Object Class Aware Video Anomaly Detection through Image Translation 论文阅读
Object Class Aware Video Anomaly Detection through Image Translation
文章信息:

原文链接:https://arxiv.org/abs/2205.01706
源代码:无
发表于:CRV 2022
Abstract
半监督视频异常检测(VAD)方法将异常检测任务表述为对学习到的正常模式的偏离进行检测。该领域中的先前工作(基于重建或预测的方法)存在两个缺点:
1)它们专注于低级特征,特别是整体方法并未有效考虑对象类别。
2)以对象为中心的方法忽略了一些上下文信息(如位置)。
为了解决这些挑战,本文提出了一种新颖的两流对象感知的VAD方法,通过图像翻译任务学习正常的外观和运动模式。外观分支将输入图像转换为由Mask-RCNN生成的目标语义分割图,而运动分支将每一帧与其预期的光流幅值相关联。在推断阶段,对外观或运动的任何偏离都显示了潜在异常的程度。我们在ShanghaiTech、UCSD-Ped1和UCSD-Ped2数据集上评估了我们提出的方法,结果显示与最先进的工作相比具有竞争力的性能。最重要的是,结果表明,与以前的方法相比,我们方法的检测是完全可解释的,并且能够准确地定位帧中的异常。
I. INTRODUCTION
人工操作员持续监视监控摄像头的输出在实际上是不够有效和合理的。因此,有需求开发一个智能系统,可以自动分析视频内容,定位可疑情况,并检测感兴趣的事件以进行进一步的分析。在庞大的视频数据中,异常视频事件对潜在的安全措施更为重要。视频异常检测(VAD)是指识别与常规事件不符或者换句话说,明显偏离预期的事件[1]。异常事件很少发生,而且它们可以呈现无限的类型[2]。因此,实际上很难获得足够的标记异常数据用于监督训练。另一方面,正常数据可以迅速大量收集,这可用于半监督训练。此外,将问题视为半监督学习任务更符合异常检测的定义,因为通常,异常的定义与正常的概念相关联。
深度学习(DL)基础的视频异常检测方法在与它们的经典对应物相比方面取得了显着的改进。先前的DL基础整体方法[3]、[4]、[5]、[2]通常集中于低级特征,以表示正常帧,从而识别异常。因此,最终决策中未考虑对象的类别,而从外观的角度来看,对象的类别实际上在定义监控摄像头中的异常时起着最关键的作用。另一方面,以对象为中心的方法[6]、[7]仅集中于检测到的对象,以更好地考虑对象。然而,它们仍然通过专注于低级特征(通过重建或预测检测到的对象的裁剪图像)来学习正常性。此外,由于它们将对象从帧中裁剪出来,它们忽略了重要的上下文信息(例如对象在场景中的位置)。以前方法的一个主要缺点是它们的检测解释性差[8]。即使一帧被准确识别为异常,也必须确保该决策是基于与异常相关的原因(例如异常对象或运动),而不是与无关的因素(如噪声、对象数量、照明变化等)[8]。重要的是,方法的解释性有助于定位异常。以前的方法没有从这个角度讨论他们的方法。此外,不同方法的重新实现表明,它们要么具有相当数量的无法解释的检测结果,要么在异常区域上没有精确的关注。
为了解决上述问题,我们提出了一种双流方法来检测视频中的异常。一支学习正常外观,而第二支则考虑运动。与以前的方法不同,我们提出的方法在异常检测中考虑对象的类别,而不是低级特征(例如强度、颜色等)。低级特征无法有效地表示监控视频中的异常,并且它们更容易受到噪声和照明变化的影响。在这个分支中,我们训练了一个U-net(使用在ImageNet上预训练的resnet34作为编码器)来将输入帧转换为其目标语义分割图。这种表述有助于网络学习帧中的正常对象,考虑到它们的类别。与此同时,在运动分支中,一个相同的网络将输入帧转换为其光流幅值图。通过这种方式,网络学习将对象与其正常运动关联起来。总之,我们在本文中的贡献如下:
- 我们提出了一种新颖的双流视频异常检测方法,重点关注对象的类别,而不是专注于低级特征。通过将问题重新表述为从输入帧到其预先计算的语义分割图的图像转换来实现这一目标。据我们所知,这是第一项考虑对象类别进行视频异常检测的研究。
- 我们将学习正常运动的任务构建为从输入帧到其目标光流幅度图的图像转换。
- 我们的方法是可解释的,仅基于与异常相关的激活将帧标识为异常。此外,考虑异常地图激活,能够准确地定位帧中的异常。
- 我们提出的方法在Shanghaitech数据集上优于最先进的方法,并在UCSD数据集上取得了竞争性的结果。
II. RELATED WORKS
视频异常检测通常以半监督的方式解决。研究人员主要通过将任务表述为重建任务[3],[4],[5],[9],[10],[11]或预测任务[2],[12],[13],[14]来解决这个问题。在基于重建的方法中,通常训练无监督网络(通常是自编码器、U-net等)来重建正常帧,假设异常帧会导致更高的重建误差。另一方面,基于预测的方法获取正常片段的连续帧,并训练以预测未来帧,期望异常帧的预测误差较高。这些方法本质上考虑了帧的演变以预测未来帧,因此捕捉了运动模式。为了兼顾重建和预测框架的优势,[15],[16]提出了一种混合方法,在不同的分支中使用两种方法。
基于重建和基于预测的方法存在缺点:1)它们通常考虑预测的低级特征,并且不能有效地考虑对象的类别[17],[14]。2)在单个流中同时建模外观和运动的方法未能像外观一样有效地考虑运动。
与上述的整体方法不同,面向对象的方法[6]仅关注检测到的对象。这些方法将对象从帧中裁剪出来,并分别学习它们的外观和运动。面向对象的方法专注于对象,并因此可以推广到不同的场景。此外,它们不必处理由于背景引起的计算复杂性[13]。然而,它们仍然有两个主要缺点:1)它们将对象从帧中裁剪出来,单独处理它们,并且不考虑位置信息。2)重建或预测裁剪对象的图像有助于网络关注对象,但并不一定能保证学习对象的类别。
最近,Krzysztof等人[18]提出了一种通过从语义分割图重建帧来检测图像中新奇性的方法。通过这个框架,网络考虑了对象的类别。受到这种方法和[19]的启发,我们以一种不同的方式利用语义分割,并将问题表述为从原始帧到其语义分割图的图像转换。此外,与先前的工作不同,我们添加了第二个分支来捕捉运动模式。
尽管对于VAD的构建和考虑运动已经应用了不同的策略,但运动与对象之间的对应关系并没有得到有效考虑。为此,Nguyen等人[20]将学习正常运动的问题构建为图像转换任务。他们训练一个网络,将原始帧转换为其相应的光流图。然而,从单个帧中识别对象的运动方向对网络来说是混乱的。我们实现了类似的方法,但我们训练我们的网络将原始帧转换为相应的光流幅度图。因此,网络仅考虑运动的幅度,不会因方向而混淆。
III. PROPOSED METHOD
我们提出了一种基于深度学习的半监督视频异常检测方法,利用两个并行分支分别对正常外观和运动进行建模,并因此利用图像转换来检测异常。所提出方法的流程如图1所示,详细说明了训练和推断(测试)阶段。所提出方法的详细信息在以下各小节中描述。
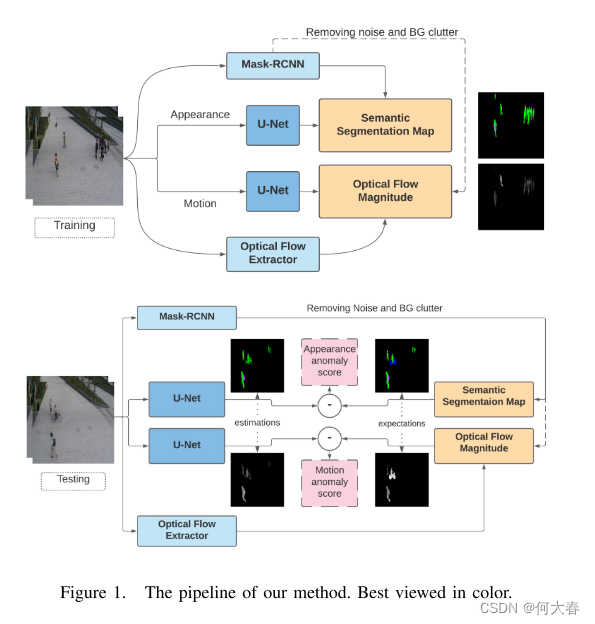
A. The two-stream method
我们的方法在两个不同但相似的分支中分别对正常外观和运动进行建模。[17]中的实验证明,将运动和外观分开建模能够保持每个因素对最终决策的影响,不同于单分支方法,其中一个特征可能会被另一个特征主导。
B. The appearance branch
在外观分支中,我们使用一个预训练的带有resnet34编码器的U-net进行训练(在ImageNet上进行了训练)。该网络被训练来学习将输入帧转换为其目标语义分割图的过程。帧的目标语义分割图是使用最先进的目标分割方法Mask-RCNN获得的。假设网络通过这种形式学会识别帧内的对象并识别它们的对象类别。通过这种方式,网络学会了在不需要将对象从帧中裁剪出来的情况下专注于对象并识别它们的类别。
C. The motion branch
在运动分支中,采用了与外观分支相同的公式,训练了一个相同的U-net,以学习将输入图像转换为其相应的光流幅度图。光流幅度图是一幅灰度图像,仅保留光流的幅度信息,去除了方向信息(即光流图中的颜色)。通过这种形式,网络学会了将对象与它们在不同位置的正常运动关联起来。值得一提的是,这种转换是从一幅图像到另一幅图像。换句话说,我们不使用两个连续的帧作为U-net的输入来学习光流的计算。然而,连续的帧用于创建目标图像,网络学习了输入帧中每个对象与其预先计算的运动幅度之间的对应关系。我们的实验证明,当网络尝试学习到原始光流图时,它会在方向上感到困惑,而且不能产生有用的结果。然而,它能够正确学习每个对象的正常运动幅度。图2说明了这个挑战及其解决方案。

我们设计了综合方法,使得位置信息不被忽略。这在场景异常检测中发挥着至关重要的作用,因为从外观的角度来看,通常期望每种对象类型出现在帧的特定区域(例如,车辆预计会出现在街道上,而不是人行道上)。相同的规则也适用于运动。尤其重要的是,我们的方法预计将学习在不同位置产生不同正常运动(即使是相同的对象类型)。例如,远离摄像头的行人产生的运动幅度较低(在其光流结果方面),而靠近摄像头的行人产生的运动幅度较大。我们的实验证明,我们提出的网络学习了每个对象的正常运动,考虑了它们的位置。
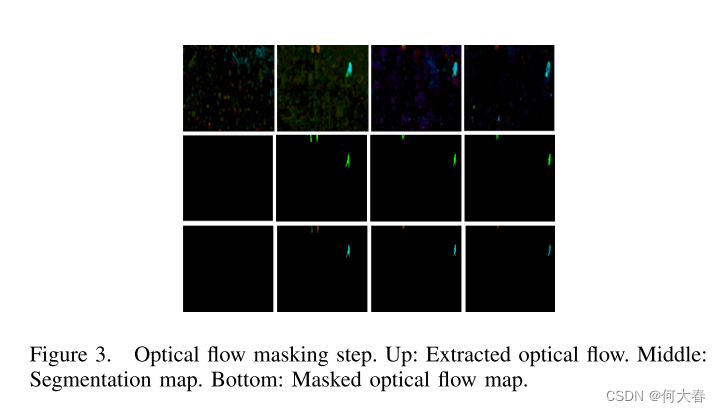
D. Masking
为了集中在对象的运动上,我们将计算得到的语义分割掩码(由Mask-RCNN生成)应用于计算得到的目标光流图上。通过这种方式,背景运动被抑制,有助于网络集中学习检测到的对象的运动。图3显示了嘈杂的原始光流图样本,相应的分割掩码和最终的带有对象运动的遮罩光流图。
E. Training
我们训练外观分支和运动分支的网络,以最小化它们的目标图像(T)与它们的输出(
F
W
(
I
t
)
F_W(I_t)
FW?(It?))之间的差异。因此,优化遵循以下目标函数(1):
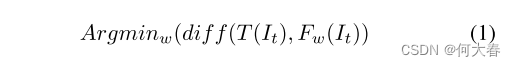
其中,diff表示计算T和
F
w
F_w
Fw?之间差异的函数。T和
F
w
F_w
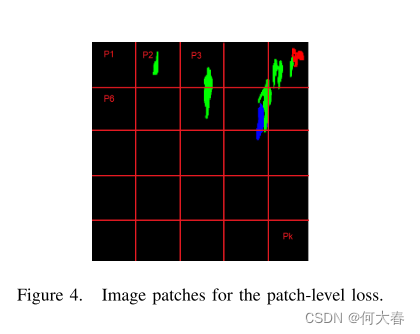
Fw?分别表示输入I(在时间t处)的目标图像和网络(Unet)的函数。值得一提的是,受到[20]的启发,我们利用了光流的L1损失,因为它不会放大噪声的影响。对于外观网络,我们利用了L2损失,以计算输出与目标图像之间的差异。此外,Yang等人[21]认为,使用基于补丁的损失进行训练会迫使网络平等地关注不同区域,而不是优先考虑背景。因此,我们利用基于补丁的损失为每个帧计算MSE或MAE损失(图4中的虚线框),并选择最大的补丁损失作为帧的最终损失。基于补丁的损失如下(对于外观分支和运动分支的损失):
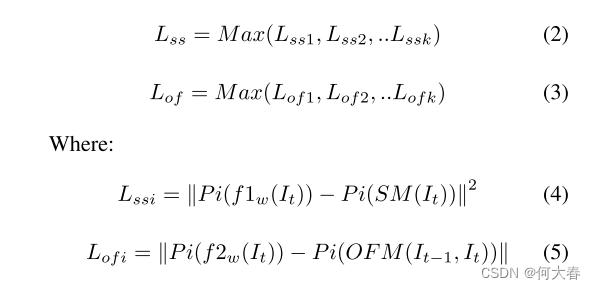
Pi选择帧中的第i个补丁(如图4所示)。
L
s
s
i
L_{ssi}
Lssi?和
L
o
f
i
L_{ofi}
Lofi?表示外观和运动的第i个补丁(在k个生成的补丁中)的损失,而
L
s
s
L_{ss}
Lss?和
L
o
f
L_{of}
Lof?分别表示外观和运动分支的最终损失。在上述方程中,w是网络的权重,
f
1
w
f1_w
f1w?和
f
2
w
f2_w
f2w?分别表示外观和运动分支的网络。此外,SM表示由Mask-RCNN生成的分割掩码(SM)的函数,OFM是生成光流幅度图(OFM)的函数。
F. Inference
图1说明了推理阶段。在这个阶段,对于每个分支,我们将训练好的网络的输出与它们的期望(目标图像)进行比较,并计算它们的差异(即所有对应像素的像素差异之和)作为异常分数。为此,我们计算输出和目标图像之间的均方误差(MSE)损失,并将其用作异常分数。对于输入帧,如果任何分支的异常分数超过其设定的阈值,则从外观或运动的角度将该帧标记为异常。总体而言,如果任何分支的异常分数超过其阈值,我们将帧标记为异常。
G. Refinement
正如[17]中研究的那样,现有方法的一个缺点是它们的异常分数受到前景对象数量的影响。换句话说,一帧中的对象越多,产生的异常分数就越高。尽管正常对象产生较低的重建/预测误差,但大量正常前景对象可能导致更高的总异常分数,并具有与异常对象相同的效果。通过分析我们的方法和其他方法生成的异常图,我们发现正常对象的异常激活是非浓缩的,通过进行几步侵蚀和膨胀形态学操作,可以缓解该问题而不对异常的激活产生明显影响。为此,我们分别对异常图应用了几步侵蚀和膨胀操作,以解决上述的非不变对象数量的问题。
H. Temporal denoising
基于目标检测或分割的方法可能在某些帧中未能检测到某些对象,这可能导致异常分数突然变化。另一方面,考虑到视频的帧率,相邻帧非常相似,预期会产生类似的异常分数。因此,基于这个假设,我们对帧的异常分数应用Savitzky–Golay滤波器[8],以平滑异常分数并消除噪音。
IV. EXPERIMENTS AND RESULTS
在本节中,我们在三个基准测试(ShanghaiTech [2],UCSD-Ped 1和UCSD-Ped 2 [22])上评估了我们提出的方法的性能。在这些数据集中,正态和异常的概念是相同的,它们都适合于半监督训练,因为它们在训练子集中包含正常帧。除了定量的结果,我们提供了许多定性的结果来说明激活的异常地图,支持我们的方法的可解释性。数据集和实验的详细信息见以下小节。
A. Datasets
如前所述,我们在三个基准数据集(ShanghaiTech、Ped1 和 Ped2)上评估了所提方法的有效性。这些数据集在训练和测试中都是独立使用的。ShanghaiTech 数据集是在一所大学校园内拍摄的,行人行走是正常的。它包含不同类型的异常,如异常对象(例如汽车、摩托车等)和异常运动(例如奔跑、追逐等)。该数据集提供了像素级别和帧级别的注释。该数据集的最显著特点包括:1)多个场景和视角;2)复杂的光照条件。在UCSD-Ped1 和 Ped2 数据集中,正常场景包括人们在人行道上行走,而异常是由于场景中出现意外对象(如手推车、自行车、滑板等)或不同的运动模式(滑板骑行等)引起的。这些数据集的主要挑战包括:1)相对较低的分辨率和灰度,导致难以识别对象;2)由于与相机的距离不同,人的大小可能会发生相当大的变化;3)某些帧存在明显的相机抖动。值得一提的是,在这些数据集的地面实况注释中,如果帧包含异常对象或运动,则将其注释为异常。
B. Evaluation metric
在我们的实验中,我们使用帧级曲线下面积(AUC)分数作为准确性度量。通过对异常分数应用不同的阈值并获得不同的真阳性率(TPR)和假阳性率(FPR),绘制受试者操作特征(ROC),并计算曲线下面积来评估该方法的性能,从而将其与最先进的方法进行比较。AUC越高,性能越好。
C. Implementation details
在我们的实验中,为了外观和运动分支,所有帧都被调整大小为 224?224。此外,我们使用两个连续的帧(Δt = 1)来生成光流目标图,简单地使用OpenCV库中的Farneback算法。为了训练网络,我们使用Adam优化器来优化参数。训练的学习率从 0.005 开始,但每经过 10 个时期就减半。在我们的实现中,我们还将 K(在补丁级别培训中的补丁数)设置为 9。我们还通过分别应用侵蚀和膨胀运算的每一步,并将滤波器大小设置为 3,获得了最佳的细化步骤性能。
D. Qualitative analysis
在这个小节中,我们提供异常地图来直观验证贡献的有效性,并展示我们的方法是如何专注于正确的方面(对象的类别或运动)和正确的位置(对象的位置)来做出决策的。如异常地图所示,主要的和较高的激活是由异常产生的,这支持了我们VAD方法的可解释性。
图5和图6展示了该方法在Shanghai-Tech和Ped2数据集上的一些定性结果。这些图表现了外观(彩色图像)和运动分支(灰度图像)的性能。对于每个样本帧,呈现了以下数据:原始输入帧,目标地图(期望的输出),估计的输出(网络的输出),异常地图(期望输出和估计输出之间的差异),最后是经过处理的异常地图。如图所示,每个分支的网络在正常帧上训练,已经学会了正常外观和运动,以便对于正常帧,网络产生的输出与它们的期望输出相当相似(分别为外观和运动分支的语义分割地图和光流幅度地图)。然而,对于异常对象,网络的行为并不相同。对于异常对象的异常类别,外观网络要么将它们识别为先前见过的对象之一(主要是行人),要么将它们(或它们的某些部分)检测为背景。因此,在该位置,估计的外观与期望的外观之间的差异生成了显著的异常分数,在这两种情况下都是如此。对于正常对象的运动网络还估计了与其目标运动图相当接近的运动,导致较低的异常分数。然而,对于异常运动(通常是更快的运动),估计接近正常运动(即不同于它们实际的运动),从而产生较大的差异(即更高的异常分数)。

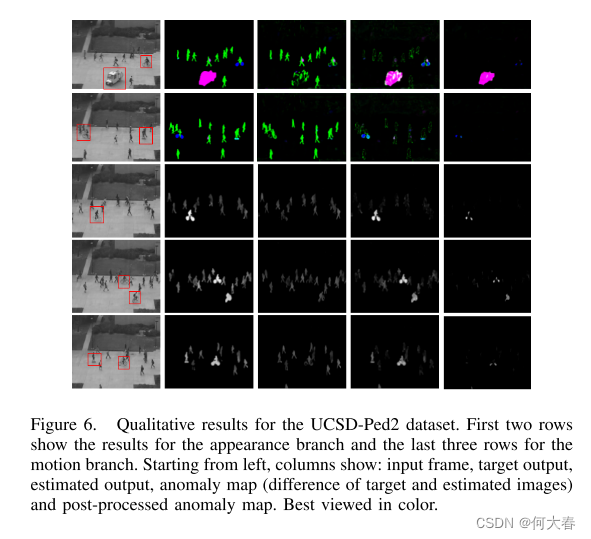
计算得到的异常图主要由在异常对象的位置产生的较大和密集的激活组成,还有在正常对象的某些点上一些非浓缩的激活(具有较弱的确定性)。尽管异常分数主要受到原始异常地图中的异常的影响,但形态学后处理操作通过消除非浓缩像素减少了正常像素的影响。我们的实验结果表明,形态学的细化在Shanghai数据集中更为有效。通过对结果进行定性分析,可以认为性能差异主要是由UCSD数据集中输入帧的低分辨率和对象的小尺寸引起的。
我们还定性地评估了该方法在建立正常对象与其运动之间的关联方面的性能。图7显示了我们的模型如何有效地学习在对象的位置和其运动之间建立对应关系。此外,它学习了对象部分和它们运动之间的关联。例如,输出结果表明网络已经学会为腿估计比其他身体部分更大的运动。此外,网络对于靠近摄像机的对象预测较大的运动。

我们的实验还表明,大多数假阳性检测是由于一个网络(图像翻译器或Mask-RCNN)检测到了一个正常对象,而另一个网络误检测引起的。这导致了该对象的估计输出与期望输出之间的差异较大(即异常地图中的大激活)。我们的实验证明,上述误检测主要是由于输入帧的低分辨率,对象的非常小的尺寸,物体在镜子中的反射和与背景的伪装等因素。此外,通过分析结果,我们发现外观网络(图像翻译器)在分割正常对象方面优于MaskRCNN,而且大多数先前提到的失败(即一个网络在检测正常对象时的失败)发生在Mask-RCNN中。
我们的方法假定基于外观的异常是由未见过的对象类别引起的。因此,我们不希望在异常是由于低级图像特征(例如表面的缺陷检测)引起时获得良好的性能。此外,为了提高运动分支在对象与其运动之间建立对应关系方面的性能,我们集中在可能降低性能的运动的幅度上。
E. Comparison with the state-of-the-art methods and ablation study
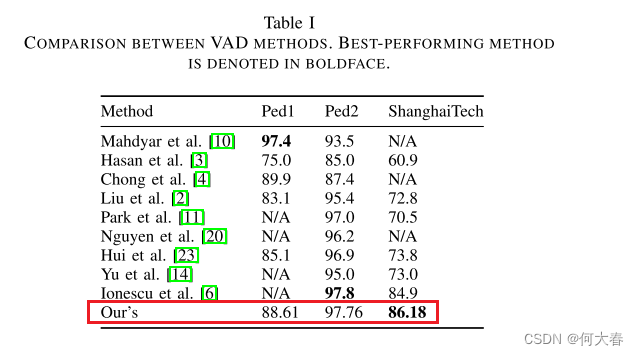
在表I中,我们将我们提出的方法的有效性与最先进的方法进行了比较。结果显示,我们提出的方法在ShanghaiTech上的表现优于其他方法(考虑AUC),在UCSD数据集上与其他方法相比表现竞争力。
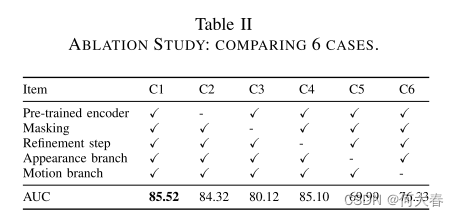
表II提供了我们在ShanghaiTech上进行的消融研究的结果,以分析所提方法中各个组件的贡献。结果显示,使用预训练的U-net和掩蔽阶段对性能的影响最为积极。掩蔽阶段的更高效果可能是因为许多帧中存在相机抖动,导致运动图中出现背景噪声,从而在异常地图中产生大量的假激活。此外,结果表明外观和运动分支相互补充,它们的组合显著提高了性能(与仅使用运动分支相比提高了15.53%,与仅使用外观分支相比提高了9.19%)。
表III显示了通过时间去噪步骤改善性能(AUC)的情况。基于对数据集的大量实验证明,我们得到的最佳结果是窗口长度和多项式阶数(滤波器的超参数)均为41和1。我们认为这些数字与视频剪辑的帧速率有关。如预期,时间去噪步骤在UCSD数据集上更为有效,因为由于分辨率较低,它们中的许多存在Mask-RCNN检测失败。
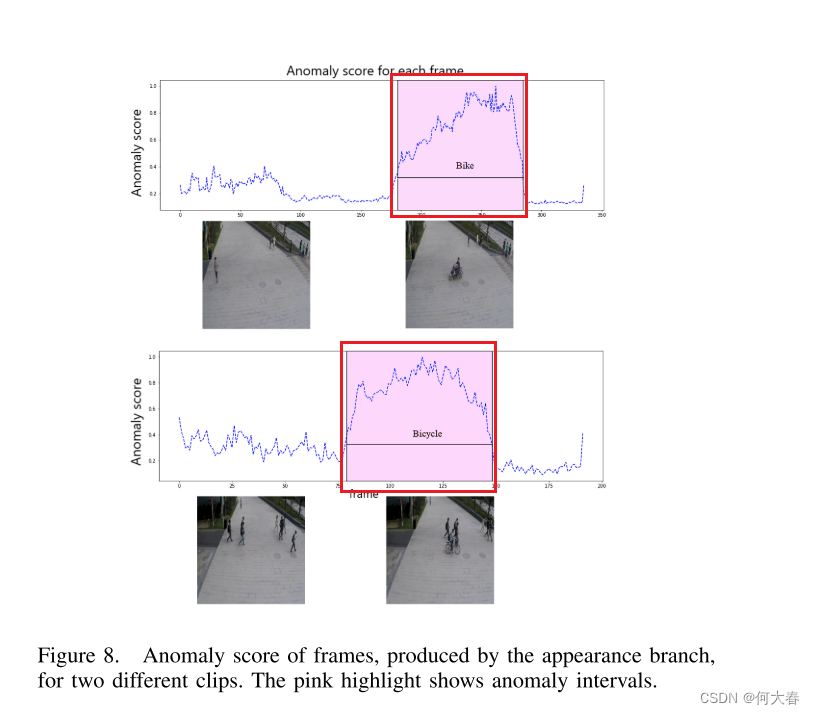
F. Visualizing frame anomaly score
图8显示了外观网络为两个测试剪辑生成的异常分数。该图表明,在包含异常对象类的帧中,异常分数经历了显著的上升。
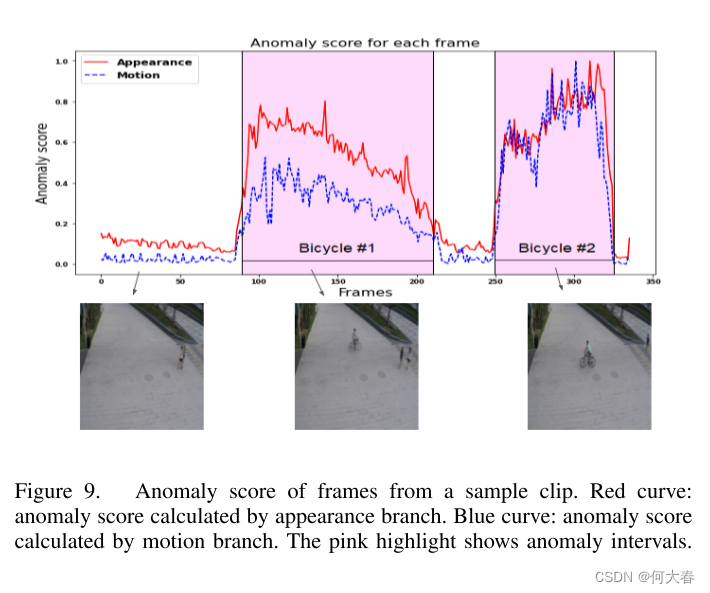
另一方面,图9展示了外观和运动流在通过相应的异常分数检测异常方面的性能。在自行车经过的帧中,两个流的异常分数都观察到了显著的上升。
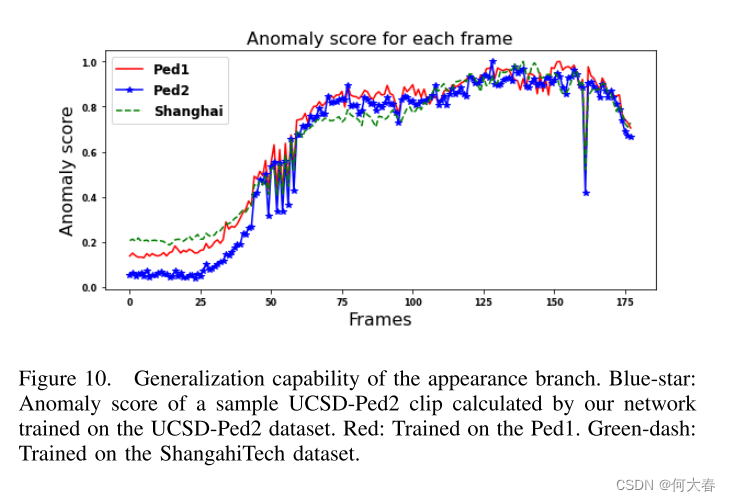
最后,图10显示了训练方法(这里是外观分支作为示例)对其他场景的泛化能力。该图包括由分别在Ped2、Ped1和Shanghai-Tech上训练的网络生成的一个测试剪辑(Ped2-test004)的异常分数。
V. CONCLUSION
我们提出了一种新颖的对象类感知视频异常检测方法,它结合了两个互补的分支来检测视频中的异常。这两个分支都利用了图像转换任务,以建立输入帧与其相应目标图像之间的关联,从而学习正常模式。在推断阶段,分支的网络(U-Net)在正常帧上训练,无法正确地将异常输入帧与其目标图像进行对应,导致异常图中的激活较大。与基准数据集上最先进方法相比的有竞争力的定量结果显示出良好的性能,定性结果展示了我们提出的方法的高可解释性。
阅读总结
Multi-Task Learning based Video Anomaly Detection with Attention 论文阅读是对这篇文章的改进,这篇文章忽略的运动分支方向和距离的影响。
网络结构还是不负责的,训练思路也并不复杂,想法感觉还是有意思的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!