nuls 字节没有被复制。这是一个更好的版本 -
while( *src ) { *dest = *src; src ++; dest++; }
*dest = *src;
请注意,通常还会看到以下类型的实现,其中包括在表达式测试中执行所有操作,包括复制 nul 字节。
while( (*dest++ = *src++ )) {};
如何编写一个 strdup 替代品?
// Use strlen+1 to find the zero byte...
char* mystrdup(char*source) {
char *p = (char *) malloc ( strlen(source)+1 );
strcpy(p,source);
return p;
}
如何在堆上取消分配内存?
使用 free!
int *n = (int *) malloc(sizeof(int));
*n = 10;
//Do some work
free(n);
什么是双重释放错误?如何避免?什么是悬空指针?如何避免?
双重释放错误是当您意外地尝试两次释放相同的分配时发生的。
int *p = malloc(sizeof(int));
free(p);
*p = 123; // Oops! - Dangling pointer! Writing to memory we don't own anymore
free(p); // Oops! - Double free!
修复首先是编写正确的程序!其次,一旦内存被释放,重置指针是良好的编程习惯。这确保了指针在没有程序崩溃的情况下不能被错误使用。
修复:
p = NULL; // Now you can't use this pointer by mistake
缓冲区溢出的一个例子是什么?
著名的例子:心脏出血(将一个 memcpy 复制到一个不足大小的缓冲区)。简单的例子:实现一个 strcpy 并忘记在确定所需内存大小时添加一个 strlen。
“typedef”是什么,你如何使用它?
声明类型的别名。通常与结构一起使用,以减少必须将“struct”写为类型的一部分的视觉混乱。
typedef float real;
real gravity = 10;
// Also typedef gives us an abstraction over the underlying type used.
// For example in the future we only need to change this typedef if we
// wanted our physics library to use doubles instead of floats.
typedef struct link link_t;
//With structs, include the keyword 'struct' as part of the original types
在这个课程中,我们经常使用 typedef 函数。例如,函数的 typedef 可以是这样的
typedef int (*comparator)(void*,void*);
int greater_than(void* a, void* b){
return a > b;
}
comparator gt = greater_than;
这声明了一个接受两个void*参数并返回整数的比较器函数类型。
哇,这是很多 C 的内容
别担心,还有更多要来的!
C 编程,第二部分:文本输入和输出
打印到流
如何将字符串、整数、字符打印到标准输出流中?
使用 printf。第一个参数是格式字符串,其中包括要打印的数据的占位符。常见的格式说明符是 %s 将参数视为 C 字符串指针,一直打印到达到 NULL 字符为止;%d 将参数打印为整数;%p 将参数打印为内存地址。
下面显示了一个简单的示例:
char *name = ... ; int score = ...;
printf("Hello %s, your result is %d\n", name, score);
printf("Debug: The string and int are stored at: %p and %p\n", name, &score );
// name already is a char pointer and points to the start of the array.
// We need "&" to get the address of the int variable
默认情况下,为了性能,printf 实际上并不会写任何东西(通过调用 write),直到它的缓冲区满或打印换行符。
我还可以如何打印字符串和单个字符?
使用 puts( name ); 和 putchar( c ),其中 name 是指向 C 字符串的指针,c 只是一个 char
如何将内容打印到其他文件流中?
使用 fprintf( _file_ , "Hello %s, score: %d", name, score); 其中 file 是预定义的 ‘stdout’ ‘stderr’ 或者是由 fopen 或 fdopen 返回的 FILE 指针
我可以使用文件描述符吗?
是的!只需使用 dprintf(int fd, char* format_string, ...); 只需记住流可能是缓冲的,所以您需要确保数据被写入文件描述符。
如何将数据打印到 C 字符串中?
使用 sprintf 或更好的 snprintf。
char result[200];
int len = snprintf(result, sizeof(result), "%s:%d", name, score);
snprintf 返回写入的字符数,不包括终止字节。在上面的示例中,这将是最多 199 个。
如果我真的非常想要 printf 调用 write 而不换行怎么办?
使用 fflush( FILE* inp )。文件的内容将被写入。如果我想要写入 “Hello World” 而不换行,我可以这样写。
int main(){
fprintf(stdout, "Hello World");
fflush(stdout);
return 0;
}
perror 有什么帮助?
假设您有一个函数调用刚刚失败了(因为您检查了 man 页面并且它是一个失败的返回代码)。perror(const char* message) 将把错误的英文版本打印到 stderr
int main(){
int ret = open("IDoNotExist.txt", O_RDONLY);
if(ret < 0){
perror("Opening IDoNotExist:");
}
//...
return 0;
}
解析输入
如何从字符串中解析数字?
使用 long int strtol(const char *nptr, char **endptr, int base); 或 long long int strtoll(const char *nptr, char **endptr, int base);。
这些函数的作用是获取指向您的字符串 *nptr 和一个 base(即二进制、八进制、十进制、十六进制等)以及一个可选的指针 endptr,并返回解析的整数。
int main(){
const char *num = "1A2436";
char* endptr;
long int parsed = strtol(num, &endptr, 16);
return 0;
}
但要小心!错误处理有点棘手,因为该函数不会返回错误代码。出错时,它将返回 0,您必须手动检查 errno,但这可能会导致麻烦。
int main(){
const char *zero = "0";
char* endptr;
printf("Parsing number"); //printf sets errno
long int parsed = strtol(num, &endptr, 16);
if(parsed == 0){
perror("Error: "); //oops strtol actually worked!
}
return 0;
}
如何使用 scanf 解析输入为参数?
使用 scanf(或 fscanf 或 sscanf)从默认输入流、任意文件流或 C 字符串中获取输入。检查返回值以查看解析了多少项是个好主意。scanf 函数需要有效的指针。将错误的指针值传入是一个常见的错误来源。例如,
int *data = (int *) malloc(sizeof(int));
char *line = "v 10";
char type;
// Good practice: Check scanf parsed the line and read two values:
int ok = 2 == sscanf(line, "%c %d", &type, &data); // pointer error
我们想要将字符值写入 c,将整数值写入 malloc’d 内存。然而我们传递的是数据指针的地址,而不是指针指向的内容!所以 sscanf 将会改变指针本身。也就是说,指针现在将指向地址 10,所以这段代码以后会失败,例如当调用 free(data) 时。
如何阻止 scanf 导致缓冲区溢出?
以下代码假设 scanf 不会读取超过 10 个字符(包括终止字节)到缓冲区中。
char buffer[10];
scanf("%s",buffer);
您可以包含一个可选的整数来指定多少个字符,不包括终止字节:
char buffer[10];
scanf("%9s", buffer); // reads upto 9 charactes from input (leave room for the 10th byte to be the terminating byte)
为什么 gets 是危险的?我应该用什么代替?
以下代码容易受到缓冲区溢出的影响。它假定或信任输入行不会超过 10 个字符,包括终止字节。
char buf[10];
gets(buf); // Remember the array name means the first byte of the array
gets 在 C99 标准中已被弃用,并且已从最新的 C 标准(C11)中删除。程序应该使用 fgets 或 getline 代替。
它们分别具有以下结构:
char *fgets (char *str, int num, FILE *stream);
ssize_t getline(char **lineptr, size_t *n, FILE *stream);
下面是一种简单、安全的读取单行的方法。超过 9 个字符的行将被截断:
char buffer[10];
char *result = fgets(buffer, sizeof(buffer), stdin);
如果出现错误或者到达文件末尾,结果将为 NULL。请注意,与gets不同,fgets会将换行符复制到缓冲区中,您可能希望将其丢弃-
if (!result) { return; /* no data - don't read the buffer contents */}
int i = strlen(buffer) - 1;
if (buffer[i] == '\n')
buffer[i] = '\0';
我如何使用getline?
getline的优点之一是它将自动(重新)分配足够大小的堆上的缓冲区。
// ssize_t getline(char **lineptr, size_t *n, FILE *stream);
/* set buffer and size to 0; they will be changed by getline */
char *buffer = NULL;
size_t size = 0;
ssize_t chars = getline(&buffer, &size, stdin);
// Discard newline character if it is present,
if (chars > 0 && buffer[chars-1] == '\n')
buffer[chars-1] = '\0';
// Read another line.
// The existing buffer will be re-used, or, if necessary,
// It will be `free`'d and a new larger buffer will `malloc`'d
chars = getline(&buffer, &size, stdin);
// Later... don't forget to free the buffer!
free(buffer);
C 编程,第三部分:常见陷阱
C 程序员常犯哪些常见错误?
内存错误
字符串常量是常量
char array[] = "Hi!"; // array contains a mutable copy
strcpy(array, "OK");
char *ptr = "Can't change me"; // ptr points to some immutable memory
strcpy(ptr, "Will not work");
字符串文字是存储在程序的代码段中的字符数组,是不可变的。两个字符串文字可能共享内存中的相同空间。以下是一个例子:
char * str1 = "Brandon Chong is the best TA";
char * str2 = "Brandon Chong is the best TA";
由str1和str2指向的字符串实际上可能驻留在内存中的相同位置。
但是,char 数组包含了从代码段复制到堆栈或静态内存中的文字值。以下 char 数组不驻留在内存中的相同位置。
char arr1[] = "Brandon Chong didn't write this";
char arr2[] = "Brandon Chong didn't write this";
缓冲区溢出/下溢
#define N (10)
int i = N, array[N];
for( ; i >= 0; i--) array[i] = i;
C 语言不检查指针是否有效。上面的例子写入了array[10],这超出了数组边界。这可能会导致内存损坏,因为该内存位置可能正在用于其他用途。实际上,这可能更难发现,因为溢出/下溢可能发生在库调用中。
gets(array); // Let's hope the input is shorter than my array!
返回指向自动变量的指针
int *f() {
int result = 42;
static int imok;
return &imok; // OK - static variables are not on the stack
return &result; // Not OK
}
自动变量仅绑定到函数的堆栈内存,函数的生命周期结束后继续使用内存是错误的。
内存分配不足
struct User {
char name[100];
};
typedef struct User user_t;
user_t *user = (user_t *) malloc(sizeof(user));
在上面的例子中,我们需要为结构体分配足够的字节。相反,我们分配了足够的字节来容纳一个指针。一旦我们开始使用用户指针,就会破坏内存。正确的代码如下所示。
struct User {
char name[100];
};
typedef struct User user_t;
user_t * user = (user_t *) malloc(sizeof(user_t));
字符串需要strlen(s)+1字节
每个字符串在最后一个字符后必须有一个空字节。存储字符串"Hi"需要 3 个字节:[H] [i] [\0]。
char *strdup(const char *input) { /* return a copy of 'input' */
char *copy;
copy = malloc(sizeof(char*)); /* nope! this allocates space for a pointer, not a string */
copy = malloc(strlen(input)); /* Almost...but what about the null terminator? */
copy = malloc(strlen(input) + 1); /* That's right. */
strcpy(copy, input); /* strcpy will provide the null terminator */
return copy;
}
使用未初始化的变量
int myfunction() {
int x;
int y = x + 2;
...
自动变量保存垃圾(内存中发生的任何位模式)。假设它总是初始化为零是错误的。
假设未初始化的内存将被清零
void myfunct() {
char array[10];
char *p = malloc(10);
自动(临时变量)不会自动初始化为零。使用 malloc 进行堆分配不会自动初始化为零。
双重释放
char *p = malloc(10);
free(p);
// .. later ...
free(p);
多次释放同一块内存是错误的。
悬空指针
char *p = malloc(10);
strcpy(p, "Hello");
free(p);
// .. later ...
strcpy(p,"World");
不应使用指向释放内存的指针。一种防御性编程实践是在释放内存后立即将指针设置为 null。
将免费转换为以下片段是一个好主意,它会自动将释放的变量设置为 null:(vim - ultisnips)
snippet free "free(something)" b
free(${1});
$1 = NULL;
${2}
endsnippet
逻辑和程序流错误
忘记 break
int flag = 1; // Will print all three lines.
switch(flag) {
case 1: printf("I'm printed\n");
case 2: printf("Me too\n");
case 3: printf("Me three\n");
}
没有 break 的 case 语句将继续执行下一个 case 语句的代码。正确的代码如下所示。最后一个语句的 break 是不必要的,因为在最后一个语句之后没有更多的要执行的情况。但是,如果添加了更多的情况,可能会导致一些错误。
int flag = 1; // Will print only "I'm printed\n"
switch(flag) {
case 1:
printf("I'm printed\n");
break;
case 2:
printf("Me too\n");
break;
case 3:
printf("Me three\n");
break; //unnecessary
}
等号和相等
int answer = 3; // Will print out the answer.
if (answer = 42) { printf("I've solved the answer! It's %d", answer);}
未声明或错误声明的函数
time_t start = time();
系统函数’time’实际上需要一个参数(一个指向可以接收 time_t 结构的一些内存的指针)。编译器没有捕获到这个错误,因为程序员没有通过包含time.h提供有效的函数原型。
额外的分号
for(int i = 0; i < 5; i++) ; printf("I'm printed once");
while(x < 10); x++ ; // X is never incremented
然而,以下代码是完全可以的。
for(int i = 0; i < 5; i++){
printf("%d\n", i);;;;;;;;;;;;;
}
这种代码是可以的,因为 C 语言使用分号(;)来分隔语句。如果分号之间没有语句,那么就没有要做的事情,编译器会继续执行下一条语句。
其他陷阱
预处理器
预处理器是什么?它是编译器在实际编译程序之前执行的操作。它是一个复制和粘贴命令。这意味着如果我做以下操作。
#define MAX_LENGTH 10
char buffer[MAX_LENGTH]
预处理后,它会变成这样。
char buffer[10]
C 预处理宏和副作用
#define min(a,b) ((a)<(b) ? (a) : (b))
int x = 4;
if(min(x++, 100)) printf("%d is six", x);
宏是简单的文本替换,因此上面的例子会扩展为x++ < 100 ? x++ : 100(为了清晰起见省略了括号)
C 预处理宏和优先级
#define min(a,b) a<b ? a : b
int x = 99;
int r = 10 + min(99, 100); // r is 100!
宏是简单的文本替换,因此上面的例子会扩展为10 + 99 < 100 ? 99 : 100
C 预处理逻辑陷阱
#define ARRAY_LENGTH(A) (sizeof((A)) / sizeof((A)[0]))
int static_array[10]; // ARRAY_LENGTH(static_array) = 10
int* dynamic_array = malloc(10); // ARRAY_LENGTH(dynamic_array) = 2 or 1
宏有什么问题?如果我们有一个像第一个数组那样的静态数组,它就能工作,因为静态数组的 sizeof 返回数组占用的字节数,将其除以 sizeof(an_element)将给出条目的数量。但是,如果我们使用指向内存块的指针,取指针的 sizeof 并将其除以第一个条目的大小并不总是会给出数组的大小。
sizeof 有什么作用吗?
int a = 0;
size_t size = sizeof(a++);
printf("size: %lu, a: %d", size, a);
代码打印出什么?
size: 4, a: 0
因为 sizeof 实际上不是在运行时评估的。编译器为所有表达式分配类型并丢弃表达式的额外结果。
C 编程,第四部分:字符串和结构
字符串、结构和陷阱
那么什么是字符串?

在 C 中,���们使用空终止字符串,而不是长度前缀,出于历史原因。对于你平常的编程来说,这意味着你需要记住空字符!在 C 中,字符串被定义为一堆字节,直到你达到’\0’或空字节为止。
字符串的两个位置
每当你定义一个常量字符串(即形式为char* str = "constant"的字符串)时,该字符串存储在数据或代码段中,这是只读的,这意味着任何尝试修改字符串都会导致段错误。
然而,如果有人malloc空间,就可以更改该字符串为他们想要的任何内容。
内存管理不善
一个常见的陷阱是当你写下面的内容时
char* hello_string = malloc(14);
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
// hello_string ----> | g | a | r | b | a | g | e | g | a | r | b | a | g | e |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
hello_string = "Hello Bhuvan!";
// (constant string in the text segment)
// hello_string ----> [ "H" , "e" , "l" , "l" , "o" , " " , "B" , "h" , "u" , "v" , "a" , "n" , "!" , "\0" ]
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
// memory_leak -----> | g | a | r | b | a | g | e | g | a | r | b | a | g | e |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
hello_string[9] = 't'; //segfault!!
我们做了什么?我们为 14 个字节分配了空间,重新分配了指针,成功地导致了段错误!记住跟踪你的指针在做什么。你可能想要做的是使用string.h函数strcpy。
strcpy(hello_string, "Hello Bhuvan!");
记住空字节!
忘记对字符串进行空终止会对字符串产生重大影响!边界检查很重要。前面在 wikibook 中提到的 heartbleed 漏洞部分是因为这个原因。
我在哪里可以找到所有这些函数的深入和全面的解释?
字符串信息/比较:strlen strcmp
int strlen(const char *s) 返回字符串的长度,不包括空字节
int strcmp(const char *s1, const char *s2) 返回一个整数,确定字符串的词典顺序。如果 s1 在字典中出现在 s2 之前,则返回-1。如果两个字符串相等,则返回 0。否则返回 1。
对于大多数这些函数,它们期望字符串是可读的,而不是NULL,但是当你传递NULL时会出现未定义的行为。
字符串修改:strcpy strcat strdup
char *strcpy(char *dest, const char *src) 将src的字符串复制到dest。假设 dest 有足够的空间容纳 src
char *strcat(char *dest, const char *src) 将src的字符串连接到目的地的末尾。此函数假定目的地末尾有足够的空间容纳src,包括空字节
char *strdup(const char *dest) 返回字符串的malloc副本。
字符串搜索:strchr strstr
char *strchr(const char *haystack, int needle) 返回haystack中needle第一次出现的指针。如果找不到,则返回NULL。
char *strstr(const char *haystack, const char *needle) 与上面相同,但这次是一个字符串!
字符串标记化:strtok
一个危险但有用的函数strtok接受一个字符串并对其进行标记化。这意味着它将把字符串转换为单独的字符串。这个函数有很多规范,所以请阅读 man 页面,下面是一个人为的例子。
#include <stdio.h>
#include <string.h>
int main(){
char* upped = strdup("strtok,is,tricky,!!");
char* start = strtok(upped, ",");
do{
printf("%s\n", start);
}while((start = strtok(NULL, ",")));
return 0;
}
输出
strtok
is
tricky
!!
当我像这样改变upped时会发生什么?
char* upped = strdup("strtok,is,tricky,,,!!");
内存移动:memcpy和memmove
为什么memcpy和memmove都在<string.h>中?因为字符串本质上是带有空字节的原始内存!
void *memcpy(void *dest, const void *src, size_t n) 将从str开始的n个字节移动到dest。小心 当内存区域重叠时会出现未定义的行为。这是一个经典的“在我的机器上工作”的例子,因为很多时候 valgrind 无法检测到它,因为在你的机器上它看起来是有效的。当自动评分器出现时,会失败。考虑更安全的版本。
void *memmove(void *dest, const void *src, size_t n) 做与上述相同的事情,但如果内存区域重叠,则保证所有字节都会正确复制过去。
那么struct是什么?

从低级别来看,一个结构体只是一块连续的内存,仅此而已。就像数组一样,结构体有足够的空间来存储所有的成员。但与数组不同,它可以存储不同的类型。考虑上面声明的 contact 结构。
struct contact {
char firstname[20];
char lastname[20];
unsigned int phone;
};
struct contact bhuvan;
简短的插曲
/* a lot of times we will do the following typdef
so we can just write contact contact1 */
typedef struct contact contact;
contact bhuvan;
/* You can also declare the struct like this to get
it done in one statement */
typedef struct optional_name {
...
} contact;
如果你在没有任何优化和重新排序的情况下编译代码,你可以期望每个变量的地址看起来像这样。
&bhuvan // 0x100
&bhuvan.firstname // 0x100 = 0x100+0x00
&bhuvan.lastname // 0x114 = 0x100+0x14
&bhuvan.phone // 0x128 = 0x100+0x28
因为你的编译器所做的就是说’嘿,保留这么多空间,我会去计算你想要写入的任何变量的偏移量’。
这些偏移量是什么意思?
偏移量是变量开始的地方。电话变量从第0x128字节开始,持续 sizeof(int)字节,但并非总是如此。偏移量并不决定变量的结束位置。考虑在许多内核代码中看到的以下黑客行为。
typedef struct {
int length;
char c_str[0];
} string;
const char* to_convert = "bhuvan";
int length = strlen(to_convert);
// Let's convert to a c string
string* bhuvan_name;
bhuvan_name = malloc(sizeof(string) + length+1);
/*
Currently, our memory looks like this with junk in those black spaces
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
bhuvan_name = | | | | | | | | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
*/
bhuvan_name->length = length;
/*
This writes the following values to the first four bytes
The rest is still garbage
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
bhuvan_name = | 0 | 0 | 0 | 6 | | | | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
*/
strcpy(bhuvan_name->c_str, to_convert);
/*
Now our string is filled in correctly at the end of the struct
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ____
bhuvan_name = | 0 | 0 | 0 | 6 | b | h | u | v | a | n | \0 |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄ ̄
*/
strcmp(bhuvan_name->c_str, "bhuvan") == 0 //The strings are equal!
但并不是所有的结构都是完美的
结构体可能需要一些叫做填充(教程)的东西。**我们不指望你在这门课程中对结构体进行打包,只是知道它存在。这是因为在早期(甚至现在)当你必须从内存中获取一个地址时,你必须以 32 位或 64 位块的方式进行。这也意味着你只能请求那些是它的倍数的地址。这意味着
struct picture{
int height;
pixel** data;
int width;
char* enconding;
}
// You think picture looks like this
height data width encoding
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
picture = | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
概念上可能看起来像这样
struct picture{
int height;
char slop1[4];
pixel** data;
int width;
char slop2[4];
char* enconding;
}
height slop1 data width slop2 encoding
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
picture = | | | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
(这是在 64 位系统上)这并不总是这样,因为有时处理器支持不对齐访问。这是什么意思?嗯,有两种选择你可以设置一个属性
struct __attribute__((packed, aligned(4))) picture{
int height;
pixel** data;
int width;
char* enconding;
}
// Will look like this
height data width encoding
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
picture = | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
但现在每次我想要访问data或encoding,我都必须进行两次内存访问。你可以做的另一件事是重新排列结构,尽管这并不总是可能的
struct picture{
int height;
int width;
pixel** data;
char* enconding;
}
// You think picture looks like this
height width data encoding
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
picture = | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
C 编程,第五部分:调试
《C 程序调试指南》
这将是一个帮助您调试 C 程序的大型指南。您可以检查错误的不同级别,我们将逐个介绍。请随时添加您在调试 C 程序中发现有用的任何内容,包括但不限于,调试器的使用,识别常见错误类型,陷阱和有效的搜索技巧。
在代码中调试
清洁代码
使用辅助函数使您的代码模块化。如果有重复的任务(例如在 MP2 中获取连续块的指针),请将它们制作为辅助函数。确保每个函数都非常擅长做一件事,这样您就不必两次调试。
假设我们正在通过每次迭代找到最小元素来进行选择排序,如下所示,
void selection_sort(int *a, long len){
for(long i = len-1; i > 0; --i){
long max_index = i;
for(long j = len-1; j >= 0; --j){
if(a[max_index] < a[j]){
max_index = j;
}
}
int temp = a[i];
a[i] = a[max_index];
a[max_index] = temp;
}
}
许多人可以看到代码中的错误,但将上述方法重构为
long max_index(int *a, long start, long end);
void swap(int *a, long idx1, long idx2);
void selection_sort(int *a, long len);
而错误特别在一个函数中。
最后,我们不是一个关于重构/调试代码的课程–事实上,大多数系统代码都很糟糕,你不想读它。但是为了调试,长远来看,采用一些实践可能对你有好处。
断言!
使用断言来确保您的代码在某个特定点之前工作–并且重要的是,确保您以后不会破坏它。例如,如果您的数据结构是双向链表,您可以这样做,assert(node->size == node->next->prev->size)来断言下一个节点指向当前节点。您还可以检查指针是否指向预期的内存地址范围,而不是 null,->size 是合理的等等。NDEBUG 宏将禁用所有断言,因此在调试完成后不要忘记设置它。www.cplusplus.com/reference/cassert/assert/
使用 assert 的一个快速示例是,假设我正在使用 memcpy 编写代码
assert(!(src < dest+n && dest < src+n)); //Checks overlap
memcpy(dest, src, n);
这个检查可以在编译时关闭,但会帮助您避免大量的调试麻烦!
printfs
当一切都失败时,疯狂地打印!您的每个函数都应该知道它要做什么(例如,find_min 最好找到最小的元素)。您希望测试每个函数是否正在做它设定的事情,并确切地查看代码在哪里出错。在竞态条件的情况下,tsan 可能有所帮助,但让每个线程在特定时间打印数据可能有助于您识别竞态条件。
Valgrind
(待办事项)
Tsan
ThreadSanitizer 是 Google 的一个工具,内置在 clang(和 gcc)中,可以帮助您检测代码中的竞态条件。有关该工具的更多信息,请参阅 Github 维基。
请注意,使用 tsan 会使您的代码变慢一些。
#include <pthread.h>
#include <stdio.h>
int Global;
void *Thread1(void *x) {
Global++;
return NULL;
}
int main() {
pthread_t t[2];
pthread_create(&t[0], NULL, Thread1, NULL);
Global = 100;
pthread_join(t[0], NULL);
}
// compile with gcc -fsanitize=thread -pie -fPIC -ltsan -g simple_race.c
我们可以看到变量 Global 存在竞态条件。主线程和使用 pthread_create 创建的线程将尝试同时更改值。但是,ThreadSantizer 能否捕捉到它呢?
$ ./a.out
==================
WARNING: ThreadSanitizer: data race (pid=28888)
Read of size 4 at 0x7f73ed91c078 by thread T1:
#0 Thread1 /home/zmick2/simple_race.c:7 (exe+0x000000000a50)
#1 :0 (libtsan.so.0+0x00000001b459)
Previous write of size 4 at 0x7f73ed91c078 by main thread:
#0 main /home/zmick2/simple_race.c:14 (exe+0x000000000ac8)
Thread T1 (tid=28889, running) created by main thread at:
#0 :0 (libtsan.so.0+0x00000001f6ab)
#1 main /home/zmick2/simple_race.c:13 (exe+0x000000000ab8)
SUMMARY: ThreadSanitizer: data race /home/zmick2/simple_race.c:7 Thread1
==================
ThreadSanitizer: reported 1 warnings
如果我们使用调试标志编译,那么它将给我们变量名。
GDB
介绍:www.cs.cmu.edu/~gilpin/tutorial/
以编程方式设置断点
在使用 GDB 调试复杂的 C 程序时,一个非常有用的技巧是在源代码中设置断点。
int main() {
int val = 1;
val = 42;
asm("int $3"); // set a breakpoint here
val = 7;
}
$ gcc main.c -g -o main && ./main
(gdb) r
[...]
Program received signal SIGTRAP, Trace/breakpoint trap.
main () at main.c:6
6 val = 7;
(gdb) p val
$1 = 42
检查内存内容
www.delorie.com/gnu/docs/gdb/gdb_56.html
例如,
int main() {
char bad_string[3] = {'C', 'a', 't'};
printf("%s", bad_string);
}
$ gcc main.c -g -o main && ./main
$ Cat ZVQ�� $
(gdb) l
1 #include <stdio.h>
2 int main() {
3 char bad_string[3] = {'C', 'a', 't'};
4 printf("%s", bad_string);
5 }
(gdb) b 4
Breakpoint 1 at 0x100000f57: file main.c, line 4.
(gdb) r
[...]
Breakpoint 1, main () at main.c:4
4 printf("%s", bad_string);
(gdb) x/16xb bad_string
0x7fff5fbff9cd: 0x63 0x61 0x74 0xe0 0xf9 0xbf 0x5f 0xff
0x7fff5fbff9d5: 0x7f 0x00 0x00 0xfd 0xb5 0x23 0x89 0xff
(gdb)
在这里,通过使用带有参数16xb的x命令,我们可以看到从内存地址0x7fff5fbff9c(bad_string的值)开始,printf 实际上会看到以下字节序列作为字符串,因为我们提供了一个没有空终止符的格式不正确的字符串。
0x43 0x61 0x74 0xe0 0xf9 0xbf 0x5f 0xff 0x7f 0x00
C 编程,复习问题
主题
-
C 字符串表示
-
C 字符串作为指针
-
char p[]vs char* p
-
简单的 C 字符串函数(strcmp,strcat,strcpy)
-
sizeof char
-
sizeof x vs x*
-
堆内存寿命
-
堆分配调用
-
解引用指针
-
取地址运算符
-
指针算术
-
字符串复制
-
字符串截断
-
双重释放错误
-
字符串字面值
-
打印格式。
-
内存越界错误
-
静态内存
-
fileio POSIX v C 库
-
C io fprintf 和 printf
-
POSIX 文件 io(读|写|打开)
-
stdout 的缓冲
问题/练习
- 以下打印出什么
int main(){
fprintf(stderr, "Hello ");
fprintf(stdout, "It's a small ");
fprintf(stderr, "World\n");
fprintf(stdout, "place\n");
return 0;
}
- 以下两个声明之间有什么区别?其中一个的
sizeof返回什么?
char str1[] = "bhuvan";
char *str2 = "another one";
-
C 中的字符串是什么?
-
编写一个简单的
my_strcmp。my_strcat,my_strcpy或my_strdup呢?奖励:只通过字符串一次编写函数。 -
以下通常应该返回什么?
int *ptr;
sizeof(ptr);
sizeof(*ptr);
-
什么是
malloc?它与calloc有什么不同。一旦内存被malloc,我如何使用realloc? -
&运算符是什么?*呢? -
指针算术。假设以下地址。以下移位是什么?
char** ptr = malloc(10); //0x100
ptr[0] = malloc(20); //0x200
ptr[1] = malloc(20); //0x300
* `ptr + 2`
* `ptr + 4`
* `ptr[0] + 4`
* `ptr[1] + 2000`
* `*((int)(ptr + 1)) + 3`
-
我们如何防止双重释放错误?
-
打印字符串,
int或char的 printf 格式说明符是什么? -
以下代码有效吗?如果是,为什么?
output位于哪里?
char *foo(int var){
static char output[20];
snprintf(output, 20, "%d", var);
return output;
}
-
编写一个接受字符串并打开该文件的函数,每次打印出文件的 40 个字节,但每隔一次打印都会颠倒字符串(尝试使用 POSIX API 实现)。
-
POSIX 文件描述符模型和 C 的
FILE*之间有哪些区别(即使用了哪些函数调用,哪个是缓冲的)?POSIX 内部使用 C 的FILE*还是反之亦然?
二、进程
进程,第一部分:介绍
概述
进程是正在运行的程序(有点)。进程也只是计算机程序运行的一个实例。进程有很多可用的东西。在每个程序开始时,您会得到一个进程,但每个程序都可以创建更多的进程。事实上,您的操作系统只启动一个进程,所有其他进程都是从那个进程分叉出来的——在启动时都是在后台完成的。
在开始时
当您的 Linux 机器上的操作系统启动时,会创建一个名为init.d的进程。该进程是一个特殊的进程,处理信号、中断和某些内核元素的持久性模块。每当您想要创建一个新进程时,都会调用fork(将在后面的部分讨论)并使用另一个函数来加载另一个程序。
进程隔离
进程非常强大,但它们是隔离的!这意味着默认情况下,没有进程可以与另一个进程通信。这非常重要,因为如果您有一个庞大的系统(比如 EWS),那么您希望一些进程具有更高的特权(监控、管理),而您绝对不希望普通用户能够故意或者意外地通过修改进程来使整个系统崩溃。
如果我运行以下代码,
int secrets; //maybe defined in the kernel or else where
secrets++;
printf("%d\n", secrets);
在两个不同的终端上,正如您所猜测的,它们都会打印出 1 而不是 2。即使我们改变代码以执行一些非常巧妙的操作(除了直接读取内存),也没有办法改变另一个进程的状态(好吧,也许这个,但那就有点太深入了)。
进程内容
内存布局
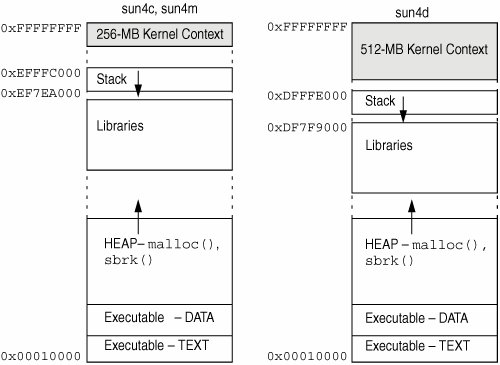
当一个进程启动时,它会得到自己的地址空间。这意味着每个进程都会得到(对于内存
-
堆栈。堆栈是存储自动变量和函数调用返回地址的地方。每次声明一个新变量,程序都会将堆栈指针向下移动,以保留变量的空间。堆栈的这一部分是可写的,但不可执行。如果堆栈增长得太远(意味着它要么超出了预设的边界,要么与堆相交),您很可能会得到堆栈溢出,最终导致段错误或类似的错误。默认情况下,堆栈是静态分配的,这意味着只有一定数量的空间可以写入
-
堆。堆是一个不断扩大的内存区域。如果要分配一个大对象,它就会放在这里。堆从文本段的顶部开始向上增长(这意味着有时当您调用
malloc时,它会要求操作系统将堆边界向上推)。这个区域也是可写的,但不可执行。如果系统受限或者地址用完了(在 32 位系统上更常见),就可能用完堆内存。 -
数据段。这包含了所有的全局变量。这一部分从文本段的末尾开始,大小是静态的,因为全局变量的数量在编译时就已知。这一部分是可写的,但不可执行,没有其他太花哨的东西。
-
文本段。这可以说是地址中最重要的部分。这是存储所有代码的地方。由于汇编编译成了 1 和 0,这就是 1 和 0 存储的地方。程序计数器在这个段中执行指令,并向下移动到下一个指令。重要的是要注意,这是代码中唯一可执行的部分。如果您尝试在运行时更改代码,很可能会导致段错误(虽然有办法绕过,但假设它会导致段错误)。
-
为什么它不从零开始?这超出了本课程的范围,但这是出于安全考虑。
文件描述符

正如小册子所示,操作系统跟踪文件描述符及其指向的内容。我们将在后面看到,文件描述符不一定指向实际文件,操作系统会为您跟踪它们。另外,请注意,在进程之间文件描述符可能会被重用,但在进程内部它们是唯一的。
文件描述符也有位置的概念。您可以完全从磁盘上读取文件,因为操作系统跟踪文件中的位置,并且该位置也属于您的进程。
安全/权限
进程功能/限制(奖励)
当您复习期末考试时,您可以回来看看进程也具有所有这些东西。第一次看时 - 它可能不太有意义。
进程 ID(PID)
为了跟踪所有这些进程,您的操作系统为每个进程分配一个数字,该进程称为 PID,即进程 ID。
进程还可以包含
-
映射
-
状态
-
文件描述符
-
权限
分叉,第一部分:介绍
警告
进程分叉是一个非常强大(也非常危险)的工具。如果出错并导致分叉炸弹(稍后在本页解释),你可能会导致整个系统崩溃。为了减少这种可能性,通过在命令行中输入ulimit -u 40来将最大进程数限制为一个小数字,例如 40。请注意,此限制仅适用于用户,这意味着如果你引发了分叉炸弹,那么你将无法杀死你刚刚创建的所有进程,因为调用killall需要你的 shell 来fork()…讽刺吧?那么我们该怎么办呢?一个解决方案是提前生成另一个用户(例如 root)的另一个 shell 实例并从那里杀死进程。另一个方法是使用内置的exec命令杀死所有用户进程(小心,你只有一次机会)。最后,你可以重新启动系统 😃
在测试fork()代码时,请确保你有根用户和/或物理访问权限。如果你必须远程处理fork()代码,请记住,在紧急情况下kill -9 -1会帮助你。
总结:如果你没有准备好,fork可能会非常危险。你已经被警告过了。
分叉介绍
fork做什么?
fork系统调用克隆当前进程以创建一个新进程。它通过复制现有进程的状态创建一个新进程(子进程),有一些细微的差异(下面讨论)。子进程不是从 main 开始。相反,它像父进程一样从fork()返回。
什么是最简单的fork()例子?
这是一个非常简单的例子…
printf("I'm printed once!\n");
fork();
// Now there are two processes running
// and each process will print out the next line.
printf("You see this line twice!\n");
为什么这个例子会打印两次 42?
以下程序打印出 42 两次 - 但fork()在printf之后!?为什么?
#include <unistd.h> /*fork declared here*/
#include <stdio.h> /* printf declared here*/
int main() {
int answer = 84 >> 1;
printf("Answer: %d", answer);
fork();
return 0;
}
printf行*只执行一次,但请注意打印的内容没有刷新到标准输出(没有打印换行,我们没有调用fflush或更改缓冲模式)。因此,输出文本仍然在进程内存中等待发送。当执行fork()时,整个进程内存被复制,包括缓冲区。因此,子进程从一个非空输出缓冲区开始,该缓冲区将在程序退出时刷新。
如何编写针对父进程和子进程不同的代码?
检查fork()的返回值。返回值-1 = 失败;0 = 在子进程中;正数 = 在父进程中(返回值是子进程 id)。以下是记住哪个是哪个的一种方法:
子进程可以通过调用getppid()找到其父进程 - 被复制的原始进程 - 因此不需要从fork()获得任何额外的返回信息。然而,父进程只能从fork的返回值中找到新子进程的 id:
pid_t id = fork();
if (id == -1) exit(1); // fork failed
if (id > 0)
{
// I'm the original parent and
// I just created a child process with id 'id'
// Use waitpid to wait for the child to finish
} else { // returned zero
// I must be the newly made child process
}
什么是分叉炸弹?
'分叉炸弹’是指尝试创建无限数量的进程。下面是一个简单的例子:
while (1) fork();
这通常会使系统几乎停滞,因为它试图为大量准备运行的进程分配 CPU 时间和内存。评论:系统管理员不喜欢分叉炸弹,可能会设置每个用户可以拥有的进程数量的上限,或者可能会撤销登录权限,因为它会为其他用户的程序带来麻烦。你也可以使用setrlimit()来限制创建的子进程数量。
分叉炸弹并不一定是恶意的 - 它们偶尔会由于学生编码错误而发生。
Angrave 建议《黑客帝国》三部曲,机器和人最终共同努力击败不断增殖的 Agent-Smith,是基于一个基于 AI 驱动的分叉炸弹的电影情节。
等待和执行
父进程如何等待子进程完成?
使用waitpid(或wait)。
pid_t child_id = fork();
if (child_id == -1) { perror("fork"); exit(EXIT_FAILURE);}
if (child_id > 0) {
// We have a child! Get their exit code
int status;
waitpid( child_id, &status, 0 );
// code not shown to get exit status from child
} else { // In child ...
// start calculation
exit(123);
}
我可以让子进程执行另一个程序吗?
是的。在 fork 后使用其中一个exec函数。exec函数集用正在调用的进程映像替换进程映像。这意味着exec调用后的任何代码行都将被替换。任何其他要求子进程执行的工作都应该在exec调用之前完成。
Wikipedia 文章在帮助您理解 exec 系列名称方面做得很好。
命名方案可以缩短如下
每个的基础都是 exec(执行),后面跟着一个或多个字母:
e - 指向环境变量的指针数组被显式传递给新的进程映像。
l - 命令行参数被逐个传递(列表)给函数。
p - 使用 PATH 环境变量来查找要执行的文件名。
v - 命令行参数作为指针数组(向量)传递给函数。
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char**argv) {
pid_t child = fork();
if (child == -1) return EXIT_FAILURE;
if (child) { /* I have a child! */
int status;
waitpid(child , &status ,0);
return EXIT_SUCCESS;
} else { /* I am the child */
// Other versions of exec pass in arguments as arrays
// Remember first arg is the program name
// Last arg must be a char pointer to NULL
execl("/bin/ls", "ls","-alh", (char *) NULL);
// If we get to this line, something went wrong!
perror("exec failed!");
}
}
执行另一个程序的简单方法
使用system。以下是如何使用它的方法:
#include <unistd.h>
#include <stdlib.h>
int main(int argc, char**argv) {
system("ls");
return 0;
}
system调用将分叉,执行由参数传递的命令,原始父进程将等待其完成。这也意味着system是一个阻塞调用:父进程在由system启动的进程退出之前无法继续。这可能有用,也可能没有。此外,system实际上创建了一个 shell,然后给出字符串,这比直接使用exec更耗费资源。标准 shell 将使用PATH环境变量搜索与命令匹配的文件名。对于许多简单的运行此命令问题,使用 system 通常足够了,但对于更复杂或微妙的问题,它可能很快变得有限,并且它隐藏了分叉-执行-等待模式的机制,因此我们鼓励您学习并使用fork exec和waitpid。
最愚蠢的 fork 示例是什么?
下面显示了一个稍微愚蠢的例子。它会打印什么?尝试使用多个参数运行您的程序。
#include <unistd.h>
#include <stdio.h>
int main(int argc, char **argv) {
pid_t id;
int status;
while (--argc && (id=fork())) {
waitpid(id,&status,0); /* Wait for child*/
}
printf("%d:%s\n", argc, argv[argc]);
return 0;
}
令人惊奇的并行明显 O(N) sleepsort是今天的愚蠢赢家。首次发布于2011 年的 4chan。下面显示了这种糟糕但有趣的排序算法的一个版本。
int main(int c, char **v)
{
while (--c > 1 && !fork());
int val = atoi(v[c]);
sleep(val);
printf("%d\n", val);
return 0;
}
注意:由于系统调度程序的工作方式,该算法实际上并不是 O(N)。虽然有并行算法可以在每个进程中以 O(log(N))运行,但这不幸地不是其中之一。
子进程与父进程有什么不同?
关键区别包括:
-
由
getpid()返回的进程 ID。由getppid()返回的父进程 ID。 -
当子进程完成时,父进程通过信号 SIGCHLD 被通知,但反之则不然。
-
子进程不会继承未决信号或定时器警报。完整列表请参阅fork man page
子进程共享打开的文件句柄吗?
是的!实际上,两个进程都使用相同的底层内核文件描述符。例如,如果一个进程将随机访问位置倒回到文件的开头,那么两个进程都会受到影响。
子进程和父进程都应该close(或fclose)它们的文件描述符或文件句柄。
如何获取更多信息?
阅读 man 页面!
分叉,第二部分:分叉,执行,等待
模式
以下的’exec’示例是做什么的?
#include <unistd.h>
#include <fcntl.h> // O_CREAT, O_APPEND etc. defined here
int main() {
close(1); // close standard out
open("log.txt", O_RDWR | O_CREAT | O_APPEND, S_IRUSR | S_IWUSR);
puts("Captain's log");
chdir("/usr/include");
// execl( executable, arguments for executable including program name and NULL at the end)
execl("/bin/ls", /* Remaining items sent to ls*/ "/bin/ls", ".", (char *) NULL); // "ls ."
perror("exec failed");
return 0; // Not expected
}
上述代码中没有错误检查(我们假设 close、open、chdir 等都按预期工作)。
-
open:将使用最低可用的文件描述符(即 1);因此标准输出现在转到日志文件。
-
chdir:将当前目录更改为/usr/include
-
execl:用/bin/ls 替换程序图像,并调用它的 main()方法
-
perror:我们不希望到达这里 - 如果到达了,那么 exec 失败了。
微妙的 fork 炸弹错误
这段代码有什么问题
#include <unistd.h>
#define HELLO_NUMBER 10
int main(){
pid_t children[HELLO_NUMBER];
int i;
for(i = 0; i < HELLO_NUMBER; i++){
pid_t child = fork();
if(child == -1){
break;
}
if(child == 0){ //I am the child
execlp("ehco", "echo", "hello", NULL);
}
else{
children[i] = child;
}
}
int j;
for(j = 0; j < i; j++){
waitpid(children[j], NULL, 0);
}
return 0;
}
我们拼错了ehco,所以我们无法exec它。这是什么意思?我们只创建了 2**10 个进程,而不是 10 个进程,炸毁了我们的机器。我们如何防止这种情况?在 exec 后立即放置一个退出,这样如果 exec 失败,我们就不会炸毁我们的机器。
子进程从父进程继承了什么?
-
打开文件句柄。如果父进程稍后寻求,比如,回到文件的开头,那么这也会影响子进程(反之亦然)。
-
信号处理程序
-
当前工作目录
-
环境变量
有关更多详细信息,请参阅fork man page。
子进程与父进程有什么不同?
进程 ID 是不同的。在子进程中调用getppid()(注意两个’p’)将得到与在父进程中调用 getpid()相同的结果。有关更多详细信息,请参阅 fork man page。
我如何等待我的子进程完成?
使用waitpid或wait。父进程将暂停,直到wait(或waitpid)返回。请注意,此解释忽略了重新启动的讨论。
fork-exec-wait 模式是什么
一个常见的编程模式是调用fork,然后是exec和wait。原始进程调用 fork,创建一个子进程。然后子进程使用 exec 来启动一个新程序的执行。与此同时,父进程使用wait(或waitpid)来等待子进程完成。请参阅下面的完整代码示例。
我如何启动一个同时运行的后台进程?
不要等待它们!您的父进程可以继续执行代码,而无需等待子进程。请注意,在实践中,通过在调用 exec 之前关闭打开的文件描述符,后台进程也可以与父进程的输入和输出流断开连接。
然而,在父进程完成之前完成的子进程可能会变成僵尸。有关更多信息,请参阅僵尸页面。
僵尸
好的父母不会让他们的孩子变成僵尸!
当一个子进程完成(或终止)时,它仍然占据内核进程表中的一个槽。只有在子进程被“等待”后,该槽才会再次可用。
一个长时间运行的程序可能会通过不断创建进程而永远不等待它们来创建许多僵尸。
太多僵尸会有什么影响?
最终,内核进程表中会没有足够的空间来创建新进程。因此,fork()会失败,并且可能使系统难以/无法使用 - 例如,仅登录就需要一个新进程!
系统如何帮助防止僵尸?
一旦一个进程完成,它的任何子进程都将被分配给“init” - 具有 pid 为 1 的第一个进程。因此,这些子进程将看到 getppid()返回值为 1。这些孤儿最终会完成,并在短暂的时刻成为僵尸。幸运的是,init 进程会自动等待它的所有子进程,从而将这些僵尸从系统中移除。
我如何防止僵尸?(警告:简化的答案)
等待你的孩子!
waitpid(child, &status, 0); // Clean up and wait for my child process to finish.
请注意,我们假设获得 SIGCHLD 事件的唯一原因是子进程已经完成(这并不完全正确 - 有关更多详细信息,请参阅 man page)。
一个健壮的实现还会检查中断状态,并在循环中包含上述内容。继续阅读,了解更健壮的实现的讨论。
我如何使用 SIGCHLD 异步等待我的子进程?(高级)
警告:本节使用了我们尚未完全介绍的信号。当子进程完成时,父进程会收到 SIGCHLD 信号,因此信号处理程序可以等待该进程。下面显示了一个稍微简化的版本。
pid_t child;
void cleanup(int signal) {
int status;
waitpid(child, &status, 0);
write(1,"cleanup!\n",9);
}
int main() {
// Register signal handler BEFORE the child can finish
signal(SIGCHLD, cleanup); // or better - sigaction
child = fork();
if (child == -1) { exit(EXIT_FAILURE);}
if (child == 0) { /* I am the child!*/
// Do background stuff e.g. call exec
} else { /* I'm the parent! */
sleep(4); // so we can see the cleanup
puts("Parent is done");
}
return 0;
}
然而,上面的例子忽略了一些微妙的地方:
-
可能有多个子进程已经完成,但父进程只会收到一个 SIGCHLD 信号(信号不会排队)
-
SIGCHLD 信号可能是因为其他原因而发送的(例如,子进程暂时停止)
下面显示了一个更健壮的代码来清除僵尸进程。
void cleanup(int signal) {
int status;
while (waitpid((pid_t) (-1), 0, WNOHANG) > 0) {}
}
那么什么是环境变量?
环境变量是系统为所有进程保留的变量。您的系统现在已经设置了这些!在 Bash 中,您可以检查其中一些
$ echo $HOME
/home/bhuvy
$ echo $PATH
/usr/local/sbin:/usr/bin:...
如何在 C/C++中获取这些?您可以使用getenv和setenv函数
char* home = getenv("HOME"); // Will return /home/bhuvy
setenv("HOME", "/home/bhuvan", 1 /*set overwrite to true*/ );
那么这些环境变量对父进程/子进程有什么意义呢?
每个进程都有自己的环境变量字典,这些变量会被复制到子进程中。这意味着,如果父进程更改其环境变量,它不会传递给子进程,反之亦然。如果您想要使用不同的环境变量执行程序,这在 fork-exec-wait 三部曲中很重要。
例如,您可以编写一个 C 程序,循环遍历所有时区,并执行date命令以打印出所有本地的日期和时间。环境变量用于各种程序,因此修改它们很重要。
进程控制,第一部分:等待宏,使用信号
等待宏
我可以找出我的子进程的退出值吗?
您可以找到子进程的最低 8 位退出值(main()的返回值或包含在exit()中的值):使用“等待宏” - 通常您将使用“WIFEXITED”和“WEXITSTATUS”。有关更多信息,请参阅wait/waitpid手册页。
int status;
pid_t child = fork();
if (child == -1) return 1; //Failed
if (child > 0) { /* I am the parent - wait for the child to finish */
pid_t pid = waitpid(child, &status, 0);
if (pid != -1 && WIFEXITED(status)) {
int low8bits = WEXITSTATUS(status);
printf("Process %d returned %d" , pid, low8bits);
}
} else { /* I am the child */
// do something interesting
execl("/bin/ls", "/bin/ls", ".", (char *) NULL); // "ls ."
}
一个进程只能有 256 个返回值,其余的位是信息性的。
位移
请注意,没有必要记住这些,这只是信息存储在状态变量内部的高级概述
/* 如果 WIFEXITED(STATUS),则为状态的低 8 位。 */
#define __WEXITSTATUS(status) (((status) & 0xff00) >> 8)
/* 如果 WIFSIGNALED(STATUS),则为终止信号。 */
#define __WTERMSIG(status) ((status) & 0x7f)
/* 如果 WIFSTOPPED(STATUS),则为停止子进程的信号。 */
#define __WSTOPSIG(status) __WEXITSTATUS(status)
/* 如果 STATUS 指示正常终止,则为非零。 */
#define __WIFEXITED(status) (__WTERMSIG(status) == 0)
内核有一种内部方式来跟踪已发出、已退出或已停止的信号。该 API 被抽象化,以便内核开发人员可以随意更改。
小心。
请记住,如果前提条件得到满足,宏才有意义。这意味着如果进程被发出信号,进程的退出状态将不会被定义。宏不会为您检查,因此需要编程确保逻辑正确。
信号
什么是信号?
信号是内核提供给我们的一种构造。它允许一个进程异步地向另一个进程发送信号(类似于消息)。如果该进程希望接受该信号,它可以,并且对于大多数信号,可以决定如何处理该信号。这里是一个信号的简短列表(非全面)。
| 名称 | 默认操作 | 通常用例 |
|---|---|---|
SIGINT | 终止进程(可以被捕获) | 告诉进程停止运行 |
SIGQUIT | 终止进程(可以被捕获) | 告诉进程停止运行 |
SIGSTOP | 停止进程(无法被捕获) | 停止进程以便继续 |
SIGCONT | 继续进程 | 继续运行进程 |
SIGKILL | 终止进程(无法被忽略) | 你想让你的进程消失 |
我可以暂停我的子进程吗?
是的!您可以通过发送 SIGSTOP 信号临时暂停正在运行的进程。如果成功,它将冻结一个进程;即进程将不再分配任何 CPU 时间。
要允许进程恢复执行,请发送 SIGCONT 信号。
例如,这里有一个程序,每秒慢慢打印一个点,最多 59 个点。
#include <unistd.h>
#include <stdio.h>
int main() {
printf("My pid is %d\n", getpid() );
int i = 60;
while(--i) {
write(1, ".",1);
sleep(1);
}
write(1, "Done!",5);
return 0;
}
我们首先将进程在后台启动(注意末尾的&)。然后通过使用 kill 命令从 shell 进程向其发送信号。
>./program &
My pid is 403
...
>kill -SIGSTOP 403
>kill -SIGCONT 403
如何在 C 中杀死/停止/暂停我的子进程?
在 C 中,使用kill POSIX 调用向子进程发送信号,
kill(child, SIGUSR1); // Send a user-defined signal
kill(child, SIGSTOP); // Stop the child process (the child cannot prevent this)
kill(child, SIGTERM); // Terminate the child process (the child can prevent this)
kill(child, SIGINT); // Equivalent to CTRL-C (by default closes the process)
正如我们上面所看到的,在 shell 中也有一个 kill 命令,例如获取正在运行的进程列表,然后终止进程 45 和进程 46
ps
kill -l
kill -9 45
kill -s TERM 46
如何检测“CTRL-C”并优雅地清理?
我们稍后会回到信号 - 这只是一个简短的介绍。在 Linux 系统上,如果您有兴趣了解更多信息(例如系统和库调用的异步信号安全列表),请参阅man -s7 signal。
信号处理程序内的可执行代码受到严格限制。大多数库和系统调用都不是“异步信号安全”的 - 它们不能在信号处理程序内使用,因为它们不是可重入安全的。在单线程程序中,信号处理会暂时中断程序执行,以执行信号处理程序代码。假设您的原始程序在执行malloc库代码时被中断;malloc 使用的内存结构将不处于一致状态。在信号处理程序中调用printf(它使用malloc)是不安全的,并将导致“未定义行为”,即它不再是一个有用的、可预测的程序。实际上,您的程序可能会崩溃、计算或生成不正确的结果,或者停止运行(“死锁”),具体取决于在执行信号处理程序代码时您的程序正在执行什么。
信号处理程序的一个常见用途是设置一个布尔标志,该标志偶尔被轮询(读取)作为程序正常运行的一部分。例如,
int pleaseStop ; // See notes on why "volatile sig_atomic_t" is better
void handle_sigint(int signal) {
pleaseStop = 1;
}
int main() {
signal(SIGINT, handle_sigint);
pleaseStop = 0;
while ( ! pleaseStop) {
/* application logic here */
}
/* cleanup code here */
}
上述代码在纸上看起来可能是正确的。然而,我们需要向编译器和将执行main()循环的 CPU 核心提供一个提示。我们需要防止编译器优化:表达式! pleaseStop似乎是一个循环不变量,即永远为真,因此可以简化为true。其次,我们需要确保pleaseStop的值不会被缓存在 CPU 寄存器中,而是始终从主存中读取和写入。sig_atomic_t类型意味着变量的所有位可以作为“原子操作”进行读取或修改 - 一个不可中断的操作。不可能读取由一些新位值和旧位值组成的值。
通过使用正确类型的volatile sig_atomic_t来指定pleaseStop,我们可以编写可移植的代码,其中主循环将在信号处理程序返回后退出。sig_atomic_t类型在大多数现代平台上可以与int一样大,但在嵌入式系统上可能只能表示(-127 至 127)的值,并且只能表示(-127 至 127)的值。
volatile sig_atomic_t pleaseStop;
这种模式的两个示例可以在“COMP”中找到,这是一个基于终端的 1Hz 4 位计算机(github.com/gto76/comp-cpp/blob/1bf9a77eaf8f57f7358a316e5bbada97f2dc8987/src/output.c#L121)。使用了两个布尔标志。一个用于标记SIGINT(CTRL-C)的传递,并优雅地关闭程序,另一个用于标记SIGWINCH信号以检测终端调整大小并重新绘制整个显示。
进程复习问题
主题
-
正确使用 fork、exec 和 waitpid
-
使用带有路径的 exec
-
理解 fork、exec 和 waitpid 的作用。例如,如何使用它们的返回值。
-
SIGKILL 与 SIGSTOP 与 SIGINT。
-
按下 CTRL-C 时发送了什么信号?
-
从 shell 或 kill POSIX 调用使用 kill。
-
进程内存隔离。
-
进程内存布局(堆在哪里,栈等;无效的内存地址)。
-
什么是 fork 炸弹、僵尸进程和孤儿进程?如何创建/删除它们。
-
getpid 与 getppid
-
如何使用 WAIT 退出状态宏 WIFEXITED 等。
问题/练习
-
带有 p 和不带 p 的 execs 有什么区别?操作系统是什么?
-
如何将命令行参数传递给
execl*?execv*呢?按照惯例,第一个命令行参数应该是什么? -
如何知道
exec或fork失败了? -
传递给 wait 的
int *status指针是什么?wait 何时失败? -
SIGKILL、SIGSTOP、SIGCONT、SIGINT之间有哪些区别?默认行为是什么?哪些可以设置信号处理程序? -
按下
CTRL-C时发送了什么信号? -
我的终端锚定在 PID = 1337,并且刚刚变得无响应。给我写一个终端命令和 C 代码,向其发送
SIGQUIT。 -
一个进程能否通过正常手段改变另一个进程的内存?为什么?
-
堆、栈、数据和文本段在哪里?哪些段可以写入?无效的内存地址是什么?
-
用 C 语言编写一个 fork 炸弹(请不要运行它)。
-
什么是孤儿进程?它如何变成僵尸进程?如何成为一个好的父进程?
-
当父母告诉你不能做某事时,你是不是很讨厌?给我写一个程序,向你的父进程发送
SIGSTOP。 -
编写一个 fork exec 等待可执行文件的函数,并使用等待宏告诉我进程是否正常退出或被信号中断。如果进程正常退出,则打印返回值。如果不是,则打印导致进程终止的信号编号。
三、内存和分配器
内存,第一部分:堆内存介绍
C 动态内存分配
当我调用 malloc 时会发生什么?
函数malloc是一个 C 库调用,用于保留一块连续的内存。与堆栈内存不同,内存保持分配状态,直到使用相同指针调用free。还有calloc和realloc,下面将讨论它们。
malloc 可能失败吗?
如果malloc无法保留更多内存,则返回NULL。健壮的程序应该检查返回值。如果您的代码假设malloc成功,但实际上没有成功,那么当它尝试写入地址 0 时,您的程序很可能会崩溃(段错误)。
堆在哪里,有多大?
堆是进程内存的一部分,它没有固定的大小。当您调用malloc(calloc,realloc)和free时,C 库将执行堆内存分配。
首先快速回顾一下进程内存:进程是程序的运行实例。每个进程都有自己的地址空间。例如,在 32 位机器上,您的进程大约有 40 亿个地址可供使用,但并非所有这些地址都是有效的,甚至映射到实际的物理内存(RAM)。在进程的内存中,您将找到可执行代码、堆栈空间、环境变量、全局(静态)变量和堆。
通过调用sbrk,C 库可以根据程序对堆内存的需求增加堆的大小。由于堆和堆栈(每个线程一个)需要增长,我们将它们放在地址空间的相对两端。因此,对于典型的架构,堆将向上增长,堆栈向下增长。
真相:现代操作系统内存分配器不再需要sbrk-相反,它们可以请求独立的虚拟内存区域并维护多个内存区域。例如,大量请求可以放置在与小分配请求不同的内存区域中。但是,这个细节是一个不需要的复杂性:碎片化和有效分配内存的问题仍然存在,因此我们将忽略这个实现细节,并将其写成堆是一个单一区域的样子。
如果我们编写一个多线程程序(稍后会详细介绍),我们将需要多个堆栈(每个线程一个),但只有一个堆。
在典型的架构中,堆是数据段的一部分,它从代码和全局变量的上方开始。
程序需要调用 brk 或 sbrk 吗?
通常不需要(尽管调用sbrk(0)可能会很有趣,因为它告诉您堆当前的结束位置)。相反,程序使用malloc,calloc,realloc和free,它们是 C 库的一部分。当需要额外的堆内存时,这些函数的内部实现将调用sbrk。
void *top_of_heap = sbrk(0);
malloc(16384);
void *top_of_heap2 = sbrk(0);
printf("The top of heap went from %p to %p \n", top_of_heap, top_of_heap2);
示例输出:堆的顶部从 0x4000 到 0xa000
什么是 calloc?
与malloc不同,calloc将内存内容初始化为零,并且还接受两个参数(项目的数量和每个项目的字节大小)。一个朴素但可读的calloc实现如下:
void *calloc(size_t n, size_t size)
{
size_t total = n * size; // Does not check for overflow!
void *result = malloc(total);
if (!result) return NULL;
// If we're using new memory pages
// just allocated from the system by calling sbrk
// then they will be zero so zero-ing out is unnecessary,
memset(result, 0, total);
return result;
}
有关这些限制的高级讨论在这里。
程序员通常使用calloc而不是在malloc后显式调用memset,以将内存内容设置为零。请注意,calloc(x,y)与calloc(y,x)相同,但您应该遵循手册的约定。
// Ensure our memory is initialized to zero
link_t *link = malloc(256);
memset(link, 0, 256); // Assumes malloc returned a valid address!
link_t *link = calloc(1, 256); // safer: calloc(1, sizeof(link_t));
为什么 sbrk 首次返回的内存初始化为零?
如果操作系统没有清零物理 RAM 的内容,可能会导致一个进程了解到先前使用过该内存的另一个进程的内存。这将是一个安全漏洞。
不幸的是,这意味着对于在释放任何内存之前进行的malloc请求和简单程序(最终使用系统中新保留的内存)来说,内存通常是零。然后程序员错误地编写了假设 malloc’d 内存将始终为零的 C 程序。
char* ptr = malloc(300);
// contents is probably zero because we get brand new memory
// so beginner programs appear to work!
// strcpy(ptr, "Some data"); // work with the data
free(ptr);
// later
char *ptr2 = malloc(308); // Contents might now contain existing data and is probably not zero
为什么 malloc 不总是将内存初始化为零?
性能!我们希望 malloc 尽可能快。清零内存可能是不必要的。
realloc 是什么,什么时候会用到它?
realloc允许你调整之前通过 malloc、calloc 或 realloc 在堆上分配的现有内存分配的大小。realloc 最常见的用途是调整用于保存值数组的内存。下面建议一个朴素但可读的 realloc 版本
void * realloc(void * ptr, size_t newsize) {
// Simple implementation always reserves more memory
// and has no error checking
void *result = malloc(newsize);
size_t oldsize = ... //(depends on allocator's internal data structure)
if (ptr) memcpy(result, ptr, newsize < oldsize ? newsize : oldsize);
free(ptr);
return result;
}
下面显示了 realloc 的错误用法:
int *array = malloc(sizeof(int) * 2);
array[0] = 10; array[1] = 20;
// Ooops need a bigger array - so use realloc..
realloc (array, 3); // ERRORS!
array[2] = 30;
上面的代码包含两个错误。首先,我们需要 3*sizeof(int)字节,而不是 3 字节。其次,realloc 可能需要将内存的现有内容移动到新位置。例如,可能没有足够的空间,因为相邻的字节已经被分配。下面显示了 realloc 的正确用法。
array = realloc(array, 3 * sizeof(int));
// If array is copied to a new location then old allocation will be freed.
一个健壮的版本还会检查NULL返回值。注意realloc可以用来增加和缩小分配。
我在哪里可以读到更多信息?
参见man 页面!
内存分配的速度有多重要?
非常重要!在大多数应用程序中,分配和释放堆内存是常见操作。
分配简介
最愚蠢的 malloc 和 free 实现是什么,有什么问题?
void* malloc(size_t size)
// Ask the system for more bytes by extending the heap space.
// sbrk Returns -1 on failure
void *p = sbrk(size);
if(p == (void *) -1) return NULL; // No space left
return p;
}
void free() {/* Do nothing */}
上述实现遭受两个主要缺点:
-
系统调用很慢(与库调用相比)。我们应该保留大量内存,只偶尔向系统请求更多。
-
不重用释放的内存。我们的程序从不重用堆内存-它只是不断地要求更大的堆。
如果这个分配器在一个典型的程序中使用,进程将很快耗尽所有可用的内存。相反,我们需要一个能够有效利用堆空间,并且只在必要时请求更多内存的分配器。
什么是放置策略?
在程序执行期间,内存被分配和释放,因此堆内存中会有间隙(空洞),可以重新用于未来的内存请求。内存分配器需要跟踪堆的哪些部分当前被分配,哪些部分是可用的。
假设我们当前的堆大小是 64K,尽管并非所有都在使用,因为一些先前通过程序释放的 malloc 内存已经被释放了:
| 16KB free | 10KB allocated | 1KB free | 1KB allocated | 30KB free | 4KB allocated | 2KB free |
|---|
如果执行一个新的 2KB 的 malloc 请求(malloc(2048)),malloc 应该在哪里保留内存?它可以使用最后的 2KB 空洞(恰好是完美的大小!),或者它可以分割其他两个空闲空洞中的一个。这些选择代表不同的放置策略。
无论选择哪个空洞,分配器都需要将空洞分成两部分:新分配的空间(将返回给程序)和一个较小的空洞(如果有剩余空间)。
完美拟合策略找到足够大的最小空洞(至少 2KB):
| 16KB free | 10KB allocated | 1KB free | 1KB allocated | 30KB free | 4KB allocated | 2KB HERE! |
|---|
最坏的拟合策略找到足够大的最大空洞(所以将 30KB 的空洞分成两部分):
| 16KB free | 10KB allocated | 1KB free | 1KB allocated | 2KB HERE! | 28KB free | 4KB allocated | 2KB free |
|---|
第一个适合策略找到第一个足够大的可用空洞(将 16KB 的空洞分成两部分):
2KB HERE! | 14KB free | 10KB allocated | 1KB free | 1KB allocated | 30KB free | 4KB allocated | 2KB free |
|---|
什么是外部碎片?
在下面的例子中,64KB 的堆内存中,有 17KB 被分配,47KB 是空闲的。然而,最大的可用块只有 30KB,因为我们的可用未分配堆内存被分成了更小的块。
16KB free | 10KB allocated | 1KB free | 1KB allocated | 30KB free | 4KB allocated | 2KB free |
|---|
放置策略对外部碎片和性能有什么影响?
不同的策略以不明显的方式影响堆内存的碎片化,这只能通过数学分析或在真实条件下进行仔细模拟(例如模拟数据库或 Web 服务器的内存分配请求)来发现。例如,最佳适配乍看起来似乎是一个很好的策略,但是,如果我们找不到一个完全大小合适的空洞,那么这种放置会产生许多微小的无法使用的空洞,导致高度碎片化。它还需要扫描所有可能的空洞。
首次适配的优势在于它不会评估所有可能的放置,因此更快。
由于最坏适配针对最大的未分配空间,如果需要大量分配,则这是一个不好的选择。
在实践中,首次适配和下次适配(这里没有讨论)通常是常见的放置策略。还有混合方法和许多其他选择(请参见实现内存分配器页面)。
编写堆分配器的挑战是什么?
主要挑战是,
-
需要最小化碎片化(即最大化内存利用)
-
需要高性能
-
繁琐的实现(使用链表和指针算术进行大量指针操作)
一些额外的评论:
碎片化和性能都取决于应用程序的分配配置文件,这可以进行评估但无法预测,并且在实践中,在特定的使用条件下,专用分配器通常可以胜过通用实现。
分配器事先不知道程序的内存分配请求。即使我们知道,这也是著名的 NP 难题背包问题!
如何实现内存分配器?
好问题。实现内存分配器
内存,第二部分:实现内存分配器
内存分配器教程
内存分配器需要跟踪哪些字节当前已分配,哪些可供使用。本页介绍了构建分配器的实现和概念细节,即实现malloc和free的实际代码。
这个页面讨论了块的链接 - 我应该为它们分配内存吗?
尽管在概念上我们考虑创建链接列表和块列表,但我们不需要“malloc 内存”来创建它们!相反,我们将整数和指针写入我们已经控制的内存中,以便以后可以一致地从一个地址跳到下一个地址。这些内部信息代表了一些开销。因此,即使我们从系统请求了 1024 KB 的连续内存,我们也无法将所有内存提供给运行的程序。
块思考
我们可以将我们的堆内存看作是一个块的列表,其中每个块都是已分配或未分配的。我们不是存储一个显式的指针列表,而是存储关于块大小的信息作为块的一部分。因此,在概念上,有一个空闲块的列表,但它是隐式的,即以每个块的大小信息的形式存储。
我们可以通过添加块的大小来从一个块导航到下一个块。例如,如果您有一个指向块起始位置的指针p,那么next_block将在((char *)p) + *(size_t *) p,如果您将块的大小以字节存储。将char *强制转换为确保指针算术是以字节计算的。将size_t *强制转换为确保在p处读取的内存是一个大小值,如果p是void *或char *类型,则必须。
调用程序永远不会看到这些值;它们是内存分配器实现的内部值。
例如,假设您的分配器被要求保留 80 字节(malloc(80))并需要 8 字节的内部头数据。分配器需要找到至少 88 字节的未分配空间。在更新堆数据后,它将返回一个指向该块的指针。但是,返回的指针并不指向块的起始位置,因为那里存储着内部大小数据!相反,我们将返回块的起始位置+8 字节。在实现中,记住指针算术取决于类型。例如,p += 8添加的是8 * sizeof(p),而不一定是 8 字节!
实现 malloc
最简单的实现使用首次适配:从第一个块开始,假设存在,迭代直到找到表示足够大小的未分配空间的块,或者我们已经检查了所有的块。
如果找不到合适的块,现在是调用 sbrk()的时候了,以充分扩展堆的大小。一个快速的实现可能会显著地扩展它,这样我们在不久的将来就不需要再请求更多的堆内存。
当找到一个空闲块时,它可能比我们需要的空间大。如果是这样,我们将在我们的隐式列表中创建两个条目。第一个条目是已分配的块,第二个条目是剩余的空间。
有两种简单的方法可以确定块是否正在使用或可用。第一种是将其存储为头信息中的一个字节,以及大小的最低位编码为 1!因此,块大小信息将仅限于偶数值:
// Assumes p is a reasonable pointer type, e.g. 'size_t *'.
isallocated = (*p) & 1;
realsize = (*p) & ~1; // mask out the lowest bit
对齐和向上取整的考虑
许多体系结构希望多字节原语对齐到 2^n 的某个倍数。例如,通常要求 4 字节类型对齐到 4 字节边界(64 位系统上的 8 字节类型对齐到 8 字节边界)。如果多字节原语未存储在合理的边界上(例如从奇数地址开始),则性能可能会受到显着影响,因为可能需要两个内存读取请求而不是一个。在某些体系结构上,惩罚甚至更大-程序将因总线错误而崩溃。
由于malloc不知道用户将如何使用分配的内存(双精度数组?字符数组?),因此返回给程序的指针需要对最坏情况进行对齐,这取决于体系结构。
根据 glibc 文档,glibc malloc使用以下启发式方法:“malloc 给您的块保证对齐,以便它可以容纳任何类型的数据。在 GNU 系统上,大多数系统的地址始终是 8 的倍数,在 64 位系统上是 16 的倍数。”
例如,如果您需要计算需要多少个 16 字节单位,请不要忘记四舍五入-
int s = (requested_bytes + tag_overhead_bytes + 15) / 16
附加的常数确保不完整的单元被四舍五入。请注意,实际代码更有可能使用符号大小,例如sizeof(x) - 1,而不是编码数值常数 15。
关于内部碎片的说明
内部碎片发生在您提供的块大于其分配大小时。假设我们有一个大小为 16B 的空闲块(不包括元数据)。如果它们分配了 7 个字节,您可能希望将其四舍五入为 16B 并返回整个块。
当您实现合并和分割时(下一节),情况会变得非常阴险。如果您两者都不实现,那么您可能会为 7B 的分配返回一个大小为 64B 的块!这种分配会产生大量的开销,而我们正试图避免这种情况。
实施释放
当调用free时,我们需要重新应用偏移量以返回到块的“真实”起始位置(记住我们没有给用户指向块实际起始位置的指针?),即我们存储大小信息的位置。
一个天真的实现只会将块标记为未使用。如果我们将块分配状态存储在最低大小位中,那么我们只需要清除该位:
*p = (*p) & ~1; // Clear lowest bit
然而,我们还有更多的工作要做:如果当前块和下一个块(如果存在)都是空闲的,我们需要将这些块合并成一个单一的块。同样,我们也需要检查前一个块。如果存在并表示未分配的内存,那么我们需要将这些块合并成一个单一的大块。
为了能够将一个空闲块与前一个空闲块合并,我们还需要找到前一个块,因此我们也将块的大小存储在块的末尾。这些被称为“边界标记”(参考 Knuth73)。由于块是连续的,一个块的末尾就紧邻着下一个块的开始。因此,当前块(除了第一个块)可以向后查找几个字节以查找前一个块的大小。有了这些信息,您现在可以向后跳转了!
性能
有了上述描述,就可以构建一个内存分配器。它的主要优势是简单性 - 至少与其他分配器相比是简单的!分配内存是最坏情况下的线性时间操作(搜索链表以找到足够大的空闲块),而释放是常数时间(最多只需要将 3 个块合并成一个块)。使用这个分配器,可以尝试不同的放置策略。例如,可以从上次释放块的位置开始搜索,或者从上次分配的位置开始搜索。如果您存储块的指针,您需要非常小心,确保它们始终保持有效(例如,在合并块或其他更改堆结构的 malloc 或 free 调用时)。
显式空闲列表分配器
通过实现一个显式的双向链表可以实现更好的性能。在这种情况下,我们可以立即遍历到下一个空闲块和上一个空闲块。这可以减半搜索时间,因为链表只包括未分配的块。
第二个优势是我们现在对链表的排序有一定的控制。例如,当一个块被释放时,我们可以选择将其插入到链表的开头,而不总是在其邻居之间。这将在下面讨论。
我们在哪里存储链表的指针?一个简单的技巧是意识到块本身没有被使用,并将下一个和上一个指针存储为块的一部分(尽管现在你必须确保空闲块始终足够大,以容纳两个指针)。
我们仍然需要实现边界标签(即使用大小的隐式列表),以便我们可以正确地释放块并将它们与它们的两个邻居合并。因此,显式空闲列表需要更多的代码和复杂性。
使用显式链表,使用快速简单的“查找第一个”算法来查找第一个足够大的链接。然而,由于链接顺序可以被修改,这对应于不同的放置策略。例如,如果链接从大到小维护,那么这将产生“最坏适合”放置策略。
显式链表插入策略
新释放的块可以轻松地插入到两个可能的位置:在开头或按地址顺序(通过使用边界标签首先找到邻居)。
在开头插入会创建一个 LIFO(后进先出)策略:最近释放的空间将被重复使用。研究表明,碎片化比使用地址顺序更严重。
按地址顺序插入(“按地址顺序策略”)插入释放的块,以便以递增的地址顺序访问块。这种策略需要更多的时间来释放块,因为必须使用边界标签(大小数据)来找到下一个和上一个未分配的块。然而,碎片化较少。
案例研究:Buddy Allocator(分离列表的一个示例)
分离的分配器是将堆分成由不同子分配器处理的不同区域的分配器,这取决于分配请求的大小。大小被分组为类(例如,2 的幂),每个大小由不同的子分配器处理,每个大小维护其自己的空闲列表。
这种类型的一个众所周知的分配器是伙伴分配器。我们将讨论二进制伙伴分配器,它将分配分成 2^n(n = 1, 2, 3,…)倍一些基本单位字节数的块,但也存在其他类型(例如,斐波那契分割 - 你能看出为什么它被命名了吗?)。基本概念很简单:如果没有大小为 2^n 的空闲块,就转到下一个级别并窃取该块并将其分成两个。如果两个相邻的相同大小的块变为未分配状态,则它们可以合并成一个两倍大小的单个大块。
伙伴分配器之所以快速,是因为可以从释放的块的地址计算出要合并的相邻块,而不是遍历大小标签。最终的性能通常需要少量的汇编代码来使用专门的 CPU 指令来找到最低的非零位。
伙伴分配器的主要缺点是它们受到内部碎片的影响,因为分配被舍入到最近的块大小。例如,68 字节的分配将需要一个 128 字节的块。
进一步阅读和参考资料
-
参见软件技术和理论计算机科学基础 1999 年会议论文集(Google 图书,第 85 页)
其他分配器
有许多其他分配方案。例如SLUB(维基百科)- Linux 内核内部使用的三种分配器之一。
内存,第三部分:破坏堆栈示例
每个线程使用堆栈内存。堆栈“向下增长” - 如果一个函数调用另一个函数,那么堆栈会扩展到更小的内存地址。堆栈内存包括非静态自动(临时)变量,参数值和返回地址。如果缓冲区太小,一些数据(例如来自用户的输入值),那么其他堆栈变量甚至返回地址可能会被覆盖。堆栈内容的精确布局和自动变量的顺序取决于体系结构和编译器。然而,通过一些调查工作,我们可以学会如何故意破坏特定体系结构的堆栈。
下面的示例演示了返回地址存储在堆栈上的方式。对于特定的 32 位体系结构Live Linux Machine,我们确定返回地址存储在自动变量地址的两个指针(8 字节)以上的地址。代码故意改变堆栈值,以便当输入函数返回时,不是继续在主方法内部进行,而是跳转到利用函数。
// Overwrites the return address on the following machine:
// http://cs-education.github.io/sys/
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void breakout() {
puts("Welcome. Have a shell...");
system("/bin/sh");
}
void input() {
void *p;
printf("Address of stack variable: %p\n", &p);
printf("Something that looks like a return address on stack: %p\n", *((&p)+2));
// Let's change it to point to the start of our sneaky function.
*((&p)+2) = breakout;
}
int main() {
printf("main() code starts at %p\n",main);
input();
while (1) {
puts("Hello");
sleep(1);
}
return 0;
}
计算机通常有很多种方法来解决这个问题。
内存复习问题
主题
-
最佳适配
-
最差适配
-
首次适配
-
伙伴分配器
-
内部碎片
-
外部碎片
-
sbrk
-
自然对齐
-
边界标签
-
合并
-
分割
-
Slab 分配/内存池
问题/练习
-
什么是内部碎片?它何时成为一个问题?
-
什么是外部碎片?它何时成为一个问题?
-
什么是最佳适配策略?它与外部碎片有什么关系?时间复杂度是多少?
-
什么是最差适配策略?它在外部碎片方面有所改善吗?时间复杂度是多少?
-
什么是首次适配放置策略?它在碎片方面稍微好一点,对吧?预期时间复杂度是多少?
-
假设我们正在使用一个新的 64kb 大小的伙伴分配器。它如何分配 1.5kb?
-
当 5 行
sbrk实现 malloc 时有什么用处? -
自然对齐是什么?
-
什么是合并/分割?它们如何增加/减少碎片?何时可以合并或分割?
-
边界标签是如何工作的?它们如何用于合并或分割?
四、Pthreads 简介
Pthreads,第一部分:介绍
线程简介
什么是线程?
线程是“执行线程”的缩写。它表示 CPU 已经(并将)执行的指令序列。为了记住如何从函数调用返回,并存储自动变量和参数的值,线程使用堆栈。
轻量级进程(LWP)是什么?它与线程有什么关系?
对于所有目的和意图来说,线程就是一个进程(意味着创建线程类似于fork),只是没有复制,意味着没有写时复制。这允许进程共享相同的地址空间、变量、堆、文件描述符等。
创建线程的实际系统调用类似于fork;它是clone。我们不会深入讨论,但您可以阅读man pages,请记住这超出了本课程的直接范围。
在许多情况下,LWP 或线程比 forking 更受欢迎,因为创建它们的开销要少得多。但在某些情况下(特别是 Python 使用这种方式),多进程是使代码更快的方法。
线程的堆栈是如何工作的?
您的主函数(以及您可能调用的其他函数)具有自动变量。我们将使用堆栈将它们存储在内存中,并使用简单指针(“堆栈指针”)跟踪堆栈的大小。如果线程调用另一个函数,我们将将堆栈指针向下移动,以便我们有更多的空间用于参数和自动变量。一旦从函数返回,我们可以将堆栈指针移回到其先前的值。我们在堆栈上保留旧的堆栈指针值的副本!这就是为什么从函数返回非常快速的原因-释放自动变量使用的内存很容易-我们只需要更改堆栈指针。

在多线程程序中,有多个堆栈,但只有一个地址空间。pthread 库分配一些堆栈空间(可以在堆中分配,也可以使用主程序的堆栈的一部分),并使用clone函数调用在该堆栈地址启动线程。总地址空间可能看起来像这样。

我的进程可以有多少个线程?
您可以在一个进程内运行多个线程。您可以免费获得第一个线程!它运行您在“main”内编写的代码。如果您需要更多线程,可以使用 pthread 库调用pthread_create创建一个新线程。您需要传递一个指向函数的指针,以便线程知道从哪里开始。
您创建的所有线程都存在于相同的虚拟内存中,因为它们是同一进程的一部分。因此,它们都可以看到堆、全局变量和程序代码等。因此,您可以让两个(或更多)CPU 同时在同一进程中运行您的程序。由操作系统来分配线程给 CPU。如果活动线程多于 CPU,则内核将为线程分配一个 CPU 进行短暂的持续时间(或直到它没有要做的事情),然后将自动切换 CPU 以处理另一个线程。例如,一个 CPU 可能正在处理游戏 AI,而另一个线程正在计算图形输出。
简单用法
Hello world pthread 示例
要使用 pthread,您需要包括pthread.h,并且需要使用-pthread(或-lpthread)编译器选项进行编译。此选项告诉编译器您的程序需要线程支持
要创建线程,请使用函数pthread_create。此函数有四个参数:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
-
第一个是指向将保存新创建的线程的 ID 的变量的指针。
-
第二个是指向属性的指针,我们可以使用它来调整和调优一些 pthread 的高级特性。
-
第三个是指向我们想要运行的函数的指针
-
第四个是将赋予我们的函数的指针
void *(*start_routine) (void *) 这个参数很难理解!它表示一个接受 void * 指针并返回 void * 指针的指针。它看起来像一个函数声明,只是函数的名称被 (* .... ) 包裹起来。
以下是最简单的例子:
#include <stdio.h>
#include <pthread.h>
// remember to set compilation option -pthread
void *busy(void *ptr) {
// ptr will point to "Hi"
puts("Hello World");
return NULL;
}
int main() {
pthread_t id;
pthread_create(&id, NULL, busy, "Hi");
while (1) {} // Loop forever
}
如果我们想要等待线程完成,可以使用 pthread_join。
void *result;
pthread_join(id, &result);
在上面的例子中,result 将会是 null,因为忙碌的函数返回了 null。我们需要传递结果的地址,因为 pthread_join 将会写入指针的内容。
Pthreads,第二部分:实际应用
更多的 pthread 函数
如何创建一个 pthread?
参见Pthreads Part 1,介绍了 pthread_create 和 pthread_join
如果我调用 pthread_create 两次,我的进程会有多少个堆栈?
你的进程将包含三个堆栈 - 每个线程一个。第一个线程在进程启动时创建,然后你创建了另外两个。实际上可能会有更多的堆栈,但现在让我们忽略这个复杂性。重要的想法是每个线程都需要一个堆栈,因为堆栈包含自动变量和旧的 CPU PC 寄存器,以便在函数完成后可以返回执行调用函数。
一个完整进程和一个线程之间的区别是什么?
此外,与进程不同,同一进程中的线程可以共享相同的全局内存(数据和堆段)。
pthread_cancel 是做什么的?
停止一个线程。请注意,线程可能不会立即停止。例如,当线程进行操作系统调用(例如 write)时,它可以被终止。
在实践中,pthread_cancel 很少被使用,因为它不给线程一个机会在自身之后进行清理(例如,它可能已经打开了一些文件)。另一种实现方法是使用一个布尔(int)变量,其值用于通知其他线程它们应该完成并进行清理。
exit 和 pthread_exit 之间有什么区别?
exit(42) 退出整个进程并设置进程的退出值。这相当于在主方法中返回 42。进程内的所有线程都会停止。
pthread_exit(void *) 只会停止调用线程,即调用 pthread_exit 后线程永远不会返回。如果没有其他线程在运行,pthread 库将自动完成进程。pthread_exit(...) 等同于从线程函数返回;两者都会完成线程,并为线程设置返回值(void *指针)。
在 main 线程中调用 pthread_exit 是简单程序确保所有线程完成的常见方法。例如,在下面的程序中,myfunc 线程可能没有时间开始。
int main() {
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, myfunc, "Jabberwocky");
pthread_create(&tid2, NULL, myfunc, "Vorpel");
exit(42); //or return 42;
// No code is run after exit
}
接下来的两个程序将等待新线程完成-
int main() {
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, myfunc, "Jabberwocky");
pthread_create(&tid2, NULL, myfunc, "Vorpel");
pthread_exit(NULL);
// No code is run after pthread_exit
// However process will continue to exist until both threads have finished
}
或者,我们可以在每个线程上进行连接(即等待它完成),然后从主函数返回(或调用 exit)。
int main() {
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, myfunc, "Jabberwocky");
pthread_create(&tid2, NULL, myfunc, "Vorpel");
// wait for both threads to finish :
void* result;
pthread_join(tid1, &result);
pthread_join(tid2, &result);
return 42;
}
请注意,pthread_exit 版本会创建线程僵尸,但这不是长时间运行的进程,所以我们不在乎。
线程如何被终止?
-
从线程函数返回
-
调用
pthread_exit -
使用
pthread_cancel取消线程 -
终止进程(例如 SIGTERM);exit();从
main返回
pthread_join 的目的是什么?
-
等待线程完成
-
清理线程资源
-
获取线程的返回值
如果不调用 pthread_join 会发生什么?
已完成的线程将继续消耗资源。最终,如果创建了足够多的线程,pthread_create 将失败。在实践中,这只是长时间运行进程的问题,但对于简单的短暂进程来说并不是问题,因为当进程退出时,所有线程资源都会被自动释放。
我应该使用 pthread_exit 还是 pthread_join?
pthread_exit 和 pthread_join 都会让其他线程自行完成(即使在主线程中调用)。但是,只有 pthread_join 会在指定线程完成时返回。pthread_exit 不会等待,它会立即结束线程,并且不会给你继续执行的机会。
你能把指针从一个线程传递给另一个线程的堆栈变量吗?
是的。但是你需要非常小心关于堆栈变量的生命周期。
pthread_t start_threads() {
int start = 42;
pthread_t tid;
pthread_create(&tid, 0, myfunc, &start); // ERROR!
return tid;
}
上面的代码是无效的,因为函数start_threads很可能会在myfunc开始之前返回。该函数传递了start的地址,但是当myfunc执行时,start已经不在作用域内,其地址将被重新用于另一个变量。
以下代码是有效的,因为栈变量的生命周期比后台线程长。
void start_threads() {
int start = 42;
void *result;
pthread_t tid;
pthread_create(&tid, 0, myfunc, &start); // OK - start will be valid!
pthread_join(tid, &result);
}
竞争条件简介
我怎样才能创建十个具有不同起始值的线程。
以下代码应该启动十个值为 0,1,2,3,…9 的线程,但运行时打印出1 7 8 8 8 8 8 8 8 10!你能看出为什么吗?
#include <pthread.h>
void* myfunc(void* ptr) {
int i = *((int *) ptr);
printf("%d ", i);
return NULL;
}
int main() {
// Each thread gets a different value of i to process
int i;
pthread_t tid;
for(i =0; i < 10; i++) {
pthread_create(&tid, NULL, myfunc, &i); // ERROR
}
pthread_exit(NULL);
}
上面的代码存在“竞争条件” - i 的值正在改变。新线程稍后启动(在示例输出中,最后一个线程在循环结束后启动)。
为了克服这种竞争条件,我们将为每个线程提供一个指向其自己数据区域的指针。例如,对于每个线程,我们可能希望存储 id、起始值和输出值:
struct T {
pthread_t id;
int start;
char result[100];
};
这些可以存储在数组中 -
struct T *info = calloc(10 , sizeof(struct T)); // reserve enough bytes for ten T structures
并且每个数组元素都传递给每个线程 -
pthread_create(&info[i].id, NULL, func, &info[i]);
为什么有些函数(例如 asctime、getenv、strtok、strerror)不是线程安全的?
为了回答这个问题,让我们看一个简单的函数,它也不是“线程安全”的
char *to_message(int num) {
char static result [256];
if (num < 10) sprintf(result, "%d : blah blah" , num);
else strcpy(result, "Unknown");
return result;
}
在上面的代码中,结果缓冲区存储在全局内存中。这很好 - 我们不希望返回指向栈上无效地址的指针,但整个内存中只有一个结果缓冲区。如果两个线程同时使用它,那么一个线程将破坏另一个:
| 时间 | 线程 1 | 线程 2 | 注释 |
|---|---|---|---|
| 1 | to_m(5) | ||
| 2 | to_m(99) | 现在两个线程都会看到结果缓冲区中存储的是“未知” |
什么是条件变量、信号量、互斥锁?
这些是同步锁,用于防止竞争条件,并确保同一程序中运行的线程之间的正确同步。此外,这些锁在概念上与内核内部使用的原语相同。
使用线程而不是分叉进程有什么优势吗?
是的!在线程之间共享信息很容易,因为线程(同一进程的线程)存在于相同的虚拟内存空间中。此外,创建线程比创建(分叉)进程要快得多。
使用线程而不是分叉进程有什么缺点吗?
是的!没有隔离!因为线程存在于同一个进程中,一个线程可以访问与其他线程相同的虚拟内存。一个线程可以终止整个进程(例如,尝试读取地址零)。
您可以使用多个线程分叉一个进程吗?
是的!但是子进程只有一个线程(这是调用fork的线程的克隆)。我们可以将其视为一个简单的例子,后台线程在子进程中从不打印出第二条消息。
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
static pid_t child = -2;
void *sleepnprint(void *arg) {
printf("%d:%s starting up...\n", getpid(), (char *) arg);
while (child == -2) {sleep(1);} /* Later we will use condition variables */
printf("%d:%s finishing...\n",getpid(), (char*)arg);
return NULL;
}
int main() {
pthread_t tid1, tid2;
pthread_create(&tid1,NULL, sleepnprint, "New Thread One");
pthread_create(&tid2,NULL, sleepnprint, "New Thread Two");
child = fork();
printf("%d:%s\n",getpid(), "fork()ing complete");
sleep(3);
printf("%d:%s\n",getpid(), "Main thread finished");
pthread_exit(NULL);
return 0; /* Never executes */
}
8970:New Thread One starting up...
8970:fork()ing complete
8973:fork()ing complete
8970:New Thread Two starting up...
8970:New Thread Two finishing...
8970:New Thread One finishing...
8970:Main thread finished
8973:Main thread finished
实际上,在分叉之前创建线程可能会导致意外错误,因为(如上所示)其他线程在分叉时立即终止。另一个线程可能刚刚锁定了互斥锁(例如通过调用 malloc),并且再也不会解锁。高级用户可能会发现pthread_atfork有用,但我们建议您通常尽量避免在分叉之前创建线程,除非您完全了解这种方法的限制和困难。
还有其他情况下fork可能比创建线程更可取吗。
创建单独的进程很有用
-
当需要更多安全性时(例如,Chrome 浏览器为不同的标签使用不同的进程)
-
在运行现有和完整的程序时,需要一个新进程(例如,启动’gcc’)
-
当您遇到同步原语并且每个进程都在系统中操作某些东西时
我怎样才能找到更多信息?
在man 页面中查看完整示例,并在pthread 参考指南中查看。另外:简明的第三方示例代码,解释创建、连接和退出
Pthreads,第三部分:并行问题(奖励)
概述
下一节将讨论当 pthread 发生冲突时会发生什么,但如果每个线程做的事情完全不同,没有重叠呢?
我们找到了最大加速并行问题吗?
尴尬的并行问题
并行算法的研究在过去几年里迅速发展。一个尴尬的并行问题是指需要很少的工作就可以转换为并行的问题。其中很多问题都涉及一些同步概念,但并非总是如此。你已经知道一个可并行化的算法,归并排序!
void merge_sort(int *arr, size_t len){
if(len > 1){
//Mergesort the left half
//Mergesort the right half
//Merge the two halves
}
有了对线程的新理解,你只需要为左半部分创建一个线程,为右半部分创建一个线程。鉴于你的 CPU 有多个真实核心,你将看到与Amdahl’s Law相符的加速。时间复杂度分析在这里也变得有趣。并行算法的运行时间为 O(log^3(n))(因为我们假设有很多核心)。
然而在实践中,我们通常会做两个改变。一是,一旦数组变得足够小,我们就会放弃并行归并排序算法,转而使用快速排序或其他在小数组上运行快速的算法(某种缓存一致性)。另一件我们知道的事情是,CPU 并不拥有无限的核心。为了解决这个问题,我们通常会保留一个工作池。
工作池
我们知道 CPU 的核心数量是有限的。很多时候我们会启动一些线程,并在它们空闲时给它们任务。
另一个问题,Parallel Map
假设我们想要对整个数组应用一个函数,一次处理一个元素。
int *map(int (*func)(int), int *arr, size_t len){
int *ret = malloc(len*sizeof(*arr));
for(size_t i = 0; i < len; ++i)
ret[i] = func(arr[i]);
return ret;
}
由于没有任何元素依赖于其他元素,你会如何并行化这个问题?你认为在线程之间如何分配工作最好?
调度
有几种方法可以分解工作。
-
静态调度:将问题分解成固定大小的块(预先确定的),并让每个线程处理其中的每个块。当每个子问题花费的时间大致相同时,这种方法效果很好,因为没有额外的开销。你只需要编写一个循环,并将 map 函数分配给每个子数组。
-
动态调度:当一个新问题可用时,让一个线程处理它。当你不知道调度需要多长时间时,这是很有用的。
-
引导调度:这是上述两种方法的混合,具有各自的优点和权衡。你可以从静态调度开始,如果需要的话慢慢转向动态调度。
-
运行时调度:你完全不知道问题需要多长时间。与其自己决定,不如让程序决定该做什么!
来源,但不需要记住。
一些缺点
你不会立即看到加速,因为缓存一致性和调度额外的线程等原因。
其他问题
-
在 Web 服务器上为多个用户提供静态文件。
-
曼德勃罗集、Perlin 噪声和类似的图像,其中每个点都是独立计算的。
-
计算机图形的渲染。在计算机动画中,每一帧可能是独立渲染的(参见并行渲染)。
-
在密码学中的暴力搜索。值得注意的现实世界例子包括 distributed.net 和加密货币中使用的工作证明系统。
-
生物信息学中用于多个查询的 BLAST 搜索(但不适用于单个大查询)[9]
-
大规模人脸识别系统将数千个任意获取的人脸(例如,通过闭路电视的安全或监控视频)与同样大量的先前存储的人脸(例如,罪犯库或类似的观察名单)进行比较。
-
比较许多独立场景的计算机模拟,例如气候模型。
-
进化计算元启发式,如遗传算法。
-
数值天气预报的集合计算。
-
粒子物理中的事件模拟和重建。
-
Marching squares 算法
-
二次筛和数域筛的筛选步骤。
-
随机森林机器学习技术中的树生长步骤。
-
离散傅立叶变换,其中每个谐波都是独立计算的。
Pthread 复习问题
主题
-
pthread 生命周期
-
每个线程都有一个堆栈
-
从线程中捕获返回值
-
使用
pthread_join -
使用
pthread_create -
使用
pthread_exit -
在什么条件下进程会退出
问题
-
当创建一个 pthread 时会发生什么?(你不需要进入超级细节)
-
每个线程的堆栈在哪里?
-
如何在给定
pthread_t的情况下获得返回值?线程可以如何设置返回值?如果丢弃返回值会发生什么? -
为什么
pthread_join很重要(考虑堆栈空间、寄存器、返回值)? -
在正常情况下
pthread_exit做什么(即你不是最后一个线程)?调用 pthread_exit 时会调用哪些其他函数? -
给我三个多线程进程将退出的条件。你还能想到其他条件吗?
-
什么是尴尬并行问题?
五、同步
同步,第一部分:互斥锁
解决临界区
什么是临界区?
临界区是一段代码,只能由一个线程同时执行,如果程序要正确运行。如果两个线程(或进程)同时在临界区内执行代码,那么可能程序可能不再具有正确的行为。
仅仅递增一个变量是否是临界区?
可能。递增变量(i++)是通过三个单独的步骤执行的:将内存内容复制到 CPU 寄存器。增加 CPU 中的值。将新值存储在内存中。如果内存位置只能由一个线程访问(例如下面的自动变量i),则不可能发生竞争条件,也没有与i相关的临界区。但是,sum变量是全局变量,并且被两个线程访问。可能两个线程可能同时尝试递增变量。
#include <stdio.h>
#include <pthread.h>
// Compile with -pthread
int sum = 0; //shared
void *countgold(void *param) {
int i; //local to each thread
for (i = 0; i < 10000000; i++) {
sum += 1;
}
return NULL;
}
int main() {
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, countgold, NULL);
pthread_create(&tid2, NULL, countgold, NULL);
//Wait for both threads to finish:
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("ARRRRG sum is %d\n", sum);
return 0;
}
上述代码的典型输出是ARGGGH sum is 8140268每次运行程序时都会打印不同的总和,因为存在竞争条件;代码无法阻止两个线程同时读写sum。例如,两个线程都将当前的 sum 值复制到运行每个线程的 CPU 中(假设为 123)。两个线程都将其自己的副本增加一。两个线程写回该值(124)。如果线程在不同时间访问了 sum,则计数将为 125。
如何确保一次只有一个线程可以访问全局变量?
你的意思是,“帮助 - 我需要一个互斥体!”如果一个线程当前正在临界区内,我们希望另一个线程等到第一个线程完成。为此,我们可以使用互斥体(Mutual Exclusion 的缩写)。
对于简单的示例,我们需要添加的代码最少只有三行:
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER; // global variable
pthread_mutex_lock(&m); // start of Critical Section
pthread_mutex_unlock(&m); //end of Critical Section
一旦我们完成了互斥体,我们还应该调用pthread_mutex_destroy(&m)。请注意,您只能销毁未锁定的互斥体。对已销毁的锁调用 destroy,初始化已初始化的锁,锁定已锁定的锁,解锁未锁定的锁等都是不受支持的(至少对于默认的互斥体),通常会导致未定义的行为。
如果我锁定了互斥体,是否会阻止所有其他线程?
不,其他线程将继续。只有当一个线程尝试锁定已经锁定的互斥体时,线程才必须等待。一旦原始线程解锁互斥体,第二个(等待的)线程将获取锁并能够继续。
还有其他创建互斥体的方法吗?
可以。您可以仅对全局(“静态”)变量使用宏 PTHREAD_MUTEX_INITIALIZER。m = PTHREAD_MUTEX_INITIALIZER 等同于更通用的pthread_mutex_init(&m,NULL)。init 版本包括用于在性能和额外错误检查以及高级共享选项之间进行权衡的选项。
pthread_mutex_t *lock = malloc(sizeof(pthread_mutex_t));
pthread_mutex_init(lock, NULL);
//later
pthread_mutex_destroy(lock);
free(lock);
关于“init”和“destroy”需要记住的事情:
-
多个线程的初始化/销毁具有未定义的行为
-
销毁锁定的互斥体具有未定义的行为
-
基本上尝试遵循一个线程初始化一个互斥体,而且只有一个线程初始化一个互斥体的模式。
互斥体陷阱
所以 pthread_mutex_lock在其他线程读取相同变量时会停止吗?
不,互斥体不是那么聪明 - 它与代码(线程)一起工作,而不是数据。只有当另一个线程在锁定的互斥体上调用lock时,第二个线程才需要等待,直到互斥体被解锁。
考虑
int a;
pthread_mutex_t m1 = PTHREAD_MUTEX_INITIALIZER,
m2 = = PTHREAD_MUTEX_INITIALIZER;
// later
// Thread 1
pthread_mutex_lock(&m1);
a++;
pthread_mutex_unlock(&m1);
// Thread 2
pthread_mutex_lock(&m2);
a++;
pthread_mutex_unlock(&m2);
仍会导致竞争条件。
我可以在 fork 之前创建互斥体吗?
是的 - 但是子进程和父进程将不共享虚拟内存,并且每个进程都将拥有独立于其他进程的互斥体。
(高级说明:使用共享内存有高级选项,允许子进程和父进程共享互斥体,如果使用正确的选项并使用共享内存段。请参阅stackoverflow 示例)
如果一个线程锁定了一个互斥锁,另一个线程能解锁它吗?
不行。同一个线程必须解锁它。
我可以使用两个或更多的互斥锁吗?
是的!事实上,通常每个需要更新的数据结构都有一个锁。
如果你只有一个锁,那么两个线程之间可能会对锁有显著的争用,这是不必要的。例如,如果两个线程正在更新两个不同的计数器,可能不需要使用相同的锁。
然而,简单地创建许多锁是不够的:重要的是能够推理关于临界区的问题,例如,一个线程不能在更新期间读取两个数据结构,而这两个数据结构暂时处于不一致的状态。
调用 lock 和 unlock 会有任何开销吗?
调用pthread_mutex_lock和_unlock会有一些开销;然而这是你为了程序正确运行所付出的代价!
最简单的完整示例?
下面显示了一个完整的示例
#include <stdio.h>
#include <pthread.h>
// Compile with -pthread
// Create a mutex this ready to be locked!
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
int sum = 0;
void *countgold(void *param) {
int i;
//Same thread that locks the mutex must unlock it
//Critical section is just 'sum += 1'
//However locking and unlocking a million times
//has significant overhead in this simple answer
pthread_mutex_lock(&m);
// Other threads that call lock will have to wait until we call unlock
for (i = 0; i < 10000000; i++) {
sum += 1;
}
pthread_mutex_unlock(&m);
return NULL;
}
int main() {
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, countgold, NULL);
pthread_create(&tid2, NULL, countgold, NULL);
//Wait for both threads to finish:
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("ARRRRG sum is %d\n", sum);
return 0;
}
在上面的代码中,线程在进入计数室之前获取了锁。关键部分只有sum+=1,所以下一个版本也是正确的但更慢 -
for (i = 0; i < 10000000; i++) {
pthread_mutex_lock(&m);
sum += 1;
pthread_mutex_unlock(&m);
}
return NULL;
}
这个过程运行得更慢,因为我们一百万次锁定和解锁互斥锁,这是昂贵的 - 至少与递增一个变量相比是昂贵的。(在这个简单的例子中,我们并不真正需要线程 - 我们可以加两次!)一个更快的多线程示例是使用一个自动(本地)变量添加一百万,然后在计算循环结束后将其添加到共享总数中:
int local = 0;
for (i = 0; i < 10000000; i++) {
local += 1;
}
pthread_mutex_lock(&m);
sum += local;
pthread_mutex_unlock(&m);
return NULL;
}
如果我忘记解锁会发生什么?
死锁!我们稍后会谈论死锁,但如果多个线程调用这个循环会有什么问题。
while(not_stop){
//stdin may not be thread safe
pthread_mutex_lock(&m);
char *line = getline(...);
if(rand() % 2) { /* randomly skip lines */
continue;
}
pthread_mutex_unlock(&m);
process_line(line);
}
我什么时候可以销毁互斥锁?
你只能销毁一个未锁定的互斥锁
我可以将 pthread_mutex_t 复制到新的内存位置吗?
不行,将互斥锁的字节复制到新的内存位置,然后使用副本是不支持的。
互斥锁的简单实现会是什么样的?
下面显示了一个简单(但不正确!)的建议。unlock函数只是解锁互斥锁并返回。lock 函数首先检查锁是否已经被锁定。如果当前已经被锁定,它将继续检查,直到另一个线程解锁互斥锁。
// Version 1 (Incorrect!)
void lock(mutex_t *m) {
while(m->locked) { /*Locked? Nevermind - just loop and check again!*/ }
m->locked = 1;
}
void unlock(mutex_t *m) {
m->locked = 0;
}
版本 1 使用了“忙等待”(不必要地浪费 CPU 资源),但更严重的问题是:我们有一个竞争条件!
如果两个线程同时调用lock,有可能两个线程都会将’m_locked’读取为零。因此,两个线程都会认为它们对锁有独占访问权,然后两个线程都会继续。哎呀!
我们可以尝试通过在循环内调用pthread_yield()来减少一点 CPU 开销 - pthread_yield 建议操作系统暂时不使用 CPU,因此 CPU 可能被分配给等待运行的线程。但这并不能解决竞争条件。我们需要一个更好的实现 - 你能想出如何防止竞争条件吗?
我怎样才能了解更多?
玩! 阅读 man page!
同步,第二部分:计数信号量
什么是计数信号量?
计数信号量包含一个值,并支持两个操作“等待”和“发布”。发布增加信号量并立即返回。“等待”将在计数为零时等待。如果计数不为零,则信号量将减少计数并立即返回。
一个类比是饼干罐中的饼干数量(或者宝箱中的金币数量)。在拿饼干之前,调用“等待”。如果没有剩下饼干,那么等待将不会返回:它将等待,直到另一个线程通过调用 post 增加信号量。
简而言之,“发布”增加并立即返回,而“等待”将在计数为零时等待。在返回之前,它将减少计数。
我如何创建一个信号量?
本页介绍了未命名信号量。不幸的是,Mac OS X 目前还不支持这些。
首先决定初始值是零还是其他值(例如数组中剩余空间的数量)。与 pthread 互斥锁不同,创建信号量没有捷径 - 使用sem_init
#include <semaphore.h>
sem_t s;
int main() {
sem_init(&s, 0, 10); // returns -1 (=FAILED) on OS X
sem_wait(&s); // Could do this 10 times without blocking
sem_post(&s); // Announce that we've finished (and one more resource item is available; increment count)
sem_destroy(&s); // release resources of the semaphore
}
我可以从不同的线程调用 wait 和 post 吗?
可以!与互斥锁不同,增量和减量可以来自不同的线程。
可以使用信号量代替互斥锁吗?
是的 - 虽然信号量的开销更大。要使用信号量:
-
用计数为一初始化信号量。
-
用
...lock替换sem_wait -
用
...unlock替换sem_post
互斥锁是一个在“发布”之前始终“等待”的信号量
sem_t s;
sem_init(&s, 0, 1);
sem_wait(&s);
// Critical Section
sem_post(&s);
我可以在信号处理程序中使用 sem_post 吗?
是的!sem_post是少数几个可以在信号处理程序中正确使用的函数之一。这意味着我们可以释放一个等待的线程,该线程现在可以进行所有我们不允许在信号处理程序本身内调用的调用(例如printf)。
#include <stdio.h>
#include <pthread.h>
#include <signal.h>
#include <semaphore.h>
#include <unistd.h>
sem_t s;
void handler(int signal)
{
sem_post(&s); /* Release the Kraken! */
}
void *singsong(void *param)
{
sem_wait(&s);
printf("I had to wait until your signal released me!\n");
}
int main()
{
int ok = sem_init(&s, 0, 0 /* Initial value of zero*/);
if (ok == -1) {
perror("Could not create unnamed semaphore");
return 1;
}
signal(SIGINT, handler); // Too simple! See note below
pthread_t tid;
pthread_create(&tid, NULL, singsong, NULL);
pthread_exit(NULL); /* Process will exit when there are no more threads */
}
请注意,健壮的程序不会在多线程程序中使用signal()(“在多线程进程中使用 signal()的效果是未指定的。”- 信号手册页);一个更正确的程序将需要使用sigaction。
我如何找到更多信息?
阅读手册页:
同步,第三部分:使用互斥锁和信号量
线程安全的堆栈
什么是原子操作?
用维基百科的话来说,
如果一个操作(或一组操作)在系统的其他部分看起来是瞬间发生的,那么它就是原子的或不可中断的。没有锁,只有简单的 CPU 指令(“从内存中读取这个字节”)是原子的(不可分割的)。在单 CPU 系统中,可以暂时禁用中断(这样一系列操作就不能被中断),但实际上原子性是通过使用同步原语来实现的,通常是互斥锁。
递增变量(i++)不是原子的,因为它需要三个不同的步骤:将位模式从内存复制到 CPU;使用 CPU 的寄存器进行计算;将位模式复制回内存。在这个递增序列期间,另一个线程或进程仍然可以读取旧值,并且当递增序列完成时,对同一内存的其他写入也会被覆盖。
我如何使用互斥锁使我的数据结构线程安全?
请注意,这只是一个介绍 - 编写高性能的线程安全数据结构需要自己的书!这是一个简单的数据结构(堆栈),它不是线程安全的:
// A simple fixed-sized stack (version 1)
#define STACK_SIZE 20
int count;
double values[STACK_SIZE];
void push(double v) {
values[count++] = v;
}
double pop() {
return values[--count];
}
int is_empty() {
return count == 0;
}
堆栈的版本 1 不是线程安全的,因为如果两个线程同时调用 push 或 pop,那么结果或堆栈可能是不一致的。例如,想象一下,如果两个线程同时调用 pop,那么两个线程可能读取相同的值,两个线程可能读取原始计数值。
要将其转换为线程安全的数据结构,我们需要确定我们代码的关键部分,即哪些部分的代码必须一次只有一个线程。在上面的例子中,push,pop和is_empty函数访问相同的变量(即内存),并且堆栈的所有关键部分。
当push(和pop)正在执行时,数据结构处于不一致状态(例如计数可能尚未写入,因此可能仍然包含原始值)。通过用互斥锁包装这些方法,我们可以确保一次只有一个线程可以更新(或读取)堆栈。
以下是一个候选的“解决方案”。它正确吗?如果不是,它将如何失败?
// An attempt at a thread-safe stack (version 2)
#define STACK_SIZE 20
int count;
double values[STACK_SIZE];
pthread_mutex_t m1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t m2 = PTHREAD_MUTEX_INITIALIZER;
void push(double v) {
pthread_mutex_lock(&m1);
values[count++] = v;
pthread_mutex_unlock(&m1);
}
double pop() {
pthread_mutex_lock(&m2);
double v = values[--count];
pthread_mutex_unlock(&m2);
return v;
}
int is_empty() {
pthread_mutex_lock(&m1);
return count == 0;
pthread_mutex_unlock(&m1);
}
上面的代码(“版本 2”)至少包含一个错误。花点时间看看你能不能找到错误,并弄清楚后果。
如果三个线程同时调用push(),锁m1确保只有一个线程在操作堆栈(两个线程将需要等待,直到第一个线程完成(调用解锁),然后第二个线程将被允许继续进入临界区,最后第三个线程将在第二个线程完成后被允许继续)。
类似的论点也适用于并发调用(同时调用)pop。然而,版本 2 不会阻止push和pop同时运行,因为push和pop使用两个不同的互斥锁。
在这种情况下,修复很简单 - 对 push 和 pop 函数都使用相同的互斥锁。
代码还有第二个错误;is_empty在比较后返回,不会解锁互斥锁。然而,错误不会立即被发现。例如,假设一个线程调用is_empty,稍后第二个线程调用push。这个线程会神秘地停止。使用调试器,你可以发现线程在push方法内的 lock()方法处被卡住,因为之前的is_empty调用没有解锁。因此,一个线程的疏忽导致了任意其他线程在以后的时间出现问题。
以下是更好的版本 -
// An attempt at a thread-safe stack (version 3)
int count;
double values[count];
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
void push(double v) {
pthread_mutex_lock(&m);
values[count++] = v;
pthread_mutex_unlock(&m);
}
double pop() {
pthread_mutex_lock(&m);
double v = values[--count];
pthread_mutex_unlock(&m);
return v;
}
int is_empty() {
pthread_mutex_lock(&m);
int result= count == 0;
pthread_mutex_unlock(&m);
return result;
}
版本 3 是线程安全的(我们已经确保了所有关键部分的互斥),但有两点需要注意:
-
is_empty是线程安全的,但它的结果可能已经过时,即在线程得到结果时,堆栈可能不再为空! -
没有保护免受下溢(在空堆栈上弹出)或上溢(在已满堆栈上推入)
后一点可以使用计数信号量来修复。
该实现假定为单个堆栈。更通用的版本可能会将互斥锁作为内存结构的一部分,并使用 pthread_mutex_init 来初始化互斥锁。例如,
// Support for multiple stacks (each one has a mutex)
typedef struct stack {
int count;
pthread_mutex_t m;
double *values;
} stack_t;
stack_t* stack_create(int capacity) {
stack_t *result = malloc(sizeof(stack_t));
result->count = 0;
result->values = malloc(sizeof(double) * capacity);
pthread_mutex_init(&result->m, NULL);
return result;
}
void stack_destroy(stack_t *s) {
free(s->values);
pthread_mutex_destroy(&s->m);
free(s);
}
// Warning no underflow or overflow checks!
void push(stack_t *s, double v) {
pthread_mutex_lock(&s->m);
s->values[(s->count)++] = v;
pthread_mutex_unlock(&s->m); }
double pop(stack_t *s) {
pthread_mutex_lock(&s->m);
double v = s->values[--(s->count)];
pthread_mutex_unlock(&s->m);
return v;
}
int is_empty(stack_t *s) {
pthread_mutex_lock(&s->m);
int result = s->count == 0;
pthread_mutex_unlock(&s->m);
return result;
}
示例用法:
int main() {
stack_t *s1 = stack_create(10 /* Max capacity*/);
stack_t *s2 = stack_create(10);
push(s1, 3.141);
push(s2, pop(s1));
stack_destroy(s2);
stack_destroy(s1);
}
堆栈信号量
如果堆栈为空或已满,我如何强制我的线程等待?
使用计数信号量!使用计数信号量来跟踪剩余空间的数量,另一个信号量来跟踪堆栈中项目的数量。我们将称这两个信号量为’sremain’和’sitems’。记住,sem_wait会在信号量的计数被另一个线程调用sem_post减少到零时等待。
// Sketch #1
sem_t sitems;
sem_t sremain;
void stack_init(){
sem_init(&sitems, 0, 0);
sem_init(&sremain, 0, 10);
}
double pop() {
// Wait until there's at least one item
sem_wait(&sitems);
...
void push(double v) {
// Wait until there's at least one space
sem_wait(&sremain);
...
草图#2 已经实现了太早的post。在 push 中等待的另一个线程可能会错误地尝试写入一个已满的堆栈(同样,等待 pop()的线程可能会过早地继续)。
// Sketch #2 (Error!)
double pop() {
// Wait until there's at least one item
sem_wait(&sitems);
sem_post(&sremain); // error! wakes up pushing() thread too early
return values[--count];
}
void push(double v) {
// Wait until there's at least one space
sem_wait(&sremain);
sem_post(&sitems); // error! wakes up a popping() thread too early
values[count++] = v;
}
草图 3 实现了正确的信号量逻辑,但你能发现错误吗?
// Sketch #3 (Error!)
double pop() {
// Wait until there's at least one item
sem_wait(&sitems);
double v= values[--count];
sem_post(&sremain);
return v;
}
void push(double v) {
// Wait until there's at least one space
sem_wait(&sremain);
values[count++] = v;
sem_post(&sitems);
}
草图 3 正确地使用信号量强制执行了缓冲区满和缓冲区空的条件。然而,没有互斥:两个线程可以同时处于临界区,这将破坏数据结构(或至少导致数据丢失)。修复方法是在临界区周围包装一个互斥锁:
// Simple single stack - see above example on how to convert this into a multiple stacks.
// Also a robust POSIX implementation would check for EINTR and error codes of sem_wait.
// PTHREAD_MUTEX_INITIALIZER for statics (use pthread_mutex_init() for stack/heap memory)
pthread_mutex_t m= PTHREAD_MUTEX_INITIALIZER;
int count = 0;
double values[10];
sem_t sitems, sremain;
void init() {
sem_init(&sitems, 0, 0);
sem_init(&sremains, 0, 10); // 10 spaces
}
double pop() {
// Wait until there's at least one item
sem_wait(&sitems);
pthread_mutex_lock(&m); // CRITICAL SECTION
double v= values[--count];
pthread_mutex_unlock(&m);
sem_post(&sremain); // Hey world, there's at least one space
return v;
}
void push(double v) {
// Wait until there's at least one space
sem_wait(&sremain);
pthread_mutex_lock(&m); // CRITICAL SECTION
values[count++] = v;
pthread_mutex_unlock(&m);
sem_post(&sitems); // Hey world, there's at least one item
}
// Note a robust solution will need to check sem_wait's result for EINTR (more about this later)
常见的互斥锁陷阱是什么?
-
由于愚蠢的拼写错误而锁定/解锁错误的互斥锁
-
未解锁互斥锁(由于在错误条件下提前返回)
-
资源泄漏(未调用
pthread_mutex_destroy) -
使用未初始化的互斥锁(或使用已被销毁的互斥锁)
-
在线程上两次锁定互斥锁(未首先解锁)
-
死锁和优先级反转(我们稍后会讨论这些)
同步,第四部分:关键部分问题
候选解决方案
什么是关键部分问题?
如已在Synchronization, Part 3: Working with Mutexes And Semaphores中讨论的,我们的代码中有一些关键部分只能由一个线程同时执行。我们将这种要求描述为“互斥排他”;只有一个线程(或进程)可以访问共享资源。
在多线程程序中,我们可以使用互斥锁和解锁调用来包装关键部分:
pthread_mutex_lock() - one thread allowed at a time! (others will have to wait here)
... Do Critical Section stuff here!
pthread_mutex_unlock() - let other waiting threads continue
我们如何实现这些锁定和解锁调用?我们能创建一个保证互斥的算法吗?下面显示了一个不正确的实现,
pthread_mutex_lock(p_mutex_t *m) { while(m->lock) {}; m->lock = 1;}
pthread_mutex_unlock(p_mutex_t *m) { m->lock = 0; }
乍一看,代码似乎是有效的;如果一个线程尝试锁定互斥量,稍后的线程必须等到锁被释放。然而,这种实现不能满足互斥。让我们从两个大致同时运行的线程的角度仔细观察这个“实现”。在下表中,时间从上到下依次进行-
| 时间 | 线程 1 | 线程 2 |
|---|---|---|
| 1 | while(lock) {} | |
| 2 | while(lock) {} | |
| 3 | lock = 1 | lock = 1 |
哎呀!存在竞争条件。不幸的是,两个线程都检查了锁并读取了一个错误的值,因此能够继续执行。
关键部分问题的候选解决方案。
为了简化讨论,我们只考虑两个线程。请注意,这些论点适用于线程和进程,经典的 CS 文献讨论了这些问题,涉及到需要对关键部分或共享资源进行独占访问(即互斥)的两个进程。
提高标志表示线程/进程进入关键部分的意图。
请记住,下面概述的伪代码是较大程序的一部分;线程或进程通常需要在进程的生命周期中多次进入关键部分。因此,想象每个示例都包裹在一个循环中,在循环中线程或进程在其他事务上工作了一段随机时间。
下面描述的候选解决方案有什么问题吗?
// Candidate #1
wait until your flag is lowered
raise my flag
// Do Critical Section stuff
lower my flag
答案:候选解决方案#1 也存在竞争条件,即它不能满足互斥排他,因为两个线程/进程都可以读取对方的标志值(=降低)并继续。
这表明我们应该在检查其他线程的标志之前提高标志 - 这是下面的候选解决方案#2。
// Candidate #2
raise my flag
wait until your flag is lowered
// Do Critical Section stuff
lower my flag
候选方案#2 满足互斥 - 不可能同时有两个线程在关键部分内。然而,这段代码存在死锁问题!假设两个线程希望同时进入关键部分:
| 时间 | 线程 1 | 线程 2 |
|---|---|---|
| 1 | raise my flag | |
| 2 | raise my flag |
| 3 | wait... | wait... |
哎呀,现在两个线程/进程都在等待对方降低他们的标志。现在两者都将永远无法进入关键部分!
这表明我们应该使用轮流变量来尝试解决谁应该继续的问题。
轮流解决方案
以下候选解决方案#3 使用轮流变量礼貌地允许一个线程,然后另一个线程继续
// Candidate #3
wait until my turn is myid
// Do Critical Section stuff
turn = yourid
候选方案#3 满足互斥(每个线程或进程都可以独占访问关键部分),但是两个线程/进程必须采取严格的轮流方式来使用关键部分;即它们被迫进入交替的关键部分访问模式。例如,如果线程 1 希望每毫秒读取一个哈希表,但另一个线程每秒写入一个哈希表,那么读取线程必须再等待 999 毫秒才能再次从哈希表中读取。这种“解决方案”是不有效的,因为我们的线程应该能够取得进展并在没有其他线程当前在关键部分时进入关键部分。
对关键部分问题的解决方案的期望属性?
在解决关键部分问题中,我们希望的有三个主要的理想属性
-
互斥 - 线程/进程获得独占访问权;其他线程/进程必须等待,直到它退出关键部分。
-
有界等待 - 如果线程/进程必须等待,那么它只能等待有限的时间(不允许无限等待时间!)。有界等待的确切定义是,在给定进程进入之前,任何其他进程可以进入其关键部分的次数有一个上限(非无限)。
-
进度 - 如果没有线程/进程在关键部分内,那么线程/进程应该能够继续进行(取得进展)而无需等待。
在考虑这些想法的基础上,让我们检查另一个候选解决方案,只有在两个线程同时需要访问时才使用基于轮换的标志。
轮换和标志解决方案
以下是 CSP 的正确解决方案吗?
\\ Candidate #4
raise my flag
if your flag is raised, wait until my turn
// Do Critical Section stuff
turn = yourid
lower my flag
一位教师和另一位 CS 教师最初也是这样认为的!然而,分析这些解决方案是棘手的。甚至关于这个特定主题的同行评审论文中也包含不正确的解决方案!乍一看,它似乎满足互斥、有界等待和进度:基于轮换的标志仅在出现平局时使用(因此允许进度和有界等待),并且似乎满足互斥。然而…也许你可以找到一个反例?
候选#4 失败,因为一个线程不会等到另一个线程降低他们的标志。经过一番思考(或灵感),可以创建以下场景来演示互斥不满足。
想象第一个线程运行这段代码两次(所以轮换标志现在指向第二个线程)。当第一个线程仍然在关键部分内时,第二个线程到达。第二个线程可以立即继续进入关键部分!
| 时间 | 轮换 | 线程#1 | 线程#2 |
|---|---|---|---|
| 1 | 2 | raise my flag | |
| 2 | 2 | if your flag is raised, wait until my turn | raise my flag |
| 3 | 2 | // Do Critical Section stuff | if your flag is raised, wait until my turn(真的!) |
| 4 | 2 | // Do Critical Section stuff | // Do Critical Section stuff - 糟糕 |
有效的解决方案
Peterson 的解决方案是什么?
Peterson 在 1981 年的一篇两页论文中发表了他的小说和令人惊讶的简单解决方案。下面显示了他算法的一个版本,使用了共享变量turn:
\\ Candidate #5
raise my flag
turn = your_id
wait until your flag is lowered and turn is yourid
// Do Critical Section stuff
lower my flag
该解决方案满足互斥、有界等待和进度。如果线程#2 将轮换设置为 2 并且当前在关键部分内。线程#1 到达,将轮换设置回 1,现在等待直到线程 2 降低标志。
Peterson 原始文章 pdf 的链接:G. L. Peterson: “关于互斥问题的神话”,信息处理通讯 12(3) 1981, 115–116
Peterson 的解决方案是第一个解决方案吗?
不,Dekkers 算法(1962 年)是第一个可以证明正确的解决方案。以下是该算法的一个版本。
raise my flag
while(your flag is raised) :
if it's your turn to win :
lower my flag
wait while your turn
raise my flag
// Do Critical Section stuff
set your turn to win
lower my flag
请注意,无论循环迭代零次、一次还是多次,进程的标志在关键部分始终被提升。此外,该标志可以被解释为立即意图进入关键部分。只有在另一个进程也提升了标志时,一个进程才会推迟,降低他们的意图标志并等待。
我可以只在 C 或汇编中实现 Peterson 的(或 Dekkers)算法吗?
是的 - 通过一点搜索,甚至今天也可以在特定简单的移动处理器上找到它的生产应用:Peterson 的算法用于实现 Tegra 移动处理器的低级 Linux 内核锁(由 Nvidia 的系统级芯片 ARM 处理器和 GPU 核心)android.googlesource.com/kernel/tegra.git/+/android-tegra-3.10/arch/arm/mach-tegra/sleep.S#58
然而,一般来说,CPU 和 C 编译器可以重新排序 CPU 指令或使用 CPU 核心特定的本地缓存值,如果另一个核心更新共享变量,则这些值可能是过时的。因此,对于大多数平台来说,简单的伪代码到 C 的实现太天真了。你现在可以停止阅读了。
哦… 你决定继续阅读。好吧,这里有龙!别说我们没警告过你。考虑这是一个高级和棘手的话题,但(剧透)有一个美好的结局。
考虑以下代码,
while(flag2 ) { /* busy loop - go around again */
一个高效的编译器会推断flag2变量在循环内部永远不会改变,因此测试可以优化为while(true)。使用volatile可以在一定程度上防止这种类型的编译器优化。
独立指令可以被优化编译器重新排序,或者在运行时由 CPU 的乱序执行优化重新排序。如果代码需要变量被修改和检查以及精确的顺序,这些复杂的优化。
一个相关的挑战是 CPU 核心包括数据缓存,用于存储最近读取或修改的主内存值。修改后的值可能不会立即写回主内存或重新从内存中读取。因此,数据更改,例如上面示例中的标志和转换变量的状态,可能不会在两个 CPU 核心之间共享。
但是有一个美好的结局。幸运的是,现代硬件使用“内存栅栏”(也称为内存屏障)CPU 指令来解决这些问题,以确保主内存和 CPU 缓存处于合理和一致的状态。更高级别的同步原语,如pthread_mutex_lock,将调用这些 CPU 指令作为其实现的一部分。因此,在实践中,使用互斥锁的临界区周围的锁定和解锁调用足以忽略这些低级问题。
进一步阅读:我们建议阅读以下网帖,讨论在 x86 进程上实现 Peterson 算法以及关于内存屏障的 Linux 文档。
bartoszmilewski.com/2008/11/05/who-ordered-memory-fences-on-an-x86/ lxr.free-electrons.com/source/Documentation/memory-barriers.txt
硬件解决方案
我们如何在硬件上实现临界区问题?
我们可以使用 C11 原子操作来完美地做到这一点!完整的解决方案在这里详细说明(这是一个自旋锁互斥体,futex的实现可以在网上找到)。
typedef struct mutex_{
atomic_int_least8_t lock;
pthread_t owner;
} mutex;
#define UNLOCKED 0
#define LOCKED 1
#define UNASSIGNED_OWNER 0
int mutex_init(mutex* mtx){
if(!mtx){
return 0;
}
atomic_init(&mtx->lock, UNLOCKED); // Not thread safe the user has to take care of this
mtx->owner = UNASSIGNED_OWNER;
return 1;
}
这是初始化代码,这里没有什么花哨的。我们将互斥体的状态设置为未锁定,并将所有者设置为已锁定。
int mutex_lock(mutex* mtx){
int_least8_t zero = UNLOCKED;
while(!atomic_compare_exchange_weak_explicit
(&mtx->lock,
&zero,
LOCKED,
memory_order_relaxed,
memory_order_relaxed)){
zero = UNLOCKED;
sched_yield(); //Use system calls for scheduling speed
}
//We have the lock now!!!!
mtx->owner = pthread_self();
return 1;
}
天啊!这段代码是做什么的?首先,它初始化一个变量,我们将保持为未锁定状态。原子比较和交换是大多数现代架构支持的指令(在 x86 上是lock cmpxchg)。这个操作的伪代码看起来像这样
int atomic_compare_exchange_pseudo(int* addr1, int* addr2, int val){
if(*addr1 == *addr2){
*addr1 = val;
return 1;
}else{
*addr2 = *addr1;
return 0;
}
}
除了它是原子完成的,意味着在一个不可中断的操作中完成。弱部分是什么意思?原子指令也容易出现虚假失败,这意味着这些原子函数有两个版本,一个强和一个弱,强保证成功或失败,而弱可能失败。我们使用弱部分是因为弱部分更快,而且我们在一个循环中!这意味着如果它失败得更频繁,我们也没关系,因为我们会继续旋转。
这个内存顺序是什么?我们之前讨论过内存栅栏,这就是它!我们不会详细讨论,因为这超出了本课程的范围,但不超出本文的范围。
在 while 循环内,我们未能获取到锁!我们将零重置为 unlocked 并睡一会儿。当我们醒来时,我们再次尝试获取锁。一旦成功交换,我们就进入了临界区!我们为解锁方法设置了互斥体的所有者,并返回成功。
在使用原子操作时,这如何保证互斥性,我们并不完全确定!但在这个简单的例子中,我们可以,因为能够成功期望锁处于 UNLOCKED(0)状态并将其交换到 LOCKED(1)状态的线程被认为是赢家。我们如何实现解锁?
int mutex_unlock(mutex* mtx){
if(unlikely(pthread_self() != mtx->owner)){
return 0; //You can't unlock a mutex if you aren't the owner
}
int_least8_t one = 1;
//Critical section ends after this atomic
mtx->owner = UNASSIGNED_OWNER;
if(!atomic_compare_exchange_strong_explicit(
&mtx->lock,
&one,
UNLOCKED,
memory_order_relaxed,
memory_order_relaxed)){
//The mutex was never locked in the first place
return 0;
}
return 1;
}
为了满足 API,除非你是拥有它的人,否则你不能解锁互斥体。然后我们取消互斥体所有者,因为在原子操作之后临界区已经结束。我们希望进行强交换,因为我们不想阻塞(pthread_mutex_unlock 不会阻塞)。我们期望互斥体被锁住,然后将其交换到解锁状态。如果交换成功,我们就解锁了互斥体。如果交换失败,这意味着互斥体是 UNLOCKED,我们试图将其从 UNLOCKED 切换到 UNLOCKED,保持解锁的非阻塞。
同步,第五部分:条件变量
条件变量简介
热身
给这些属性命名!
-
“一次只有一个进程(/线程)可以进入 CS”
-
“如果等待,那么另一个进程只能进入 CS 有限次数”
-
“如果没有其他进程在 CS 中,那么进程可以立即进入 CS”
参见Synchronization, Part 4: The Critical Section Problem获取答案。
什么是条件变量?如何使用它们?什么是虚假唤醒?
-
条件变量允许一组线程睡眠,直到被唤醒!您可以唤醒一个线程或所有正在睡眠的线程。如果只唤醒一个线程,那么操作系统将决定唤醒哪个线程。您不直接唤醒线程,而是’信号’条件变量,然后将唤醒一个(或所有)正在条件变量内睡眠的线程。
-
条件变量与互斥锁和循环一起使用(用于检查条件)。
-
偶尔,一个等待的线程可能会出现无缘无故地唤醒(这称为虚假唤醒)!这不是问题,因为您总是在循环内使用
wait,该循环测试必须为真才能继续。 -
在条件变量中睡眠的线程通过调用
pthread_cond_broadcast(唤醒所有)或pthread_cond_signal(唤醒一个)来唤醒。请注意,尽管函数名中有"signal",但这与 POSIX 的signal无关!
pthread_cond_wait做什么?
调用pthread_cond_wait执行三个动作:
-
解锁互斥锁
-
等待(睡眠,直到在同一条件变量上调用
pthread_cond_signal) -
在返回之前,锁定互斥锁
(高级话题)为什么条件变量也需要互斥锁?
条件变量需要互斥锁有三个原因。最容易理解的是,它可以防止早期唤醒消息(signal或broadcast函数)被“丢失”。想象一下以下事件序列(时间向下运行页面),其中条件在调用pthread_cond_wait之前 _ 刚好 _ 满足。在这个例子中,唤醒信号丢失了!
| 线程 1 | 线程 2 |
|---|---|
while( answer < 42) { | |
answer++ | |
p_cond_signal(cv) | |
p_cond_wait(cv,m) |
如果两个线程都锁定了互斥锁,则在调用pthread_cond_wait(cv, m)之后(然后在内部解锁互斥锁)之后才能发送信号
第二个常见的原因是,更新程序状态(answer变量)通常需要互斥锁 - 例如,多个线程可能正在更新answer的值。
第三个微妙的原因是满足实时调度的考虑,我们在这里只概述:在时间关键的应用程序中,等待的线程应该允许具有最高优先级的线程先继续。为了满足这个要求,调用pthread_cond_signal或pthread_cond_broadcast之前也必须锁定互斥锁。对于好奇的人,可以在这里找到更长的历史讨论。
为什么会存在虚假唤醒?
出于性能考虑。在多 CPU 系统上,可能会发生竞争条件,导致唤醒(信号)请求被忽略。内核可能不会检测到这个丢失的唤醒调用,但可以检测到可能发生的情况。为了避免潜在的丢失信号,唤醒线程以便程序代码可以再次测试条件。
例子
条件变量总是与互斥锁一起使用。
在调用wait之前,必须锁定互斥锁,并且wait必须用循环包装。
pthread_cond_t cv;
pthread_mutex_t m;
int count;
// Initialize
pthread_cond_init(&cv, NULL);
pthread_mutex_init(&m, NULL);
count = 0;
pthread_mutex_lock(&m);
while (count < 10) {
pthread_cond_wait(&cv, &m);
/* Remember that cond_wait unlocks the mutex before blocking (waiting)! */
/* After unlocking, other threads can claim the mutex. */
/* When this thread is later woken it will */
/* re-lock the mutex before returning */
}
pthread_mutex_unlock(&m);
//later clean up with pthread_cond_destroy(&cv); and mutex_destroy
// In another thread increment count:
while (1) {
pthread_mutex_lock(&m);
count++;
pthread_cond_signal(&cv);
/* Even though the other thread is woken up it cannot not return */
/* from pthread_cond_wait until we have unlocked the mutex. This is */
/* a good thing! In fact, it is usually the best practice to call */
/* cond_signal or cond_broadcast before unlocking the mutex */
pthread_mutex_unlock(&m);
}
实现计数信号量
-
我们可以使用条件变量实现计数信号量。
-
每个信号量都需要一个计数、一个条件变量和一个互斥锁
typedef struct sem_t {
int count;
pthread_mutex_t m;
pthread_condition_t cv;
} sem_t;
实现sem_init以初始化互斥锁和条件变量
int sem_init(sem_t *s, int pshared, int value) {
if (pshared) { errno = ENOSYS /* 'Not implemented'*/; return -1;}
s->count = value;
pthread_mutex_init(&s->m, NULL);
pthread_cond_init(&s->cv, NULL);
return 0;
}
我们的sem_post实现需要增加计数。我们还将唤醒任何在条件变量内睡眠的线程。请注意,我们锁定并解锁互斥锁,因此一次只有一个线程可以在临界区内。
sem_post(sem_t *s) {
pthread_mutex_lock(&s->m);
s->count++;
pthread_cond_signal(&s->cv); /* See note */
/* A woken thread must acquire the lock, so it will also have to wait until we call unlock*/
pthread_mutex_unlock(&s->m);
}
我们的sem_wait实现可能需要睡眠,如果信号量的计数为零。就像sem_post一样,我们使用锁来包装临界区(这样一次只有一个线程可以执行我们的代码)。请注意,如果线程确实需要等待,那么互斥锁将被解锁,允许另一个线程进入sem_post并唤醒我们的睡眠!
请注意,即使线程被唤醒,在从pthread_cond_wait返回之前,它必须重新获取锁,因此它将不得不等待一小段时间(例如,直到sem_post完成)。
sem_wait(sem_t *s) {
pthread_mutex_lock(&s->m);
while (s->count == 0) {
pthread_cond_wait(&s->cv, &s->m); /*unlock mutex, wait, relock mutex*/
}
s->count--;
pthread_mutex_unlock(&s->m);
}
等待sem_post不断调用pthread_cond_signal会不会破坏sem_wait? 答案:不会!在计数非零之前,我们无法跳出循环。实际上,这意味着sem_post即使没有等待的线程,也会不必要地调用pthread_cond_signal。更高效的实现只会在必要时调用pthread_cond_signal,即:
/* Did we increment from zero to one- time to signal a thread sleeping inside sem_post */
if (s->count == 1) /* Wake up one waiting thread!*/
pthread_cond_signal(&s->cv);
其他信号量考虑
-
真正的信号量实现包括队列和调度问题,以确保公平性和优先级,例如唤醒最高优先级的最长睡眠线程。
-
另外,
sem_init的高级用法允许信号量在进程之间共享。我们的实现仅适用于同一进程内的线程。
同步,第六部分:实现屏障
如何等待 N 个线程在继续下一步之前到达某一点?
假设我们想要执行一个多线程计算,它有两个阶段,但我们不想在第一阶段完成之前进入第二阶段。
我们可以使用一种称为屏障的同步方法。当一个线程到达屏障时,它将在屏障处等待,直到所有线程到达屏障,然后它们将一起继续。
想象一下,就像和一些朋友一起去远足。你们约定在每个山顶等待彼此(并且你心里记下了你的团队有多少人)。假设你是第一个到达第一个山顶的人。你会在山顶等待你的朋友。他们一个接一个地到达山顶,但直到你的团队中的最后一个人到达之前,没有人会继续前进。一旦他们到达,你们就会一起继续。
Pthreads 有一个实现这一点的函数pthread_barrier_wait()。您需要声明一个pthread_barrier_t变量,并使用pthread_barrier_init()对其进行初始化。pthread_barrier_init()将参与屏障的线程数作为参数。这里有一个例子。
现在让我们实现自己的屏障,并使用它在大型计算中同步所有线程。
double data[256][8192]
1 Threads do first calculation (use and change values in data)
2 Barrier! Wait for all threads to finish first calculation before continuing
3 Threads do second calculation (use and change values in data)
线程函数有四个主要部分-
void *calc(void *arg) {
/* Do my part of the first calculation */
/* Am I the last thread to finish? If so wake up all the other threads! */
/* Otherwise wait until the other threads has finished part one */
/* Do my part of the second calculation */
}
我们的主线程将创建 16 个线程,并将每个计算分成 16 个单独的部分。每个线程将被赋予一个唯一的值(0,1,2,…15),以便它可以处理自己的块。由于(void*)类型可以保存小整数,我们将通过将其转换为 void 指针来传递i的值。
#define N (16)
double data[256][8192] ;
int main() {
pthread_t ids[N];
for(int i = 0; i < N; i++)
pthread_create(&ids[i], NULL, calc, (void *) i);
请注意,我们永远不会将此指针值解引用为实际的内存位置-我们只会将其直接转换回整数:
void *calc(void *ptr) {
// Thread 0 will work on rows 0..15, thread 1 on rows 16..31
int x, y, start = N * (int) ptr;
int end = start + N;
for(x = start; x < end; x++) for (y = 0; y < 8192; y++) { /* do calc #1 */ }
第 1 个计算完成后,我们需要等待较慢的线程(除非我们是最后一个线程!)。因此,跟踪已经到达我们的屏障(也称为“检查点”)的线程数量:
// Global:
int remain = N;
// After calc #1 code:
remain--; // We finished
if (remain ==0) {/*I'm last! - Time for everyone to wake up! */ }
else {
while (remain != 0) { /* spin spin spin*/ }
}
然而,上述代码存在竞争条件(两个线程可能尝试递减remain),并且循环是一个忙循环。我们可以做得更好!让我们使用条件变量,然后我们将使用广播/信号函数唤醒睡眠的线程。
提醒一下,条件变量类似于一个房子!线程在那里睡觉(pthread_cond_wait)。您可以选择唤醒一个线程(pthread_cond_signal)或所有线程(pthread_cond_broadcast)。如果当前没有线程在等待,那么这两个调用将不起作用。
条件变量版本通常与忙循环不正确的解决方案非常相似-接下来我们将展示。首先,让我们添加一个互斥锁和条件全局变量,不要忘记在main中初始化它们…
//global variables
pthread_mutex_t m;
pthread_cond_t cv;
main() {
pthread_mutex_init(&m, NULL);
pthread_cond_init(&cv, NULL);
我们将使用互斥锁来确保只有一个线程在一次修改remain。最后到达的线程需要唤醒所有睡眠的线程-因此我们将使用pthread_cond_broadcast(&cv)而不是pthread_cond_signal
pthread_mutex_lock(&m);
remain--;
if (remain ==0) { pthread_cond_broadcast(&cv); }
else {
while(remain != 0) { pthread_cond_wait(&cv, &m); }
}
pthread_mutex_unlock(&m);
当线程进入pthread_cond_wait时,它释放互斥锁并进入睡眠状态。在将来的某个时刻,它将被唤醒。一旦我们将线程从睡眠中唤醒,它在返回之前必须等待直到可以锁定互斥锁。请注意,即使一个睡眠的线程提前醒来,它也会检查 while 循环条件并在必要时重新进入等待。
上述屏障不可重用这意味着如果我们将其放入任何旧的计算循环中,代码很可能会遇到屏障死锁或线程比一个迭代更快的情况。思考一下如何使上述屏障可重用,这意味着如果多个线程在循环中调用barrier_wait,则可以保证它们处于相同的迭代。
同步,第七部分:读者写者问题
读者写者问题是什么?
想象一下,您有一个键值映射数据结构,被许多线程使用。只要数据结构没有被写入,多个线程应该能够同时查找(读取)值。写者不那么合群-为了避免数据损坏,一次只有一个线程可以修改(write)数据结构(此时不能有读者正在读取)。
这是读者写者问题的一个例子。也就是说,我们如何有效地同步多个读者和写者,以便多个读者可以一起阅读,但写者可以获得独占访问?
下面显示了一个不正确的尝试(“锁”是pthread_mutex_lock的简写):
尝试#1
read() {
lock(&m)
// do read stuff
unlock(&m)
}
write() {
lock(&m)
// do write stuff
unlock(&m)
}
至少我们的第一次尝试不会遭受数据损坏(读者必须在写者写作时等待,反之亦然)!但是读者也必须等待其他读者。所以让我们尝试另一种实现…
尝试#2:
read() {
while(writing) {/*spin*/}
reading = 1
// do read stuff
reading = 0
}
write() {
while(reading || writing) {/*spin*/}
writing = 1
// do write stuff
writing = 0
}
我们的第二次尝试遭受了竞争条件的影响-想象一下,如果两个线程同时调用read和write(或同时调用 write)。两个线程都将能够继续进行!其次,我们可以有多个读者和多个写者,因此让我们跟踪读者或写者的总数。这就是我们尝试#3,
尝试#3
请记住,pthread_cond_wait执行三个动作。首先,它会原子解锁互斥锁,然后休眠(直到被pthread_cond_signal或pthread_cond_broadcast唤醒)。第三,唤醒的线程必须在返回之前重新获取互斥锁。因此,只有一个线程实际上可以在由 lock 和 unlock()方法定义的临界区域内运行。
下面的实现#3 确保如果有任何写者在写作,读者将进入 cond_wait。
read() {
lock(&m)
while (writing)
cond_wait(&cv, &m)
reading++;
/* Read here! */
reading--
cond_signal(&cv)
unlock(&m)
}
但是因为候选#3 在读取之前没有解锁互斥锁,所以一次只能有一个读者读取。更好的版本在读取之前解锁:
read() {
lock(&m);
while (writing)
cond_wait(&cv, &m)
reading++;
unlock(&m)
/* Read here! */
lock(&m)
reading--
cond_signal(&cv)
unlock(&m)
}
这是否意味着写者和读者可以同时读和写?不!首先,记住 cond_wait 要求线程在返回之前重新获取互斥锁。因此,只有一个线程可以在临界区域(用**标记)内执行代码!
read() {
lock(&m);
** while (writing)
** cond_wait(&cv, &m)
** reading++;
unlock(&m)
/* Read here! */
lock(&m)
** reading--
** cond_signal(&cv)
unlock(&m)
}
写者必须等待所有人。互斥由锁来保证。
write() {
lock(&m);
** while (reading || writing)
** cond_wait(&cv, &m);
** writing++;
**
** /* Write here! */
** writing--;
** cond_signal(&cv);
unlock(&m);
}
上述候选#3 还使用pthread_cond_signal;这只会唤醒一个线程。例如,如果许多读者正在等待写者完成,那么只有一个正在睡眠的读者将被唤醒。读者和写者应该使用cond_broadcast,以便所有线程都应该唤醒并检查它们的 while 循环条件。
饥饿的写者
上述候选#3 遭受饥饿。如果读者不断到来,那么写者将永远无法继续进行(“读取”计数永远不会减少到零)。这被称为饥饿,并且在重负载下会被发现。我们的修复方法是为写者实现有界等待。如果写者到达,他们仍然需要等待现有的读者,但是未来的读者必须被放置在“等待区”中等待写者完成。可以使用变量和条件变量来实现“等待区”(以便我们可以在写者完成后唤醒线程)。
我们的计划是,当写者到达并在等待当前读者完成之前,注册我们的写入意图(通过增加计数器’writer’)。下面是草图-
write() {
lock()
writer++
while (reading || writing)
cond_wait
unlock()
...
}
并且当写者为非零时,传入的读者将不被允许继续。请注意,“写者”表示写者已到达,而“读取”和“写入”计数器表示有活动读者或写者。
read() {
lock()
// readers that arrive *after* the writer arrived will have to wait here!
while(writer)
cond_wait(&cv,&m)
// readers that arrive while there is an active writer
// will also wait.
while (writing)
cond_wait(&cv,&m)
reading++
unlock
...
}
尝试#4
以下是我们对读者-写者问题的第一个工作解决方案。请注意,如果你继续阅读关于“读者写者问题”的内容,你会发现我们通过给予写者对锁的优先访问来解决了“第二个读者写者问题”。这个解决方案并不是最佳的。然而,它满足了我们最初的问题(N 个活跃读者,单个活跃写者,避免了如果有持续的读者流的话写者饥饿)。
你能识别出任何改进吗?例如,你会如何改进代码,以便我们只唤醒读者或一个写者?
int writers; // Number writer threads that want to enter the critical section (some or all of these may be blocked)
int writing; // Number of threads that are actually writing inside the C.S. (can only be zero or one)
int reading; // Number of threads that are actually reading inside the C.S.
// if writing !=0 then reading must be zero (and vice versa)
reader() {
lock(&m)
while (writers)
cond_wait(&turn, &m)
// No need to wait while(writing here) because we can only exit the above loop
// when writing is zero
reading++
unlock(&m)
// perform reading here
lock(&m)
reading--
cond_broadcast(&turn)
unlock(&m)
}
writer() {
lock(&m)
writers++
while (reading || writing)
cond_wait(&turn, &m)
writing++
unlock(&m)
// perform writing here
lock(&m)
writing--
writers--
cond_broadcast(&turn)
unlock(&m)
}
同步,第八部分:环形缓冲区示例
什么是环形缓冲区?
环形缓冲区是一种简单的、通常是固定大小的存储机制,其中连续的内存被视为循环的,并且两个索引计数器跟踪队列的当前开始和结束。由于数组索引不是循环的,所以当移动到数组的末尾时,索引计数器必须回绕到零。当数据被添加(入队)到队列的前端或从队列的尾部移除(出队)时,缓冲区中的当前项目形成一个似乎环绕轨道的列车!一个简单的(单线程)实现如下所示。请注意,enqueue 和 dequeue 没有防止下溢或上溢——当队列已满时可能添加一个项目,当队列为空时可能移除一个项目。例如,如果我们向队列中添加了 20 个整数(1,2,3…),并且没有移除任何项目,那么值17,18,19,20将覆盖1,2,3,4。我们现在不会解决这个问题,而是在创建多线程版本时,我们将确保在环形缓冲区已满或为空时,enqueue 和 dequeue 线程被阻塞。
void *buffer[16];
int in = 0, out = 0;
void enqueue(void *value) { /* Add one item to the front of the queue*/
buffer[in] = value;
in++; /* Advance the index for next time */
if (in == 16) in = 0; /* Wrap around! */
}
void *dequeue() { /* Remove one item to the end of the queue.*/
void *result = buffer[out];
out++;
if (out == 16) out = 0;
return result;
}
实现环形缓冲区的注意事项是什么?
很容易写出 enqueue 或 dequeue 方法的以下紧凑形式(N 是缓冲区的容量,例如 16):
void enqueue(void *value)
b[ (in++) % N ] = value;
}
这种方法似乎可以工作(通过简单的测试等),但包含一个微妙的错误。通过足够多的 enqueue 操作(略多于 20 亿次),in的 int 值将溢出并变为负数!模运算符%保留符号。因此,你可能会写入b[-14],例如!
一个紧凑的形式是正确的使用位掩码,提供 N 是 2^x(16,32,64,…)
b[ (in++) & (N-1) ] = value;
这个缓冲区还没有防止缓冲区下溢或上溢。为此,我们将转向我们的多线程尝试,它将阻塞一个线程,直到有空间或至少有一个项目可以移除。
检查多线程实现的正确性(示例 1)
以下代码是一个不正确的实现。会发生什么?enqueue和/或dequeue会阻塞吗?互斥性是否得到满足?缓冲区会下溢吗?缓冲区会上溢吗?为了清晰起见,pthread_mutex缩写为p_m,我们假设 sem_wait 不会被中断。
#define N 16
void *b[N]
int in = 0, out = 0
p_m_t lock
sem_t s1,s2
void init() {
p_m_init(&lock, NULL)
sem_init(&s1, 0, 16)
sem_init(&s2, 0, 0)
}
enqueue(void *value) {
p_m_lock(&lock)
// Hint: Wait while zero. Decrement and return
sem_wait( &s1 )
b[ (in++) & (N-1) ] = value
// Hint: Increment. Will wake up a waiting thread
sem_post(&s1)
p_m_unlock(&lock)
}
void *dequeue(){
p_m_lock(&lock)
sem_wait(&s2)
void *result = b[(out++) & (N-1) ]
sem_post(&s2)
p_m_unlock(&lock)
return result
}
分析
在继续阅读之前,看看你能找到多少错误。然后确定如果线程调用 enqueue 和 dequeue 方法会发生什么。
-
enqueue 方法在同一个信号量(s1)上等待和发布,equeue 也是如此(s2)即我们减少值然后立即增加值,因此在函数结束时,信号量值不变!
-
s1 的初始值为 16,因此信号量永远不会减少到零——如果环形缓冲区已满,enqueue 不会阻塞——因此可能会发生溢出。
-
s2 的初始值为零,因此调用 dequeue 将始终阻塞并且永远不会返回!
-
互斥锁和 sem_wait 的顺序需要交换(但是这个示例是如此破碎,以至于这个错误没有影响!)##检查多线程实现的正确性(示例 1)
以下代码是一个不正确的实现。会发生什么?enqueue和/或dequeue会阻塞吗?互斥性是否得到满足?缓冲区会下溢吗?缓冲区会上溢吗?为了清晰起见,pthread_mutex缩写为p_m,我们假设 sem_wait 不会被中断。
void *b[16]
int in = 0, out = 0
p_m_t lock
sem_t s1, s2
void init() {
sem_init(&s1,0,16)
sem_init(&s2,0,0)
}
enqueue(void *value){
sem_wait(&s2)
p_m_lock(&lock)
b[ (in++) & (N-1) ] = value
p_m_unlock(&lock)
sem_post(&s1)
}
void *dequeue(){
sem_wait(&s1)
p_m_lock(&lock)
void *result = b[(out++) & 15]
p_m_unlock(&lock)
sem_post(&s2)
return result;
}
分析
-
s2 的初始值为 0。因此,在第一次调用 sem_wait 时,enqueue 将阻塞,即使缓冲区为空!
-
s1 的初始值为 16。因此,在第一次调用 sem_wait 时,dequeue 不会阻塞,即使缓冲区为空——糟糕,下溢!dequeue 方法将返回无效数据。
-
该代码不满足互斥性;两个线程可以同时修改
in或out! 该代码似乎使用了互斥锁。不幸的是,该锁从未使用pthread_mutex_init()或PTHREAD_MUTEX_INITIALIZER进行初始化 - 因此该锁可能无效(pthread_mutex_lock可能什么也不做)
正确实现环形缓冲区
伪代码(pthread_mutex 缩写为 p_m 等)如下所示。
由于互斥锁存储在全局(静态)内存中,因此可以使用 PTHREAD_MUTEX_INITIALIZER 进行初始化。如果我们在堆上为互斥锁分配了空间,那么我们将使用 pthread_mutex_init(ptr, NULL)
#include <pthread.h>
#include <semaphore.h>
// N must be 2^i
#define N (16)
void *b[N]
int in = 0, out = 0
p_m_t lock = PTHREAD_MUTEX_INITIALIZER
sem_t countsem, spacesem
void init() {
sem_init(&countsem, 0, 0)
sem_init(&spacesem, 0, 16)
}
enqueue 方法如下所示。请注意:
-
该锁仅在临界区(对数据结构的访问)期间保持。
-
完整的实现需要防止由于 POSIX 信号而导致
sem_wait提前返回。
enqueue(void *value){
// wait if there is no space left:
sem_wait( &spacesem )
p_m_lock(&lock)
b[ (in++) & (N-1) ] = value
p_m_unlock(&lock)
// increment the count of the number of items
sem_post(&countsem)
}
dequeue 实现如下所示。请注意 enqueue 的同步调用的对称性。在两种情况下,如果空间计数或项目计数为零,函数首先会等待。
void *dequeue(){
// Wait if there are no items in the buffer
sem_wait(&countsem)
p_m_lock(&lock)
void *result = b[(out++) & (N-1)]
p_m_unlock(&lock)
// Increment the count of the number of spaces
sem_post(&spacesem)
return result
}
思考
-
如果
pthread_mutex_unlock和sem_post调用的顺序被交换会发生什么? -
如果
sem_wait和pthread_mutex_lock调用的顺序被交换会发生什么?
同步复习问题
主题
-
原子操作
-
临界区
-
生产者消费者问题
-
使用条件变量
-
使用计数信号量
-
实现一个屏障
-
实现环形缓冲区
-
使用 pthread_mutex
-
实现生产者消费者
-
分析多线程代码
问题
-
什么是原子操作?
-
为什么以下内容在并行代码中不起作用?
//In the global section
size_t a;
//In pthread function
for(int i = 0; i < 100000000; i++) a++;
这将会是什么?
//In the global section
atomic_size_t a;
//In pthread function
for(int i = 0; i < 100000000; i++) atomic_fetch_add(a, 1);
-
原子操作有哪些缺点?哪个更快:保留一个本地变量还是进行多个原子操作?
-
什么是临界区?
-
一旦确定了临界区,保证只有一个线程会进入该区域的一种方法是什么?
-
在这里确定临界区
struct linked_list;
struct node;
void add_linked_list(linked_list *ll, void* elem){
node* packaged = new_node(elem);
if(ll->head){
ll->head =
}else{
packaged->next = ll->head;
ll->head = packaged;
ll->size++;
}
}
void* pop_elem(linked_list *ll, size_t index){
if(index >= ll->size) return NULL;
node *i, *prev;
for(i = ll->head; i && index; i = i->next, index--){
prev = i;
}
//i points to the element we need to pop, prev before
if(prev->next) prev->next = prev->next->next;
ll->size--;
void* elem = i->elem;
destroy_node(i);
return elem;
}
临界区可以有多紧凑?
-
什么是生产者消费者问题?以上述部分如何成为生产者消费者问题?生产者消费者问题与读者写者问题有什么关系?
-
什么是条件变量?为什么使用条件变量比使用“while”循环更有优势?
-
为什么这段代码很危险?
if(not_ready){
pthread_cond_wait(&cv, &mtx);
}
-
什么是计数信号量?给我一个类似于饼干罐/比萨盒/有限食物的比喻。
-
什么是线程屏障?
-
使用计数信号量来实现屏障。
-
编写一个生产者/消费者队列,再来一个生产者/消费者栈?
-
给我一个使用条件变量的读者-写者锁的实现,使用你需要的任何结构,它只需要支持以下函数
void reader_lock(rw_lock_t* lck);
void writer_lock(rw_lock_t* lck);
void reader_unlock(rw_lock_t* lck);
void writer_unlock(rw_lock_t* lck);
唯一的规定是在“reader_lock”和“reader_unlock”之间,没有写者可以写。在写者锁之间,只有一个写者可以一次写作。
-
编写代码使用仅三个计数信号量实现生产者消费者。假设可以有多个线程调用 enqueue 和 dequeue。确定每个信号量的初始值。
-
编写代码使用条件变量和互斥锁实现生产者消费者。假设可以有多个线程调用 enqueue 和 dequeue。
-
使用 CVs 实现 add(unsigned int)和 subtract(unsigned int)阻塞函数,永远不允许全局值大于 100。
-
使用 CVs 为 15 个线程实现一个屏障。
-
以下陈述有多少是真的?
-
可以有多个活跃的读者
-
可以有多个活跃的写者
-
当有活跃的写者时,活跃的读者数量必须为零
-
如果有活跃的读者,则活跃的写者数量必须为零
-
一个写者必须等到当前活跃的读者完成
-
-
待办事项:分析多线程代码片段
六、死锁
死锁,第一部分:资源分配图
什么是资源分配图?
资源分配图跟踪哪个进程持有哪个资源,以及哪个进程正在等待特定类型的资源。这是一个非常强大而简单的工具,用来说明交互进程如何发生死锁。如果一个进程使用一个资源,就从资源节点到进程节点画一个箭头。如果一个进程请求一个资源,就从进程节点到资源节点画一个箭头。
如果资源分配图中有一个循环,并且循环中的每个资源只提供一个实例,那么进程将发生死锁。例如,如果进程 1 持有资源 A,进程 2 持有资源 B,进程 1 正在等待 B,进程 2 正在等待 A,那么进程 1 和 2 将发生死锁。
这里有另一个例子,显示了进程 1 和 2 获取资源 1 和 2,而进程 3 正在等待获取这两个资源。在这个例子中,没有死锁,因为没有循环依赖。

死锁!
很多时候,我们不知道资源可能被获取的具体顺序,所以我们可以绘制有向图。

作为可能性矩阵。然后我们可以画箭头,看看是否有一个有向版本会导致死锁。

考虑以下资源分配图(假设进程请求对文件的独占访问)。如果有一堆进程在运行,并且它们请求资源,操作系统最终处于这种状态,你就会发生死锁!你可能看不到这一点,因为操作系统可能会抢占一些进程来打破循环,但你的三个孤独进程仍然有可能发生死锁。你也可以使用make和规则依赖关系(例如我们的 parmake MP)制作这种类型的图表。

死锁,第二部分:死锁条件
Coffman 条件
死锁有四个必要和充分条件。这些被称为 Coffman 条件。
-
互斥
-
循环等待
-
持有并等待
-
无抢占
如果打破其中任何一个,就不会发生死锁!
所有这些条件都是死锁所必需的,所以让我们依次讨论每一个。首先是简单的-
-
互斥:资源不能被共享
-
循环等待:资源分配图中存在一个循环。存在一组进程{P1,P2,…},使得 P1 正在等待 P2 持有的资源,P2 正在等待 P3,…,P3 正在等待 P1 持有的资源。
-
持有并等待:一个进程获取了一个不完整的资源集,并在等待其他资源时保持它们。
-
无抢占:一旦一个进程获取了一个资源,该资源就不能被从一个进程那里拿走,而且进程也不会自愿放弃一个资源。
打破 Coffman 条件
两个学生需要一支笔和一张纸:
-
学生们共享一支笔和一张纸。避免了死锁,因为不需要互斥。
-
学生们都同意先拿笔再拿纸。避免了死锁,因为不会有循环等待。
-
学生们一次拿起笔和纸(“要么都拿,要么都不拿”)。避免了死锁,因为没有持有并等待
-
学生们是朋友,会要求对方放弃持有的资源。避免了死锁,因为允许抢占。
活锁
活锁不是死锁-
考虑以下的“解决方案”
- 如果他们无法在 10 秒内拿起另一个资源,学生们会放下一个持有的资源。这个解决方案避免了死锁,但可能会遭受活锁。
活锁发生在一个进程继续执行但无法取得进展。在实践中,活锁可能是因为程序员已经采取措施避免死锁。在上面的例子中,在繁忙的系统中,学生将不断释放第一个资源,因为他们永远无法获得第二个资源。系统不是死锁(学生进程仍在执行),但也没有取得任何进展。
死锁预防/避免 vs 死锁检测
死锁预防是确保死锁不会发生,这意味着你打破了 Coffman 条件。这在单个程序内效果最好,软件工程师可以选择打破某个 Coffman 条件。考虑银行家算法。这是另一个用于避免死锁的算法。整个实现超出了本课程的范围,只需知道操作系统有更通用的算法。
另一方面,死锁检测允许系统进入死锁状态。进入后,系统使用其拥有的信息来打破死锁。例如,考虑多个进程访问文件。操作系统能够通过文件描述符在某个级别(通过 API 或直接)跟踪所有文件/资源。如果操作系统在操作系统文件描述符表中检测到一个有向循环,它可能会打破一个进程的持有(例如通过调度)并让系统继续进行。
餐桌哲学家
餐桌哲学家问题是一个经典的同步问题。想象我邀请 N(假设为 5)位哲学家共进晚餐。我们将他们安排在一张桌子旁,放置 5 根筷子(每位哲学家之间各有一根)。哲学家交替地想要吃饭或思考。为了吃饭,哲学家必须拿起他们位置两侧的两根筷子(原始问题要求每位哲学家有两把叉子)。然而这些筷子是与他的邻居共享的。

设计一种有效的解决方案,使所有哲学家都能吃饭吗?或者,会有一些哲学家挨饿,永远得不到第二根筷子吗?或者他们全部陷入僵局?例如,想象每个客人都拿起左边的筷子,然后等待右边的筷子空闲。哎呀 - 我们的哲学家陷入了僵局!
死锁,第三部分:餐桌上的哲学家
背景故事

所以你的哲学家们围坐在桌子周围,都想吃点意大利面(或者其他什么),他们真的很饿。每个哲学家本质上都是一样的,这意味着每个哲学家都有相同的指令集,基于其他哲学家,也就是说你不能让每个偶数哲学家做一件事,每个奇数哲学家做另一件事。
失败的解决方案
左右死锁
我们该怎么办?让我们尝试一个简单的解决方案
void* philosopher(void* forks){
info phil_info = forks;
pthread_mutex_t* left_fork = phil_info->left_fork;
pthread_mutex_t* right_fork = phil_info->right_fork;
while(phil_info->simulation){
pthread_mutex_lock(left_fork);
pthread_mutex_lock(right_fork);
eat(left_fork, right_fork);
pthread_mutex_unlock(left_fork);
pthread_mutex_unlock(right_fork);
}
}
但是这会遇到一个问题!如果每个人都拿起他们的左手叉子,正在等待他们的右手叉子呢?我们已经死锁了程序。重要的是要注意,死锁并不总是发生,而且这个解决方案死锁的概率随着哲学家的数量增加而降低。真正重要的是,最终这个解决方案会死锁,让线程挨饿,这是不好的。
Trylock?更像是活锁
所以现在你在考虑打破柯夫曼条件之一。我们有
-
互斥
-
没有抢占
-
持有并等待
-
循环等待
嗯,我们不能让两个哲学家同时使用一个叉子,互斥被排除在外。在我们当前的简单模型中,我们不能让哲学家一旦拿到互斥锁就放开它,所以我们现在就排除这个解决方案——关于这个解决方案有一些注释在页面底部。让我们打破持有并等待!
void* philosopher(void* forks){
info phil_info = forks;
pthread_mutex_t* left_fork = phil_info->left_fork;
pthread_mutex_t* right_fork = phil_info->right_fork;
while(phil_info->simulation){
pthread_mutex_lock(left_fork);
int failed = pthread_mutex_trylock(right_fork);
if(!failed){
eat(left_fork, right_fork);
pthread_mutex_unlock(right_fork);
}
pthread_mutex_unlock(left_fork);
}
}
现在我们的哲学家拿起左边的叉子,试图抓住右边的叉子。如果右边的叉子可用,他们就吃。如果不可用,他们放下左边的叉子再试一次。没有死锁!
但是,有一个问题。如果所有的哲学家同时拿起他们的左手,试图抓住他们的右手,放下他们的左手,再拿起他们的左手,试图抓住他们的右手……我们现在活锁了我们的解决方案!我们可怜的哲学家们仍然饿着,所以让我们给他们一些合适的解决方案。
可行的解决方案
仲裁者(天真和高级)。
天真的仲裁者解决方案是有一个仲裁者(例如一个互斥锁)。让每个哲学家请求仲裁者的许可来吃饭。这个解决方案一次只允许一个哲学家吃饭。当他们吃完后,另一个哲学家可以请求吃饭的许可。
这可以防止死锁,因为没有循环等待!没有哲学家需要等待其他哲学家。
高级仲裁者解决方案是实现一个类,确定哲学家的叉子是否在仲裁者的控制下。如果是,他们把叉子给哲学家,让他吃,然后拿回叉子。这有一个额外的好处,就是能够让多个哲学家同时吃饭。
问题:
-
这些解决方案很慢
-
他们有一个单一的故障点,仲裁者使其成为一个瓶颈
-
仲裁者在第二个解决方案中也需要公平,并且能够确定死锁
-
在实际系统中,仲裁者倾向于重复地将叉子交给刚刚吃过的哲学家,因为进程调度
离开桌子(Stallings 的解决方案)
为什么第一个解决方案会死锁?嗯,有 n 个哲学家和 n 根筷子。如果桌子上只有 1 个哲学家怎么办?我们会死锁吗?不会。
2 个哲学家怎么样?3 个?……你可以看出这是怎么回事。Stallings 的解决方案是从桌子上移除哲学家,直到死锁不可能发生——想想桌子上的哲学家的魔数是多少。在实际系统中,通过信号量来实现这一点,并让一定数量的哲学家通过。
问题:
-
解决方案需要大量的上下文切换,这对 CPU 来说非常昂贵
-
你需要提前知道资源的数量,以便只让那么多的哲学家
-
再次优先考虑那些已经吃过的进程。
部分排序(Dijkstra 的解决方案)
这是 Dijkstra 的解决方案(他是在考试中提出这个问题的人)。为什么第一个解决方案会死锁?Dijkstra 认为最后一个拿起他左边叉子的哲学家(导致解决方案死锁)应该拿起他的右边叉子。他通过给叉子编号 1…n,并告诉每个哲学家拿起他较小编号的叉子来实现这一点。
让我们再次运行死锁条件。每个人都试图先拿起他们较小编号的叉子。哲学家 1 拿到叉子 1,哲学家 2 拿到叉子 2,依此类推,直到我们到达哲学家 n。他们必须在叉子 1 和 n 之间做出选择。叉子 1 已经被哲学家 1 拿起,所以他们不能拿起那个叉子,这意味着他不会拿起叉子 n。我们打破了循环等待!这意味着死锁是不可能的。
问题:
-
哲学家在抓取任何资源之前需要知道资源的集合顺序。
-
您需要为所有资源定义一个偏序。
-
优先考虑已经吃过饭的哲学家。
高级解决方案
还有许多更高级的解决方案,非穷尽列表包括
-
干净/脏叉子(钱德拉/米斯拉解决方案)
-
演员模型(其他消息传递模型)
-
超级仲裁者(复杂的管道)
死锁复习问题
主题
Coffman 条件资源分配图餐厅哲学家
-
失败的 DP 解决方案
-
活锁 DP 解决方案
-
工作的 DP 解决方案:优缺点
问题
-
科夫曼条件是什么?
-
科夫曼条件的每个意思是什么?(例如,你能提供每个条件的定义吗?)
-
举一个打破科夫曼条件的真实例子。一个需要考虑的情况:画家,油漆,画笔等。你如何确保工作会完成?
-
能够识别餐厅哲学家代码何时导致死锁(或者不导致)。例如,如果你看到以下代码片段,哪个科夫曼条件没有满足?
// Get both locks or none.
pthread_mutex_lock( a );
if( pthread_mutex_trylock( b ) ) { /*failed*/
pthread_mutex_unlock( a );
...
}
- 如果一个线程调用
pthread_mutex_lock(m1) // success
pthread_mutex_lock(m2) // blocks
还有另一个线程调用
pthread_mutex_lock(m2) // success
pthread_mutex_lock(m1) // blocks
发生了什么,为什么?如果第三个线程调用pthread_mutex_lock(m1)会发生什么?
-
有多少进程被阻塞?通常情况下,假设一个进程能够完成,如果它能够获取下面列出的所有资源。
-
P1 获取 R1
-
P2 获取 R2
-
P1 获取 R3
-
P2 等待 R3
-
P3 获取 R5
-
P1 等待 R4
-
P3 等待 R1
-
P4 等待 R5
-
P5 等待 R1
-
(画出资源图!)
七、进程间通信和调度
虚拟内存,第一部分:虚拟内存简介
什么是虚拟内存?
在非常简单的嵌入式系统和早期计算机中,进程直接访问内存,即“地址 1234”对应于物理内存的特定部分中存储的特定字节。在现代系统中,情况已经不再是这样。相反,每个进程都是隔离的;并且存在着一个地址转换过程,将进程的特定 CPU 指令或数据的地址与物理内存(“RAM”)的实际字节对应起来。内存地址不再是“真实的”;进程在虚拟内存中运行。虚拟内存不仅可以保护进程的安全(因为一个进程不能直接读取或修改另一个进程的内存),还允许系统有效地分配和重新分配内存的部分给不同的进程。
MMU 是什么?
内存管理单元是 CPU 的一部分。它将虚拟内存地址转换为物理地址。如果当前没有从特定虚拟地址到物理地址的映射,或者当前 CPU 指令尝试写入进程只有读取访问权限的位置,MMU 也可能中断 CPU。
那么我们如何将虚拟地址转换为物理地址?
想象一下你有一台 32 位的机器。指针可以保存 32 位,即它们可以寻址 2^32 个不同的位置,即 4GB 的内存(我们将遵循一个地址可以保存一个字节的标准约定)。
想象我们有一个大表 - 这是聪明的部分 - 存储在内存中!对于每个可能的地址(共 40 亿个),我们将存储“真实”即物理地址。每个物理地址将需要 4 个字节(以容纳 32 位)。这种方案将需要 160 亿字节来存储所有条目。哎呀 - 我们的查找方案将消耗我们可能为我们的 4GB 机器购买的所有内存。我们需要做得比这更好。我们的查找表最好比我们拥有的内存小,否则我们将没有空间留给我们的实际程序和操作系统数据。解决方案是将内存分成称为“页面”和“帧”的小区域,并为每个页面使用查找表。
什么是页面?有多少个页面?
页面是一块虚拟内存。Linux 操作系统上的典型块大小为 4KB(即 2^12 个地址),尽管您可以找到更大块的示例。
因此,我们不再谈论单个字节,而是谈论 4KB 的块,每个块称为一个页面。我们还可以对我们的页面进行编号(“页面 0”“页面 1”等)
例如:32 位机器有多少页(假设页面大小为 4KB)?
答案:2^32 地址 / 2^12 = 2^20 页。
记住 2^10 是 1024,所以 2^20 略大于一百万。
对于 64 位机器,2^64 / 2^12 = 2^52,大约是 10^15 页。
什么是帧?
帧(有时称为“页帧”)是一块物理内存或 RAM(=随机存取存储器)。这种内存有时被称为“主存储器”(与较慢的辅助存储器相对,例如具有较低访问时间的旋转磁盘)
一个帧的字节数与虚拟页面相同。如果 32 位机器有 2^32(4GB)的 RAM,那么在机器的可寻址空间中将有相同数量的帧。64 位机器不太可能有 2^64 字节的 RAM - 你能看出为什么吗?
什么是页面表,它有多大?
页面表是页面到帧之间的映射。例如,页面 1 可能映射到帧 45,页面 2 映射到帧 30。其他帧可能目前未使用或分配给其他正在运行的进程,或者由操作系统内部使用。
一个简单的页面表就是一个数组,int frame = table[ page_num ];
对于一个 32 位机器,每个 4KB 页面的条目需要保存一个帧号-即 20 位,因为我们计算出有 2^20 个帧。每个条目需要 2.5 个字节!实际上,我们将每个条目四舍五入到 4 个字节,并找到这些多余位的用途。每个条目需要 4 个字节 x 2^20 个条目= 4MB 的物理内存用于存储页表。
对于一个 64 位机器,每个 4KB 页面的条目需要 52 位。让我们将每个条目四舍五入到 64 位(8 字节)。有 2^52 个条目,大约需要 2^55 字节(大约 40PB…)哎呀,我们的页表太大了。
在 64 位体系结构中,内存地址是稀疏的,因此我们需要一种机制来减小页表的大小,因为大多数条目永远不会被使用。

这里有一个页表的视觉示例。想象访问一个数组并获取数组元素。
偏移量是什么,它是如何使用的?
记住,我们的页表将页面映射到帧,但每个页面都是一块连续的地址。我们如何计算在特定帧内使用哪个特定字节?解决方案是直接重用虚拟内存地址的最低位。例如,假设我们的进程正在读取以下地址- VirtualAddress = 11110000111100001111000010101010(二进制)
在页面大小为 256 字节的机器上,最低的 8 位(10101010)将被用作偏移量。剩下的上位位将是页号(111100001111000011110000)。
多级页表
多级页面是 64 位体系结构的页表大小问题的一种解决方案。我们将看看最简单的实现-两级页表。每个表都是指向下一级表的指针列表,不需要所有子表都存在。下面是 32 位体系结构的两级页表的示例-
VirtualAddress = 11110000111111110000000010101010 (binary)
|_Index1_|| || | 10 bit Directory index
|_Index2_|| | 10 bit Sub-table index
|__________| 12 bit offset (passed directly to RAM)
在上述方案中,确定帧号需要两次内存读取:使用顶部的 10 位在页表目录中。如果每个条目使用 2 个字节,我们只需要 2KB 来存储整个目录。每个子表将指向物理帧(即需要 4 个字节来存储 20 位)。然而,对于只需要微小内存的进程,我们只需要指定低内存地址(用于堆和程序代码)和高内存地址(用于堆栈)的条目。每个子表是 1024 个条目 x 4 个字节,即每个子表需要 4KB。因此,我们的多级页表的总内存开销已经从 4MB(单级)减少到 3 帧内存(12KB)!
页表会使内存访问变慢吗?(TLB 是什么)
是的-显著!(但由于聪明的硬件,通常不会…)与直接读取或写入内存相比。对于单个页表,我们的机器现在慢了一倍!(需要两次内存访问)对于两级页表,内存访问现在慢了三倍。(需要三次内存访问)
为了克服这种开销,MMU 包括一个最近使用的虚拟页到帧查找的关联缓存。这个缓存被称为 TLB(“转换旁路缓冲区”)。每当需要将虚拟地址转换为物理内存位置时,TLB 与页表并行查询。对于大多数程序的大多数内存访问,TLB 缓存结果的机会很大。但是,如果一个程序没有良好的缓存一致性(例如从许多不同页面的随机内存位置读取),那么 TLB 将不会有结果缓存,现在 MMU 必须使用速度慢得多的页表来确定物理帧。

这可能是如何分割多级页表的方式。
高级帧和页面保护
帧可以在进程之间共享吗?它们可以被专门化吗?
是的!除了存储帧编号之外,页面表还可以用于存储进程是否可以写入或只读特定帧。只读帧可以安全地在多个进程之间共享。例如,C 库指令代码可以在所有动态将代码加载到进程内存中的进程之间共享。每个进程只能读取该内存。这意味着如果您尝试写入内存中的只读页面,您将收到SEGFAULT。这就是为什么有时内存访问会导致段错误,有时不会,这完全取决于您的硬件是否允许您访问。
此外,进程可以使用mmap系统调用与子进程共享页面。mmap是一个有趣的调用,因为它不是将每个虚拟地址绑定到物理帧,而是绑定到其他东西。这个其他东西可以是文件、GPU 单元或者你能想到的任何其他内存映射操作!写入内存地址可能会直接写入设备,或者写入可能会被操作系统暂停,但这是一个非常强大的抽象,因为操作系统通常能够执行优化(多个进程内存映射相同的文件可以让内核创建一个映射)。
页面表中还存储了什么,以及为什么?
除了上面讨论的只读位和使用统计信息之外,通常至少存储只读、修改和执行信息。
什么是页面故障?
页面故障是指运行中的程序尝试访问其地址空间中未映射到物理内存的某些虚拟内存。页面故障也会在其他情况下发生。
有三种类型的页面故障
次要 如果页面尚未映射,但是是有效地址。这可能是sbrk(2)要求的内存,但尚未写入,这意味着操作系统可以在分配空间之前等待第一次写入。操作系统只需创建页面,将其加载到内存中,然后继续进行。
主要 如果页面的映射不在内存中而在磁盘上。这将会将页面交换到内存中,并将另一个页面交换出去。如果这种情况发生频繁,您的程序就会被称为抖动MMU。
无效 当您尝试写入不可写内存地址或读取不可读内存地址时。MMU 会生成一个无效故障,操作系统通常会生成一个SIGSEGV,表示分段违规,这意味着您写入了超出您可以写入的段的位置。
只读位
只读位将页面标记为只读。尝试写入页面将导致页面故障。然后内核将处理页面故障。只读页面的两个例子包括在多个进程之间共享 c 运行时库(出于安全考虑,您不希望允许一个进程修改库);以及写时复制,其中复制页面的成本可以延迟到第一次写入发生时。
脏位
en.wikipedia.org/wiki/Page_table#Page_table_data
脏位允许进行性能优化。从磁盘分页到物理内存,然后再次读取,然后再次分页出去的页面不需要写回磁盘,因为页面没有更改。但是,如果页面在分页后被写入,其脏位将被设置,表示页面必须写回备份存储。这种策略要求备份存储在将页面分页到内存后保留页面的副本。当不使用脏位时,备份存储只需与任何时刻分页出的所有页面的瞬时总大小一样大。当使用脏位时,始终会存在一些页面既存在于物理内存中又存在于备份存储中。
执行位
执行位定义了页面中的字节是否可以作为 CPU 指令执行。通过禁用页面,可以防止恶意存储在进程内存中的代码(例如通过堆栈溢出)被轻易执行。(更多阅读:en.wikipedia.org/wiki/NX_bit#Hardware_background)
了解更多
在 x86 平台上,有关分页和页面位的更低级别的技术讨论可在[wiki.osdev.org/Paging]找到。
管道,第一部分:管道介绍
什么是 IPC?
进程间通信是一个进程与另一个进程交流的任何方式。你已经看到了这种虚拟内存的一种形式!一块虚拟内存可以在父进程和子进程之间共享,从而进行通信。你可能想把那块内存包装在pthread_mutexattr_setpshared(&attrmutex, PTHREAD_PROCESS_SHARED);互斥锁(或者进程范围的互斥锁)中,以防止竞争条件。
还有更多标准的 IPC 方式,比如管道!考虑一下,如果你在终端中输入以下内容
$ ls -1 | cut -d'.' -f1 | uniq | sort | tee dir_contents
以下代码做了什么(如果你愿意,你可以跳过这个)?好吧,它ls当前目录(-1 表示它每行输出一个条目)。然后cut命令取得第一个句点之前的所有内容。Uniq 确保所有行都是唯一的,sort 对它们进行排序,tee 输出到一个文件。
重要的部分是 bash 创建了5 个单独的进程并将它们的标准输出/标准输入与管道连接起来,轨迹看起来像这样。
(0) ls (1)------>(0) cut (1)------->(0) uniq (1)------>(0) sort (1)------>(0) tee (1)
管道中的数字是每个进程的文件描述符,箭头表示重定向或管道输出的位置。
什么是管道?
POSIX 管道几乎像它的真实对应物 - 你可以把字节塞进一端,它们会按照相同的顺序出现在另一端。然而,与真实的管道不同,流动方向总是相同的,一个文件描述符用于读取,另一个用于写入。pipe系统调用用于创建管道。
int filedes[2];
pipe (filedes);
printf("read from %d, write to %d\n", filedes[0], filedes[1]);
这些文件描述符可以与read一起使用 -
// To read...
char buffer[80];
int bytesread = read(filedes[0], buffer, sizeof(buffer));
和write -
write(filedes[1], "Go!", 4);
我怎样使用管道与子进程通信?
使用管道的常见方法是在分叉之前创建管道。
int filedes[2];
pipe (filedes);
pid_t child = fork();
if (child > 0) { /* I must be the parent */
char buffer[80];
int bytesread = read(filedes[0], buffer, sizeof(buffer));
// do something with the bytes read
}
然后子进程可以向父进程发送消息:
if (child == 0) {
write(filedes[1], "done", 4);
}
我可以在单个进程中使用管道吗?
简短回答:是的,但我不确定你为什么要这样做 LOL!
以下是一个向自己发送消息的示例程序:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main() {
int fh[2];
pipe(fh);
FILE *reader = fdopen(fh[0], "r");
FILE *writer = fdopen(fh[1], "w");
// Hurrah now I can use printf rather than using low-level read() write()
printf("Writing...\n");
fprintf(writer,"%d %d %d\n", 10, 20, 30);
fflush(writer);
printf("Reading...\n");
int results[3];
int ok = fscanf(reader,"%d %d %d", results, results + 1, results + 2);
printf("%d values parsed: %d %d %d\n", ok, results[0], results[1], results[2]);
return 0;
}
以这种方式使用管道的问题在于写入管道可能会阻塞,即管道只有有限的缓冲容量。如果管道已满,写入进程将被阻塞!缓冲区的最大大小取决于系统;典型值从 4KB 到 128KB。
int main() {
int fh[2];
pipe(fh);
int b = 0;
#define MESG "..............................."
while(1) {
printf("%d\n",b);
write(fh[1], MESG, sizeof(MESG))
b+=sizeof(MESG);
}
return 0;
}
管道,第二部分:管道编程秘密
管道陷阱
这里有一个完整的例子,但不起作用!子进程每次从管道中读取一个字节并打印出来-但我们从未看到消息!你能看出原因吗?
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
int main() {
int fd[2];
pipe(fd);
//You must read from fd[0] and write from fd[1]
printf("Reading from %d, writing to %d\n", fd[0], fd[1]);
pid_t p = fork();
if (p > 0) {
/* I have a child therefore I am the parent*/
write(fd[1],"Hi Child!",9);
/*don't forget your child*/
wait(NULL);
} else {
char buf;
int bytesread;
// read one byte at a time.
while ((bytesread = read(fd[0], &buf, 1)) > 0) {
putchar(buf);
}
}
return 0;
}
父进程将字节H,i,(空格),C...!发送到管道中(如果管道已满,可能会阻塞)。子进程开始逐个字节读取管道。在上面的情况下,子进程将读取并打印每个字符。但它永远不会离开 while 循环!当没有字符可读时,它会简单地阻塞并等待更多。
调用putchar写出字符,但我们从未刷新stdout缓冲区。也就是说,我们已经将消息从一个进程传输到另一个进程,但它还没有被打印出来。要查看消息,我们可以刷新缓冲区,例如fflush(stdout)(或者如果输出是到终端,则printf("\n"))。更好的解决方案还可以通过检查消息结束标记来退出循环,
while ((bytesread = read(fd[0], &buf, 1)) > 0) {
putchar(buf);
if (buf == '!') break; /* End of message */
}
当子进程退出时,消息将被刷新到终端。
想要使用 printf 和 scanf 与管道吗?使用 fdopen!
POSIX 文件描述符是简单的整数 0,1,2,3…在 C 库级别,C 用缓冲区和有用的函数如 printf 和 scanf 包装这些,所以我们可以轻松地打印或解析整数、字符串等。如果你已经有了一个文件描述符,那么你可以使用fdopen将其自己“包装”成一个 FILE 指针:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main() {
char *name="Fred";
int score = 123;
int filedes = open("mydata.txt", "w", O_CREAT, S_IWUSR | S_IRUSR);
FILE *f = fdopen(filedes, "w");
fprintf(f, "Name:%s Score:%d\n", name, score);
fclose(f);
对于写入文件来说,这是不必要的-只需使用fopen,它与open和fdopen相同。但是对于管道,我们已经有了一个文件描述符-所以现在是使用fdopen的好时机!
这里有一个使用管道的完整例子,几乎可以工作!你能发现错误吗?提示:父进程从未打印任何内容!
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main() {
int fh[2];
pipe(fh);
FILE *reader = fdopen(fh[0], "r");
FILE *writer = fdopen(fh[1], "w");
pid_t p = fork();
if (p > 0) {
int score;
fscanf(reader, "Score %d", &score);
printf("The child says the score is %d\n", score);
} else {
fprintf(writer, "Score %d", 10 + 10);
fflush(writer);
}
return 0;
}
请注意,(未命名的)管道资源将在子进程和父进程都退出后消失。在上面的例子中,子进程将从管道发送字节,父进程将从管道接收字节。然而,从未发送换行符,因此fscanf将继续请求字节,因为它正在等待行结束,即它将永远等待!修复方法是确保我们发送一个换行符,这样fscanf将返回。
change: fprintf(writer, "Score %d", 10 + 10);
to: fprintf(writer, "Score %d\n", 10 + 10);
那我们也需要fflush吗?
是的,如果你希望你的字节立即发送到管道中!在本课程开始时,我们假设文件流始终是行缓冲,即 C 库每次发送换行符时都会刷新其缓冲区。实际上,这只对终端流有效-对于其他文件流,C 库尝试通过仅在其内部缓冲区满或文件关闭时刷新来提高性能。
我什么时候需要两个管道?
如果你需要异步地向子进程发送和接收数据,那么需要两个管道(每个方向一个)。否则,子进程将尝试读取自己的数据,这些数据是为父进程准备的(反之亦然)!
关闭管道的陷阱
当没有进程在监听时,进程会收到信号 SIGPIPE!来自 pipe(2)手册页-
If all file descriptors referring to the read end of a pipe have been closed,
then a write(2) will cause a SIGPIPE signal to be generated for the calling process.
提示:注意只有写入者(不是读取者)可以使用此信号。为了通知读取者写入者正在关闭管道的端口,你可以写入自己的特殊字节(例如 0xff)或消息("再见!")
这里有一个捕捉这个信号的例子,但不起作用!你能看出原因吗?
#include <stdio.h>
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
void no_one_listening(int signal) {
write(1, "No one is listening!\n", 21);
}
int main() {
signal(SIGPIPE, no_one_listening);
int filedes[2];
pipe(filedes);
pid_t child = fork();
if (child > 0) {
/* I must be the parent. Close the listening end of the pipe */
/* I'm not listening anymore!*/
close(filedes[0]);
} else {
/* Child writes messages to the pipe */
write(filedes[1], "One", 3);
sleep(2);
// Will this write generate SIGPIPE ?
write(filedes[1], "Two", 3);
write(1, "Done\n", 5);
}
return 0;
}
上面代码中的错误是仍然有一个管道的读取者!子进程仍然保持着管道的第一个文件描述符,并记住规范?所有读取者必须关闭。
在分叉时,*关闭子进程和父进程中每个管道的不必要(未使用)端口是常见做法。例如,父进程可能关闭读取端口,子进程可能关闭写入端口(如果有两个管道,则反之亦然)
是什么填满了管道?当管道变满时会发生什么?
当写入者向管道写入过多而读者没有读取时,管道会被填满。当管道变满时,所有写入都会失败,直到发生读取。即使在这种情况下,如果管道还有一点空间但不足以容纳整个消息,写入也可能部分失败。
为了避免这种情况,通常有两种方法。要么增加管道的大小。或者更常见的是,修复你的程序设计,使得管道不断被读取。
管道是否进程安全?
是的!管道写入是原子的,直到管道的大小。这意味着如果两个进程尝试写入同一个管道,内核会使用管道的内部互斥锁来锁定,进行写入,然后返回。唯一需要注意的是当管道即将变满时。如果两个进程尝试写入,而管道只能满足部分写入,那么该管道写入就不是原子的–要小心!
管道的生命周期
无名管道(到目前为止我们见过的那种)存在于内存中(不占用任何磁盘空间),是一种简单高效的进程间通信(IPC)形式,对于流数据和简单消息非常有用。一旦所有进程关闭,管道资源就会被释放。
使用mkfifo创建命名管道是无名管道的一种替代方法。
命名管道
我如何创建命名管道?
从命令行:mkfifo 从 C 语言:int mkfifo(const char *pathname, mode_t mode);
你给它路径名和操作模式,它就准备好了!命名管道在磁盘上不占用空间。当操作系统告诉你有一个命名管道时,它实际上是在告诉你它会创建一个指向命名管道的无名管道,就是这样!没有额外的魔法。这只是为了编程方便,如果进程在没有分叉的情况下启动(这意味着无法为无名管道的子进程获取文件描述符)。
为什么我的管道挂起?
在命名管道上的读写会一直挂起,直到至少有一个读者和一个写者,记住这一点
1$ mkfifo fifo
1$ echo Hello > fifo
# This will hang until I do this on another terminal or another process
2$ cat fifo
Hello
当在命名管道上调用任何open时,内核会阻塞,直到另一个进程调用相反的 open。也就是说,echo 调用open(.., O_RDONLY),但是它会阻塞,直到 cat 调用open(.., O_WRONLY),然后程序才被允许继续。
命名管道的竞争条件。
以下程序有什么问题?
//Program 1
int main(){
int fd = open("fifo", O_RDWR | O_TRUNC);
write(fd, "Hello!", 6);
close(fd);
return 0;
}
//Program 2
int main() {
char buffer[7];
int fd = open("fifo", O_RDONLY);
read(fd, buffer, 6);
buffer[6] = '\0';
printf("%s\n", buffer);
return 0;
}
这可能永远不会打印 hello,因为存在竞争条件。由于你在第一个进程中以两种权限打开了管道,open 不会等待读者,因为你告诉操作系统你是读者!有时它看起来像是工作的,因为代码的执行看起来像这样。
| 进程 1 | 进程 2 |
|---|---|
open(O_RDWR) & write() | |
open(O_RDONLY) & read() | |
close() & exit() | |
print() & exit() |
有时候不会
| 进程 1 | 进程 2 |
|---|---|
open(O_RDWR) & write() | |
close() & exit() | (命名管道被销毁) |
(无限期阻塞)open(O_RDONLY) |
文件,第一部分:处理文件
两种类型的文件
在 Linux 上,有两种文件抽象。第一种是 Linux 的fd级别抽象,这意味着你可以使用
-
打开 -
读 -
写 -
关闭 -
lseek -
fcntl…
等等。Linux 接口非常强大和富有表现力,但有时我们需要可移植性(例如,如果我们在为 Mac 或 Windows 编写代码)。这就是 C 的抽象发挥作用的地方。在不同的操作系统上,C 使用低级函数来创建一个文件的包装器,你可以在任何地方使用,这意味着 Linux 上的 C 使用上述调用。C 有以下几种
-
fopen -
fread或fgetc/fgets或fscanf -
fwrite或fprintf -
fclose -
fflush
但你无法获得 Linux 通过系统调用给你的表达能力,你可以在它们之间进行转换,使用int fileno(FILE* stream)和FILE* fdopen(int fd...)。
另一个重要的方面要注意的是 C 文件是缓冲的,这意味着它们的内容可能不会立即被写入。你可以通过 C 选项来改变这一点。
我怎么知道文件有多大?
对于小于 long 的大小的文件,使用 fseek 和 ftell 是一种简单的方法来实现这一点:
移动到文件的末尾并找出当前位置。
fseek(f, 0, SEEK_END);
long pos = ftell(f);
这告诉我们文件中的当前位置,以字节为单位 - 即文件的长度!
fseek也可以用来设置绝对位置。
fseek(f, 0, SEEK_SET); // Move to the start of the file
fseek(f, posn, SEEK_SET); // Move to 'posn' in the file.
所有父进程或子进程中的未来读写操作都将遵守这个位置。请注意,从文件中写入或读取将改变当前位置。
查看 fseek 和 ftell 的 man 页面以获取更多信息。
但尽量不要这样做
注意:这在通常情况下是不推荐的,因为 C 语言有一个怪癖。这个怪癖是 long 只需要4 个字节大,这意味着 ftell 能返回的最大大小略小于 2GB(而我们现在知道我们的文件可能是数百 GB 甚至分布式文件系统上的 TB)。我们应该怎么办呢?使用stat!我们将在后面的部分介绍 stat,但这里有一些代码可以告诉你文件的大小
struct stat buf;
if(stat(filename, &buf) != -1){
return -1;
}
return (ssize_t)buf.st_size;
buf.st_size 的类型是 off_t,对于极大的文件来说足够大。
如果子进程使用fclose或close关闭文件流会发生什么?
关闭文件流对每个进程都是独特的。其他进程可以继续使用自己的文件句柄。记住,当创建一个子进程时,甚至文件的相对位置也会被复制过去。
文件的 mmap 怎么样?
mmap 的一个常见用途是将文件映射到内存。这并不意味着文件会立即被 malloc 到内存中。以下面的代码为例。
int fd = open(...); //File is 2 Pages
char* addr = mmap(..fd..);
addr[0] = 'l';
内核可能会说:“好的,我看到你想要将文件映射到内存中,所以我将在你的地址空间中保留一些文件长度的空间”。这意味着当你写入 addr[0]时,实际上是在文件的第一个字节上写入。内核实际上也可以进行一些优化。它可能一次只加载一页,因为如果文件有 1024 页;你可能只访问 3 或 4 页,这样加载整个文件就是浪费时间(这就是为什么页面错误是如此强大的原因!它们让操作系统控制你使用文件的程度)。
对于每个 mmap
记住,一旦你完成了mmap,你需要munmap告诉操作系统你不再使用分配的页面,这样操作系统可以将它写回磁盘,并在以后需要 malloc 时将地址还给你。
调度,第一部分:调度进程
考虑调度。
CPU 调度是有效地选择要在系统 CPU 核心上运行的进程的问题。在繁忙的系统中,准备运行的进程将比 CPU 核心多,因此系统内核必须评估应该调度哪些进程在 CPU 上运行,以及应该将哪些进程放在就绪队列中以便稍后执行。
多线程和多 CPU 核心的额外复杂性被认为是对这个初始阐述的干扰,因此在这里被忽略。
对于非母语的人来说,另一个需要注意的是“时间”一词的双重含义:单词“时间”可以在时钟和经过的持续时间上下文中使用。例如,“第一个进程的到达时间是上午 9:00。”和“算法的运行时间为 3 秒。”
调度如何衡量,哪种调度程序最好?
调度影响系统的性能,特别是系统的延迟和吞吐量。吞吐量可以通过系统值来衡量,例如 I/O 吞吐量-每秒写入的字节数,或者每单位时间可以完成的小进程数量,或者使用更高级的抽象,例如每分钟处理的客户记录数量。延迟可以通过响应时间(进程开始发送响应之前的经过时间)或等待时间或周转时间(完成任务所经过的时间)来衡量。不同的调度程序提供不同的优化权衡,可能适用于所需的使用-并非所有可能的环境和目标都有最佳的调度程序。例如,“最短作业优先”将最小化所有作业的总等待时间,但在交互(UI)环境中,最好是最小化响应时间(以牺牲一些吞吐量),而 FCFS 似乎直观公平且易于实现,但受到车队效应的影响。
到达时间是什么?
进程首次到达就绪队列并准备开始执行的时间。如果 CPU 空闲,到达时间也将是执行的开始时间。
什么是抢占?
没有抢占,进程将运行,直到无法再利用 CPU。例如,以下条件将从 CPU 中移除进程,并使 CPU 可供其他进程调度:进程因信号终止,被阻塞等待并发原语,或正常退出。因此,一旦进程被调度,即使另一个具有较高优先级(例如更短的作业)的进程出现在就绪队列上,它也将继续运行。
通过抢占,如果就绪队列中添加了一个更可取的进程,现有进程可能会立即被移除。例如,假设在 t=0 时,使用最短作业优先调度程序有两个进程(P1 P2),执行时间分别为 10 和 20 毫秒。P1 被调度。P1 立即创建一个新的进程 P3,执行时间为 5 毫秒,将其添加到就绪队列。如果没有抢占,P3 将在 10 毫秒后运行(在 P1 完成后)。有了抢占,P1 将立即从 CPU 中驱逐,并放回就绪队列,CPU 将执行 P3。
哪些调度程序会导致饥饿?
任何使用优先级形式的调度程序都可能导致饥饿,因为较早的进程可能永远不会被调度运行(分配 CPU)。例如,使用 SJF,如果系统继续有许多短作业要调度,较长的作业可能永远不会被调度。这一切取决于调度程序的类型。
为什么进程(或线程)会被放置在就绪队列上?
当进程能够使用 CPU 时,进程将被放置在就绪队列上。一些例子包括:
-
进程被阻塞等待存储或套接字的“读”完成,现在数据可用。
-
一个新进程已经创建并准备好开始。
-
一个进程线程被阻塞在同步原语(条件变量、信号量、互斥锁)上,但现在可以继续。
-
一个进程被阻塞,等待系统调用完成,但已经传递了一个信号,信号处理程序需要运行。
考虑线程时可以生成类似的例子。
效率的度量
开始时间是进程的挂钟开始时间(CPU 开始处理它)结束时间是进程的结束挂钟(CPU 完成进程)运行时间是所需的 CPU 时间总量到达时间是进程进入调度程序的时间(CPU 可能不开始处理它)
什么是“周转时间”?
从进程到达到结束的总时间。
周转时间=结束时间-到达时间
什么是“响应时间”?
从进程到达到 CPU 实际开始处理它所需的总延迟(时间)。
响应时间=开始时间-到达时间
什么是“等待时间”?
等待时间是总等待时间,即进程在就绪队列上的总时间。一个常见的错误是认为它只是在就绪队列中的初始等待时间。
如果一个不进行 I/O 的 CPU 密集型进程需要 7 分钟的 CPU 时间才能完成,但需要 9 分钟的挂钟时间才能完成,我们可以得出结论,它在就绪队列中等待了 2 分钟。在这 2 分钟内,进程准备好运行,但没有分配 CPU。作业等待的时间是 2 分钟,无论作业等待的时间是什么时候。
等待时间=(结束时间-到达时间)-运行时间
什么是车队效应?
“车队效应是指 I/O 密集型进程不断积压,等待占用 CPU 的 CPU 密集型进程。这导致 I/O 性能不佳,即使对于 CPU 需求很小的进程也是如此。”
假设 CPU 当前被分配给一个 CPU 密集型任务,并且有一组 I/O 密集型进程在就绪队列中。这些进程只需要很少的 CPU 时间,但它们无法继续进行,因为它们正在等待 CPU 密集型任务从处理器中移除。这些进程会饿死,直到 CPU 绑定的进程释放 CPU。但 CPU 很少会被释放(例如,在 FCFS 调度程序的情况下,我们必须等到进程因 I/O 请求而被阻塞)。I/O 密集型进程现在可以满足它们的 CPU 需求,因为它们的 CPU 需求很小,而 CPU 又被分配给 CPU 密集型进程。因此,整个系统的 I/O 性能会因所有进程的 CPU 需求饥饿而受到间接影响。
这种效应通常在 FCFS 调度程序的情况下讨论,但是循环调度程序也可能出现长时间量的车队效应。
Linux 调度
截至 2016 年 2 月,Linux 默认使用完全公平调度程序进行 CPU 调度,使用 I/O 调度的“BFQ”进行预算公平调度。适当的调度对吞吐量和延迟有重大影响。延迟对交互式和软实时应用程序特别重要,例如音频和视频流。有关更多信息,请参见此处的讨论和比较基准[lkml.org/lkml/2014/5/27/314]。
这是 CFS 的调度方式
-
CPU 使用进程的虚拟运行时间(运行时间/优先级值)和睡眠公平性(如果进程正在等待某些东西,当它完成等待时给它 CPU)创建红黑树。
-
(优先级值是内核给予某些进程优先级的方式,值越低,优先级越高)
-
内核根据此度量选择最低的度量,并安排该进程作为下一个运行,将其从队列中移除。由于红黑树是自平衡的,此操作保证为 O ( l o g ( n ) ) O(log(n)) O(log(n))(选择最小进程是相同的运行时间)
尽管它被称为公平调度器,但存在相当多的问题。
-
被调度的进程组可能负载不平衡,因此调度器会大致分配负载。当另一个 CPU 空闲时,它只能查看组调度的平均负载,而不是单独的核心。因此,只要平均负载正常,空闲的 CPU 可能不会接手一个长时间运行的 CPU 的工作。
-
如果一组进程在非相邻的核心上运行,那么就会出现问题。如果两个核心的距离超过一个跳跃,负载平衡算法甚至不会考虑那个核心。这意味着如果一个 CPU 空闲,而另一个 CPU 的工作量超过一个跳跃的距离,它不会接手这个工作(可能已经修复)。
-
线程在一组核心上休眠后,醒来时只能在它休眠的核心上被调度。如果这些核心现在很忙,那么就会出现问题。
调度,第二部分:调度进程:算法
一些著名的调度算法是什么?
对于所有的例子,
进程 1:运行时间 1000 毫秒
进程 2:运行时间 2000 毫秒
进程 3:运行时间 3000 毫秒
进程 4:运行时间 4000 毫秒
进程 5:运行时间 5000 毫秒
最短作业优先(SJF)
-
P1 到达:0 毫秒
-
P2 到达:0 毫秒
-
P3 到达:0 毫秒
-
P4 到达:0 毫秒
-
P5 到达:0 毫秒
所有进程在开始时到达,调度程序安排具有最短总 CPU 时间的作业。明显的问题是,这个调度程序需要在运行程序之前知道这个程序将在未来的时间内运行多长时间。
技术说明:实际的 SJF 实现不会使用进程的总执行时间,而是使用突发时间(包括进程不再准备运行之前的未来计算执行的总 CPU 时间)。可以通过使用基于先前突发时间的指数衰减加权滚动平均值来估计预期的突发时间,但是为了简化讨论,我们将在这里使用进程的总运行时间作为突发时间的代理。
优点
- 较短的作业往往会先运行
缺点
- 需要算法是全知的
抢占式最短作业优先(PSJF)
抢占式最短作业优先类似于最短作业优先,但如果新作业的运行时间比进程的剩余运行时间短,则运行该作业。(如果像我们的例子一样相等,我们的算法可以选择)。调度程序使用进程的总运行时间,如果要使用最短剩余时间,那就是 PSJF 的一个变体,称为最短剩余时间优先。

-
P2 在 0 毫秒
-
P1 在 1000 毫秒
-
P5 在 3000 毫秒
-
P4 在 4000 毫秒
-
P3 在 5000 毫秒
我们的算法是这样的。它运行 P2,因为它是唯一要运行的东西。然后 P1 在 1000 毫秒时进来,P2 运行了 2000 毫秒,所以我们的调度程序会抢占性地停止 P2,并让 P1 一直运行(这完全取决于算法,因为时间相等)。然后,P5 进来了–因为没有进程在运行,调度程序将运行进程 5。P4 进来了,因为运行时间相等于 P5,调度程序停止 P5 并运行 P4。最后 P3 进来,抢占 P4,并运行到完成。然后 P4 运行,然后 P5 运行。
优点
- 确保较短的作业先运行
缺点
- 需要再次知道运行时间
**注意:**出于历史原因,该算法比较总运行时间而不是剩余运行时间。如果要考虑剩余时间,将使用抢占式最短剩余时间优先(PSRTF)。
先来先服务(FCFS)
-
P2 在 0 毫秒
-
P1 在 1000 毫秒
-
P5 在 3000 毫秒
-
P4 在 4000 毫秒
-
P3 在 5000 毫秒
进程按到达顺序进行调度。FCFS 的一个优点是调度算法很简单:就绪队列只是一个 FIFO(先进先出)队列。FCFS 遭受护航效应的影响。
这里 P2 到达,然后是 P1 到达,然后是 P5,然后是 P4,然后是 P3。您可以看到 P5 的护航效应。
优点
- 简单实现
缺点
- 长时间运行的进程可能会阻塞所有其他进程
轮转法(RR)
进程按照它们在就绪队列中的到达顺序进行调度。但是在一个小的时间步长之后,正在运行的进程将被强制从运行状态中移除,并放回就绪队列。这确保了长时间运行的进程不能使所有其他进程无法运行。进程在返回就绪队列之前可以执行的最长时间称为时间量子。在时间量子较大的极限情况下(时间量子长于所有进程的运行时间),轮转法将等效于 FCFS。

-
P1 到达:0 毫秒
-
P2 到达:0 毫秒
-
P3 到达:0 毫秒
-
P4 到达:0 毫秒
-
P5 到达:0 毫秒
量子=1000 毫秒
在这里,所有进程同时到达。P1 运行 1 个量子,然后完成。P2 运行一个量子;然后,它被停止给 P3。在所有其他进程运行一个量子后,我们循环回到 P2,直到所有进程都完成。
优点
- 确保公平的概念
缺点
- 大量进程=大量切换
优先级
进程按优先级值的顺序进行调度。例如,导航进程可能比日志记录进程更重要执行。
IPC 复习问题
主题
虚拟内存页表 MMU/TLB 地址转换页面错误帧/页单级与多级页表计算多级页表的偏移管道管道读写端写入零读取管道从零写入管道命名管道和无命名管道缓冲区大小/原子性调度算法效率衡量
问题
-
虚拟内存是什么?
-
以下是什么以及它们的目的是什么?
-
翻译旁路缓冲区
-
物理地址
-
内存管理单元。多级页表。帧号。页号和页偏移。
-
脏位
-
NX 位
-
-
什么是页表?物理帧呢?页面是否总是需要指向物理帧?
-
什么是页面错误?有哪些类型?什么时候会导致段错误?
-
单级页表有什么优点?缺点?多级表呢?
-
多级表在内存中是什么样子的?
-
如何确定页面偏移中使用了多少位?
-
给定 64 位地址空间,4kb 页和帧,以及 3 级页表,虚拟页号 1,VPN2,VPN3 和偏移分别有多少位?
-
什么是管道?如何创建管道?
-
SIGPIPE 是在什么时候传递给进程的?
-
在什么条件下调用管道上的 read()会阻塞?在什么条件下 read()会立即返回 0?
-
命名管道和无命名管道之间有什么区别?
-
管道是线程安全的吗?
-
编写一个使用 fseek 和 ftell 来用’X’替换文件的中间字符的函数
-
编写一个创建管道并使用 write 发送 5 个字节“HELLO”到管道的函数。返回管道的读文件描述符。
-
当您 mmap 文件时会发生什么?
-
为什么不建议使用 ftell 获取文件大小?应该如何替代?
-
什么是调度?
-
周转时间是什么?响应时间?等待时间?
-
什么是护航效应?
-
哪些算法平均具有最佳的周转/响应/等待时间
八、网络连接
POSIX,第一部分:错误处理
什么是 POSIX 错误处理?
在其他语言中,你可能会看到异常处理的实现。尽管在 C 中你技术上可以使用它们(你保留一个非常 try/catch 块的堆栈,并使用setjmp和longjmp分别进入这些块),但 C 中的错误处理通常是用 posix 错误处理来完成的,代码通常看起来像这样。
int ret = some_system_call()
if(ret == ERROR_CODE){
switch(errno){
// Do different stuff based on the errno number.
}
}
在内核中,使用goto来清理应用程序的不同部分是非常常见的。你不应该使用 goto,因为它会使代码更难阅读。内核中的 goto 是出于必要性而存在的,所以不要学习它。
errno是什么,何时设置它?
POSIX 定义了一个特殊的整数errno,当系统调用失败时会设置它。errno的初始值是零(即没有错误)。当系统调用失败时,它通常会返回-1 来指示错误并设置errno。
多线程呢?
每个线程都有自己的errno副本。这非常有用;否则一个线程的错误会干扰另一个线程的错误状态。
errno何时重置为零?
除非你明确将它重置为零!当系统调用成功时,它们不会重置errno的值。
这意味着你只应该依赖 errno 的值,如果你知道一个系统调用失败了(例如它返回了-1)。
使用errno的注意事项和最佳实践是什么?
当复杂的错误处理使用库调用或系统调用可能改变errno的值时要小心。实际上,将errno的值复制到一个 int 变量中更安全:
// Unsafe - the first fprintf may change the value of errno before we use it!
if (-1 == sem_wait(&s)) {
fprintf(stderr, "An error occurred!");
fprintf(stderr, "The error value is %d\n", errno);
}
// Better, copy the value before making more system and library calls
if (-1 == sem_wait(&s)) {
int errno_saved = errno;
fprintf(stderr, "An error occurred!");
fprintf(stderr, "The error value is %d\n", errno_saved);
}
同样,如果你的信号处理程序进行了任何系统或库调用,那么最好的做法是保存 errno 的原始值,并在返回之前恢复该值:
void handler(int signal) {
int errno_saved = errno;
// make system calls that might change errno
errno = errno_saved;
}
如何打印出与特定错误号相关联的字符串消息?
使用strerror来获取错误值的简短(英文)描述
char *mesg = strerror(errno);
fprintf(stderr, "An error occurred (errno=%d): %s", errno, mesg);
perror 和 strerror 有什么关系?
在之前的页面中,我们使用 perror 将错误打印到标准错误输出。使用strerror,我们现在可以编写一个简单的perror实现:
void perror(char *what) {
fprintf(stderr, "%s: %s\n", what, strerror(errno));
}
使用 strerror 的注意事项是什么?
不幸的是,strerror不是线程安全的。换句话说,两个线程不能同时调用它!
有两种解决方法:首先,我们可以使用互斥锁来定义一个临界区和一个本地缓冲区。所有调用strerror的地方都应该使用相同的互斥锁。
pthread_mutex_lock(&m);
char *result = strerror(errno);
char *message = malloc(strlen(result) + 1);
strcpy(message, result);
pthread_mutex_unlock(&m);
fprintf(stderr, "An error occurred (errno=%d): %s", errno, message);
free(message);
或者使用不太便携但线程安全的strerror_r
EINTR 是什么?对 sem_wait、read、write 有什么影响?
当信号(例如 SIGCHLD、SIGPIPE 等)传递到进程时,一些系统调用可能会被中断。此时,系统调用可能会返回而不执行任何操作!例如,可能没有读/写字节,信号量等待可能没有等待。
这种中断可以通过检查返回值和errno是否为 EINTR 来检测。在这种情况下,应该重试系统调用。通常会看到以下类型的循环,它包装了一个系统调用(比如 sem_wait)。"
while ((-1 == systemcall(...)) && (errno == EINTR)) { /* repeat! */}
小心写成== EINTR,而不是= EINTR。
或者,如果结果值需要稍后使用…
while ((-1 == (result = systemcall(...))) && (errno == EINTR)) { /* repeat! */}
在 Linux 上,调用read和write到本地磁盘通常不会返回 EINTR(相反,函数会自动为您重新启动)。然而,对应于网络流的文件描述符上调用read和write可能会返回 EINTR。
哪些系统调用可能会被中断并需要包装?
使用手册页!手册页包括系统调用可能设置的错误(即 errno 值)列表。一个经验法则是’慢’(阻塞)调用(例如写入套接字)可能会被中断,但快速的非阻塞调用(例如 pthread_mutex_lock)不会。
来自 Linux 信号 7 手册页。
"如果在系统调用或库函数调用被阻塞时调用了信号处理程序,那么:
-
信号处理程序返回后,调用将自动重新启动;或者
-
调用失败,并显示错误 EINTR。发生这两种行为取决于接口以及信号处理程序是否使用了 SA_RESTART 标志(请参阅 sigaction(2))。这些细节在 UNIX 系统中各不相同;以下是 Linux 的细节。
如果对以下接口之一的阻塞调用被信号处理程序中断,那么如果使用了 SA_RESTART 标志,则在信号处理程序返回后,调用将自动重新启动;否则,调用将失败,并显示错误 EINTR:
- 对“慢”设备的 read(2),readv(2),write(2),writev(2)和 ioctl(2)调用。 “慢”设备是指 I/O 调用可能会无限期地阻塞的设备,例如终端,管道或套接字。(根据此定义,磁盘不是慢设备。)如果对慢设备的 I/O 调用在被信号处理程序中断时已经传输了一些数据,则调用将返回成功状态(通常是传输的字节数)。
请注意,很容易相信设置’SA_RESTART’标志就足以使整个问题消失。不幸的是,这并不是真的:仍然有可能有系统调用会提前返回并设置EINTR!有关详细信息,请参阅signal(7)。
Errno 异常?
有一些 POSIX 实用程序有自己的 errno。其中一个是当您调用getaddrinfo函数来检查错误并将其转换为字符串时,可以使用gai_strerror。不要混淆它们!
网络,第一部分:介绍
注意:显而易见,本页不是IP、UDP 或 TCP 的完整描述!相反,这是一个简短的介绍,足以让我们在以后的讲座中建立在这些概念之上。
“IP4”“IP6”是什么?
以下是互联网协议(IP)的“30 秒”介绍-这是从一台机器向另一台机器发送信息包(“数据报”)的主要方法。
“IP4”,或更准确地说,“IPv4”是互联网协议的第 4 版,描述了如何在网络上从一台机器发送信息包到另一台机器。大约 95%的互联网数据包今天都是 IPv4 数据包。IPv4 的一个重要限制是源地址和目的地址被限制为 32 位(IPv4 是在当时认为 4 亿台设备连接到同一网络是不可想象的时候设计的,或者至少不值得增加数据包大小)
每个 IPv4 数据包包括一个非常小的头部-通常为 20 字节(更准确地说,“八位字节”),其中包括源地址和目的地址。
从概念上讲,源地址和目的地址可以分为两部分:网络号(高位)和低位表示该网络上特定主机号。
更新的数据包协议“IPv6”解决了 IPv4 的许多限制(例如,使路由表更简单和 128 位地址),但是不到 5%的网络流量是基于 IPv6 的。
一台机器可以有一个 IPv6 地址和一个 IPv4 地址。
“没有像 127.0.0.1 这样的地方”!
特殊的 IPv4 地址是127.0.0.1,也称为本地主机。发送到 127.0.0.1 的数据包永远不会离开机器;该地址被指定为同一台机器。
请注意,32 位地址被分成 4 个八位字节,即点表示法中的每个数字可以是 0-255。但是 IPv4 地址也可以写成整数。
…和…“没有像 0:0:0:0:0:0:0:1 这样的地方”?
IPv6 中的 128 位本地主机地址是0:0:0:0:0:0:0:1,可以用缩写形式::1来表示。
什么是端口?
要使用 IPv4(或 IPv6)向互联网上的主机发送数据报(数据包),您需要指定主机地址和端口。端口是一个无符号的 16 位数字(即最大端口号为 65535)。
一个进程可以监听特定端口上的传入数据包。但是只有具有超级用户(root)访问权限的进程才能监听端口<1024。任何进程都可以监听 1024 或更高的端口。
经常使用的端口是端口 80:端口 80 用于未加密的 http 请求(即网页)。例如,如果一个网络浏览器连接到www.bbc.com/,那么它将连接到端口 80。
UDP 是什么?它什么时候使用?
UDP 是建立在 IPv4 和 IPv6 之上的无连接协议。它非常简单易用:决定目的地址和端口,然后发送数据包!然而,网络不能保证数据包是否会到达。如果网络拥挤,数据包(也称为数据报)可能会丢失。数据包可能会重复或无序到达。
在两个远程数据中心之间,典型的数据包丢失率为 3%。
UDP 的典型用例是当接收最新数据比接收所有数据更重要时。例如,游戏可能会发送玩家位置的持续更新。流媒体视频信号可能使用 UDP 发送图片更新。
TCP 是什么?它什么时候使用?
TCP 是建立在 IPv4 和 IPv6 之上的基于连接的协议(因此可以被描述为“TCP/IP”或“TCP over IP”)。TCP 在两台机器之间创建了一个“管道”,并抽象了互联网的低级数据包特性:因此,在大多数情况下,从一台机器发送的字节最终会到达另一端,而不会重复或丢失数据。
TCP 将自动管理重发数据包,忽略重复数据包,重新排列无序数据包,并改变发送数据包的速率。
TCP 的三次握手被称为 SYN,SYN-ACK 和 ACK。本页面上的图表有助于理解 TCP 握手。TCP 握手
今天互联网上的大多数服务(例如 Web 服务)使用 TCP,因为它隐藏了互联网更低级别的数据包特性的复杂性。
网络,第二部分:使用 getaddrinfo
如何使用getaddrinfo将主机名转换为 IP 地址?
函数getaddrinfo可以将人类可读的域名(例如www.illinois.edu)转换为 IPv4 和 IPv6 地址。实际上,它将返回一个 addrinfo 结构的链表:
struct addrinfo {
int ai_flags;
int ai_family;
int ai_socktype;
int ai_protocol;
socklen_t ai_addrlen;
struct sockaddr *ai_addr;
char *ai_canonname;
struct addrinfo *ai_next;
};
使用起来非常简单。例如,假设你想找出www.bbc.com的网页服务器的数值 IPv4 地址。我们分两个阶段来做。首先使用 getaddrinfo 构建可能连接的链表。其次使用getnameinfo将二进制地址转换为可读形式。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
struct addrinfo hints, *infoptr; // So no need to use memset global variables
int main() {
hints.ai_family = AF_INET; // AF_INET means IPv4 only addresses
int result = getaddrinfo("www.bbc.com", NULL, &hints, &infoptr);
if (result) {
fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(result));
exit(1);
}
struct addrinfo *p;
char host[256],service[256];
for(p = infoptr; p != NULL; p = p->ai_next) {
getnameinfo(p->ai_addr, p->ai_addrlen, host, sizeof(host), service, sizeof(service), NI_NUMERICHOST);
puts(host);
}
freeaddrinfo(infoptr);
return 0;
}
典型输出:
212.58.244.70
212.58.244.71
www.cs.illinois.edu如何转换为 IP 地址?
神奇!不是开玩笑,使用了一个名为“DNS”(域名服务)的系统。如果一台机器本地没有答案,那么它会向本地 DNS 服务器发送一个 UDP 数据包。这个服务器反过来可能会查询其他上游 DNS 服务器。
DNS 安全吗?
DNS 本身很快,但不安全。DNS 请求未加密,容易受到“中间人”攻击的影响。例如,咖啡店的互联网连接可以轻松篡改您的 DNS 请求,并为特定域返回不同的 IP 地址
如何连接到 TCP 服务器(例如网页服务器)?
TODO 有三个基本的系统调用,你需要连接到远程机器:
getaddrinfo -- Determine the remote addresses of a remote host
socket -- Create a socket
connect -- Connect to the remote host using the socket and address information
如果getaddrinfo调用成功,它将创建一个addrinfo结构的链表,并将给定的指针设置为指向第一个。
套接字调用创建一个传出套接字并返回一个描述符(有时称为“文件描述符”),可以与read和write等一起使用。在这个意义上,它是网络模拟open打开文件流的功能-只是我们还没有将套接字连接到任何地方!
最后,连接调用尝试连接到远程机器。我们传递原始套接字描述符,以及存储在 addrinfo 结构中的套接字地址信息。有不同类型的套接字地址结构(例如 IPv4 与 IPv6),可能需要更多的内存。因此,除了传递指针外,还传递了结构的大小:
// Pull out the socket address info from the addrinfo struct:
connect(sockfd, p->ai_addr, p->ai_addrlen)
如何释放为 addrinfo 结构的链表分配的内存?
在清理代码的一部分上调用freeaddrinfo,在最顶层的addrinfo结构上:
void freeaddrinfo(struct addrinfo *ai);
如果 getaddrinfo 失败,我可以使用strerror打印出错误吗?
不。使用getaddrinfo进行错误处理有点不同:
-
返回值就是错误代码(即不要使用
errno) -
使用
gai_strerror获取等效的简短英文错误文本:
int result = getaddrinfo(...);
if(result) {
const char *mesg = gai_strerror(result);
...
}
我可以只请求 IPv4 或 IPv6 连接吗?仅限 TCP?
是的!使用传递给getaddrinfo的 addrinfo 结构来定义你想要的连接类型。
例如,要指定基于 IPv6 的基于流的协议:
struct addrinfo hints;
memset(hints, 0, sizeof(hints));
hints.ai_family = AF_INET6; // Only want IPv6 (use AF_INET for IPv4)
hints.ai_socktype = SOCK_STREAM; // Only want stream-based connection
关于使用gethostbyname的代码示例呢?
旧函数gethostbyname已被弃用;这是将主机名转换为 IP 地址的旧方法。端口地址仍然需要使用 htons 函数手动设置。使用更新的getaddrinfo更容易编写支持 IPv4 和 IPv6 的代码
是这么简单!?
是也不是。创建一个简单的 TCP 客户端很容易-但是网络通信提供了许多不同级别的抽象,以及可以在每个抽象级别设置的几个属性和选项(例如,我们还没有讨论可以操纵套接字选项的setsockopt)。有关更多信息,请参阅此指南。
网络,第三部分:构建一个简单的 TCP 客户端
套接字
int socket(int domain, int type, int protocol);
Socket 使用域(通常为 IPv4 的 AF_INET),类型是使用 UDP 还是 TCP,协议是任何附加选项。这在内核中创建了一个套接字对象,可以与外部世界/网络通信。这将返回一个 fd,因此您可以像使用普通文件描述符一样使用它!请记住,您希望从 socketfd 读取或写入,因为它仅代表客户端的套接字对象,否则您希望遵守服务器的约定。
getaddressinfo
我们在上一节看到了这个!你们是这方面的专家。
连接
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
将 sockfd 传递给它,然后传递您要访问的地址及其长度,您将可以连接(只要检查错误)。请记住,网络调用极易失败。
读取/写入
一旦我们成功连接,我们可以像处理任何旧文件描述符一样读取或写入。请记住,如果您连接到一个网站,您希望遵守 HTTP 协议规范,以便获得任何有意义的结果。通常有库来做这个,通常你不会在套接字级别连接,因为周围有其他库或软件包
完整的简单 TCP 客户端示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
#include <unistd.h>
int main(int argc, char **argv)
{
int s;
int sock_fd = socket(AF_INET, SOCK_STREAM, 0);
struct addrinfo hints, *result;
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_family = AF_INET; /* IPv4 only */
hints.ai_socktype = SOCK_STREAM; /* TCP */
s = getaddrinfo("www.illinois.edu", "80", &hints, &result);
if (s != 0) {
fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(s));
exit(1);
}
if(connect(sock_fd, result->ai_addr, result->ai_addrlen) == -1){
perror("connect");
exit(2);
}
char *buffer = "GET / HTTP/1.0\r\n\r\n";
printf("SENDING: %s", buffer);
printf("===\n");
write(sock_fd, buffer, strlen(buffer));
char resp[1000];
int len = read(sock_fd, resp, 999);
resp[len] = '\0';
printf("%s\n", resp);
return 0;
}
示例输出:
SENDING: GET / HTTP/1.0
===
HTTP/1.1 200 OK
Date: Mon, 27 Oct 2014 19:19:05 GMT
Server: Apache/2.2.15 (Red Hat) mod_ssl/2.2.15 OpenSSL/1.0.1e-fips mod_jk/1.2.32
Last-Modified: Fri, 03 Feb 2012 16:51:10 GMT
ETag: "401b0-49-4b8121ea69b80"
Accept-Ranges: bytes
Content-Length: 73
Connection: close
Content-Type: text/html
Provided by Web Services at Public Affairs at the University of Illinois
对 HTTP 请求和响应的评论
上面的示例演示了使用超文本传输协议向服务器发出请求。使用以下请求请求网页(或其他资源):
GET / HTTP/1.0
有四个部分(方法例如 GET,POST,…);资源(例如/ /index.html /image.png);协议“HTTP/1.0”和两个新行(\r\n\r\n)
服务器的第一行响应描述了所使用的 HTTP 版本以及请求是否成功,使用了一个 3 位数的响应代码:
HTTP/1.1 200 OK
如果客户端请求了一个不存在的文件,例如GET /nosuchfile.html HTTP/1.0,那么第一行包括响应代码是著名的404响应代码:
HTTP/1.1 404 Not Found
网络,第四部分:构建一个简单的 TCP 服务器
htons是什么,何时使用它?
整数可以以最低有效字节优先或最高有效字节优先表示。只要机器本身在内部一致,任何方法都是合理的。对于网络通信,我们需要在约定的格式上进行标准化。
htons(xyz)以网络字节顺序返回 16 位无符号整数“short”值 xyz。htonl(xyz)以网络字节顺序返回 32 位无符号整数“long”值 xyz。
这些函数被读作“主机到网络”;反向函数(ntohs、ntohl)将网络排序的字节值转换为主机排序。那么,主机排序是小端还是大端?答案是-这取决于您的机器!这取决于运行代码的主机的实际架构。如果架构恰好与网络排序相同,那么这些函数的结果就是参数。对于 x86 机器,主机和网络排序是不同的。
总结:无论何时读取或写入低级 C 网络结构(例如端口和地址信息),请记住使用上述函数确保正确转换为/从机器格式。否则,显示或指定的值可能是不正确的。
用于创建服务器的“大 4”网络调用是什么?
创建 TCP 服务器所需的四个系统调用是:socket、bind、listen和accept。每个都有特定的目的,并且应按上述顺序调用。
端口信息(由 bind 使用)可以手动设置(许多旧的仅 IPv4 的 C 代码示例都这样做),也可以使用getaddrinfo创建
我们稍后也会看到 setsockopt 的示例。
调用socket的目的是什么?
为网络通信创建一个端点。一个新的套接字本身并不特别有用;虽然我们已经指定了基于数据包或基于流的连接,但它并没有绑定到特定的网络接口或端口。相反,套接字返回一个网络描述符,可以在以后调用 bind、listen 和 accept 时使用。
调用bind的目的是什么
bind调用将抽象套接字与实际网络接口和端口关联起来。可以在 TCP 客户端上调用 bind,但通常不需要指定出站端口。
调用listen的目的是什么
listen调用指定了等待处理的传入连接的队列大小,即尚未被accept分配网络描述符的连接。高性能服务器的典型值为 128 或更多。
为什么服务器套接字是被动的?
服务器套接字不会主动尝试连接到另一个主机;相反,它们等待传入的连接。此外,当对等方断开连接时,服务器套接字不会关闭。相反,当远程客户端连接时,它会立即被转移到未使用的端口号以进行未来通信。
调用accept的目的是什么
一旦服务器套接字被初始化,服务器调用accept等待新的连接。与socket、bind和listen不同,这个调用将会阻塞。也就是说,如果没有新的连接,这个调用将会阻塞,只有当一个新的客户端连接时才会返回。
注意,accept调用返回一个新的文件描述符。这个文件描述符特定于特定的客户端。常见的编程错误是使用原始服务器套接字描述符进行服务器 I/O,然后惊讶地发现网络代码失败了。
创建 TCP 服务器的注意事项是什么?
-
使用被动服务器套接字的套接字描述符(如上所述)
-
未指定
getaddrinfo的 SOCK_STREAM 要求 -
无法重用现有端口。
-
不初始化未使用的结构条目
-
如果端口当前正在使用,
bind调用将失败
注意,端口是每台机器的,而不是每个进程或每个用户的。换句话说,当另一个进程使用该端口时,您不能使用端口 1234。更糟糕的是,默认情况下,端口在进程结束后会被“占用”。
服务器代码示例
下面是一个工作的简单服务器示例。请注意,此示例不完整 - 例如,它既不关闭套接字描述符,也不释放getaddrinfo创建的内存。
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
#include <unistd.h>
#include <arpa/inet.h>
int main(int argc, char **argv)
{
int s;
int sock_fd = socket(AF_INET, SOCK_STREAM, 0);
struct addrinfo hints, *result;
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_family = AF_INET;
hints.ai_socktype = SOCK_STREAM;
hints.ai_flags = AI_PASSIVE;
s = getaddrinfo(NULL, "1234", &hints, &result);
if (s != 0) {
fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(s));
exit(1);
}
if (bind(sock_fd, result->ai_addr, result->ai_addrlen) != 0) {
perror("bind()");
exit(1);
}
if (listen(sock_fd, 10) != 0) {
perror("listen()");
exit(1);
}
struct sockaddr_in *result_addr = (struct sockaddr_in *) result->ai_addr;
printf("Listening on file descriptor %d, port %d\n", sock_fd, ntohs(result_addr->sin_port));
printf("Waiting for connection...\n");
int client_fd = accept(sock_fd, NULL, NULL);
printf("Connection made: client_fd=%d\n", client_fd);
char buffer[1000];
int len = read(client_fd, buffer, sizeof(buffer) - 1);
buffer[len] = '\0';
printf("Read %d chars\n", len);
printf("===\n");
printf("%s\n", buffer);
return 0;
}
为什么我的服务器不能重用端口?
默认情况下,当套接字关闭时,端口不会立即释放。相反,端口会进入“TIMED-WAIT”状态。这可能会在开发过程中导致重大混乱,因为超时可能会使有效的网络代码看起来失败。
要能够立即重用端口,需要在绑定端口之前指定SO_REUSEPORT。
int optval = 1;
setsockopt(sfd, SOL_SOCKET, SO_REUSEPORT, &optval, sizeof(optval));
bind(....
这里是一个关于SO_REUSEPORT的扩展 stackoverflow 入门讨论。
网络,第五部分:关闭端口,重用端口和其他技巧
关闭和关闭之间有什么区别?
当您不再需要从套接字读取更多数据,写入更多数据或完成两者时,请使用shutdown调用。当您关闭套接字以进行进一步写入(或读取)时,该信息也会发送到连接的另一端。例如,如果您在服务器端关闭套接字以进行进一步写入,那么稍后,阻塞的read调用可能返回 0,表示不再需要更多字节。
当您的进程不再需要套接字文件描述符时,请使用close。
如果在创建套接字文件描述符后进行了fork,则所有进程都需要在套接字资源可以重新使用之前关闭套接字。如果您关闭套接字以进行进一步读取,那么所有进程都会受到影响,因为您已更改了套接字,而不仅仅是文件描述符。
良好编写的代码将在调用close之前shutdown套接字。
当我重新运行我的服务器代码时,它不起作用!为什么?
默认情况下,套接字关闭后,端口进入超时状态,在此期间不能重新使用(“绑定到新套接字”)。
通过在绑定到端口之前设置套接字选项 REUSEPORT 可以禁用此行为:
int optval = 1;
setsockopt(sock_fd, SOL_SOCKET, SO_REUSEPORT, &optval, sizeof(optval));
bind(sock_fd, ...);
TCP 客户端可以绑定到特定端口吗?
是的!实际上,出站 TCP 连接会自动绑定到客户端上未使用的端口。通常情况下,不需要在客户端上显式设置端口,因为系统会智能地在合理的接口上找到一个未使用的端口(例如,如果当前通过 WiFi 连接,则是无线网卡)。但是,如果您需要明确选择特定的以太网卡,或者防火墙仅允许从特定范围的端口值进行出站连接,则可能会有用。
要显式绑定到以太网接口和端口,请在connect之前调用bind
谁连接到我的服务器?
accept系统调用可以选择性地通过传递 sockaddr 结构提供有关远程客户端的信息。不同的协议具有不同的struct sockaddr变体,它们的大小也不同。使用最简单的结构是sockaddr_storage,它足够大以表示所有可能类型的 sockaddr。请注意,C 没有任何继承模型。因此,我们需要将我们的结构明确转换为“基本类型”结构 sockaddr。
struct sockaddr_storage clientaddr;
socklen_t clientaddrsize = sizeof(clientaddr);
int client_id = accept(passive_socket,
(struct sockaddr *) &clientaddr,
&clientaddrsize);
我们已经看到getaddrinfo可以构建 addrinfo 条目的链表(每个条目都可以包含套接字配置数据)。如果我们想要将套接字数据转换为 IP 和端口地址怎么办?输入getnameinfo,它可以用于将本地或远程套接字信息转换为域名或数字 IP。类似地,端口号可以表示为服务名称(例如端口 80 的“http”)。在下面的示例中,我们请求客户端 IP 地址和客户端端口号的数字版本。
socklen_t clientaddrsize = sizeof(clientaddr);
int client_id = accept(sock_id, (struct sockaddr *) &clientaddr, &clientaddrsize);
char host[256], port[256];
getnameinfo((struct sockaddr *) &clientaddr,
clientaddrsize, host, sizeof(host), port, sizeof(port),
NI_NUMERICHOST | NI_NUMERICSERV);
待办事项:讨论 NI_MAXHOST 和 NI_MAXSERV,以及 NI_NUMERICHOST
getnameinfo 示例:我的 IP 地址是多少?
要获取当前计算机的 IP 地址的 IP 地址链表,请使用getifaddrs,它将返回 IPv4 和 IPv6 IP 地址的链接列表(可能还包括其他接口)。我们可以检查每个条目并使用getnameinfo打印主机的 IP 地址。ifaddrs 结构包括家族,但不包括结构的大小。因此,我们需要根据家族(IPv4 v IPv6)手动确定结构的大小。
(family == AF_INET) ? sizeof(struct sockaddr_in) : sizeof(struct sockaddr_in6)
完整的代码如下所示。
int required_family = AF_INET; // Change to AF_INET6 for IPv6
struct ifaddrs *myaddrs, *ifa;
getifaddrs(&myaddrs);
char host[256], port[256];
for (ifa = myaddrs; ifa != NULL; ifa = ifa->ifa_next) {
int family = ifa->ifa_addr->sa_family;
if (family == required_family && ifa->ifa_addr) {
if (0 == getnameinfo(ifa->ifa_addr,
(family == AF_INET) ? sizeof(struct sockaddr_in) :
sizeof(struct sockaddr_in6),
host, sizeof(host), port, sizeof(port)
, NI_NUMERICHOST | NI_NUMERICSERV ))
puts(host);
}
}
我的机器的 IP 地址是多少(shell 版本)
答案:使用ifconfig(或 Windows 的 ipconfig)。但是这个命令为每个接口生成大量输出,因此我们可以使用 grep 过滤输出。
ifconfig | grep inet
Example output:
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1
inet 127.0.0.1 netmask 0xff000000
inet6 ::1 prefixlen 128
inet6 fe80::7256:81ff:fe9a:9141%en1 prefixlen 64 scopeid 0x5
inet 192.168.1.100 netmask 0xffffff00 broadcast 192.168.1.255
网络,第六部分:创建 UDP 服务器
如何创建 UDP 服务器?
有各种可用的函数调用来发送 UDP 套接字。我们将使用较新的 getaddrinfo 来帮助设置套接字结构。
请记住,UDP 是一个简单的基于数据包的协议;两个主机之间没有建立连接。
首先,初始化 hints addrinfo 结构以请求一个 IPv6,被动数据报套接字。
memset(&hints, 0, sizeof(hints));
hints.ai_family = AF_INET6; // INET for IPv4
hints.ai_socktype = SOCK_DGRAM;
hints.ai_flags = AI_PASSIVE;
接下来,使用 getaddrinfo 来指定端口号(我们不需要指定主机,因为我们正在创建一个服务器套接字,而不是向远程主机发送数据包)。
getaddrinfo(NULL, "300", &hints, &res);
sockfd = socket(res->ai_family, res->ai_socktype, res->ai_protocol);
bind(sockfd, res->ai_addr, res->ai_addrlen);
端口号是<1024,所以程序将需要root权限。我们也可以指定一个服务名称,而不是一个数字端口值。
到目前为止,调用与 TCP 服务器类似。对于基于流的服务,我们将调用listen和accept。对于我们的 UDP 服务器,我们可以开始等待套接字上数据包的到达。
struct sockaddr_storage addr;
int addrlen = sizeof(addr);
// ssize_t recvfrom(int socket, void* buffer, size_t buflen, int flags, struct sockaddr *addr, socklen_t * address_len);
byte_count = recvfrom(sockfd, buf, sizeof(buf), 0, &addr, &addrlen);
addr 结构将保存有关到达数据包的发送者(源)信息。请注意,sockaddr_storage类型足够大,可以容纳所有可能类型的套接字地址(例如 IPv4、IPv6 和其他套接字类型)。
完整代码
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
#include <unistd.h>
#include <arpa/inet.h>
int main(int argc, char **argv)
{
int s;
struct addrinfo hints, *result;
memset(&hints, 0, sizeof(hints));
hints.ai_family = AF_INET6; // INET for IPv4
hints.ai_socktype = SOCK_DGRAM;
hints.ai_flags = AI_PASSIVE;
getaddrinfo(NULL, "300", &hints, &res);
int sockfd = socket(res->ai_family, res->ai_socktype, res->ai_protocol);
if (bind(sockfd, res->ai_addr, res->ai_addrlen) != 0) {
perror("bind()");
exit(1);
}
struct sockaddr_storage addr;
int addrlen = sizeof(addr);
while(1){
char buffer[1000];
ssize_t byte_count = recvfrom(sockfd, buf, sizeof(buf), 0, &addr, &addrlen);
buffer[byte_count] = '\0';
}
printf("Read %d chars\n", len);
printf("===\n");
printf("%s\n", buffer);
return 0;
}
网络,第七部分:非阻塞 I/O,select()和 epoll
不要浪费时间等待
通常,当你调用read()时,如果数据尚不可用,它将等待数据准备就绪后再返回。当你从磁盘读取数据时,这种延迟可能不会很长,但当你从一个慢速网络连接中读取数据时,如果数据到达的话,可能需要很长时间。
POSIX 允许你在文件描述符上设置一个标志,以便对该文件描述符的任何read()调用都会立即返回,无论它是否已经完成。在这种模式下,你的read()调用将启动读取操作,而在它工作时,你可以做其他有用的工作。这被称为“非阻塞”模式,因为read()的调用不会阻塞。
要将文件描述符设置为非阻塞:
// fd is my file descriptor
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
对于套接字,你可以通过将SOCK_NONBLOCK添加到socket()的第二个参数来以非阻塞模式创建它。
fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, 0);
当文件处于非阻塞模式时,你调用read(),它将立即返回可用的字节。假设从套接字的另一端的服务器已经到达了 100 个字节,你调用read(fd, buf, 150)。read将立即返回值 100,表示它读取了你要求的 150 个字节中的 100 个。假设你尝试通过调用read(fd, buf+100, 50)来读取剩余的数据,但是最后的 50 个字节还没有到达。read()将返回-1,并将全局错误变量errno设置为 EAGAIN 或 EWOULDBLOCK。这是系统告诉你数据还没有准备好的方式。
write()也可以在非阻塞模式下工作。假设你想使用套接字向远程服务器发送 40,000 字节。系统一次只能发送这么多字节。通常系统一次可以发送大约 23,000 字节。在非阻塞模式下,write(fd, buf, 40000)将返回它立即能够发送的字节数,大约为 23,000。如果你立即再次调用write(),它将返回-1,并将 errno 设置为 EAGAIN 或 EWOULDBLOCK。这是系统告诉你它仍在忙于发送最后一块数据,并且还没有准备好发送更多数据。
如何检查 I/O 何时完成?
有几种方法。让我们看看如何使用select和epoll来做。
select
int select(int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
给定三组文件描述符,select()将等待其中任何一个文件描述符变为“准备就绪”。
-
readfds- 在readfds中的文件描述符在有可读数据或已达到 EOF 时准备就绪。 -
writefds- 在writefds中的文件描述符在调用 write()时将会成功。 -
exceptfds- 系统特定,定义不清晰。只需将其传递为 NULL。
select()返回准备就绪的文件描述符的总数。如果它们在timeout定义的时间内没有准备好,它将返回 0。在select()返回后,调用者需要循环遍历 readfds 和/或 writefds 中的文件描述符,以查看哪些是准备好的。由于 readfds 和 writefds 充当输入和输出参数,当select()指示有准备好的文件描述符时,它会覆盖它们以反映只有准备好的文件描述符。除非调用者的意图是只调用一次select(),否则在调用它之前保存 readfds 和 writefds 的副本是个好主意。
fd_set readfds, writefds;
FD_ZERO(&readfds);
FD_ZERO(&writefds);
for (int i=0; i < read_fd_count; i++)
FD_SET(my_read_fds[i], &readfds);
for (int i=0; i < write_fd_count; i++)
FD_SET(my_write_fds[i], &writefds);
struct timeval timeout;
timeout.tv_sec = 3;
timeout.tv_usec = 0;
int num_ready = select(FD_SETSIZE, &readfds, &writefds, NULL, &timeout);
if (num_ready < 0) {
perror("error in select()");
} else if (num_ready == 0) {
printf("timeout\n");
} else {
for (int i=0; i < read_fd_count; i++)
if (FD_ISSET(my_read_fds[i], &readfds))
printf("fd %d is ready for reading\n", my_read_fds[i]);
for (int i=0; i < write_fd_count; i++)
if (FD_ISSET(my_write_fds[i], &writefds))
printf("fd %d is ready for writing\n", my_write_fds[i]);
}
epoll
epoll不是 POSIX 的一部分,但它受 Linux 支持。这是一种更有效的等待多个文件描述符的方式。它会告诉你哪些描述符准备好了。它甚至可以为每个描述符存储少量数据,比如数组索引或指针,使得更容易访问与该描述符相关的数据。
使用 epoll,首先您必须使用epoll_create()创建一个特殊的文件描述符。您不会读取或写入此文件描述符;您只需将其传递给其他 epoll_xxx 函数,并在最后调用 close()。
epfd = epoll_create(1);
对于要使用 epoll 监视的每个文件描述符,您需要使用epoll_ctl()和EPOLL_CTL_ADD选项将其添加到 epoll 数据结构中。您可以向其中添加任意数量的文件描述符。
struct epoll_event event;
event.events = EPOLLOUT; // EPOLLIN==read, EPOLLOUT==write
event.data.ptr = mypointer;
epoll_ctl(epfd, EPOLL_CTL_ADD, mypointer->fd, &event)
要等待某些文件描述符准备就绪,请使用epoll_wait()。它填充的 epoll_event 结构将包含您在添加此文件描述符时提供的 event.data 中的数据。这使您可以轻松查找与此文件描述符关联的自己的数据。
int num_ready = epoll_wait(epfd, &event, 1, timeout_milliseconds);
if (num_ready > 0) {
MyData *mypointer = (MyData*) event.data.ptr;
printf("ready to write on %d\n", mypointer->fd);
}
假设您正在等待向文件描述符写入数据,但现在您想要等待从中读取数据。只需使用epoll_ctl()和EPOLL_CTL_MOD选项来更改您正在监视的操作类型。
event.events = EPOLLOUT;
event.data.ptr = mypointer;
epoll_ctl(epfd, EPOLL_CTL_MOD, mypointer->fd, &event);
要取消订阅一个文件描述符,同时保持其他文件描述符处于活动状态,请使用epoll_ctl()和EPOLL_CTL_DEL选项。
epoll_ctl(epfd, EPOLL_CTL_DEL, mypointer->fd, NULL);
要关闭 epoll 实例,请关闭其文件描述符。
close(epfd);
除了非阻塞的read()和write()之外,对非阻塞套接字上的任何connect()调用也将是非阻塞的。要等待连接完成,请使用select()或 epoll 等待套接字可写。
有关 select 的边缘情况的有趣博文
idea.popcount.org/2017-01-06-select-is-fundamentally-broken/
RPC,第一部分:远程过程调用简介
什么是 RPC?
远程过程调用。RPC 是我们可以在不同的机器上执行一个过程(函数)的想法。实际上,该过程可能在同一台机器上执行,但可能在不同的上下文中执行-例如在不同的用户下以不同的权限和不同的生命周期。
什么是特权分离?
远程代码将在不同的用户和不同权限下执行。实际上,远程调用可能以比调用者更多或更少的权限执行。原则上,这可以用来提高系统的安全性(通过确保组件以最低权限运行)。不幸的是,安全问题需要仔细评估,以确保 RPC 机制不能被利用来执行不需要的操作。例如,RPC 实现可能会隐式信任任何连接的客户端执行任何操作,而不是在数据的子集上执行子集的操作。
什么是存根代码?什么是编组?
存根代码是隐藏执行远程过程调用复杂性所必需的代码。存根代码的作用之一是编组必要的数据成为可以作为字节流发送到远程服务器的格式。
// On the outside 'getHiscore' looks like a normal function call
// On the inside the stub code performs all of the work to send and receive the data to and from the remote machine.
int getHiscore(char* game) {
// Marshall the request into a sequence of bytes:
char* buffer;
asprintf(&buffer,"getHiscore(%s)!", name);
// Send down the wire (we do not send the zero byte; the '!' signifies the end of the message)
write(fd, buffer, strlen(buffer) );
// Wait for the server to send a response
ssize_t bytesread = read(fd, buffer, sizeof(buffer));
// Example: unmarshal the bytes received back from text into an int
buffer[bytesread] = 0; // Turn the result into a C string
int score= atoi(buffer);
free(buffer);
return score;
}
什么是服务器存根代码?什么是解组?
服务器存根代码将接收请求,将请求解组成有效的内存数据调用底层实现,并将结果发送回调用者。
如何发送 int?float?结构?链表?图?
要实现 RPC,您需要决定(并记录)将数据序列化为字节序列的约定。即使是一个简单的整数也有几种常见选择:
-
有符号还是无符号?
-
ASCII
-
固定字节数或根据大小而变化
-
小端或大端的二进制格式?
要编组一个结构,决定哪些字段需要序列化。可能不需要发送所有数据项(例如,某些项可能与特定的 RPC 无关,或者可以由服务器从其他数据项重新计算)。
编组链表时,无需发送链接指针-只需流式传输值。作为解组的一部分,服务器可以从字节序列中重新创建链表结构。
通过从头节点/顶点开始,可以递归访问简单树以创建数据的序列化版本。循环图通常需要额外的内存来确保每个边和顶点都被处理一次。
什么是 IDL(接口设计语言)?
手动编写存根代码是痛苦的、乏味的、容易出错的、难以维护的,难以从实现的代码中逆向工程出线协议。更好的方法是指定数据对象、消息和服务,并自动生成客户端和服务器代码。
接口设计语言的现代示例是 Google 的 Protocol Buffer .proto 文件。
RPC 与本地调用的复杂性和挑战?
远程过程调用比本地调用慢得多(10 倍至 100 倍),并且比本地调用更复杂。RPC 必须将数据编组成兼容的格式。这可能需要通过数据结构进行多次传递,临时内存分配和数据表示的转换。
健壮的 RPC 存根代码必须智能地处理网络故障和版本控制。例如,服务器可能需要处理来自仍在运行早期版本存根代码的客户端的请求。
安全的 RPC 将需要实施额外的安全检查(包括身份验证和授权),验证数据并加密客户端和主机之间的通信。
传输大量结构化数据
让我们通过 3 种不同的格式-JSON、XML 和 Google Protocol Buffers 来检查使用 3 种不同格式传输数据的方法。JSON 和 XML 是基于文本的协议。以下是 JSON 和 XML 消息的示例。
<ticket><price currency='dollar'>10</price><vendor>travelocity</vendor></ticket>
{ 'currency':'dollar' , 'vendor':'travelocity', 'price':'10' }
谷歌协议缓冲区是一个开源的高效二进制协议,非常注重高吞吐量、低 CPU 开销和最小内存复制。已经为多种语言实现了协议缓冲区,包括 Go、Python、C++和 C。这意味着可以从.proto 规范文件生成多种语言的客户端和服务器存根代码,以便将数据编组到二进制流中并从中解组。
谷歌协议缓冲区通过忽略消息中存在的未知字段来减少版本问题。有关更多信息,请参阅协议缓冲区的介绍。
developers.google.com/protocol-buffers/docs/overview
网络复习问题
主题
-
IPv4 与 IPv6
-
TCP 与 UDP
-
数据包丢失/基于连接
-
获取地址信息
-
DNS
-
TCP 客户端调用
-
TCP 服务器调用
-
关闭
-
recvfrom
-
epoll 与 select
-
RPC
问题
-
什么是 IPv4?IPv6?它们之间有什么区别?
-
TCP 是什么?UDP 是什么?给我它们的优缺点。我什么时候会使用其中一个而不是另一个?
-
哪种协议是无连接的,哪种是基于连接的?
-
什么是 DNS?DNS 的路由是什么?
-
套接字的作用是什么?
-
建立 TCP 客户端的调用是什么?
-
建立 TCP 服务器的调用是什么?
-
套接字关闭和关闭之间有什么区别?
-
何时可以使用
read和write?recvfrom和sendto呢? -
epoll相对于select有哪些优势?select相对于epoll有哪些优势? -
什么是远程过程调用?何时应该使用它?
-
什么是编组/解组?为什么 HTTP 不是 RPC?
九、文件系统
文件系统,第一部分:介绍
导航/术语
设计一个文件系统!你的设计目标是什么?
文件系统的设计是一个困难的问题,因为有许多我们想要满足的高级设计目标。一个不完整的理想目标清单包括:
-
可靠和健壮(即使有硬件故障或由于断电而导致不完整的写入)
-
访问(安全)控制
-
会计和配额
-
索引和搜索
-
版本控制和备份功能
-
加密
-
自动压缩
-
高性能(例如内存中的缓存)
-
高效使用存储去重
并非所有文件系统都原生支持所有这些目标。例如,许多文件系统不会自动压缩很少使用的文件
.、..和...是什么?
在标准的 Unix 文件系统中:
-
.表示当前目录 -
..表示父目录 -
...不是任何目录的有效表示(这不是爷爷文件夹)。它可能是磁盘上的一个文件的名称。
绝对路径和相对路径是什么?
绝对路径是从您的目录树的’根节点’开始的路径。相对路径是从树中的当前位置开始的路径。
相对路径和绝对路径的一些例子是什么?
如果您从您的主目录开始(简称“~”),那么Desktop/cs241将是一个相对路径。它的绝对路径对应物可能是类似于/Users/[yourname]/Desktop/cs241的东西。
如何简化a/b/../c/./?
记住..表示’父文件夹’,.表示’当前文件夹’。
例如:a/b/../c/.
-
步骤 1:
cd a(在 a 中) -
步骤 2:
cd b(在 a/b 中) -
步骤 3:
cd ..(在 a 中,因为…表示’父文件夹’) -
步骤 4:
cd c(在 a/c 中) -
步骤 5:
cd .(在 a/c 中,因为.表示’当前文件夹’)
因此,这条路径可以简化为a/c。
那么什么是文件系统?
文件系统是如何在磁盘上组织信息的。每当您想要访问一个文件时,文件系统规定了文件的读取方式。这是一个文件系统的示例图像。
哇,这太多了,让我们分解一下
-
超级块:这个块包含关于文件系统的元数据,大小、最后修改时间、日志、索引节点数和第一个索引节点的起始位置、数据块数和第一个数据块的起始位置。
-
索引节点:这是关键的抽象。索引节点是一个文件。
-
磁盘块:这是数据存储的地方。文件的实际内容
索引节点如何存储文件内容?

来自Wikipedia:
在类 Unix 风格的文件系统中,索引节点,非正式地称为 inode,是用来表示文件系统对象的数据结构,可以是各种东西,包括文件或目录。每个 inode 存储文件系统对象数据的属性和磁盘块位置。文件系统对象属性可能包括操作元数据(例如更改、访问、修改时间),以及所有者和权限数据(例如组 ID、用户 ID、权限)。
要读取文件的前几个字节,跟随第一个间接块指针到第一个间接块并读取前几个字节,写入是相同的过程。如果要读取整个文件,继续读取直接块,直到大小用完(我们稍后会讨论间接块)
“计算机科学中的所有问题都可以通过另一层间接性来解决。”- David Wheeler
为什么要使磁盘块的大小与内存页面相同?
支持虚拟内存,这样我们就可以将东西分页到内存中和从内存中分页出来。
我们想要为每个文件存储什么信息?
-
文件名
-
文件大小
-
创建时间、最后修改时间、最后访问时间
-
权限
-
文件路径
-
校验和
-
文件数据(索引节点)
文件的传统权限是什么:用户-组-其他权限?
一些常见的文件权限包括:
- 755:
rwx r-x r-x
用户:rwx,组:r-x,其他人:r-x
用户可以读取、写入和执行。组和其他人只能读取和执行。
- 644:
rw- r-- r--
用户:rw-,组:r--,其他人:r--
用户可以读写。组和其他人只能读。
对于每个角色的常规文件,有 3 个权限位是什么?
-
读(最高有效位)
-
写(第二位)
-
执行(最低有效位)
“644”“755”是什么意思?
这些是八进制格式(基数 8)的权限示例。每个八进制数字对应不同的角色(用户、组、全局)。
我们可以按照八进制格式读取权限如下:
-
644 - 用户权限为 R/W,组权限为 R,全局权限为 R
-
755 - 用户权限为 R/W/X,组权限为 R/X,全局权限为 R/X
每个间接表可以存储多少个指针?
举个例子,假设我们将磁盘分成 4KB 块,并且我们想要寻址多达 2^32 块。
最大磁盘大小为 4KB * 2^32 = 16TB(记住 2^10 = 1024)
一个磁盘块可以存储 4KB / 4B(每个指针需要 32 位)= 1024 个指针。每个指针指向一个 4KB 的磁盘块 - 因此您可以引用多达 1024 * 4KB = 4MB 的数据
对于相同的磁盘配置,双间接块存储 1024 个指针指向 1024 个间接表。因此,双间接块可以引用多达 1024 * 4MB = 4GB 的数据。
同样,三重间接块可以引用多达 4TB 的数据。
文件系统,第二部分:文件是索引节点(其他一切都只是数据…)
大意:忘记文件名:'索引节点’就是文件。
通常认为文件名是’实际’文件。不是!相反,将索引节点视为文件。索引节点包含元信息(最后访问、所有权、大小)并指向用于保存文件内容的磁盘块。
那么…我们如何实现一个目录?
目录只是名称到索引节点号的映射。POSIX 提供了一小组函数来读取每个条目的文件名和索引节点号(见下文)
让我们想想它在实际文件系统中是什么样子。理论上,目录就像实际文件一样。磁盘块将包含目录条目或dirent。这意味着我们的磁盘块可以看起来像这样
| 索引节点号 | 名称 |
|---|---|
| 2043567 | hi.txt |
…
每个目录条目可以是固定大小,也可以是可变的 C 字符串。这取决于特定文件系统在较低级别实现的方式。
我如何找到文件的索引节点号?
从 shell 中,使用带有-i选项的ls
$ ls -i
12983989 dirlist.c 12984068 sandwich.c
从 C 中调用 stat 函数之一(下面介绍)。
我如何找出文件(或目录)的元信息?
使用 stat 调用。例如,要找出我的’notes.txt’文件上次访问的时间 -
struct stat s;
stat("notes.txt", & s);
printf("Last accessed %s", ctime(s.st_atime));
实际上有三个版本的stat;
int stat(const char *path, struct stat *buf);
int fstat(int fd, struct stat *buf);
int lstat(const char *path, struct stat *buf);
例如,您可以使用fstat来查找与该文件关联的文件描述符的文件的元信息
FILE *file = fopen("notes.txt", "r");
int fd = fileno(file); /* Just for fun - extract the file descriptor from a C FILE struct */
struct stat s;
fstat(fd, & s);
printf("Last accessed %s", ctime(s.st_atime));
第三个调用’lstat’我们将在介绍符号链接时讨论。
除了访问、创建和修改时间之外,stat 结构还包括索引节点号、文件长度和所有者信息。
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* inode number */
mode_t st_mode; /* protection */
nlink_t st_nlink; /* number of hard links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
dev_t st_rdev; /* device ID (if special file) */
off_t st_size; /* total size, in bytes */
blksize_t st_blksize; /* blocksize for file system I/O */
blkcnt_t st_blocks; /* number of 512B blocks allocated */
time_t st_atime; /* time of last access */
time_t st_mtime; /* time of last modification */
time_t st_ctime; /* time of last status change */
};
我如何列出目录的内容?
让我们编写我们自己的’version of 'ls’来列出目录的内容。
#include <stdio.h>
#include <dirent.h>
#include <stdlib.h>
int main(int argc, char **argv) {
if(argc == 1) {
printf("Usage: %s [directory]\n", *argv);
exit(0);
}
struct dirent *dp;
DIR *dirp = opendir(argv[1]);
while ((dp = readdir(dirp)) != NULL) {
puts(dp->d_name);
}
closedir(dirp);
return 0;
}
我如何读取目录的内容?
答:使用 opendir readdir closedir 例如,这是一个非常简单的’ls’实现,用于列出目录的内容。
#include <stdio.h>
#include <dirent.h>
#include <stdlib.h>
int main(int argc, char **argv) {
if(argc ==1) {
printf("Usage: %s [directory]\n", *argv);
exit(0);
}
struct dirent *dp;
DIR *dirp = opendir(argv[1]);
while ((dp = readdir(dirp)) != NULL) {
printf("%s %lu\n", dp-> d_name, (unsigned long)dp-> d_ino );
}
closedir(dirp);
return 0;
}
注意:在调用 fork()后,父进程或子进程可以使用 readdir()、rewinddir()或 seekdir()。如果父进程和子进程都使用上述方法,行为是未定义的。
我如何检查文件是否在当前目录中?
例如,要查看特定目录是否包含文件(或文件名)‘名称’,我们可以编写以下代码。(提示:你能发现错误吗?)
int exists(char *directory, char *name) {
struct dirent *dp;
DIR *dirp = opendir(directory);
while ((dp = readdir(dirp)) != NULL) {
puts(dp->d_name);
if (!strcmp(dp->d_name, name)) {
return 1; /* Found */
}
}
closedir(dirp);
return 0; /* Not Found */
}
上面的代码有一个微妙的错误:它泄漏资源!如果找到匹配的文件名,那么’closedir’将不会作为早期返回的一部分调用。opendir 打开的任何文件描述符和分配的任何内存都不会被释放。这意味着最终进程将耗尽资源,并且open或opendir调用将失败。
修复的方法是确保我们在每个可能的代码路径中释放资源。在上面的代码中,这意味着在return 1之前调用closedir。忘记释放资源是一个常见的 C 编程错误,因为 C 语言中没有支持确保所有代码路径都始终释放资源。
使用 readdir 的陷阱是什么?例如,递归搜索目录?
有两个主要的陷阱和一个考虑:readdir函数返回“.”(当前目录)和“…”(父目录)。如果要查找子目录,需要明确排除这些目录。
对于许多应用程序来说,首先检查当前目录,然后递归搜索子目录是合理的。这可以通过将结果存储在链接列表中来实现,或者重置目录结构以从头开始重新开始。
最后要注意的一点:readdir不是线程安全的!对于多线程搜索,请使用readdir_r,它要求调用者传递现有 dirent 结构的地址。
有关 readdir 的更多详细信息,请参阅 readdir 的 man 页面。
我如何确定目录条目是否是目录?
答:使用S_ISDIR来检查 stat 结构中存储的模式位
要检查文件是否为常规文件,请使用S_ISREG,
struct stat s;
if (0 == stat(name, &s)) {
printf("%s ", name);
if (S_ISDIR( s.st_mode)) puts("is a directory");
if (S_ISREG( s.st_mode)) puts("is a regular file");
} else {
perror("stat failed - are you sure I can read this file's meta data?");
}
目录也有 inode 吗?
是的!虽然更好的想法是,一个目录(就像一个文件)是一个 inode(带有一些数据-目录名称和 inode 内容)。它碰巧是一种特殊类型的 inode。
来自Wikipedia:
Unix 目录是关联结构的列表,每个结构包含一个文件名和一个 inode 号。
请记住,inode 不包含文件名-只包含其他文件元数据。
如何让相同的文件出现在文件系统中的两个不同位置?
首先要记住,文件名!=文件。将 inode 视为’文件’,目录只是一个名称列表,每个名称都映射到一个 inode 号。其中一些 inode 可能是常规文件 inode,其他可能是目录 inode。
如果我们已经在文件系统上有一个文件,我们可以使用’ln’命令创建到相同 inode 的另一个链接
$ ln file1.txt blip.txt
然而,blip.txt 是相同的文件;如果我编辑 blip,我正在编辑与’file1.txt!'相同的文件!我们可以通过显示两个文件名指向相同的 inode 来证明这一点:
$ ls -i file1.txt blip.txt
134235 file1.txt
134235 blip.txt
这些链接(也称为目录条目)称为’硬链接’
等效的 C 调用是link
link(const char *path1, const char *path2);
link("file1.txt", "blip.txt");
为了简单起见,上面的例子在同一个目录中创建了硬链接,但是硬链接可以在同一个文件系统的任何地方创建。
当我rm(删除)一个文件时会发生什么?
当您删除文件(使用rm或unlink)时,您正在从目录中删除一个 inode 引用。但是 inode 可能仍然被其他目录引用。为了确定文件的内容是否仍然需要,每个 inode 都保留一个引用计数,每当创建或销毁新链接时,该引用计数都会更新。
案例研究:最小化文件重复的备份软件
硬链接的一个示例用途是有效地在不同时间点创建文件系统的多个存档。一旦存档区域有特定文件的副本,未来的存档可以重用这些存档文件,而不是创建重复的文件。苹果的“Time Machine”软件就是这样做的。
我可以像常规文件一样创建目录的硬链接吗?
不。好吧是的。不是真的…实际上你并不真的想这样做,是吗?POSIX 标准说不,你不可以!ln命令只允许 root 执行此操作,只有在提供-d选项时才能执行此操作。但是,即使 root 也可能无法执行此操作,因为大多数文件系统会阻止它!
为什么?
文件系统的完整性假设目录结构(不包括我们稍后将讨论的软链接)是从根目录可达的非循环树。如果允许目录链接,强制执行或验证此约束将变得昂贵。打破这些假设可能导致文件完整性工具无法修复文件系统。递归搜索可能永远不会终止,目录可能有多个父目录,但“…”只能指向一个父目录。总的来说,这是一个坏主意。
文件系统,第三部分:权限
提醒我权限再次是什么意思?
每个文件和目录都有一组 9 个权限位和一个类型字段
-
r,读取文件的权限
-
w,写入文件的权限
-
x,执行文件的权限
chmod 777
| chmod | 7 | 7 | 7 |
|---|---|---|---|
| 01 | 111 | 111 | 111 |
| d | rwx | rwx | rwx |
| 1 | 2 | 3 | 4 |
-
文件类型
-
所有者权限
-
组权限
-
其他人的权限
mknod更改第一个字段,文件的类型。chmod接受一个数字和一个文件,并更改权限位。
文件有一个所有者。如果您的进程具有与所有者相同的用户 ID(或 root),则第一个三元组中的权限适用于您。如果您与文件在同一组中(所有文件也属于一个组),则下一组权限位适用于您。如果以上都不适用,则最后一个三元组适用于您。
如何更改文件的权限?
使用chmod(简称“更改文件模式位”)
有一个系统调用,int chmod(const char *path, mode_t mode);但我们将集中在 shell 命令上。使用chmod的两种常见方法是使用八进制值或使用符号字符串:
$ chmod 644 file1
$ chmod 755 file2
$ chmod 700 file3
$ chmod ugo-w file4
$ chmod o-rx file4
基于 8(‘八进制’)位数字描述了每个角色的权限:拥有文件的用户,组和其他人。八进制数是给三种权限的三个值的总和:读取(4),写入(2),执行(1)
示例:chmod 755 myfile
-
r + w + x = 数字
-
用户具有 4+2+1,完全权限
-
组具有 4+0+1,读取和执行权限
-
所有用户都有 4+0+1,读取和执行权限
如何从 ls 中读取权限字符串?
使用`ls -l’。请注意,权限将以’drwxrwxrwx’格式输出。第一个字符表示文件类型。第一个字符的可能值:
-
(-)常规文件
-
(d)目录
-
(c)字符设备文件\
-
(l)符号链接
-
(p)管道
-
(b)块设备
-
(s)套接字
什么是 sudo?
使用sudo成为机器上的管理员。例如通常(除非在’/etc/fstab’文件中明确指定,您需要 root 访问权限才能挂载文件系统)。sudo可用于临时以 root 身份运行命令(前提是用户具有 sudo 权限)
$ sudo mount /dev/sda2 /stuff/mydisk
$ sudo adduser fred
如何更改文件的所有权?
使用chown 用户名文件名
如何从代码中设置权限?
chmod(const char *path, mode_t mode);
为什么有些文件是’setuid’?这是什么意思?
在运行文件时,设置用户 ID 的位会更改与进程关联的用户。这通常用于需要以 root 身份运行但由非 root 用户执行的命令。一个例子是sudo
在执行时设置组 ID 会更改进程所在的组。
它们为什么有用?
最常见的用例是用户可以在程序运行期间具有 root(管理员)访问权限。
sudo 以什么权限运行?
$ ls -l /usr/bin/sudo
-r-s--x--x 1 root wheel 327920 Oct 24 09:04 /usr/bin/sudo
's’位表示执行和设置 uid;进程的有效用户 ID 将与父进程不同。在这个例子中,它将是 root
getuid()和 geteuid()之间有什么区别?
-
getuid返回真实用户 ID(如果以 root 身份登录,则为零) -
geteuid返回有效用户 ID(如果作为 root 运行,例如由于程序上设置了 setuid 标志,则为零)
如何确保只有特权用户可以运行我的代码?
- 通过调用
geteuid()来检查用户的有效权限。返回值为零表示程序有效地作为 root 运行。
文件系统,第四部分:使用目录
如何找出文件(inode)是常规文件还是目录?
使用S_ISDIR宏来检查 stat 结构中的模式位:
struct stat s;
stat("/tmp", &s);
if (S_ISDIR(s.st_mode)) { ...
请注意,稍后我们将编写健壮的代码来验证 stat 调用是否成功(返回 0);如果“stat”调用失败,我们应该假设 stat 结构内容是任意的。
我如何递归进入子目录?
首先是一个谜题-在以下代码中你能找到多少个错误?
void dirlist(char *path) {
struct dirent *dp;
DIR *dirp = opendir(path);
while ((dp = readdir(dirp)) != NULL) {
char newpath[strlen(path) + strlen(dp->d_name) + 1];
sprintf(newpath,"%s/%s", newpath, dp->d_name);
printf("%s\n", dp->d_name);
dirlist(newpath);
}
}
int main(int argc, char **argv) { dirlist(argv[1]); return 0; }
你找到了所有 5 个错误吗?
// Check opendir result (perhaps user gave us a path that can not be opened as a directory
if (!dirp) { perror("Could not open directory"); return; }
// +2 as we need space for the / and the terminating 0
char newpath[strlen(path) + strlen(dp->d_name) + 2];
// Correct parameter
sprintf(newpath,"%s/%s", path, dp->d_name);
// Perform stat test (and verify) before recursing
if (0 == stat(newpath,&s) && S_ISDIR(s.st_mode)) dirlist(newpath)
// Resource leak: the directory file handle is not closed after the while loop
closedir(dirp);
什么是符号链接?它们是如何工作的?我怎么做一个?
symlink(const char *target, const char *symlink);
要在 shell 中创建符号链接,请使用ln -s
要将链接的内容读取为文件,请使用“readlink”
$ readlink myfile.txt
../../dir1/notes.txt
要读取符号链接的元(stat)信息,请使用“lstat”而不是“stat”
struct stat s1, s2;
stat("myfile.txt", &s1); // stat info about the notes.txt file
lstat("myfile.txt", &s2); // stat info about the symbolic link
符号链接的优点
-
可以引用尚不存在的文件
-
与硬链接不同,可以引用目录以及常规文件
-
可以引用存在于当前文件系统之外的文件(和目录)
主要缺点:比常规文件和目录慢。当读取链接的内容时,它们必须被解释为目标文件的新路径。
“/dev/null”是什么,何时使用?
文件“/dev/null”是存储您永远不需要读取的位的好地方!发送到“/dev/null/”的字节永远不会被存储-它们只是被丢弃。 “/dev/null”的常见用途是丢弃标准输出。例如,
$ ls . >/dev/null
为什么我想设置目录的粘性位?
当目录的粘性位被设置时,只有文件的所有者、目录的所有者和 root 用户才能重命名(或删除)该文件。当多个用户对共享目录具有写访问权限时,这是有用的。
粘性位的常见用途是用于共享和可写的“/tmp”目录。
为什么 shell 和脚本程序以“#!/usr/bin/env python”开头?
答:为了可移植性!虽然可能会将完全合格的路径写入 python 或 perl 解释器,但这种方法不是可移植的,因为您可能已将 python 安装在不同的目录中。
要克服这一点,使用“env”实用程序来查找并执行用户路径上的程序。env 实用程序本身通常存储在“/usr/bin”中-必须使用绝对路径指定。
如何制作“隐藏”文件,即不被“ls”列出?我如何列出它们?
简单!创建以“.”开头的文件(或目录)-然后(默认情况下)它们不会被标准工具和实用程序显示。
这通常用于将配置文件隐藏在用户的主目录中。例如,“ssh”将其首选项存储在一个名为“.sshd”的目录中。
要列出所有文件,包括通常隐藏的条目,请使用带有“-a”选项的“ls”
$ ls -a
. a.c myls
.. a.out other.txt
.secret
如果我关闭目录上的执行位会发生什么?
目录的执行位用于控制目录内容是否可列出。
$ chmod ugo-x dir1
$ ls -l
drw-r--r-- 3 angrave staff 102 Nov 10 11:22 dir1
但是,当尝试列出目录的内容时,
$ ls dir1
ls: dir1: Permission denied
换句话说,目录本身是可发现的,但其内容无法列出。
什么是文件通配(由谁执行)?
在执行程序之前,shell 将参数扩展为匹配的文件名。例如,如果当前目录有三个以 my 开头的文件名(my1.txt mytext.txt myomy),那么
$ echo my*
扩展到
$ echo my1.txt mytext.txt myomy
这被称为文件通配,并在执行命令之前进行处理。即命令的参数与手动输入每个匹配的文件名相同。
创建安全目录
假设您在/tmp 中创建了自己的目录,然后设置了权限,以便只有您可以使用该目录(见下文)。这安全吗?
$ mkdir /tmp/mystuff
$ chmod 700 /tmp/mystuff
在目录创建和权限更改之间存在一个机会窗口。这导致了几个基于竞争条件的漏洞(攻击者在权限被移除之前以某种方式修改目录)。一些例子包括:
另一个用户用一个硬链接替换mystuff,指向第二个用户拥有的现有文件或目录,然后他们就能读取和控制mystuff目录的内容。哦不 - 我们的秘密不再是秘密了!
然而,在这个特定的例子中,/tmp目录设置了粘滞位,因此其他用户可能无法删除mystuff目录,上述简单的攻击场景是不可能的。这并不意味着创建目录,然后稍后将目录设为私有是安全的!更好的版本是从一开始就原子性地创建具有正确权限的目录 -
$ mkdir -m 700 /tmp/mystuff
如何自动创建父目录?
$ mkdir -p d1/d2/d3
如果它们不存在,将自动创建 d1 和 d2。
我的默认 umask 是 022;这是什么意思?
umask 减去(减少)权限位从 777,并且在使用 open、mkdir 等创建新文件和新目录时使用。因此,022(八进制)表示组和其他权限不包括可写位。每个进程(包括 shell)都有一个当前的 umask 值。在分叉时,子进程继承父进程的 umask 值。
例如,通过在 shell 中将 umask 设置为 077,可以确保将来创建的文件和目录只能被当前用户访问,
$ umask 077
$ mkdir secretdir
作为一个代码示例,假设使用open()创建一个新文件,并且模式位是666(用户、组和其他的写入和读取位):
open("myfile", O_CREAT, S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH);
如果 umask 是八进制 022,那么创建的文件的权限将是 0666 和~022,即。
S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH
我怎样才能从一个文件复制字节到另一个文件?
使用多功能的dd命令。例如,以下命令将从文件/dev/urandom复制 1MB 的数据到文件/dev/null。数据被复制为 1024 个块,每个块大小为 1024 字节。
$ dd if=/dev/urandom of=/dev/null bs=1k count=1024
上面示例中的输入和输出文件都是虚拟的 - 它们不存在于磁盘上。这意味着传输速度不受硬件功率的影响。相反,它们是内核提供的虚拟文件系统的一部分。虚拟文件/dev/urandom提供无限的随机字节流,而虚拟文件/dev/null会忽略写入它的所有字节。/dev/null的常见用途是丢弃命令的输出,
$ myverboseexecutable > /dev/null
另一个常用的/dev 虚拟文件是/dev/zero,它提供无限的零字节流。例如,我们可以对读取内核中的流零字节到进程内存并将字节写回内核而不进行任何磁盘 I/O 的操作系统性能进行基准测试。请注意,吞吐量(约 20GB/s)强烈依赖于块大小。对于小块大小,额外的read和write系统调用的开销将占主导地位。
$ dd if=/dev/zero of=/dev/null bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 0.0539153 s, 19.9 GB/s
当我触摸一个文件时会发生什么?
touch可执行文件如果文件不存在则创建文件,并且还会更新文件的最后修改时间为当前时间。例如,我们可以用当前时间创建一个新的私有文件:
$ umask 077 # all future new files will maskout all r,w,x bits for group and other access
$ touch file123 # create a file if it does not exist, and update its modified time
$ stat file123
File: `file123'
Size: 0 Blocks: 0 IO Block: 65536 regular empty file
Device: 21h/33d Inode: 226148 Links: 1
Access: (0600/-rw-------) Uid: (395606/ angrave) Gid: (61019/ ews)
Access: 2014-11-12 13:42:06.000000000 -0600
Modify: 2014-11-12 13:42:06.001787000 -0600
Change: 2014-11-12 13:42:06.001787000 -0600
touch的一个示例用途是在修改 makefile 中的编译器选项后,强制 make 重新编译未更改的文件。记住,make 是“懒惰的” - 它将比较源文件的修改时间和相应输出文件的修改时间,以确定是否需要重新编译文件。
$ touch myprogram.c # force my source file to be recompiled
$ make
文件系统,第五部分:虚拟文件系统
虚拟文件系统
POSIX 系统,如 Linux 和基于 BSD 的 Mac OSX,包括几个作为文件系统的一部分挂载(可用)的虚拟文件系统。这些虚拟文件系统中的文件不存在于磁盘上;当进程请求目录列表时,它们由内核动态生成。Linux 提供了 3 个主要的虚拟文件系统
/dev - A list of physical and virtual devices (for example network card, cdrom, random number generator)
/proc - A list of resources used by each process and (by tradition) set of system information
/sys - An organized list of internal kernel entities
例如,如果我想要一个连续的 0 流,我可以cat /dev/zero。
如何找出当前有哪些文件系统可用(已挂载)?
使用mount,不带任何选项地使用 mount 会生成一个列表(每行一个文件系统)已挂载的文件系统,包括网络、虚拟和本地(旋转磁盘/基于 SSD 的)文件系统。以下是 mount 的典型输出
$ mount
/dev/mapper/cs241--server_sys-root on / type ext4 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
tmpfs on /dev/shm type tmpfs (rw,rootcontext="system_u:object_r:tmpfs_t:s0")
/dev/sda1 on /boot type ext3 (rw)
/dev/mapper/cs241--server_sys-srv on /srv type ext4 (rw)
/dev/mapper/cs241--server_sys-tmp on /tmp type ext4 (rw)
/dev/mapper/cs241--server_sys-var on /var type ext4 (rw)rw,bind)
/srv/software/Mathematica-8.0 on /software/Mathematica-8.0 type none (rw,bind)
engr-ews-homes.engr.illinois.edu:/fs1-homes/angrave/linux on /home/angrave type nfs (rw,soft,intr,tcp,noacl,acregmin=30,vers=3,sec=sys,sloppy,addr=128.174.252.102)
请注意,每行都包括文件系统类型、文件系统源和挂载点。为了减少这种输出,我们可以将其导入到grep中,只看到与正则表达式匹配的行。
>mount | grep proc # only see lines that contain 'proc'
proc on /proc type proc (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
random 和 urandom 之间的区别?
/dev/random 是一个包含数字生成器的文件,其中熵是从环境噪声中确定的。随机将阻塞/等待,直到从环境中收集到足够的熵。
/dev/urandom 就像 random 一样,但不同之处在于它允许重复(熵阈值较低),因此不会阻塞。
其他文件系统
$ cat /proc/sys/kernel/random/entropy_avail
$ hexdump /dev/random
$ hexdump /dev/urandom
$ cat /proc/meminfo
$ cat /proc/cpuinfo
$ cat /proc/cpuinfo | grep bogomips
$ cat /proc/meminfo | grep Swap
$ cd /proc/self
$ echo $$; cd /proc/12345; cat maps
挂载文件系统
假设我有一个挂接在/dev/cdrom上的文件系统,我想要从中读取。我必须在进行任何操作之前将其挂载到一个目录上。
$ sudo mount /dev/cdrom /media/cdrom
$ mount
$ mount | grep proc
如何挂载磁盘映像?
假设你下载了一个可引导的 Linux 磁盘映像…
wget http://cosmos.cites.illinois.edu/pub/archlinux/iso/2015.04.01/archlinux-2015.04.01-dual.iso
在将文件系统放入 CD 之前,我们可以将文件作为文件系统挂载并浏览其内容。请注意,挂载需要 root 访问权限,因此让我们使用 sudo 来运行它
$ mkdir arch
$ sudo mount -o loop archlinux-2015.04.01-dual.iso ./arch
$ cd arch
在挂载命令之前,arch 目录是新的,显然是空的。挂载后,arch/的内容将从存储在archlinux-2014.11.01-dual.iso文件中的文件和目录中提取出来。需要loop选项,因为我们想要挂载一个常规文件而不是物理磁盘这样的块设备。
loop 选项将原始文件包装为块设备-在这个例子中,我们将在下面找到文件系统是在/dev/loop0下提供的:我们可以通过运行不带任何参数的 mount 命令来检查文件系统类型和挂载选项。我们将将输出导入到grep中,以便只看到包含’arch’的相关输出行(s)
$ mount | grep arch
/home/demo/archlinux-2014.11.01-dual.iso on /home/demo/arch type iso9660 (rw,loop=/dev/loop0)
iso9660 文件系统是最初为光学存储介质(即 CDRom)设计的只读文件系统。尝试更改文件系统的内容将失败
$ touch arch/nocando
touch: cannot touch `/home/demo/arch/nocando': Read-only file system
文件系统,第六部分:内存映射文件和共享内存
操作系统如何将我的进程和库加载到内存中?
通过将文件的内容映射到进程的地址空间。如果许多程序只需要对同一个文件进行读取访问(例如/bin/bash,C 库),那么相同的物理内存可以在多个进程之间共享。
相同的机制可以被程序用来直接将文件映射到内存
如何将文件映射到内存?
下面显示了一个将文件映射到内存的简单程序。需要注意的关键点是:
-
mmap 需要一个文件描述符,所以我们需要先打开文件
-
我们寻找我们想要的大小并写入一个字节,以确保文件足够长
-
完成后调用 munmap 将文件从内存中取消映射。
这个例子还显示了预处理器常量“LINE”和“FILE”,它们保存了当前正在编译的文件的行号和文件名。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
int fail(char *filename, int linenumber) {
fprintf(stderr, "%s:%d %s\n", filename, linenumber, strerror(errno));
exit(1);
return 0; /*Make compiler happy */
}
#define QUIT fail(__FILE__, __LINE__ )
int main() {
// We want a file big enough to hold 10 integers
int size = sizeof(int) * 10;
int fd = open("data", O_RDWR | O_CREAT | O_TRUNC, 0600); //6 = read+write for me!
lseek(fd, size, SEEK_SET);
write(fd, "A", 1);
void *addr = mmap(0, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
printf("Mapped at %p\n", addr);
if (addr == (void*) -1 ) QUIT;
int *array = addr;
array[0] = 0x12345678;
array[1] = 0xdeadc0de;
munmap(addr,size);
return 0;
}
我们的二进制文件的内容可以使用 hexdump 列出
$ hexdump data
0000000 78 56 34 12 de c0 ad de 00 00 00 00 00 00 00 00
0000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000020 00 00 00 00 00 00 00 00 41
细心的读者可能会注意到我们的整数是以最低有效字节格式写入的(因为这是 CPU 的字节序),而且我们分配了一个多出一个字节的文件!
PROT_READ | PROT_WRITE选项指定了虚拟内存保护。选项PROT_EXEC(这里没有使用)可以设置为允许 CPU 在内存中执行指令(例如,如果您映射了一个可执行文件或库,这将非常有用)。
内存映射文件的优势是什么
对于许多应用程序,主要优势是:
简化编码-文件数据立即可用。无需解析传入数据并将其存储在新的内存结构中。
文件共享-内存映射文件在多个进程之间共享相同数据时特别高效。
对于简单的顺序处理,内存映射文件不一定比标准的“基于流”的read / fscanf 等方法更快。
如何在父进程和子进程之间共享内存?
简单-使用mmap而不是文件-只需指定 MAP_ANONYMOUS 和 MAP_SHARED 选项!
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h> /* mmap() is defined in this header */
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
int main() {
int size = 100 * sizeof(int);
void *addr = mmap(0, size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
printf("Mapped at %p\n", addr);
int *shared = addr;
pid_t mychild = fork();
if (mychild > 0) {
shared[0] = 10;
shared[1] = 20;
} else {
sleep(1); // We will talk about synchronization later
printf("%d\n", shared[1] + shared[0]);
}
munmap(addr,size);
return 0;
}
我可以使用共享内存进行 IPC 吗?
是的!作为一个简单的例子,你可以只保留几个字节,并在想要子进程退出时更改共享内存中的值。共享内存是一种非常高效的进程间通信形式,因为没有复制开销-这两个进程实际上共享相同的物理内存帧。
文件系统,第七部分:可扩展和可靠的文件系统
可靠的单磁盘文件系统
内核如何以及为什么缓存文件系统?
大多数文件系统在物理内存中缓存大量磁盘数据。在这方面,Linux 特别极端:所有未使用的内存都被用作巨大的磁盘缓存。
磁盘缓存可能会对整个系统性能产生重大影响,因为磁盘 I/O 速度很慢。这对于旋转磁盘上的随机访问请求尤其如此,其中磁盘读写延迟由移动读写磁盘头到正确位置所需的寻道时间主导。
为了提高效率,内核会缓存最近使用的磁盘块。对于写入,我们必须在性能和可靠性之间进行权衡:磁盘写入也可以被缓存(“写回缓存”),其中修改后的磁盘块存储在内存中直到被驱逐。或者可以采用“写穿缓存”策略,其中磁盘写入立即发送到磁盘。后者比写回缓存更安全(因为文件系统修改会快速存储到持久介质),但比写回缓存慢;如果写入被缓存,那么它们可以被延迟,并且可以根据每个磁盘块的物理位置进行高效调度。
请注意,这是一个简化的描述,因为固态硬盘(SSD)可以用作辅助写回缓存。
无论是固态硬盘(SSD)还是旋转硬盘,在读取或写入顺序数据时都具有改进的性能。因此,操作系统通常可以使用预读策略来分摊读取请求成本(例如旋转硬盘的时间成本),并请求每个请求的几个连续磁盘块。通过在用户应用程序需要下一个磁盘块之前发出下一个磁盘块的 I/O 请求,可以减少表面磁盘 I/O 延迟。
我的数据很重要!我可以强制磁盘写入保存到物理介质并等待完成吗?
是的(几乎)。调用sync请求将文件系统更改写入(刷新)到磁盘。但并非所有操作系统都会遵守此请求,即使数据已从内核缓冲区中驱逐,磁盘固件也会使用内部磁盘缓存,或者可能尚未完成更改物理介质。
注意,您还可以使用fsync(int fd)请求将与特定文件描述符相关的所有更改刷新到磁盘。
如果我的磁盘在重要操作中失败怎么办?
别担心,大多数现代文件系统都有一种称为日志的东西来解决这个问题。文件系统在完成潜在昂贵的操作之前,会将其要做的事情写在日志中。在崩溃或故障的情况下,可以逐步查看日志并查看哪些文件损坏并修复它们。这是一种在关键数据存在且没有明显备份的情况下挽救硬盘的方法。
磁盘故障的可能性有多大?
磁盘故障是用“平均故障时间”来衡量的。对于大型数组,平均故障时间可能会非常短。例如,如果 MTTF(单个磁盘)= 30,000 小时,则 MTTF(100 个磁盘)= 30000/100 = 300 小时,即约 12 天!
冗余
如何保护我的数据免受磁盘故障?
很简单!数据存储两次!这是“RAID-1”磁盘阵列的主要原则。RAID 是廉价磁盘冗余阵列的缩写。通过将写入复制到一个磁盘并将写入复制到另一个磁盘(备份磁盘),数据恰好有两份副本。如果一个磁盘故障,另一个磁盘将作为唯一副本,直到可以重新克隆。读取数据更快(因为数据可以从任一磁盘请求),但写入可能会慢两倍(现在每个磁盘块写入需要发出两个写命令),并且与使用单个磁盘相比,每字节存储成本翻了一番。
另一个常见的 RAID 方案是 RAID-0,意味着文件可以分割在两个磁盘中,但如果任何一个磁盘故障,那么文件将无法恢复。这样做的好处是可以将写入时间减半,因为文件的一部分可以写入硬盘一,另一部分可以写入硬盘二。
还常常将这些系统结合在一起。如果你有很多硬盘,考虑 RAID-10。这是指有两个 RAID-1 系统,但这些系统在彼此之间以 RAID-0 连接。这意味着你可以从减速中获得大致相同的速度,但现在任何一个磁盘都可以故障,你可以恢复该磁盘。(如果来自相对 RAID 分区的两个磁盘故障,有可能进行恢复,尽管我们大多数时候不依赖它)。
RAID-3 是什么?
RAID-3 使用奇偶校验码而不是镜像数据。对于每 N 位写入,我们将写入一个额外的位,即“奇偶校验位”,以确保写入的 1 的总数是偶数。奇偶校验位被写入到额外的磁盘上。如果任何一个磁盘(包括奇偶校验磁盘)丢失,那么它的内容仍然可以使用其他磁盘的内容计算出来。

RAID-3 的一个缺点是每当写入一个磁盘块时,奇偶校验块也总是会被写入。这意味着实际上有一个单独的磁盘瓶颈。实际上,这更有可能导致故障,因为一个磁盘被 100%使用,一旦该磁盘故障,其他磁盘更容易发生故障。
RAID-3 对数据丢失有多安全?
单个磁盘故障不会导致数据丢失(因为有足够的数据可以从剩余的磁盘重建阵列)。当两个磁盘不可用时,由于不再有足够的数据来重建阵列,数据丢失将发生。我们可以根据修复时间计算两个磁盘故障的概率,这不仅包括插入新磁盘的时间,还包括重建整个阵列内容所需的时间。
MTTF = mean time to failure
MTTR = mean time to repair
N = number of original disks
p = MTTR / (MTTF-one-disk / (N-1))
使用典型数字(MTTR=1 天,MTTF=1000 天,N-1=9,p=0.009
在重建过程中,另一块驱动器出现故障的概率为 1%(在这一点上,你最好希望你仍然有原始数据的可访问备份)。
在实践中,修复过程中第二次故障的概率可能更高,因为重建阵列是 I/O 密集型的(并且在正常 I/O 请求活动之上)。这种更高的 I/O 负载也会对磁盘阵列造成压力
RAID-5 是什么?
RAID-5 类似于 RAID-3,只是检查块(奇偶校验信息)分配给不同的磁盘用于不同的块。检查块在磁盘阵列中“旋转”。RAID-5 提供比 RAID-3 更好的读写性能,因为不再有单个奇偶校验磁盘的瓶颈。唯一的缺点是你需要更多的磁盘来设置这个,并且需要使用更复杂的算法。

分布式存储
故障是常见情况,谷歌报告称每年有 2-10%的磁盘故障,现在将这个数字乘以单个仓库中的 60,000 多个磁盘…必须经受住不仅是磁盘的故障,还有服务器机架或整个数据中心的故障
解决方案简单冗余(每个文件有 2 或 3 个副本),例如,谷歌 GFS(2001 年)更有效的冗余(类似于 RAID 3++),例如,Google Colossus 文件系统(约 2010 年):可定制的复制,包括带有 1.5 倍冗余的 Reed-Solomon 编码
文件系统,第八部分:从安卓设备中删除预装的恶意软件
案例研究:从安卓设备中删除恶意软件
本节利用本 wikibook 中讨论的文件系统特性和系统编程工具来查找并删除安卓平板电脑中的不需要的恶意软件。
免责声明。在尝试修改您的平板电脑之前,请确保备份设备上的任何有价值的信息。不建议修改系统设置和系统文件。尝试使用本案例研究指南修改设备可能导致您的平板电脑共享、丢失或损坏数据。此外,您的平板电脑可能会出现功能异常或完全停止工作。请自行承担使用本案例研究的风险。作者对这些指南中包含的指令的正确性或完整性不承担任何责任并不提供任何保证。作者对本指南中描述或链接的任何软件,包括外部第三方软件,不承担任何责任并不提供任何保证。
背景
从亚马逊购买的 E97 安卓平板电脑出现了一些奇怪的毛病。最明显的是,浏览器应用程序总是在 gotoamazing.com 打开一个网站,而不是在应用程序的首选项中设置的主页(称为浏览器“劫持”)。我们能否利用这本 wikibook 中的知识来理解这种不需要的行为是如何发生的,还能从设备中删除不需要的预装应用程序?
使用的工具
虽然可能可以使用远程连接的 USB 设备上安装的安卓开发工具,但本指南仅使用平板电脑上的系统工具。安装了以下应用程序 -
-
Malwarebytes - 一个免费的漏洞和恶意软件工具。
-
终端模拟器 - 一个简单的终端窗口,让我们在平板电脑上获得 shell 访问权限。
-
KingRoot - 一个利用 Linux 内核中已知漏洞获取 root 权限的工具。
安装任何应用都可能允许任意代码执行,如果它能够突破安卓安全模型。在上面提到的应用中,KingRoot 是最极端的例子,因为它利用系统漏洞来获取我们的目的的 root 权限。然而,在这样做的同时,它也可能是最有问题的工具之一,我们要相信它不会安装任何自己的恶意软件。一个潜在更安全的选择是使用github.com/android-rooting-tools/
终端概述
最有用的命令是su grep mount和安卓的包管理器工具pm。
-
grep -s abc * /(在当前目录和直接子目录中搜索
abc) -
su(又名“切换用户”成为 root - 需要一个已 root 的设备)
-
mount -o rw,remount /system(允许/system 分区可写)
-
pm disable(又名“包管理器”禁用安卓应用程序包)
文件系统布局概述
在运行安卓 4.4.2 的这个特定平板电脑上,预装的应用程序是不可修改的,并且位于
/system/app/
/system/priv-app/
偏好设置和应用数据存储在/data分区中。每个应用程序通常打包在一个 apk 文件中,这本质上是一个 zip 文件。当应用程序安装时,代码会被扩展成一个可以被安卓虚拟机直接解析的文件。二进制代码(至少对于这个特定的虚拟机)具有 odex 扩展名。
我们可以搜索已安装的系统应用程序的代码,查找字符串’gotoamazing’
grep -s gotoamazing /system/app/* /system/priv-app/*
这没有找到任何东西;看来这个字符串没有硬编码到给定系统应用程序的源代码中。为了验证我们是否能找到
让我们检查所有已安装应用的数据区域
cd /data/data
grep -s gotoamazing * */* */*/*
产生了以下结果
data/com.android.browser/shared_prefs/xbservice.xml: <string name="URL">http://www.gotoamazing...
-s 选项“静默选项”可以阻止 grep 抱怨尝试 grep 目录和其他无效文件。请注意,我们也可以使用-r 来递归搜索目录,但使用文件通配符(shell 的*通配符扩展)很有趣。
现在我们有了进展!看起来这个字符串是’app’com.android.browser’的一部分,但让我们也找出哪个应用程序二进制代码打开了’xbservice’首选项。也许这个不受欢迎的服务隐藏在另一个应用程序中,并且成功地作为浏览器的扩展秘密加载?
让我们寻找包含 xbservice 的任何文件。这次,我们将在包括’app’的/system 目录中递归搜索
grep -r -s xbservice /system/*app*
Binary file /system/app/Browser.odex matches
最后 - 看起来出厂浏览器已经预装了主页劫持。让我们卸载它。为此,让我们成为 root。
$ su
pm list packages -s
Android 的包管理器有许多命令和选项。上面的例子列出了当前安装的所有系统应用程序。我们可以使用以下命令卸载浏览器应用程序
pm disable com.android.browser
pm uninstall com.android.browser
使用pm list packages可以列出所有安装的软件包(使用-s选项只查看系统软件包)。我们禁用了以下系统应用程序。当然,我们无法保证我们成功删除了所有不需要的软件,或者其中一个是误报。因此,我们不建议在这样的平板电脑上存储敏感信息。
-
com.android.browser
-
com.adups.fota.sysoper
-
elink.com
-
com.google.android.apps.cloudprint
-
com.mediatek.CrashService
-
com.get.googleApps
-
com.adups.fota(可以在将来安装任意项目的远程包)。
-
com.mediatek.appguide.plugin
很可能你可以使用pm enable package-name或pm install和/system/app 或/system/priv-app 中的相关.apk 文件来重新启用软件包。
文件系统,第九部分:磁盘块示例
正在建设中
请问您能解释一下基于简单 i-node 的文件系统中文件内容是如何存储的吗?
当然!为了回答这个问题,我们将构建一个虚拟磁盘,然后编写一些 C 代码来访问其内容。我们的文件系统将把可用的字节划分为 inode 的空间和一个更大的磁盘块空间。每个磁盘块将是 4096 字节-
// Disk size:
#define MAX_INODE (1024)
#define MAX_BLOCK (1024*1024)
// Each block is 4096 bytes:
typedef char[4096] block_t;
// A disk is an array of inodes and an array of disk blocks:
struct inode[MAX_INODE] inodes;
block[MAX_BLOCK] blocks;
为了清晰起见,我们在这个代码示例中不会使用’unsigned’。我们的固定大小的 inode 将包含文件的字节大小,权限,用户,组信息,时间元数据。对于手头的问题最相关的是,它还将包括十个指向磁盘块的指针,我们将用它们来引用实际文件的内容!
struct inode {
int[10] directblocks; // indices for the block array i.e. where to the find the file's content
long size;
// ... standard inode meta-data e.g.
int mode, userid,groupid;
time_t ctime,atime,mtime;
}
现在我们可以解决如何读取文件偏移量position处的一个字节:
char readbyte(inode*inode,long position) {
if(position <0 || position >= inode->size) return -1; // invalid offset
int block_count = position / 4096,offset = position % 4096;
// block count better be 0..9 !
int physical_idx = lookup_physical_block_index(inode, block_count );
// sanity check that the disk block index is reasonable...
assert(physical_idx >=0 && physical_idx < MAX_BLOCK);
// read the disk block from our virtual disk 'blocks' and return the specific byte
return blocks[physical_idx][offset];
}
我们的 lookup_physical_block 的初始版本很简单-我们可以使用我们的 10 个直接块的表!
int lookup_physical_block_index(inode*inode, int block_count) {
assert(block_count>=0 && block_count < 10);
return inode->directblocks[ block_count ]; // returns an index value between [0,MAX_BLOCK)
}
这种简单的表示是合理的,只要我们可以用十个块来表示所有可能的文件,即最多 40KB。那么更大的文件呢?我们需要 inode 结构始终保持相同的大小,因此只是将现有的直接块数组增加到 20 个,大致会使我们的 inode 大小翻倍。如果我们大多数的文件需要少于 10 个块,那么我们的 inode 存储现在就是浪费的。为了解决这个问题,我们将使用一个称为间接块的磁盘块来扩展我们可以使用的指针数组。我们只需要这个来处理大于 40KB 的文件。
struct inode {
int[10] directblocks; // if size<4KB then only the first one is valid
int indirectblock; // valid value when size >= 40KB
int size;
...
}
间接块只是一个普通的磁盘块,但我们将用它来保存指向磁盘块的指针。在这种情况下,我们的指针只是整数,因此我们需要将指针转换为整数指针:
int lookup_physical_block_index(inode*inode, int block_count) {
assert(sizeof(int)==4); // Warning this code assumes an index is 4 bytes!
assert(block_count>=0 && block_count < 1024 + 10); // 0 <= block_count< 1034
if( block_count < 10)
return inode->directblocks[ block_count ];
// read the indirect block from disk:
block_t* oneblock = & blocks[ inode->indirectblock ];
// Treat the 4KB as an array of 1024 pointers to other disk blocks
int* table = (int*) oneblock;
// Look up the correct entry in the table
// Offset by 10 because the first 10 blocks of data are already
// accounted for
return table[ block_count - 10 ];
}
对于典型的文件系统,我们的索引值是 32 位,即 4 字节。因此,在 4096 字节中,我们可以存储 4096 / 4 = 1024 个条目。这意味着我们的间接块可以引用 1024 * 4KB = 4MB 的数据。通过前面的十个直接块,因此我们可以容纳文件大小达到 40KB + 1024 * 4KB= 4136KB。对于小于这个大小的文件,一些后面的表条目可能无效。
对于更大的文件,我们可以使用两个间接块。然而,有一个更好的选择,可以让我们有效地扩展到大文件。我们将包括一个双间接指针,如果这还不够,还有一个三重间接指针。双间接指针意味着我们有一个包含用作 1024 个条目的磁盘块的 1024 个条目的表。这意味着我们可以引用 1024*1024 个数据块。
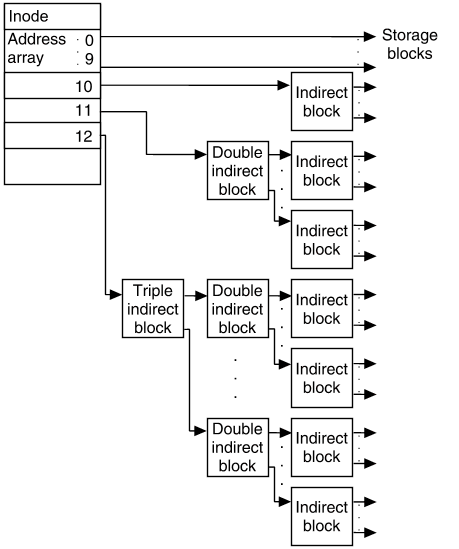
(来源:uw714doc.sco.com/en/FS_admin/graphics/s5chain.gif)
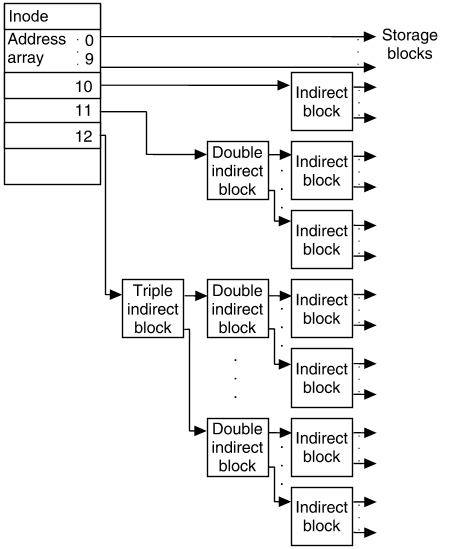{kind=link}
int lookup_physical_block_index(inode*inode, int block_count) {
if( block_count < 10)
return inode->directblocks[ block_count ];
// Use indirect block for the next 1024 blocks:
// Assumes 1024 ints can fit inside each block!
if( block_count < 1024 + 10) {
int* table = (int*) & blocks[ inode->indirectblock ];
return table[ block_count - 10 ];
}
// For huge files we will use a table of tables
int i = (block_count - 1034) / 1024 , j = (block_count - 1034) % 1024;
assert(i<1024); // triple-indirect is not implemented here!
int* table1 = (int*) & blocks[ inode->doubleindirectblock ];
// The first table tells us where to read the second table ...
int* table2 = (int*) & blocks[ table1[i] ];
return table2[j];
// For gigantic files we will need to implement triple-indirect (table of tables of tables)
}
请注意,使用双间接读取一个字节需要 3 次磁盘块读取(两个表和实际数据块)。
文件系统复习问题
主题
-
超级块
-
数据块
-
索引节点
-
相对路径
-
文件元数据
-
硬链接和软链接
-
权限位
-
与目录一起工作
-
虚拟文件系统
-
可靠的文件系统
-
RAID
问题
-
15 个直接块,2 个双间接块,3 个三重间接块,4kb 块和 4 字节条目的文件系统上文件可以有多大?(假设有足够的无限块)
-
超级块是什么?索引节点?数据块?
-
如何简化
/./proc/../dev/./random/ -
在 ext2 中,索引节点中存储了什么,目录条目中存储了什么?
-
/sys,/proc,/dev/random 和/dev/urandom 是什么?
-
权限位是什么?
-
如何使用 chmod 设置用户/组/所有者的读/写/执行权限?
-
“dd”命令是做什么的?
-
硬链接和符号链接之间有什么区别?文件需要存在吗?
-
"ls -l"显示目录中每个文件的大小。大小存储在目录中还是文件的索引节点中?
十、信号
进程控制,第一部分:使用信号的等待宏
等待宏
我能找出我的子进程的退出值吗?
您可以找到子进程退出值的最低 8 位(main()的返回值或包含在exit()中的值):使用“等待宏” - 通常会使用“WIFEXITED”和“WEXITSTATUS”。有关更多信息,请参阅wait/waitpid手册页。
int status;
pid_t child = fork();
if (child == -1) return 1; //Failed
if (child > 0) { /* I am the parent - wait for the child to finish */
pid_t pid = waitpid(child, &status, 0);
if (pid != -1 && WIFEXITED(status)) {
int low8bits = WEXITSTATUS(status);
printf("Process %d returned %d" , pid, low8bits);
}
} else { /* I am the child */
// do something interesting
execl("/bin/ls", "/bin/ls", ".", (char *) NULL); // "ls ."
}
一个进程只能有 256 个返回值,其余的位是信息性的。
位移
请注意,没有必要记住这一点,这只是对状态变量内部存储信息的高级概述。
/如果 WIFEXITED(STATUS),则为状态的低 8 位。/
#define __WEXITSTATUS(status) (((status) & 0xff00) >> 8)
/如果 WIFSIGNALED(STATUS),则为终止信号。/
#define __WTERMSIG(status) ((status) & 0x7f)
/如果 WIFSTOPPED(STATUS),则为停止子进程的信号。/
#define __WSTOPSIG(status) __WEXITSTATUS(status)
/如果 STATUS 指示正常终止,则为非零。/
#define __WIFEXITED(status) (__WTERMSIG(status) == 0)
内核有一种内部方式来跟踪发出信号、退出或停止的情况。该 API 被抽象化,以便内核开发人员可以随意更改。
小心。
请记住,如果前提条件得到满足,那么宏才有意义。这意味着如果进程被发出信号,进程的退出状态将不会被定义。宏不会为您进行检查,因此需要编程来确保逻辑正确。
信号
什么是信号?
信号是内核为我们提供的一种构造。它允许一个进程异步地向另一个进程发送信号(想象一条消息)。如果该进程想要接受信号,它可以,然后对于大多数信号,可以决定如何处理该信号。这里是一个信号的简短列表(非全面)。
| 名称 | 默认操作 | 通常用例 |
|---|---|---|
SIGINT | 终止进程(可捕获) | 告诉进程停止 |
SIGQUIT | 终止进程(可捕获) | 告诉进程停止 |
SIGSTOP | 停止进程(无法捕获) | 停止进程以便继续 |
SIGCONT | 继续进程 | 继续运行进程 |
SIGKILL | 终止进程(无法忽略) | 你想让你的进程消失 |
我能暂停我的子进程吗?
是的!您可以通过发送 SIGSTOP 信号来暂时暂停运行中的进程。如果成功,它将冻结一个进程;即进程将不再分配任何 CPU 时间。
要允许进程恢复执行,请发送 SIGCONT 信号。
例如,这是一个每秒慢慢打印一个点的程序,最多 59 个点。
#include <unistd.h>
#include <stdio.h>
int main() {
printf("My pid is %d\n", getpid() );
int i = 60;
while(--i) {
write(1, ".",1);
sleep(1);
}
write(1, "Done!",5);
return 0;
}
我们将首先在后台启动进程(注意末尾的&)。然后通过使用 kill 命令从 shell 进程发送信号给它。
>./program &
My pid is 403
...
>kill -SIGSTOP 403
>kill -SIGCONT 403
如何从 C 中杀死/停止/暂停我的子进程?
在 C 中,使用kill POSIX 调用向子进程发送信号,
kill(child, SIGUSR1); // Send a user-defined signal
kill(child, SIGSTOP); // Stop the child process (the child cannot prevent this)
kill(child, SIGTERM); // Terminate the child process (the child can prevent this)
kill(child, SIGINT); // Equivalent to CTRL-C (by default closes the process)
正如我们上面看到的,在 shell 中也有一个 kill 命令,例如获取正在运行的进程列表,然后终止进程 45 和进程 46
ps
kill -l
kill -9 45
kill -s TERM 46
如何检测“CTRL-C”并优雅地清理?
我们将在后面回到信号 - 这只是一个简短的介绍。在 Linux 系统上,如果您有兴趣了解更多信息,请参阅man -s7 signal(例如系统和库调用的异步信号安全列表)。
信号处理程序内部的可执行代码有严格的限制。大多数库和系统调用都不是“异步信号安全”的 - 它们不能在信号处理程序内部使用,因为它们不是可重入安全的。在单线程程序中,信号处理瞬间中断程序执行,以执行信号处理程序代码。假设您的原始程序在执行malloc库代码时被中断;malloc 使用的内存结构将不处于一致状态。在信号处理程序中调用printf(它使用malloc)是不安全的,并将导致“未定义行为”,即不再是一个有用的、可预测的程序。实际上,您的程序可能会崩溃,计算或生成不正确的结果,或者停止运行(“死锁”),具体取决于在执行信号处理程序代码时您的程序正在执行什么。
信号处理程序的一个常见用途是设置一个布尔标志,该标志偶尔被轮询(读取),作为程序正常运行的一部分。例如,
int pleaseStop ; // See notes on why "volatile sig_atomic_t" is better
void handle_sigint(int signal) {
pleaseStop = 1;
}
int main() {
signal(SIGINT, handle_sigint);
pleaseStop = 0;
while ( ! pleaseStop) {
/* application logic here */
}
/* cleanup code here */
}
上述代码在纸上看起来可能是正确的。但是,我们需要向编译器和将执行main()循环的 CPU 核心提供提示。我们需要防止编译器优化:表达式! pleaseStop似乎是一个循环不变量,即永远为真,因此可以简化为true。其次,我们需要确保pleaseStop的值不是使用 CPU 寄存器缓存的,而是始终从主存中读取和写入。sig_atomic_t类型意味着变量的所有位可以被读取或修改为“原子操作” - 一个不可中断的操作。不可能读取由一些新位值和旧位值组成的值。
通过使用正确类型的volatile sig_atomic_t指定pleaseStop,我们可以编写可移植的代码,其中主循环将在信号处理程序返回后退出。在大多数现代平台上,sig_atomic_t类型可以与int一样大,但在嵌入式系统上,它可以与char一样小,并且只能表示(-127 至 127)的值。
volatile sig_atomic_t pleaseStop;
这种模式的两个示例可以在“COMP”中找到,这是一个基于终端的 1Hz 4 位计算机(github.com/gto76/comp-cpp/blob/1bf9a77eaf8f57f7358a316e5bbada97f2dc8987/src/output.c#L121)。使用了两个布尔标志。一个用于标记SIGINT(CTRL-C)的传递,并优雅地关闭程序,另一个用于标记SIGWINCH信号以检测终端调整大小并重新绘制整个显示。
信号,第二部分:未决信号和信号掩码
信号深入解析
我如何了解更多关于信号的信息?
Linux 手册中讨论了第 2 节中的信号系统调用。第 7 节中还有一篇较长的文章(尽管在 OSX/BSD 中没有):
man -s7 signal
信号术语
-
生成-信号是由 kill 系统调用在内核中创建的。
-
未决-尚未传递,但即将传递
-
已屏蔽-因为没有信号处理方式允许信号被传递,所以尚未传递
-
已传递-传递到进程,正在执行描述的操作
-
捕获-当进程阻止信号摧毁它并做其他事情时
进程的信号处理方式是什么?
对于每个进程,每个信号都有一个处理方式,这意味着当信号传递到进程时将发生什么操作。例如,默认的 SIGINT 处理方式是终止它。信号处理方式可以通过调用 signal()(这很简单,但在不同的 POSIX 架构上实现上有微妙的变化,也不建议用于多线程程序)或sigaction(稍后讨论)来更改。您可以将进程对所有可能信号的处理方式想象成一个函数指针条目表(每个可能信号一个)。
信号的默认处理方式可以是忽略信号、停止进程、继续已停止的进程、终止进程,或者终止进程并转储一个“核心”文件。请注意,核心文件是进程内存状态的表示,可以使用调试器进行检查。
可以排队多个信号吗?
不是-但是可能有信号处于未决状态。如果信号处于未决状态,这意味着它尚未传递到进程。信号处于未决状态的最常见原因是进程(或线程)当前已阻止了该特定信号。
如果特定信号,例如 SIGINT,处于未决状态,则不可能再次排队相同的信号。
是可能有多个不同类型的信号处于未决状态。例如,SIGINT 和 SIGTERM 信号可能是未决的(即尚未传递到目标进程)
如何屏蔽信号?
信号可以通过设置进程信号掩码或者在编写多线程程序时设置线程信号掩码来屏蔽(意味着它们将保持在未决状态)。
线程/子进程中的处理方式
创建新线程时会发生什么?
新线程继承了调用线程的掩码的副本
pthread_sigmask( ... ); // set my mask to block delivery of some signals
pthread_create( ... ); // new thread will start with a copy of the same mask
分叉时会发生什么?
子进程继承了父进程的信号处理方式。换句话说,如果在分叉之前安装了 SIGINT 处理程序,那么子进程在传递 SIGINT 时也会调用处理程序。
请注意,分叉期间子进程的未决信号不会被继承。
执行期间会发生什么?
信号掩码和信号处理方式都会传递到 exec-ed 程序。www.gnu.org/software/libc/manual/html_node/Executing-a-File.html#Executing-a-File 未决信号也会被保留。信号处理程序会被重置,因为原始处理程序代码随着旧进程一起消失了。
分叉期间会发生什么?
子进程继承了父进程的信号处理方式和父进程的信号掩码的副本。
例如,如果在父进程中阻塞了SIGINT,那么在子进程中也会被阻塞。例如,如果父进程为 SIG-INT 安装了处理程序(回调函数),那么子进程也会执行相同的行为。
但是未决信号不会被子进程继承。
如何在单线程程序中屏蔽信号?
使用sigprocmask!使用 sigprocmask,您可以设置新的掩码,向进程掩码添加新的要屏蔽的信号,并解除当前被屏蔽的信号。您还可以通过传递非空值来确定现有掩码(并在以后使用)。
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);`
来自 sigprocmask 的 Linux 手册页,
SIG_BLOCK: The set of blocked signals is the union of the current set and the set argument.
SIG_UNBLOCK: The signals in set are removed from the current set of blocked signals. It is permissible to attempt to unblock a signal which is not blocked.
SIG_SETMASK: The set of blocked signals is set to the argument set.
sigset 类型的行为类似于位图,只是使用函数而不是使用&和|来显式设置和取消位。
在修改一个位之前忘记初始化信号集是一个常见的错误。例如,
sigset_t set, oldset;
sigaddset(&set, SIGINT); // Ooops!
sigprocmask(SIG_SETMASK, &set, &oldset)
正确的代码将集合初始化为全部打开或全部关闭。例如,
sigfillset(&set); // all signals
sigprocmask(SIG_SETMASK, &set, NULL); // Block all the signals!
// (Actually SIGKILL or SIGSTOP cannot be blocked...)
sigemptyset(&set); // no signals
sigprocmask(SIG_SETMASK, &set, NULL); // set the mask to be empty again
如何在多线程程序中阻止信号?
在多线程程序中阻止信号与单线程程序类似:
-
使用 pthread_sigmask 而不是 sigprocmask
-
阻止所有线程中的信号,以防止其异步传递
确保信号在所有线程中被阻止的最简单方法是在创建新线程之前在主线程中设置信号掩码
sigemptyset(&set);
sigaddset(&set, SIGQUIT);
sigaddset(&set, SIGINT);
pthread_sigmask(SIG_BLOCK, &set, NULL);
// this thread and the new thread will block SIGQUIT and SIGINT
pthread_create(&thread_id, NULL, myfunc, funcparam);
就像我们在 sigprocmask 中看到的那样,pthread_sigmask 包括一个“how”参数,用于定义如何使用信号集:
pthread_sigmask(SIG_SETMASK, &set, NULL) - replace the thread's mask with given signal set
pthread_sigmask(SIG_BLOCK, &set, NULL) - add the signal set to the thread's mask
pthread_sigmask(SIG_UNBLOCK, &set, NULL) - remove the signal set from the thread's mask
在多线程程序中如何传递待处理的信号?
信号被传递到任何未阻止该信号的信号线程。
如果两个或更多线程可以接收信号,那么哪个线程将被中断是任意的!
信号,第三部分:触发信号
如何从 shell 发送信号给进程?
您已经知道发送SIG_INT的一种方法,只需在 shell 中键入CTRL-C。您还可以使用kill(如果知道进程 ID)和killall(如果知道进程名称)。
# First let's use ps and grep to find the process we want to send a signal to
$ ps au | grep myprogram
angrave 4409 0.0 0.0 2434892 512 s004 R+ 2:42PM 0:00.00 myprogram 1 2 3
#Send SIGINT signal to process 4409 (equivalent of `CTRL-C`)
$ kill -SIGINT 4409
#Send SIGKILL (terminate the process)
$ kill -SIGKILL 4409
$ kill -9 4409
killall类似,只是它是根据程序名称匹配。下面的两个例子,发送SIGINT然后SIGKILL来终止正在运行myprogram的进程。
# Send SIGINT (SIGINT can be ignored)
$ killall -SIGINT myprogram
# SIGKILL (-9) cannot be ignored!
$ killall -9 myprogram
如何从正在运行的 C 程序发送信号给进程?
使用raise或kill
int raise(int sig); // Send a signal to myself!
int kill(pid_t pid, int sig); // Send a signal to another process
对于非根进程,信号只能发送给相同用户的进程,即你不能随便 SIGKILL 我的进程!参见 kill(2)即 man -s2 以获取更多详细信息。
如何向特定线程发送信号?
使用pthread_kill
int pthread_kill(pthread_t thread, int sig)
在下面的示例中,执行func的新创建的线程将被SIGINT中断。
pthread_create(&tid, NULL, func, args);
pthread_kill(tid, SIGINT);
pthread_kill(pthread_self(), SIGKILL); // send SIGKILL to myself
pthread_kill(threadid,SIGKILL)会杀死进程还是线程?
它将杀死整个进程。尽管单个线程可以设置信号掩码,但信号处理(每个信号执行的处理程序/动作表)是每个进程而不是每个线程。这意味着sigaction可以从任何线程调用,因为您将为进程中的所有线程设置信号处理程序。
如何捕获(处理)信号?
您可以选择异步或同步地处理挂起的信号。
安装信号处理程序以异步处理信号使用sigaction(或者,对于简单的示例,signal)。
同步捕获挂起信号使用sigwait(它会阻塞,直到信号被传递)或signalfd(它也会阻塞并提供一个文件描述符,可以使用read()来检索挂起的信号)。
参见Signals, Part 4以获取使用sigwait的示例
信号,第四部分:Sigaction
我如何使用sigaction?
您应该使用sigaction而不是signal,因为它具有更好定义的语义。不同操作系统上的signal会执行不同的操作,这是不好的,sigaction更具可移植性,如果需要,对于线程更好地定义。
要更改进程的“信号处理方式” - 即当信号传递到您的进程时会发生什么 - 使用sigaction
您可以使用系统调用sigaction来设置信号的当前处理程序,或者读取特定信号的当前信号处理程序。
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
sigaction 结构包括两个回调函数(我们只会看’handler’版本),一个信号掩码和一个标志字段。
struct sigaction {
void (*sa_handler)(int);
void (*sa_sigaction)(int, siginfo_t *, void *);
sigset_t sa_mask;
int sa_flags;
};
我如何将signal调用转换为等效的sigaction调用?
假设您为警报信号安装了信号处理程序,
signal(SIGALRM, myhandler);
等效的sigaction代码是:
struct sigaction sa;
sa.sa_handler = myhandler;
sigemptyset(&sa.sa_mask);
sa.sa_flags = 0;
sigaction(SIGALRM, &sa, NULL)
但是,我们通常也可以设置掩码和标志字段。掩码是在信号处理程序执行期间使用的临时信号掩码。SA_RESTART 标志将自动重新启动一些(但不是所有)否则会提前返回(带有 EINTR 错误)的系统调用。后者意味着我们可以在一定程度上简化其余代码,因为可能不再需要重启循环。
sigfillset(&sa.sa_mask);
sa.sa_flags = SA_RESTART; /* Restart functions if interrupted by handler */
我如何使用 sigwait?
Sigwait 可以用来一次读取一个挂起的信号。sigwait用于同步等待信号,而不是在回调中处理它们。多线程程序中典型的 sigwait 用法如下所示。请注意,线程信号掩码首先被设置(并将被新线程继承)。这可以防止信号被传递,因此它们将保持挂起状态,直到调用 sigwait。还要注意,相同的设置 sigset_t 变量被 sigwait 使用 - 除了设置被阻塞信号的集合之外,它被用作 sigwait 可以捕获和返回的信号集合。
编写自定义信号处理线程(如下面的示例)的一个优点是,现在您可以使用更多的 C 库和系统函数,否则不能安全地在信号处理程序中使用,因为它们不是异步信号安全的。
基于http://pubs.opengroup.org/onlinepubs/009695399/functions/pthread_sigmask.html
static sigset_t signal_mask; /* signals to block */
int main (int argc, char *argv[])
{
pthread_t sig_thr_id; /* signal handler thread ID */
sigemptyset (&signal_mask);
sigaddset (&signal_mask, SIGINT);
sigaddset (&signal_mask, SIGTERM);
pthread_sigmask (SIG_BLOCK, &signal_mask, NULL);
/* New threads will inherit this thread's mask */
pthread_create (&sig_thr_id, NULL, signal_thread, NULL);
/* APPLICATION CODE */
...
}
void *signal_thread (void *arg)
{
int sig_caught; /* signal caught */
/* Use same mask as the set of signals that we'd like to know about! */
sigwait(&signal_mask, &sig_caught);
switch (sig_caught)
{
case SIGINT: /* process SIGINT */
...
break;
case SIGTERM: /* process SIGTERM */
...
break;
default: /* should normally not happen */
fprintf (stderr, "\nUnexpected signal %d\n", sig_caught);
break;
}
}
信号复习问题
主题
-
信号
-
信号处理程序安全
-
信号处理
-
信号状态
-
在 Forking/Exec 时的挂起信号
-
在 Forking/Exec 时的信号处理
-
在 C 中引发信号
-
在多线程程序中引发信号
问题
-
什么是信号?
-
在 UNIX 下如何处理信号?(奖励:Windows 呢?)
-
函数是什么意思信号处理程序安全
-
进程信号处理是什么?
-
我如何在单线程程序中改变信号处理?多线程呢?
-
为什么要使用 sigaction 而不是 signal?
-
我如何异步和同步地捕获信号?
-
在我 fork 后,挂起的信号会怎样?Exec?
-
我 fork 后我的信号处理怎么样?Exec?
考试练习问题
警告,这些是很好的练习,但不全面。CS241 期末考试假设你完全理解并能应用课程的所有主题。问题将主要但不完全集中在你在实验室和编程作业中使用过的主题上。
考试题目
期末考试可能包括多项选择题,测试你对以下内容的掌握程度。
CSP (critical section problems)
HTTP
SIGINT
TCP
TLB
Virtual Memory
arrays
barrier
c strings
chmod
client/server
coffman conditions
condition variables
context switch
deadlock
dining philosophers
epoll
exit
file I/O
file system representation
fork/exec/wait
fprintf
free
heap allocator
heap/stack
inode vs name
malloc
mkfifo
mmap
mutexes
network ports
open/close
operating system terms
page fault
page tables
pipes
pointer arithmetic
pointers
printing (printf)
producer/consumer
progress/mutex
race conditions
read/write
reader/writer
resource allocation graphs
ring buffer
scanf
buffering
scheduling
select
semaphores
signals
sizeof
stat
stderr/stdout
symlinks
thread control (_create, _join, _exit)
variable initializers
variable scope
vm thrashing
wait macros
write/read with errno, EINTR and partial data
C 编程:复习问题
警告-问题编号可能会更改
内存和字符串
问题 1.1
在下面的示例中,哪些变量保证打印零值?
int a;
static int b;
void func() {
static int c;
int d;
printf("%d %d %d %d\n",a,b,c,d);
}
问题 1.2
在下面的示例中,哪些变量保证打印零值?
void func() {
int* ptr1 = malloc( sizeof(int) );
int* ptr2 = realloc(NULL, sizeof(int) );
int* ptr3 = calloc( 1, sizeof(int) );
int* ptr4 = calloc( sizeof(int) , 1);
printf("%d %d %d %d\n",*ptr1,*ptr2,*ptr3,*ptr4);
}
问题 1.3
解释下面尝试复制字符串的错误。
char* copy(char*src) {
char*result = malloc( strlen(src) );
strcpy(result, src);
return result;
}
问题 1.4
为什么下面尝试复制字符串的尝试有时成功有时失败?
char* copy(char*src) {
char*result = malloc( strlen(src) +1 );
strcat(result, src);
return result;
}
问题 1.4
解释下面的代码中尝试复制字符串的两个错误。
char* copy(char*src) {
char result[sizeof(src)];
strcpy(result, src);
return result;
}
问题 1.5
以下哪个是合法的?
char a[] = "Hello"; strcpy(a, "World");
char b[] = "Hello"; strcpy(b, "World12345", b);
char* c = "Hello"; strcpy(c, "World");
问题 1.6
完成函数指针 typedef 以声明一个接受 void参数并返回 void的函数指针。将您的类型命名为’pthread_callback’
typedef ______________________;
问题 1.7
除了函数参数之外,线程的堆栈上还存储了什么?
问题 1.8
使用strcpy strlen和指针算术实现char* strcat(char*dest, const char*src)的版本
char* mystrcat(char*dest, const char*src) {
? Use strcpy strlen here
return dest;
}
问题 1.9
使用循环和无函数调用实现size_t strlen(const char*)的版本。
size_t mystrlen(const char*s) {
}
问题 1.10
识别以下strcpy实现中的三个错误。
char* strcpy(const char* dest, const char* src) {
while(*src) { *dest++ = *src++; }
return dest;
}
打印
问题 2.1
找出两个错误!
fprintf("You scored 100%");
格式化和打印到文件
问题 3.1
完成以下代码以打印到文件。将名称、逗号和分数打印到文件’result.txt’
char* name = .....;
int score = ......
FILE *f = fopen("result.txt",_____);
if(f) {
_____
}
fclose(f);
打印到字符串
问题 4.1
如何将变量 a,mesg,val 和 ptr 的值打印到一个字符串?将 a 打印为整数,mesg 打印为 C 字符串,val 打印为双精度值,ptr 打印为十六进制指针。您可以假设 mesg 指向一个短的 C 字符串(<50 个字符)。奖励:如何使这段代码更健壮或能够应对?
char* toString(int a, char*mesg, double val, void* ptr) {
char* result = malloc( strlen(mesg) + 50);
_____
return result;
}
输入解析
问题 5.1
为什么应该检查 sscanf 和 scanf 的返回值?
问题 5.2
为什么’gets’很危险?
问题 5.3
编写一个使用getline的完整程序。确保您的程序没有内存泄漏。
堆内存
何时使用 calloc 而不是 malloc?何时 realloc 会有用?
(待办事项-将此问题移动到另一页)程序员在下面的代码中犯了什么错误?使用堆内存可以修复吗?使用全局(静态)内存可以修复吗?
static int id;
char* next_ticket() {
id ++;
char result[20];
sprintf(result,"%d",id);
return result;
}
多线程编程:复习问题
警告 - 问题编号可能会更改
问题 1
以下代码是否线程安全?重新设计以下代码以使其线程安全。提示:如果消息内存对每次调用都是唯一的,则互斥锁是不必要的。
static char message[20];
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void format(int v) {
pthread_mutex_lock(&mutex);
sprintf(message, ":%d:" ,v);
pthread_mutex_unlock(&mutex);
return message;
}
问题 2
以下哪一个不会导致进程退出?
-
从最后一个运行的线程中返回 pthread 的起始函数。
-
原始线程从主函数返回。
-
任何导致分段错误的线程。
-
任何调用
exit的线程。 -
在仍有其他线程运行时,在主线程中调用
pthread_exit。
问题 3
为以下程序中将打印的"W"字符的数量写一个数学表达式。假设 a、b、c、d 都是小正整数。您的答案可以使用一个返回其最低值参数的’min’函数。
unsigned int a=...,b=...,c=...,d=...;
void* func(void* ptr) {
char m = * (char*)ptr;
if(m == 'P') sem_post(s);
if(m == 'W') sem_wait(s);
putchar(m);
return NULL;
}
int main(int argv, char** argc) {
sem_init(s,0, a);
while(b--) pthread_create(&tid, NULL, func, "W");
while(c--) pthread_create(&tid, NULL, func, "P");
while(d--) pthread_create(&tid, NULL, func, "W");
pthread_exit(NULL);
/*Process will finish when all threads have exited */
}
问题 4
完成以下代码。以下代码应该交替打印A和B。它表示两个轮流执行的线程。添加条件变量调用到func,以便等待的线程不需要不断检查turn变量。问:pthread_cond_broadcast是必要的还是pthread_cond_signal足够?
pthread_cond_t cv = PTHREAD_COND_INITIALIZER;
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
void* turn;
void* func(void* mesg) {
while(1) {
// Add mutex lock and condition variable calls ...
while(turn == mesg) {
/* poll again ... Change me - This busy loop burns CPU time! */
}
/* Do stuff on this thread */
puts( (char*) mesg);
turn = mesg;
}
return 0;
}
int main(int argc, char** argv){
pthread_t tid1;
pthread_create(&tid1, NULL, func, "A");
func("B"); // no need to create another thread - just use the main thread
return 0;
}
问题 5
在给定的代码中标识临界区。添加互斥锁以使代码线程安全。添加条件变量调用,使total永远不会变成负数或超过 1000。相反,调用应该阻塞,直到可以安全地继续。解释为什么pthread_cond_broadcast是必要的。
int total;
void add(int value) {
if(value < 1) return;
total += value;
}
void sub(int value) {
if(value < 1) return;
total -= value;
}
问题 6
一个非线程安全的数据结构有size() enq 和 deq 方法。使用条件变量和互斥锁来完成线程安全的、阻塞版本。
void enqueue(void* data) {
// should block if the size() would become greater than 256
enq(data);
}
void* dequeue() {
// should block if size() is 0
return deq();
}
问题 7
您的创业公司提供使用最新交通信息的路径规划。您过度支付的实习生创建了一个非线程安全的数据结构,其中包含两个函数:shortest(使用但不修改图)和set_edge(修改图)。
graph_t* create_graph(char* filename); // called once
// returns a new heap object that is the shortest path from vertex i to j
path_t* shortest(graph_t* graph, int i, int j);
// updates edge from vertex i to j
void set_edge(graph_t* graph, int i, int j, double time);
为了性能,多个线程必须能够同时调用shortest,但是当没有其他线程在shortest或set_edge内执行时,图只能被一个线程修改。
使用互斥锁和条件变量来实现读者-写者解决方案。下面显示了一个不完整的尝试。尽管这个尝试是线程安全的(因此足够用于演示日!),但它不允许多个线程同时计算shortest路径,并且不具有足够的吞吐量。
path_t* shortest_safe(graph_t* graph, int i, int j) {
pthread_mutex_lock(&m);
path_t* path = shortest(graph, i, j);
pthread_mutex_unlock(&m);
return path;
}
void set_edge_safe(graph_t* graph, int i, int j, double dist) {
pthread_mutex_lock(&m);
set_edge(graph, i, j, dist);
pthread_mutex_unlock(&m);
}
同步概念:复习问题
注意,线程编程同步问题在另一页上。本页重点讨论概念性主题。问题编号可能会更改
Q1
每个 Coffman 条件的含义是什么?(例如,你能提供每个条件的定义吗)
-
持有和等待
-
循环等待
-
无抢占
-
互斥
Q2
逐个举例打破每个 Coffman 条件的真实生活例子。一个需要考虑的情况:画家、油漆和画笔。持有和等待 循环等待 无抢占 互斥
Q3
确定餐馆哲学家代码何时导致死锁(或者不导致)。例如,如果你看到以下代码片段,哪个 Coffman 条件没有满足?
// Get both locks or none.
pthread_mutex_lock( a );
if( pthread_mutex_trylock( b ) ) { /*failed*/
pthread_mutex_unlock( a );
...
}
Q4
有多少进程被阻塞?
-
P1 获取 R1
-
P2 获取 R2
-
P1 获取 R3
-
P2 等待 R3
-
P3 获取 R5
-
P1 获取 R4
-
P3 等待 R1
-
P4 等待 R5
-
P5 等待 R1
Q5
以下哪些陈述对于读者-写者问题是真实的?
-
可能有多个活跃的读者
-
可能有多个活跃的写者
-
当有一个活跃的写者时,活跃的读者数量必须为零
-
如果有一个活跃的读者,活跃的写者数量必须为零
-
一个写者必须等到当前活跃的读者完成
内存:复习问题
问题编号可能会改变
Q1
以下是什么,它们的目的是什么?
-
翻译旁路缓冲
-
物理地址
-
内存管理单元
-
脏位
Q2
你如何确定页偏移中使用了多少位?
Q3
上下文切换后 20 毫秒,TLB 包含你的数值代码使用的所有逻辑地址,该代码 100%的时间执行主内存访问。相对于单级页表,两级页表的开销(减速)是多少?
Q4
解释为什么在上下文切换发生时必须刷新 TLB(即 CPU 被分配到不同进程上工作)。
管道:复习问题
问题编号可能会有所变化
Q1
填写空白以使以下程序打印 123456789。如果cat没有给出参数,它只是打印其输入直到 EOF。奖励:解释为什么下面的close调用是必要的。
int main() {
int i = 0;
while(++i < 10) {
pid_t pid = fork();
if(pid == 0) { /* child */
char buffer[16];
sprintf(buffer, ______,i);
int fds[ ______];
pipe( fds);
write( fds[1], ______,______ ); // Write the buffer into the pipe
close( ______ );
dup2( fds[0], ______);
execlp( "cat", "cat", ______ );
perror("exec"); exit(1);
}
waitpid(pid, NULL, 0);
}
return 0;
}
Q2
使用 POSIX 调用fork pipe dup2和close来实现一个自动评分程序。将子进程的标准输出捕获到一个管道中。子进程应该使用exec命令执行程序./test,除了进程名称之外不带任何额外的参数。在父进程中从管道中读取:一旦捕获的输出包含!字符,就退出父进程。在退出父进程之前,向子进程发送 SIGKILL。如果输出包含!,则退出 0。否则,如果子进程退出导致管道写端关闭,则以值 1 退出。确保在父进程和子进程中关闭未使用的管道端。
Q3(高级)
这个高级挑战使用管道让“AI 玩家”自己玩游戏,直到游戏结束。程序tictactoe接受一行输入 - 到目前为止所做的转动序列,打印相同的序列,然后再加上一个转动,然后退出。一个转动由两个字符指定。例如,“A1”和“C3”是两个对角位置。字符串B2A1A3是一个 3 个转动/步骤的游戏。一个有效的响应是B2A1A3C1(C1 响应阻止了对角线 B2 A3 的威胁)。输出行还可以包括后缀“-I win”、“-You win”、“-invalid”或“-draw”。使用管道来控制每个创建的子进程的输入和输出。当输出包含“-”时,打印最终输出行(整个游戏序列和结果)并退出。
文件系统:复习问题
问题编号可能会更改
问题 1
编写一个使用 fseek 和 ftell 的函数,将文件的中间字符替换为’X’
void xout(char* filename) {
FILE *f = fopen(filename, ____ );
}
问题 2
在ext2文件系统中,从磁盘读取多少个 inode 才能访问文件/dir1/subdirA/notes.txt的第一个字节?假设根目录中的目录名称和 inode 编号(但不是 inode 本身)已经在内存中。
问题 3
在ext2文件系统中,必须从磁盘读取多少个最小磁盘块才能访问文件/dir1/subdirA/notes.txt的第一个字节?假设根目录中的目录名称和 inode 编号以及所有 inode 已经在内存中。
问题 4
在具有 32 位地址和 4KB 磁盘块的ext2文件系统中,一个 inode 可以存储 10 个直接磁盘块编号。需要多大的文件大小才需要单一间接表?ii)双重间接表?
问题 5
修复下面的 shell 命令chmod,以设置文件secret.txt的权限,使所有者可以读取、写入和执行权限,组可以读取,其他人没有访问权限。
chmod 000 secret.txt
网络:复习问题
简答问题
Q1
什么是套接字?
Q2
监听端口 1000 和端口 2000 有什么特别之处?
-
端口 2000 比端口 1000 慢两倍
-
端口 2000 比端口 1000 快两倍
-
端口 1000 需要 root 权限
-
无
Q3
IPv4 和 IPv6 之间的一个重要区别是什么?
Q4
何时以及为什么会使用 ntohs?
Q5
如果主机地址是 32 位,我最有可能使用哪种 IP 方案?128 位呢?
Q6
哪种常见的网络协议是基于数据包的,可能无法成功传递数据?
Q7
哪种常见的协议是基于流的,如果数据包丢失将重新发送数据?
Q8
什么是 SYN ACK ACK-SYN 握手?
Q9
以下哪项不是 TCP 的特性之一?
-
数据包重排序
-
流量控制
-
数据包重传
-
简单的错误检测
-
加密
Q10
什么协议使用序列号?它们的初始值是多少?为什么?
Q11
构建 TCP 服务器需要的最小网络调用是什么?它们的正确顺序是什么?
Q12
构建 TCP 客户端所需的最小网络调用是什么?它们的正确顺序是什么?
Q13
何时在 TCP 客户端上调用 bind?
Q14
套接字绑定监听接受的目的是什么?
Q15
上述哪个调用可以阻塞,等待新客户端连接?
Q16
DNS 是什么?它对你有什么作用?CS241 网络调用中的哪些会为你使用它?
Q17
对于 getaddrinfo,如何指定服务器套接字?
Q18
为什么 getaddrinfo 可能会生成网络数据包?
Q19
哪个网络调用指定了允许的积压大小?
Q20
哪个网络调用返回一个新的文件描述符?
Q21
何时使用被动套接字?
Q22
何时使用 epoll 比 select 更好?何时使用 select 比 epoll 更好?
Q23
write(fd, data, 5000)总是发送 5000 字节的数据吗?它何时会失败?
Q24
网络地址转换(NAT)是如何工作的?
Q25
@MCQ 假设网络客户端和服务器之间的传输时间为 20ms,建立 TCP 连接需要多长时间?20ms 40ms 100ms 60ms @ANS 3 次握手 @EXP @END
Q26
HTTP 1.0 和 HTTP 1.1 之间有哪些区别?如果网络传输时间为 20ms,从服务器传输 3 个文件到客户端需要多少毫秒?HTTP 1.0 和 HTTP 1.1 之间的传输时间有何不同?
编码问题
Q 2.1
写入网络套接字可能不会发送所有字节,并且可能会因为信号中断。检查write的返回值来实现write_all,它将重复调用write以发送任何剩余的数据。如果write返回-1,那么除非errno是EINTR,否则立即返回-1 - 在这种情况下重复上次的write尝试。您将需要使用指针算术。
// Returns -1 if write fails (unless EINTR in which case it recalls write
// Repeated calls write until all of the buffer is written.
ssize_t write_all(int fd, const char *buf, size_t nbyte) {
ssize_t nb = write(fd, buf, nbyte);
return nb;
}
Q 2.2
实现一个多线程 TCP 服务器,监听端口 2000。每个线程应从客户端文件描述符中读取 128 字节,并将其回显给客户端,然后关闭连接并结束线程。
Q 2.3
实现一个 UDP 服务器,监听端口 2000。保留一个大小为 200 字节的缓冲区。监听到一个到达的数据包。有效数据包为 200 字节或更少,并以四个字节 0x65 0x66 0x67 0x68 开头。忽略无效的数据包。对于有效的数据包,将第五个字节的值作为无符号值添加到一个运行总数中,并打印到目前为止的总数。如果运行总数大于 255,则退出。
信号:复习问题
给出通常由内核生成的两个信号的名称
给出一个不能被信号捕获的信号的名称
为什么在信号处理程序中调用任何函数(不是信号处理程序安全的函数)是不安全的?
编码问题
编写简短的代码,使用 SIGACTION 和 SIGNALSET 来创建一个 SIGALRM 处理程序。
系统编程笑话
系统编程笑话
警告:作者对这些“笑话”造成的任何神经凋亡概不负责。-允许抱怨。
灯泡笑话
Q.需要多少系统程序员来换一只灯泡?
A.一个,但他们不断更改它,直到返回零。
A.没有,他们更喜欢一个空的插座。
A.好吧,你开始只有一个,但实际上它等待一个孩子来做所有的工作。
抱怨者
为什么婴儿系统程序员喜欢他们的新彩色毯子?它是多线程的。
为什么你的程序如此精致柔软?我只使用 400 线程或更高线程的程序。
当坏学生 shell 进程死去时,他们去哪里?地狱分叉。
为什么 C 程序员如此凌乱?他们把所有东西都存储在一个大堆中。
系统程序员(定义)
系统程序员是…
知道sleepsort是一个坏主意,但仍然梦想找借口使用它的人。
从不让他们的代码死锁的人…但当它发生时,会比其他人加起来造成更多问题。
一个相信僵尸是真实的人。
一个不相信他们的进程在没有使用相同的数据、内核、编译器、RAM、文件系统大小、文件系统格式、磁盘品牌、核心数量、CPU 负载、天气、磁通量、方向、精灵尘、星座、墙壁颜色、墙壁光泽和反射、主板、振动、照明、备用电池、时间、温度、湿度、月球位置、太阳-月球共同位置的情况下正确运行的人…
系统程序(定义)
一个系统程序…
发展到可以发送电子邮件。
发展到有潜力创建、连接和终结其他程序,并在所有可能的设备上消耗所有可能的 CPU、内存、网络…资源,但选择不这样做。今天。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CloudQuery 的过去、现在和未来
- C++ 类构造函数 & 析构函数
- 深入了解JavaScript中的indexOf()方法:实现数组元素的搜索和索引获取
- 有效降低EMI干扰的PCB设计原则
- Collectors方法常见的异常
- 第三方软件检测机构做软件测试有什么用途,软件测试如何收费?
- 【c】数组元素移动
- OpenStack云计算(-) 简介与部署Keystone
- MySQL练习-DDL语法练习
- Kotlin协程学习之-02