2024.1.8 关于 Redis 数据类型 Zset 集合命令、编码方式、应用场景
发布时间:2024年01月09日
目录
引言
- 在 Redis 中集合间操作无非就是?交集、并集、差集?
- Set 类型与之相对应的操作命令为 sinter、sunion、sdiff
注意:
- 从 Redis 6.2 版本开始,Zset 命令才开始支持?zinter、zunion、zdiff 这几个命令
- 但是此处我们使用的是 Redis 5 版本,所以下文不涉及介绍这三个命令
Zset 集合命令
ZINTERSTORE
- 用于求出给定有序集合中元素的交集,并将其保存进目标有序集合中
- 合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数
语法:
zinterstore destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <sum | min | max>]
- destination:表示要把结果存储到哪个 key 对应的 zset 中
- numkeys:描述了后续有几个 key 参与交集运算,因此该变量需为整型
- weight:可理解为 权重,此处指定的权重,相当于一个系数,会乘以当前的分数
- aggregate:指定 当前给定的有序集合 应采用哪种聚合方式来得出新的分数
注意:
- 前面介绍的命令也是支持多个 key 的,如mget、mset 等
- 但这些命令却不涉及到类似于此处的设定,即需手动指出?key 的个数
官方文档解释:
- 主要是为了避免 zinterstore 命令的 选项 和 keys 弄混淆
- 即通过 numkeys 描述出 key 的个数后,便可明确知道后面的 "选项" 是从哪里开始的
总结:
- 正因为 mget、mset 等命令,在指定 keys 后无复杂的选项
- 所以无需采用?numkeys 来手动指出 key 的个数,以便知道?key 和 选项 之间的分界处
时间复杂度:
- O(N) + O(M * logM)
- N 为 所有输入命令中总的 有序集合 元素个数
- M 为 结果集?的元素个数
实例理解
- 此处我们可以指定 权重
- 我们还可以指定 聚合方式
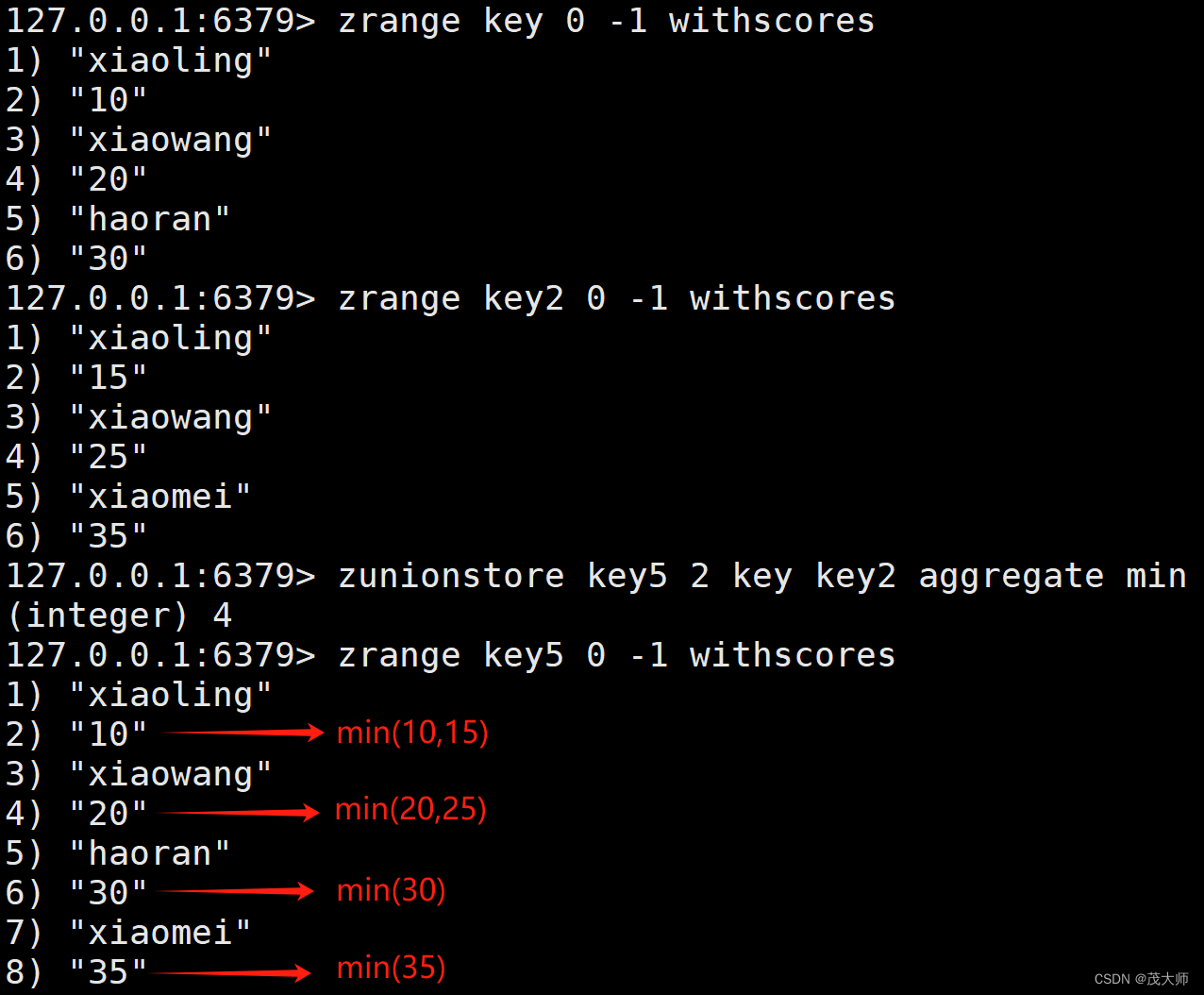
ZUNIONSTORE
- 用于求出给定有序集合的并集,并将其保存到目标有序集合中
- 合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数
语法:
zunionstore destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <sum | min | max>]
- zunionstore 和 zinterstore 命令的用法大致相同
时间复杂度:
- O(N) + O(M * logM)
- N 为 所有输入命令中总的 有序集合 元素个数
- M 为 结果集?的元素个数
实例理解
- 此处我们可以指定 权重
- 我们还可以指定 聚合方式






Zset 编码方式
- 有序集合的内部编码有 两种
- ziplist(压缩列表)
- skiplist(跳表)
注意点一:
- 如果有序集合中的元素个数较少,或者单个元素体积较小时
- 使用 ziplist 来存储,以达到 节省空间 的效果
注意点二:
- 如果有序集合中的元素个数较多,或者单个元素体积非常大时
- 使用 skiplist 来存储
两个配置项
- ??????zset-max-ziplist-entries:(单位为元素个数)
- zset-max-ziplist-value:(单位为字节)
- 当有序集合的元素个数小于 1号配置项,当每个元素的值都小于 2号配置项时
- Redis 会使用 ziplist 来作为有序集合的内部编码
关于跳表
- 简单来说,跳表是一个 复杂链表,其查询元素的时间复杂度为 O(logN)
- 相比于树形结构,更适合按照范围获取元素(B+ 树)
Zset 应用场景
排行榜系统
- 微博热搜、游戏天梯排行、成绩排行等
关键要点:
- 用来排行的分数为实时变化的
- 虽然是实时变化的,却也能够高效的更新排行
重点理解:
- 有序集合(zset) 能很好的满足上述需求和关键要点
实例理解
- 比如游戏天梯排行
- 只需要将 玩家信息和该玩家所对应的分数给放到有序集合中即可
- 从而便能 自动就形成一个排行榜
- 我们也能 随时按照排行(下标)、按照分数 来进行范围查询
- 随着分数发生改变,也可以比较方便的使用 zincrby 命令来修改分数,且排行榜顺序也能自动进行调整,该操作的时间复杂度为 O(logN)
问题:
- 游戏玩家这么多,此时都用这个 zset 来存,内存能否存下?
举例:
- 假设此时我们有?1亿 个玩家
- 约定?userId 4个字节,score 8个字节,即一个玩家需要 12 个字节来表示
- 12亿 字节 ——> 1.2 GB,对于当今计算机来说,绰绰有余!
实例理解二
- 相较于游戏排行榜,其排序依据很容易确定,仅需根据玩家积分即可
- 微博的排行榜,其排序依据评估起来更为复杂,因为 微博热度是一个综合数值!
- 其参考方面包含 浏览量、点赞量、转发量、评论量等
- 上述各方面具有不同?权重 weight,进而计算得到综合数值(热度)
重点理解
- 此时可以借助 zinterstore / zunionstore 命令,按照加权方式进行处理
- 可以把上述每个维度的数值均放到一个有序集合中
- member 为?微博的id,score 为各自维度的数值
- 通过? zinterstore / zunionstore 命令将上述有序集合按照约定好的权重,进行集合间运算即可
- 最终得到结果集合,其分数便为热度,且 排行榜也顺带着出来了!
总结:
- 上述应用场景,Redis 中的 zset 是一个选择,但不是说非得用 Reids 中的 zset 不可
- 有些场景下确实可以使用到有序集合,但又不方便使用 Redis 时,可以考虑使用其他方式的有序集合
文章来源:https://blog.csdn.net/weixin_63888301/article/details/135433116
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!